
Ogólny
Czy nadal wymagany jest model EvalSavedModel?
Wcześniej TFMA wymagała przechowywania wszystkich metryk na wykresie tensorflow przy użyciu specjalnego EvalSavedModel . Teraz metryki można obliczać poza wykresem TF przy użyciu implementacji beam.CombineFn .
Oto niektóre z głównych różnic:
- Model
EvalSavedModelwymaga specjalnego eksportu od trenera, natomiast modelu obsługującego można używać bez konieczności wprowadzania jakichkolwiek zmian w kodzie szkoleniowym. - Gdy używany jest
EvalSavedModel, wszelkie metryki dodane w czasie szkolenia są automatycznie dostępne w czasie oceny. BezEvalSavedModelte metryki muszą zostać ponownie dodane.- Wyjątkiem od tej reguły jest sytuacja, gdy używany jest model keras, metryki można również dodać automatycznie, ponieważ keras zapisuje informacje o metrykach obok zapisanego modelu.
Czy TFMA może współpracować zarówno z metrykami na wykresie, jak i metrykami zewnętrznymi?
TFMA umożliwia zastosowanie podejścia hybrydowego, w którym niektóre metryki można obliczyć na wykresie, podczas gdy inne można obliczyć na zewnątrz. Jeśli obecnie posiadasz EvalSavedModel , możesz go nadal używać.
Istnieją dwa przypadki:
- Użyj TFMA
EvalSavedModelzarówno do ekstrakcji cech, jak i obliczeń metryk, ale dodaj także dodatkowe metryki oparte na kombinacjach. W takim przypadku otrzymasz wszystkie metryki na wykresie zEvalSavedModelwraz z dodatkowymi metrykami z modułu łączącego, które mogły nie być wcześniej obsługiwane. - Użyj TFMA
EvalSavedModeldo ekstrakcji cech/prognoz, ale do wszystkich obliczeń metryk używaj metryk opartych na sumatorze. Ten tryb jest przydatny, jeśli wEvalSavedModelistnieją transformacje funkcji, których chcesz użyć do wycinania, ale wolisz wykonywać wszystkie obliczenia metryczne poza wykresem.
Organizować coś
Jakie typy modeli są obsługiwane?
TFMA obsługuje modele keras, modele oparte na ogólnych interfejsach API sygnatur TF2, a także modele oparte na estymatorach TF (chociaż w zależności od przypadku użycia modele oparte na estymatorach mogą wymagać użycia EvalSavedModel ).
Zobacz przewodnik get_started, aby zapoznać się z pełną listą obsługiwanych typów modeli i wszelkich ograniczeń.
Jak skonfigurować TFMA do pracy z natywnym modelem opartym na keras?
Poniżej znajduje się przykładowa konfiguracja modelu keras oparta na następujących założeniach:
- Zapisany model służy do serwowania i używa
serving_defaultnazwy podpisu (można to zmienić za pomocąmodel_specs[0].signature_name). - Należy ocenić wbudowane metryki z
model.compile(...)(można to wyłączyć poprzezoptions.include_default_metricw tfma.EvalConfig ).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Zobacz metryki, aby uzyskać więcej informacji na temat innych typów metryk, które można skonfigurować.
Jak skonfigurować TFMA do pracy z ogólnym modelem opartym na podpisach TF2?
Poniżej znajduje się przykładowa konfiguracja ogólnego modelu TF2. Poniżej signature_name to nazwa konkretnego podpisu, który powinien zostać użyty do oceny.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Zobacz metryki, aby uzyskać więcej informacji na temat innych typów metryk, które można skonfigurować.
Jak skonfigurować TFMA do pracy z modelem opartym na estymatorze?
W tym przypadku istnieją trzy możliwości.
Opcja 1: użyj modelu udostępniania
Jeśli ta opcja zostanie użyta, żadne metryki dodane podczas szkolenia NIE zostaną uwzględnione w ocenie.
Poniżej znajduje się przykładowa konfiguracja przy założeniu, że serving_default jest użytą nazwą podpisu:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Zobacz metryki, aby uzyskać więcej informacji na temat innych typów metryk, które można skonfigurować.
Opcja 2: użyj EvalSavedModel wraz z dodatkowymi metrykami opartymi na łącznikach
W takim przypadku użyj EvalSavedModel do ekstrakcji i oceny cech/prognoz, a także dodaj dodatkowe metryki oparte na łącznikach.
Poniżej znajduje się przykładowa konfiguracja:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Zobacz metryki , aby uzyskać więcej informacji na temat innych typów metryk, które można skonfigurować, oraz EvalSavedModel , aby uzyskać więcej informacji na temat konfigurowania EvalSavedModel.
Opcja 3: Użyj modelu EvalSavedModel tylko do wyodrębnienia cech/prognoz
Podobny do opcji (2), ale używa tylko EvalSavedModel do ekstrakcji cech/prognoz. Ta opcja jest przydatna, jeśli potrzebne są tylko metryki zewnętrzne, ale istnieją przekształcenia funkcji, które chcesz podzielić. Podobnie jak w przypadku opcji (1), żadne metryki dodane podczas szkolenia NIE będą uwzględniane w ocenie.
W tym przypadku konfiguracja jest taka sama jak powyżej, tylko include_default_metrics jest wyłączona.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
Zobacz metryki , aby uzyskać więcej informacji na temat innych typów metryk, które można skonfigurować, oraz EvalSavedModel , aby uzyskać więcej informacji na temat konfigurowania EvalSavedModel.
Jak skonfigurować TFMA do pracy z modelem opartym na modelu Keras do estymatora?
Konfiguracja keras model_to_estimator jest podobna do konfiguracji estymatora. Istnieje jednak kilka różnic specyficznych dla sposobu działania modelu do estymatora. W szczególności model do esimtatora zwraca swoje dane wyjściowe w formie dyktatu, gdzie klucz dyktowania jest nazwą ostatniej warstwy wyjściowej w powiązanym modelu keras (jeśli nie zostanie podana nazwa, keras wybierze dla ciebie domyślną nazwę takie jak dense_1 lub output_1 ). Z perspektywy TFMA zachowanie to jest podobne do tego, co można uzyskać w przypadku modelu z wieloma wynikami, nawet jeśli model do estymatora może dotyczyć tylko jednego modelu. Aby uwzględnić tę różnicę, wymagany jest dodatkowy krok w celu skonfigurowania nazwy wyjścia. Jednakże te same trzy opcje mają zastosowanie w przypadku estymatora.
Poniżej znajduje się przykład zmian wymaganych w konfiguracji opartej na estymatorze:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
Jak skonfigurować TFMA do pracy ze wstępnie obliczonymi (tzn. niezależnymi od modelu) przewidywaniami? ( TFRecord i tf.Example )
Aby skonfigurować TFMA do pracy ze wstępnie obliczonymi predykcjami, domyślny tfma.PredictExtractor musi być wyłączony, a tfma.InputExtractor musi być skonfigurowany tak, aby analizował predykcje wraz z innymi funkcjami wejściowymi. Osiąga się to poprzez skonfigurowanie tfma.ModelSpec z nazwą klucza funkcji używanego do przewidywań wraz z etykietami i wagami.
Poniżej znajduje się przykładowa konfiguracja:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Zobacz metryki , aby uzyskać więcej informacji na temat metryk, które można skonfigurować.
Należy zauważyć, że chociaż konfigurowany jest plik tfma.ModelSpec , model w rzeczywistości nie jest używany (tzn. nie ma tfma.EvalSharedModel ). Wywołanie analizy modelu może wyglądać następująco:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
Jak skonfigurować TFMA do pracy ze wstępnie obliczonymi (tzn. niezależnymi od modelu) przewidywaniami? ( pd.DataFrame )
W przypadku małych zestawów danych, które mieszczą się w pamięci, alternatywą dla TFRecord jest pandas.DataFrame s. TFMA może działać na pandas.DataFrame s przy użyciu interfejsu API tfma.analyze_raw_data . Wyjaśnienie parametrów tfma.MetricsSpec i tfma.SlicingSpec można znaleźć w podręczniku instalacji . Zobacz metryki , aby uzyskać więcej informacji na temat metryk, które można skonfigurować.
Poniżej znajduje się przykładowa konfiguracja:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
Metryka
Jakie typy metryk są obsługiwane?
TFMA obsługuje szeroką gamę wskaźników, w tym:
- metryki regresji
- metryki klasyfikacji binarnej
- metryki klasyfikacji wieloklasowej/wieloetykietowej
- wskaźniki mikrośrednie/makrośrednie
- metryki oparte na zapytaniach/rankingu
Czy obsługiwane są metryki z modeli z wieloma wynikami?
Tak. Więcej szczegółów znajdziesz w przewodniku po metrykach .
Czy obsługiwane są metryki z wielu modeli?
Tak. Więcej szczegółów znajdziesz w przewodniku po metrykach .
Czy ustawienia metryki (nazwa itp.) można dostosować?
Tak. Ustawienia metryk można dostosować (np. ustawiając określone progi itp.), dodając ustawienia config do konfiguracji metryk. Więcej szczegółów znajdziesz w przewodniku po metrykach .
Czy obsługiwane są niestandardowe metryki?
Tak. Albo pisząc niestandardową implementację tf.keras.metrics.Metric , albo pisząc niestandardową implementację beam.CombineFn . Przewodnik po metrykach zawiera więcej szczegółów.
Jakie typy metryk nie są obsługiwane?
O ile metrykę można obliczyć za pomocą beam.CombineFn , nie ma żadnych ograniczeń dotyczących typów metryk, które można obliczyć na podstawie tfma.metrics.Metric . Jeśli pracujesz z metryką pochodzącą z tf.keras.metrics.Metric , muszą zostać spełnione następujące kryteria:
- Powinno być możliwe niezależne obliczenie wystarczających statystyk dla metryki w każdym przykładzie, następnie połączenie tych wystarczających statystyk poprzez dodanie ich do wszystkich przykładów i określenie wartości metryki wyłącznie na podstawie tych wystarczających statystyk.
- Na przykład dla dokładności wystarczające statystyki to „całkowicie poprawne” i „całkowite przykłady”. Można obliczyć te dwie liczby dla poszczególnych przykładów i dodać je do grupy przykładów, aby uzyskać właściwe wartości dla tych przykładów. Ostateczną dokładność można obliczyć na podstawie „całkowicie poprawnych / wszystkich przykładów”.
Dodatki
Czy mogę użyć TFMA do oceny uczciwości lub stronniczości mojego modelu?
TFMA zawiera dodatek FairnessIndicators , który udostępnia wskaźniki poeksportowe do oceny skutków niezamierzonego błędu systematycznego w modelach klasyfikacji.
Personalizacja
A co, jeśli potrzebuję większej personalizacji?
TFMA jest bardzo elastyczna i pozwala na dostosowanie prawie wszystkich części potoku przy użyciu niestandardowych Extractors , Evaluators i/lub Writers . Abstrakcje te omówiono bardziej szczegółowo w dokumencie dotyczącym architektury .
Rozwiązywanie problemów, debugowanie i uzyskiwanie pomocy
Dlaczego metryki MultiClassConfusionMatrix nie odpowiadają binarnym metrykom ConfusionMatrix
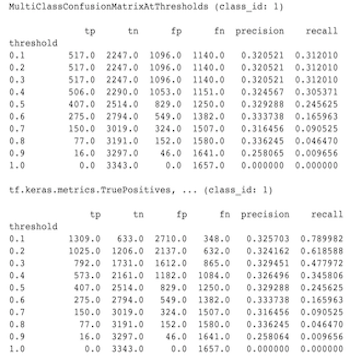
To są właściwie różne obliczenia. Binaryzacja przeprowadza porównanie dla każdego identyfikatora klasy niezależnie (tj. prognoza dla każdej klasy jest porównywana oddzielnie z podanymi progami). W tym przypadku możliwe jest, że dwie lub więcej klas wskaże, że spełniły przewidywania, ponieważ ich przewidywana wartość była większa niż próg (będzie to jeszcze bardziej widoczne przy niższych progach). W przypadku wieloklasowej macierzy zamieszania nadal istnieje tylko jedna prawdziwa przewidywana wartość, która albo odpowiada wartości rzeczywistej, albo nie. Próg służy tylko do wymuszenia dopasowania przewidywania do żadnej klasy, jeśli jest mniejszy niż próg. Im wyższy próg, tym trudniej dopasować przewidywanie klasy binarnej. Podobnie im niższy próg, tym łatwiej jest dopasować przewidywania klasy binarnej. Oznacza to, że przy progach > 0,5 wartości binarne i wartości macierzy wieloklasowej będą bliżej dopasowane, a przy progach < 0,5 będą one bardziej od siebie oddalone.
Załóżmy na przykład, że mamy 10 klas, dla których przewidywano klasę 2 z prawdopodobieństwem 0,8, ale rzeczywistą klasą była klasa 1, dla której prawdopodobieństwo wynosiło 0,15. Jeśli dokonasz binaryzacji na klasie 1 i użyjesz progu 0,1, wówczas klasa 1 zostanie uznana za poprawną (0,15 > 0,1), więc będzie liczona jako TP, jednak w przypadku wielu klas klasa 2 zostanie uznana za poprawną (0,8 > 0.1), a ponieważ rzeczywista była klasa 1, będzie to liczone jako FN. Ponieważ przy niższych progach więcej wartości będzie uznawanych za dodatnie, ogólnie rzecz biorąc, w przypadku binarnej macierzy zamieszania będą wyższe zliczenia TP i FP niż w przypadku wieloklasowej macierzy zamieszania i podobnie niższe TN i FN.
Poniżej znajduje się przykład zaobserwowanych różnic między MultiClassConfusionMatrixAtThresholds a odpowiednimi liczbami z binaryzacji jednej z klas.
Dlaczego moje wskaźniki precyzja@1 i wycofanie@1 mają tę samą wartość?
Przy najwyższej wartości k wynoszącej 1 precyzja i przypominanie są tym samym. Precyzja jest równa TP / (TP + FP) , a przywołanie jest równe TP / (TP + FN) . Najwyższa prognoza jest zawsze pozytywna i będzie zgodna lub nie zgodna z etykietą. Innymi słowy, przy N przykładach TP + FP = N . Jeśli jednak etykieta nie pasuje do najwyższej predykcji, oznacza to również, że dopasowano predykcję k spoza góry, a przy k ustawionym na 1, wszystkie przewidywania spoza pierwszej 1 będą wynosić 0. Oznacza to, że FN musi wynosić (N - TP) lub N = TP + FN . Efektem końcowym jest precision@1 = TP / N = recall@1 . Należy pamiętać, że ma to zastosowanie tylko wtedy, gdy na przykład przypada jedna etykieta, a nie w przypadku wielu etykiet.
Dlaczego moje wskaźniki mean_label i mean_prediction mają zawsze wartość 0,5?
Jest to najprawdopodobniej spowodowane tym, że metryki są skonfigurowane pod kątem problemu klasyfikacji binarnej, ale model generuje prawdopodobieństwa dla obu klas, a nie tylko jednej. Jest to powszechne, gdy używany jest interfejs API klasyfikacji tensorflow . Rozwiązaniem jest wybranie klasy, na której mają być oparte przewidywania, a następnie binaryzacja tej klasy. Na przykład:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
Jak interpretować MultiLabelConfusionMatrixPlot?
Biorąc pod uwagę konkretną etykietę, MultiLabelConfusionMatrixPlot (i powiązany MultiLabelConfusionMatrix ) może służyć do porównywania wyników innych etykiet i ich przewidywań, gdy wybrana etykieta jest rzeczywiście prawdziwa. Załóżmy na przykład, że mamy trzy klasy bird , plane i superman i klasyfikujemy obrazy, aby wskazać, czy zawierają jedną lub więcej którejkolwiek z tych klas. MultiLabelConfusionMatrix obliczy iloczyn kartezjański każdej rzeczywistej klasy względem innych klas (zwanych klasą przewidywaną). Należy zauważyć, że chociaż parowanie jest (actual, predicted) , predicted klasa niekoniecznie oznacza pozytywną prognozę, a jedynie reprezentuje przewidywaną kolumnę w macierzy rzeczywistej i przewidywanej. Załóżmy na przykład, że obliczyliśmy następujące macierze:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot ma trzy sposoby wyświetlania tych danych. We wszystkich przypadkach tabelę należy czytać wiersz po wierszu z perspektywy aktualnej klasy.
1) Całkowita liczba prognoz
W tym przypadku, dla danego wiersza (tj. rzeczywistej klasy), jakie były wartości TP + FP dla pozostałych klas. W przypadku powyższych obliczeń nasz wyświetlacz będzie wyglądał następująco:
| Przewidywany ptak | Przewidywany samolot | Przewidywany superman | |
|---|---|---|---|
| Prawdziwy ptak | 6 | 4 | 2 |
| Rzeczywisty samolot | 4 | 4 | 4 |
| Prawdziwy superman | 5 | 5 | 4 |
Kiedy na zdjęciach faktycznie pojawił się bird poprawnie przewidzieliśmy 6 z nich. W tym samym czasie przewidzieliśmy także plane (poprawnie lub błędnie) 4 razy i superman (poprawnie lub błędnie) 2 razy.
2) Nieprawidłowa liczba przewidywań
W tym przypadku, dla danego wiersza (tj. rzeczywistej klasy), jakie były liczby FP dla pozostałych klas. W przypadku powyższych obliczeń nasz wyświetlacz będzie wyglądał następująco:
| Przewidywany ptak | Przewidywany samolot | Przewidywany superman | |
|---|---|---|---|
| Prawdziwy ptak | 0 | 2 | 1 |
| Rzeczywisty samolot | 1 | 0 | 3 |
| Prawdziwy superman | 2 | 3 | 0 |
Kiedy na zdjęciach rzeczywiście był bird 2 razy błędnie przewidzieliśmy plane , a 1 raz superman .
3) Liczba fałszywie ujemna
W tym przypadku, dla danego wiersza (tj. rzeczywistej klasy), jakie były zliczenia FN dla pozostałych klas. W przypadku powyższych obliczeń nasz wyświetlacz będzie wyglądał następująco:
| Przewidywany ptak | Przewidywany samolot | Przewidywany superman | |
|---|---|---|---|
| Prawdziwy ptak | 2 | 2 | 4 |
| Rzeczywisty samolot | 1 | 4 | 3 |
| Prawdziwy superman | 2 | 2 | 5 |
Kiedy na zdjęciach faktycznie pojawił się bird 2 razy nie udało nam się tego przewidzieć. Jednocześnie nie udało nam się przewidzieć 2 razy plane i 4 razy superman .
Dlaczego otrzymuję komunikat o błędzie dotyczącym nie znalezienia klucza przewidywania?
Niektóre modele przedstawiają swoje przewidywania w formie słownika. Na przykład estymator TF dla problemu klasyfikacji binarnej generuje słownik zawierający probabilities , class_ids itp. W większości przypadków TFMA ma domyślne ustawienia wyszukiwania często używanych nazw kluczy, takich jak predictions , probabilities itp. Jednakże, jeśli Twój model jest bardzo dostosowany, może to klucze wyjściowe pod nazwami nieznanymi TFMA. W takich przypadkach do tfma.ModelSpec należy dodać ustawienie prediciton_key , aby zidentyfikować nazwę klucza, pod którym przechowywane są dane wyjściowe.