
일반적인
EvalSavedModel이 여전히 필요합니까?
이전에 TFMA에서는 특수 EvalSavedModel 사용하여 모든 측정항목을 텐서플로우 그래프 내에 저장해야 했습니다. 이제 beam.CombineFn 구현을 사용하여 TF 그래프 외부에서 측정항목을 계산할 수 있습니다.
주요 차이점 중 일부는 다음과 같습니다.
-
EvalSavedModel트레이너에서 특별한 내보내기가 필요한 반면 제공 모델은 학습 코드를 변경하지 않고도 사용할 수 있습니다. -
EvalSavedModel사용하면 훈련 시 추가된 모든 측정항목을 평가 시 자동으로 사용할 수 있습니다.EvalSavedModel이 없으면 이러한 측정항목을 다시 추가해야 합니다.- 이 규칙의 예외는 keras 모델을 사용하는 경우 keras가 저장된 모델과 함께 메트릭 정보를 저장하기 때문에 메트릭이 자동으로 추가될 수도 있다는 것입니다.
TFMA는 그래프 내 측정항목과 외부 측정항목 모두에서 작동할 수 있나요?
TFMA를 사용하면 일부 메트릭은 그래프 내에서 계산할 수 있고 다른 메트릭은 외부에서 계산할 수 있는 하이브리드 접근 방식을 사용할 수 있습니다. 현재 EvalSavedModel 이 있으면 계속 사용할 수 있습니다.
두 가지 경우가 있습니다:
- 특징 추출과 메트릭 계산 모두에 TFMA
EvalSavedModel사용하고 추가 결합기 기반 메트릭도 추가합니다. 이 경우 이전에 지원되지 않았을 수 있는 결합기 기반의 추가 측정항목과 함께EvalSavedModel의 모든 그래프 내 측정항목을 가져옵니다. - 기능/예측 추출에는 TFMA
EvalSavedModel사용하고 모든 메트릭 계산에는 결합기 기반 메트릭을 사용합니다. 이 모드는 슬라이싱에 사용하려는EvalSavedModel에 특성 변환이 있지만 그래프 외부에서 모든 메트릭 계산을 수행하는 것을 선호하는 경우에 유용합니다.
설정
어떤 모델 유형이 지원되나요?
TFMA는 keras 모델, 일반 TF2 서명 API 기반 모델 및 TF 추정기 기반 모델을 지원합니다(단, 사용 사례에 따라 추정기 기반 모델을 사용하려면 EvalSavedModel 필요할 수 있음).
지원되는 모델 유형의 전체 목록과 제한 사항은 get_started 가이드를 참조하세요.
기본 Keras 기반 모델과 작동하도록 TFMA를 어떻게 설정합니까?
다음은 다음 가정을 기반으로 하는 keras 모델의 구성 예입니다.
- 저장된 모델은 서빙용이며 서명 이름
serving_default사용합니다(model_specs[0].signature_name사용하여 변경할 수 있음). -
model.compile(...)의 내장 측정항목을 평가해야 합니다( tfma.EvalConfig 내의options.include_default_metric통해 비활성화할 수 있음).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
구성할 수 있는 다른 유형의 측정항목에 대한 자세한 내용은 측정항목을 참조하세요.
일반 TF2 서명 기반 모델과 작동하도록 TFMA를 어떻게 설정합니까?
다음은 일반 TF2 모델에 대한 구성 예시입니다. 아래에서 signature_name 평가에 사용해야 하는 특정 서명의 이름입니다.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
구성할 수 있는 다른 유형의 측정항목에 대한 자세한 내용은 측정항목을 참조하세요.
추정기 기반 모델과 함께 작동하도록 TFMA를 어떻게 설정합니까?
이 경우 세 가지 선택이 있습니다.
옵션 1: 제공 모델 사용
이 옵션을 사용하면 훈련 중에 추가된 측정항목이 평가에 포함되지 않습니다.
다음은 serving_default 사용된 서명 이름이라고 가정하는 구성의 예입니다.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
구성할 수 있는 다른 유형의 측정항목에 대한 자세한 내용은 측정항목을 참조하세요.
옵션 2: 추가 결합자 기반 측정항목과 함께 EvalSavedModel 사용
이 경우 특징/예측 추출 및 평가 모두에 EvalSavedModel 사용하고 결합자 기반 메트릭을 추가합니다.
다음은 구성 예시입니다.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
구성할 수 있는 다른 유형의 메트릭에 대한 자세한 내용은 메트릭을 참조하고, EvalSavedModel 설정에 대한 자세한 내용은 EvalSavedModel 을 참조하세요.
옵션 3: 특징/예측 추출에만 EvalSavedModel 모델 사용
옵션(2)와 유사하지만 특징/예측 추출에는 EvalSavedModel 만 사용합니다. 이 옵션은 외부 측정항목만 필요하지만 분할하려는 기능 변환이 있는 경우에 유용합니다. 옵션 (1)과 유사하게 훈련 중에 추가된 측정항목은 평가에 포함되지 않습니다.
이 경우 구성은 위와 동일하지만 include_default_metrics 가 비활성화됩니다.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
구성할 수 있는 다른 유형의 메트릭에 대한 자세한 내용은 메트릭을 참조하고, EvalSavedModel 설정에 대한 자세한 내용은 EvalSavedModel 을 참조하세요.
keras 모델-추정자 기반 모델과 작동하도록 TFMA를 어떻게 설정합니까?
keras model_to_estimator 설정은 추정기 구성과 유사합니다. 그러나 모델과 추정기가 작동하는 방식에는 몇 가지 차이점이 있습니다. 특히, model-to-esimtator는 dict 키가 연관된 keras 모델의 마지막 출력 레이어 이름인 dict 형식으로 출력을 반환합니다(이름이 제공되지 않으면 keras는 기본 이름을 선택합니다) dense_1 또는 output_1 등). TFMA 관점에서 볼 때 이 동작은 추정기에 대한 모델이 단일 모델에만 해당될 수 있더라도 다중 출력 모델의 출력과 유사합니다. 이러한 차이를 설명하려면 출력 이름을 설정하는 추가 단계가 필요합니다. 그러나 동일한 세 가지 옵션이 추정기로 적용됩니다.
다음은 추정기 기반 구성에 필요한 변경 사항의 예입니다.
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
사전 계산된(예: 모델에 구애받지 않는) 예측을 사용하도록 TFMA를 어떻게 설정합니까? ( TFRecord 및 tf.Example )
미리 계산된 예측과 함께 작동하도록 TFMA를 구성하려면 기본 tfma.PredictExtractor 비활성화해야 하며 tfma.InputExtractor 다른 입력 기능과 함께 예측을 구문 분석하도록 구성되어야 합니다. 이는 라벨 및 가중치와 함께 예측에 사용되는 기능 키의 이름으로 tfma.ModelSpec 을 구성하여 수행됩니다.
다음은 설정 예입니다.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
구성할 수 있는 측정항목에 대한 자세한 내용은 측정항목을 참조하세요.
tfma.ModelSpec 이 구성되고 있지만 모델은 실제로 사용되지 않습니다(즉, tfma.EvalSharedModel 없음). 모델 분석을 실행하기 위한 호출은 다음과 같습니다.
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
사전 계산된(예: 모델에 구애받지 않는) 예측을 사용하도록 TFMA를 어떻게 설정합니까? ( pd.DataFrame )
메모리에 들어갈 수 있는 작은 데이터 세트의 경우 TFRecord 의 대안은 pandas.DataFrame 입니다. TFMA는 tfma.analyze_raw_data API를 사용하여 pandas.DataFrame 에서 작동할 수 있습니다. tfma.MetricsSpec 및 tfma.SlicingSpec 에 대한 설명은 설정 가이드를 참조하세요. 구성할 수 있는 측정항목에 대한 자세한 내용은 측정항목을 참조하세요.
다음은 설정 예입니다.
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
측정항목
어떤 유형의 측정항목이 지원되나요?
TFMA는 다음을 포함한 다양한 측정항목을 지원합니다.
다중 출력 모델의 측정항목이 지원되나요?
예. 자세한 내용은 측정항목 가이드를 참조하세요.
다중 모델의 측정항목이 지원되나요?
예. 자세한 내용은 측정항목 가이드를 참조하세요.
측정항목 설정(이름 등)을 맞춤설정할 수 있나요?
예. 지표 구성에 config 설정을 추가하여 지표 설정을 사용자 정의할 수 있습니다(예: 특정 임계값 설정 등). 자세한 내용은 측정항목 가이드를 참조하세요.
맞춤 측정항목이 지원되나요?
예. 사용자 정의 tf.keras.metrics.Metric 구현을 작성하거나 사용자 정의 beam.CombineFn 구현을 작성하면 됩니다. 측정항목 가이드에 자세한 내용이 있습니다.
지원되지 않는 측정항목 유형은 무엇인가요?
beam.CombineFn 을 사용하여 메트릭을 계산할 수 있는 한 tfma.metrics.Metric 기반으로 계산할 수 있는 메트릭 유형에는 제한이 없습니다. tf.keras.metrics.Metric 에서 파생된 측정항목으로 작업하는 경우 다음 기준을 충족해야 합니다.
- 각 예에서 메트릭에 대한 충분한 통계를 독립적으로 계산한 다음 모든 예에 걸쳐 이러한 충분한 통계를 추가하여 이러한 충분한 통계를 결합하고 이러한 충분한 통계에서만 메트릭 값을 결정하는 것이 가능해야 합니다.
- 예를 들어, 정확성을 위해 충분한 통계는 "전체 정확" 및 "전체 예시"입니다. 개별 예에 대해 이 두 숫자를 계산하고 예 그룹에 대해 이를 추가하여 해당 예에 대한 올바른 값을 얻을 수 있습니다. 최종 정확도는 "전체 정확/전체 예시"를 사용하여 계산할 수 있습니다.
부가기능
TFMA를 사용하여 내 모델의 공정성이나 편향을 평가할 수 있나요?
TFMA에는 분류 모델에서 의도하지 않은 편향의 영향을 평가하기 위한 내보내기 후 측정항목을 제공하는 FairnessIndicators 추가 기능이 포함되어 있습니다.
맞춤화
더 많은 사용자 정의가 필요한 경우 어떻게 해야 합니까?
TFMA는 매우 유연하며 사용자 정의 Extractors , Evaluators 및/또는 Writers 사용하여 파이프라인의 거의 모든 부분을 사용자 정의할 수 있습니다. 이러한 추상화는 아키텍처 문서에서 더 자세히 논의됩니다.
문제 해결, 디버깅 및 도움말 얻기
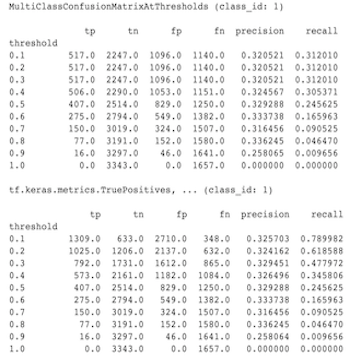
MultiClassConfusionMatrix 측정항목이 이진화된 ConfusionMatrix 측정항목과 일치하지 않는 이유
이것은 실제로 다른 계산입니다. 이진화는 각 클래스 ID에 대해 독립적으로 비교를 수행합니다. 즉, 각 클래스에 대한 예측은 제공된 임계값과 별도로 비교됩니다. 이 경우 두 개 이상의 클래스가 모두 예측 값이 임계값보다 크기 때문에 예측과 일치했음을 나타낼 수 있습니다(이는 임계값이 낮을수록 더욱 분명해집니다). 다중 클래스 혼동 행렬의 경우에는 여전히 실제 예측 값이 하나만 있으며 실제 값과 일치하거나 일치하지 않습니다. 임계값은 임계값보다 작은 경우 예측이 어떤 클래스와도 일치하지 않도록 강제하는 데에만 사용됩니다. 임계값이 높을수록 이진화된 클래스의 예측이 일치하기가 더 어려워집니다. 마찬가지로 임계값이 낮을수록 이진화된 클래스의 예측이 일치하기가 더 쉽습니다. 이는 임계값 > 0.5에서 이진화된 값과 다중 클래스 행렬 값이 더 가깝게 정렬되고 임계값 < 0.5에서는 더 멀리 떨어져 있음을 의미합니다.
예를 들어 클래스 2가 0.8의 확률로 예측되었지만 실제 클래스는 확률이 0.15인 클래스 1인 10개의 클래스가 있다고 가정해 보겠습니다. 클래스 1을 이진화하고 임계값 0.1을 사용하면 클래스 1이 올바른 것으로 간주되므로(0.15 > 0.1) TP로 계산됩니다. 그러나 다중 클래스 사례의 경우 클래스 2가 올바른 것으로 간주됩니다(0.8 > 0.1). 0.1) 그리고 클래스 1이 실제였으므로 이는 FN으로 계산됩니다. 임계값이 낮을수록 더 많은 값이 양수로 간주되기 때문에 일반적으로 다중 클래스 혼동 행렬보다 이진화된 혼동 행렬의 TP 및 FP 수가 더 높고 마찬가지로 TN 및 FN도 낮습니다.
다음은 MultiClassConfusionMatrixAtThresholds와 클래스 중 하나의 이진화에서 해당 개수 간에 관찰된 차이의 예입니다.
내 Precision@1 측정항목과 Recall@1 측정항목의 값이 동일한 이유는 무엇입니까?
상위 k 값이 1인 정밀도와 재현율은 동일합니다. 정밀도는 TP / (TP + FP) 와 같고 재현율은 TP / (TP + FN) 과 같습니다. 최상위 예측은 항상 긍정적이며 레이블과 일치하거나 일치하지 않습니다. 즉, N 예시에서는 TP + FP = N . 그러나 레이블이 상위 예측과 일치하지 않는 경우 이는 상위 k가 아닌 예측이 일치했음을 의미하며 상위 k가 1로 설정된 경우 상위 1이 아닌 모든 예측은 0이 됩니다. 이는 FN이 (N - TP) 이어야 함을 의미합니다. (N - TP) 또는 N = TP + FN . 최종 결과는 precision@1 = TP / N = recall@1 입니다. 이는 다중 라벨이 아닌 예시당 단일 라벨이 있는 경우에만 적용됩니다.
평균 라벨 및 평균 예측 지표가 항상 0.5인 이유는 무엇입니까?
이는 지표가 이진 분류 문제에 대해 구성되어 있지만 모델이 하나가 아닌 두 클래스 모두에 대한 확률을 출력하기 때문에 발생했을 가능성이 높습니다. 이는 tensorflow의 분류 API를 사용할 때 일반적입니다. 해결책은 예측의 기반이 될 클래스를 선택한 다음 해당 클래스를 이진화하는 것입니다. 예를 들어:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
MultiLabelConfusionMatrixPlot을 해석하는 방법은 무엇입니까?
특정 라벨이 주어지면 MultiLabelConfusionMatrixPlot (및 관련 MultiLabelConfusionMatrix )을 사용하여 선택한 라벨이 실제로 참일 때 다른 라벨의 결과와 예측을 비교할 수 있습니다. 예를 들어, bird , plane , superman 의 세 가지 클래스가 있고 사진에 이러한 클래스 중 하나 이상이 포함되어 있는지 표시하기 위해 사진을 분류한다고 가정해 보겠습니다. MultiLabelConfusionMatrix 는 서로 다른 클래스(예측 클래스라고 함)에 대해 각 실제 클래스의 데카르트 곱을 계산합니다. 쌍이 (actual, predicted) 인 동안 predicted 클래스가 반드시 긍정적인 예측을 의미하는 것은 아니며 단지 실제 대 예측 행렬의 예측 열을 나타낼 뿐입니다. 예를 들어 다음 행렬을 계산했다고 가정해 보겠습니다.
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot 에는 이 데이터를 표시하는 세 가지 방법이 있습니다. 모든 경우에 테이블을 읽는 방법은 실제 클래스의 관점에서 행 단위입니다.
1) 총 예측 횟수
이 경우 특정 행(예: 실제 클래스)에 대해 다른 클래스의 TP + FP 수는 얼마입니까? 위의 개수에 대한 표시는 다음과 같습니다.
| 예측된 새 | 예상 비행기 | 예측된 슈퍼맨 | |
|---|---|---|---|
| 실제 새 | 6 | 4 | 2 |
| 실제 비행기 | 4 | 4 | 4 |
| 실제 슈퍼맨 | 5 | 5 | 4 |
사진에 실제로 bird 포함되어 있을 때 우리는 그 중 6개를 정확하게 예측했습니다. 동시에 우리는 plane (올바른지 틀린지)를 4번, superman (올바른지 틀린지)을 2번 예측했습니다.
2) 잘못된 예측 횟수
이 경우 특정 행(예: 실제 클래스)에 대해 다른 클래스의 FP 수는 얼마입니까? 위의 개수에 대한 표시는 다음과 같습니다.
| 예측된 새 | 예상 비행기 | 예측된 슈퍼맨 | |
|---|---|---|---|
| 실제 새 | 0 | 2 | 1 |
| 실제 비행기 | 1 | 0 | 3 |
| 실제 슈퍼맨 | 2 | 3 | 0 |
사진에 실제로 bird 포함되어 있을 때 우리는 plane 2번, superman 1번 잘못 예측했습니다.
3) 거짓음성수
이 경우 특정 행(예: 실제 클래스)에 대해 다른 클래스의 FN 수는 얼마입니까? 위의 개수에 대한 표시는 다음과 같습니다.
| 예측된 새 | 예상 비행기 | 예측된 슈퍼맨 | |
|---|---|---|---|
| 실제 새 | 2 | 2 | 4 |
| 실제 비행기 | 1 | 4 | 3 |
| 실제 슈퍼맨 | 2 | 2 | 5 |
사진에 실제로 bird 포함되어 있을 때 우리는 두 번이나 예측에 실패했습니다. 동시에 우리는 plane 2번, superman 4번 예측하는데 실패했습니다.
예측 키를 찾을 수 없다는 오류가 발생하는 이유는 무엇입니까?
일부 모델은 사전 형태로 예측을 출력합니다. 예를 들어 이진 분류 문제에 대한 TF 추정기는 probabilities , class_ids 등이 포함된 사전을 출력합니다. 대부분의 경우 TFMA에는 predictions , probabilities 등과 같이 일반적으로 사용되는 키 이름을 찾기 위한 기본값이 있습니다. 그러나 모델이 매우 사용자 정의된 경우 TFMA에서 알 수 없는 이름의 출력 키. 이러한 경우 출력이 저장되는 키의 이름을 식별하기 위해 prediciton_key 설정을 tfma.ModelSpec 에 추가해야 합니다.