
一般的な
EvalSavedModel はまだ必要ですか?
以前の TFMA では、特別なEvalSavedModelを使用して、すべてのメトリクスを tensorflow グラフ内に保存する必要がありました。現在、 beam.CombineFn実装を使用して、TF グラフの外部でメトリクスを計算できるようになりました。
主な違いは次のとおりです。
-
EvalSavedModelトレーナーからの特別なエクスポートが必要ですが、サービング モデルはトレーニング コードに変更を加えることなく使用できます。 -
EvalSavedModelを使用すると、トレーニング時に追加されたメトリクスは評価時に自動的に使用可能になります。EvalSavedModelがない場合、これらのメトリクスを再度追加する必要があります。- このルールの例外は、keras モデルが使用されている場合、keras は保存されたモデルと一緒にメトリクス情報を保存するため、メトリクスも自動的に追加できることです。
TFMA はグラフ内メトリクスと外部メトリクスの両方で機能しますか?
TFMA を使用すると、一部のメトリクスをグラフ内で計算し、他のメトリクスを外部で計算できるハイブリッド アプローチの使用が可能になります。現在EvalSavedModelをお持ちの場合は、引き続き使用できます。
次の 2 つのケースがあります。
- 特徴抽出とメトリック計算の両方に TFMA
EvalSavedModelを使用しますが、結合器ベースのメトリックを追加することもできます。この場合、EvalSavedModelからすべてのグラフ内メトリクスを取得するとともに、以前はサポートされていなかった可能性があるコンバイナー ベースの追加メトリクスも取得します。 - 特徴/予測の抽出には TFMA
EvalSavedModelを使用しますが、すべてのメトリクスの計算には結合器ベースのメトリクスを使用します。このモードは、スライスに使用したいフィーチャ変換がEvalSavedModelに存在するが、すべてのメトリクス計算をグラフの外側で実行したい場合に便利です。
設定
どのようなモデルタイプがサポートされていますか?
TFMA は、keras モデル、汎用 TF2 シグネチャ API に基づくモデル、および TF 推定器ベースのモデルをサポートします (ただし、ユースケースによっては、推定器ベースのモデルではEvalSavedModelの使用が必要になる場合があります)。
サポートされているモデル タイプと制限事項の完全なリストについては、 get_startedガイドを参照してください。
ネイティブ keras ベースのモデルで動作するように TFMA をセットアップするにはどうすればよいですか?
以下は、次の前提に基づく keras モデルの設定例です。
- 保存されたモデルはサービング用であり、シグネチャ名
serving_defaultを使用します (これはmodel_specs[0].signature_nameを使用して変更できます)。 -
model.compile(...)の組み込みメトリクスを評価する必要があります (これはtfma.EvalConfig内のoptions.include_default_metricで無効にできます)。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
構成可能な他のタイプのメトリクスの詳細については、 「メトリクス」を参照してください。
汎用の TF2 シグネチャ ベースのモデルで動作するように TFMA をセットアップするにはどうすればよいですか?
以下は、汎用 TF2 モデルの設定例です。以下の、 signature_name 、評価に使用する必要がある特定の署名の名前です。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
構成可能な他のタイプのメトリクスの詳細については、 「メトリクス」を参照してください。
推定ベースのモデルを操作できるように TFMA をセットアップするにはどうすればよいですか?
この場合、選択肢は 3 つあります。
オプション 1: サービス提供モデルを使用する
このオプションを使用すると、トレーニング中に追加されたメトリクスは評価に含まれません。
以下は、 serving_default使用される署名名であると仮定した設定例です。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
構成可能な他のタイプのメトリクスの詳細については、 「メトリクス」を参照してください。
オプション 2: EvalSavedModel と追加の結合ベースのメトリクスを使用する
この場合、特徴/予測の抽出と評価の両方にEvalSavedModelを使用し、追加の結合器ベースのメトリクスも追加します。
以下は設定例です。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
構成可能な他のタイプのメトリクスの詳細については「メトリクス」を参照し、 EvalSavedModelの設定の詳細については「EvalSavedModel」を参照してください。
オプション 3: EvalSavedModel モデルを特徴/予測抽出のみに使用する
オプション (2) と似ていますが、特徴/予測抽出にはEvalSavedModelのみを使用します。このオプションは、外部メトリックだけが必要だが、スライスしたい特徴変換がある場合に便利です。オプション (1) と同様に、トレーニング中に追加されたメトリクスは評価に含まれません。
この場合、構成は上記と同じですが、 include_default_metricsが無効になっているだけです。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
構成可能な他のタイプのメトリクスの詳細については「メトリクス」を参照し、 EvalSavedModelの設定の詳細については「EvalSavedModel」を参照してください。
keras モデルから推定器ベースのモデルを操作するように TFMA をセットアップするにはどうすればよいですか?
keras model_to_estimatorのセットアップは、推定器の構成と似ています。ただし、モデルから推定器への動作方法に特有の違いがいくつかあります。特に、model-to-esimtator は出力を辞書の形式で返します。辞書キーは、関連付けられた keras モデルの最後の出力層の名前です (名前が指定されていない場合、keras はデフォルトの名前を選択します) dense_1やoutput_1など)。 TFMA の観点から見ると、この動作は、推定対象のモデルが単一のモデルのみである場合でも、複数出力モデルの出力に似ています。この違いを考慮するには、出力名を設定する追加の手順が必要です。ただし、同じ 3 つのオプションが推定値として適用されます。
以下は、推定ベースの構成に必要な変更の例です。
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
事前に計算された (モデルに依存しない) 予測を使用できるように TFMA を設定するにはどうすればよいですか? ( TFRecordとtf.Example )
事前に計算された予測を使用できるように TFMA を構成するには、デフォルトのtfma.PredictExtractorを無効にし、他の入力機能とともに予測を解析するようにtfma.InputExtractorを構成する必要があります。これは、ラベルと重みとともに予測に使用される機能キーの名前を使用してtfma.ModelSpecを構成することによって実現されます。
以下は設定例です。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
構成できるメトリックの詳細については、 「メトリック」を参照してください。
tfma.ModelSpecは構成されていますが、モデルは実際には使用されていないことに注意してください (つまり、 tfma.EvalSharedModelはありません)。モデル分析を実行するための呼び出しは次のようになります。
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
事前に計算された (モデルに依存しない) 予測を使用できるように TFMA を設定するにはどうすればよいですか? ( pd.DataFrame )
メモリに収まる小さなデータセットの場合、 TFRecordの代替となるのはpandas.DataFrameです。 TFMA は、 tfma.analyze_raw_data API を使用してpandas.DataFrameを操作できます。 tfma.MetricsSpecおよびtfma.SlicingSpecの説明については、セットアップガイドを参照してください。構成できるメトリックの詳細については、 「メトリック」を参照してください。
以下は設定例です。
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
メトリクス
どのような種類のメトリクスがサポートされていますか?
TFMA は、次のようなさまざまなメトリクスをサポートしています。
複数出力モデルからのメトリクスはサポートされていますか?
はい。詳細については、メトリクスガイドを参照してください。
複数のモデルからのメトリクスはサポートされていますか?
はい。詳細については、メトリクスガイドを参照してください。
メトリック設定 (名前など) はカスタマイズできますか?
はい。メトリック設定は、 config設定をメトリック構成に追加することでカスタマイズできます (例: 特定のしきい値の設定など)。詳細については、メトリクスガイドを参照してください。
カスタムメトリクスはサポートされていますか?
はい。カスタムtf.keras.metrics.Metric実装を作成するか、カスタムbeam.CombineFn実装を作成します。メトリクスガイドに詳細が記載されています。
サポートされていないメトリクスのタイプは何ですか?
beam.CombineFnを使用してメトリクスを計算できる限り、 tfma.metrics.Metricに基づいて計算できるメトリクスの種類に制限はありません。 tf.keras.metrics.Metricから派生したメトリクスを使用する場合は、次の基準を満たす必要があります。
- 各例のメトリクスの十分な統計を個別に計算し、これらの十分な統計をすべての例にわたって追加して結合し、これらの十分な統計のみからメトリクス値を決定することが可能である必要があります。
- たとえば、精度の場合、十分な統計は「完全な正解数」と「合計の例」です。個々の例に対してこれら 2 つの数値を計算し、それらを例のグループに対して合計して、それらの例に適切な値を取得することができます。最終的な精度は、「合計の正解数 / 合計の例」を使用して計算できます。
アドオン
TFMA を使用してモデルの公平性や偏りを評価できますか?
TFMA には、分類モデルにおける意図しないバイアスの影響を評価するためのエクスポート後のメトリックを提供するFairnessIndicatorsアドオンが含まれています。
カスタマイズ
さらにカスタマイズが必要な場合はどうすればよいですか?
TFMA は非常に柔軟性があり、カスタムExtractors 、 Evaluators 、およびWriters使用してパイプラインのほぼすべての部分をカスタマイズできます。これらの抽象化については、アーキテクチャに関するドキュメントで詳しく説明されています。
トラブルシューティング、デバッグ、ヘルプの取得
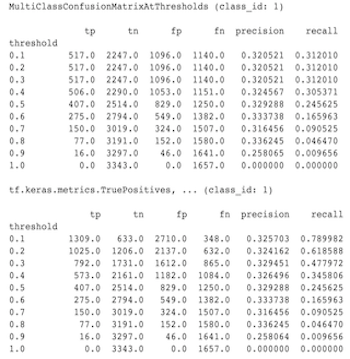
MultiClassConfusionMatrix メトリクスが 2 値化された ConfusionMatrix メトリクスと一致しないのはなぜですか
これらは実際には異なる計算です。 2 値化では、各クラス ID の比較が独立して実行されます (つまり、各クラスの予測が提供されたしきい値と個別に比較されます)。この場合、予測値がしきい値よりも大きかったため、2 つ以上のクラスがすべて、予測と一致したことを示す可能性があります (これは、しきい値が低いほど顕著になります)。マルチクラス混同行列の場合、真の予測値は依然として 1 つだけであり、それは実際の値と一致するか一致しません。しきい値は、予測がしきい値より小さい場合にどのクラスにも一致しないように強制するためにのみ使用されます。しきい値が高くなるほど、二値化されたクラスの予測が一致するのが難しくなります。同様に、しきい値が低いほど、2 値化されたクラスの予測が一致しやすくなります。これは、しきい値 > 0.5 では 2 値化値とマルチクラス行列値がより近くに位置し、しきい値 < 0.5 ではそれらの値がさらに離れることを意味します。
たとえば、クラス 2 が 0.8 の確率で予測されたクラスが 10 個あるとしますが、実際のクラスは確率 0.15 のクラス 1 であったとします。クラス 1 を 2 値化し、しきい値 0.1 を使用する場合、クラス 1 は正しい (0.15 > 0.1) とみなされ、TP としてカウントされます。ただし、マルチクラスの場合、クラス 2 は正しいとみなされます (0.8 > 0.1)。 0.1)、クラス 1 が実際のものであるため、これは FN としてカウントされます。しきい値が低いほど、より多くの値が正とみなされるため、一般に、多クラス混同行列よりも 2 値化混同行列の方が TP および FP カウントが高くなり、同様に TN および FN が低くなります。
以下は、MultiClassConfusionMatrixAtThresholds と、いずれかのクラスの 2 値化で得られた対応するカウントとの間で観察された違いの例です。
精度@1 メトリクスと再現率 @1 メトリクスが同じ値になるのはなぜですか?
上位の k 値が 1 では、精度と再現率は同じものになります。精度はTP / (TP + FP)に等しく、再現率はTP / (TP + FN)に等しくなります。上位の予測は常に正であり、ラベルと一致するか一致しません。つまり、 N個の例では、 TP + FP = N 。ただし、ラベルが上位予測と一致しない場合は、上位 k 以外の予測が一致したことも意味し、上位 k が 1 に設定されている場合、上位 1 以外のすべての予測は 0 になります。これは、FN が(N - TP)である必要があることを意味します) (N - TP)またはN = TP + FN 。最終結果はprecision@1 = TP / N = recall@1となります。これは、例ごとに単一ラベルがある場合にのみ適用され、複数ラベルには適用されないことに注意してください。
平均ラベルと平均予測メトリクスが常に 0.5 になるのはなぜですか?
これは、メトリクスがバイナリ分類問題用に構成されているにもかかわらず、モデルが 1 つのクラスだけではなく両方のクラスの確率を出力していることが原因であると考えられます。これは、tensorflow の分類 APIが使用される場合に一般的です。解決策は、予測の基にするクラスを選択し、そのクラスに基づいて二値化することです。例えば:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
MultiLabelConfusionMatrixPlot を解釈するにはどうすればよいですか?
特定のラベルを指定すると、 MultiLabelConfusionMatrixPlot (および関連するMultiLabelConfusionMatrix ) を使用して、他のラベルの結果と、選択したラベルが実際に真だった場合の予測を比較できます。たとえば、 bird 、 plane 、 supermanの 3 つのクラスがあり、写真を分類して、これらのクラスのいずれかが 1 つ以上含まれているかどうかを示すとします。 MultiLabelConfusionMatrixは、各実際のクラスの他のクラス (予測クラスと呼ばれる) に対するデカルト積を計算します。ペアリングは(actual, predicted)ですが、 predictedクラスは必ずしも肯定的な予測を意味するわけではなく、単に実際の行列と予測行列の予測列を表すだけであることに注意してください。たとえば、次の行列を計算したとします。
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlotには、このデータを表示する 3 つの方法があります。すべての場合において、テーブルを読み取る方法は、実際のクラスの観点から行ごとに行われます。
1) 総予測数
この場合、特定の行 (つまり、実際のクラス) について、他のクラスのTP + FPカウントはどうなるでしょうか。上記のカウントの場合、表示は次のようになります。
| 予測される鳥 | 予測平面 | 予言された超人 | |
|---|---|---|---|
| 本物の鳥 | 6 | 4 | 2 |
| 実機 | 4 | 4 | 4 |
| 本物のスーパーマン | 5 | 5 | 4 |
実際に写真にbird含まれている場合、そのうち 6 羽を正しく予測しました。同時に、 plane (正解または不正解) を 4 回、 superman (正解または不正解) を 2 回予測しました。
2) 不正確な予測数
この場合、特定の行 (つまり、実際のクラス) について、他のクラスのFPカウントはどうなるでしょうか。上記のカウントの場合、表示は次のようになります。
| 予測される鳥 | 予測平面 | 予言された超人 | |
|---|---|---|---|
| 本物の鳥 | 0 | 2 | 1 |
| 実機 | 1 | 0 | 3 |
| 本物のスーパーマン | 2 | 3 | 0 |
写真に実際にbird含まれていたとき、私たちはplane 2 回、 superman 1 回誤って予測しました。
3) 偽陰性の数
この場合、特定の行 (つまり、実際のクラス) について、他のクラスのFNカウントはどうなるでしょうか。上記のカウントの場合、表示は次のようになります。
| 予測される鳥 | 予測平面 | 予言された超人 | |
|---|---|---|---|
| 本物の鳥 | 2 | 2 | 4 |
| 実機 | 1 | 4 | 3 |
| 本物のスーパーマン | 2 | 2 | 5 |
写真に実際にbird含まれていたとき、私たちはそれを予測できませんでした。同時に、 plane予測は 2 回、 superman予測は 4 回失敗しました。
予測キーが見つからないというエラーが表示されるのはなぜですか?
一部のモデルは、予測を辞書の形式で出力します。たとえば、バイナリ分類問題の TF 推定器は、 probabilities 、 class_idsなどを含む辞書を出力します。ほとんどの場合、TFMA には、 predictions 、 probabilitiesなどの一般的に使用されるキー名を見つけるためのデフォルトがあります。ただし、モデルが非常にカスタマイズされている場合は、 TFMA が認識しない名前でキーを出力します。このような場合、出力が保存されているキーの名前を識別するために、 prediciton_key設定をtfma.ModelSpecに追加する必要があります。