
Общий
Требуется ли еще EvalSavedModel?
Ранее TFMA требовала, чтобы все метрики хранились в графе тензорного потока с использованием специального EvalSavedModel . Теперь метрики можно вычислять вне графика TF с помощью реализаций beam.CombineFn .
Некоторые из основных отличий:
-
EvalSavedModelтребует специального экспорта из тренера, тогда как обслуживающую модель можно использовать без каких-либо изменений, необходимых для кода обучения. - При использовании
EvalSavedModelлюбые метрики, добавленные во время обучения, автоматически доступны во время оценки. БезEvalSavedModelэти метрики необходимо добавить повторно.- Исключением из этого правила является то, что если используется модель keras, метрики также могут быть добавлены автоматически, поскольку keras сохраняет информацию о метриках вместе с сохраненной моделью.
Может ли TFMA работать как с внутриграфовыми, так и с внешними метриками?
TFMA позволяет использовать гибридный подход, при котором некоторые метрики можно вычислять внутри графа, а другие можно вычислять снаружи. Если у вас уже есть EvalSavedModel , вы можете продолжать использовать ее.
Есть два случая:
- Используйте TFMA
EvalSavedModelкак для извлечения признаков, так и для расчета метрик, а также добавляйте дополнительные метрики на основе объединителя. В этом случае вы получите все метрики в графике изEvalSavedModelвместе с любыми дополнительными метриками из объединителя, которые могли ранее не поддерживаться. - Используйте TFMA
EvalSavedModelдля извлечения признаков/прогнозов, но используйте метрики на основе объединителя для всех вычислений метрик. Этот режим полезен, если вEvalSavedModelприсутствуют преобразования объектов, которые вы хотели бы использовать для срезов, но предпочитаете выполнять все вычисления метрик вне графика.
Настраивать
Какие типы моделей поддерживаются?
TFMA поддерживает модели keras, модели, основанные на общих API-интерфейсах подписи TF2, а также модели на основе оценщика TF (хотя в зависимости от варианта использования модели на основе оценщика могут потребовать использования EvalSavedModel ).
Полный список поддерживаемых типов моделей и ограничений см. в руководстве get_started.
Как настроить TFMA для работы с собственной моделью на основе кераса?
Ниже приведен пример конфигурации модели keras, основанный на следующих предположениях:
- Сохраненная модель предназначена для обслуживания и использует имя
serving_default(его можно изменить с помощьюmodel_specs[0].signature_name). - Должны быть оценены встроенные метрики из
model.compile(...)(это можно отключить с помощьюoptions.include_default_metricв tfma.EvalConfig ).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
См. метрики для получения дополнительной информации о других типах метрик, которые можно настроить.
Как настроить TFMA для работы с общей моделью на основе сигнатур TF2?
Ниже приведен пример конфигурации для общей модели TF2. Ниже signature_name — это имя конкретной подписи, которую следует использовать для оценки.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
См. метрики для получения дополнительной информации о других типах метрик, которые можно настроить.
Как настроить TFMA для работы с моделью на основе оценщика?
В этом случае есть три варианта.
Вариант 1. Использовать модель обслуживания
Если используется этот параметр, любые показатели, добавленные во время обучения, НЕ будут включены в оценку.
Ниже приведен пример конфигурации, предполагающий, что в качестве имени подписи serving_default :
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
См. метрики для получения дополнительной информации о других типах метрик, которые можно настроить.
Вариант 2. Используйте EvalSavedModel вместе с дополнительными метриками на основе объединителя.
В этом случае используйте EvalSavedModel для извлечения и оценки функций/прогнозов, а также добавьте дополнительные метрики на основе объединителя.
Ниже приведен пример конфигурации:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
См. метрики для получения дополнительной информации о других типах метрик, которые можно настроить, а также EvalSavedModel для получения дополнительных сведений о настройке EvalSavedModel.
Вариант 3. Используйте модель EvalSavedModel только для извлечения функций/прогнозов.
Аналогично варианту (2), но используйте EvalSavedModel только для извлечения признаков/прогнозов. Эта опция полезна, если требуются только внешние метрики, но есть преобразования признаков, которые вы хотели бы разделить. Как и в случае с вариантом (1), любые показатели, добавленные во время обучения, НЕ будут включены в оценку.
В этом случае конфигурация такая же, как и выше, только include_default_metrics отключен.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
См. метрики для получения дополнительной информации о других типах метрик, которые можно настроить, а также EvalSavedModel для получения дополнительных сведений о настройке EvalSavedModel.
Как настроить TFMA для работы с моделью на основе модели кераса?
Настройка keras model_to_estimator аналогична настройке оценщика. Однако есть несколько отличий, связанных с тем, как работает модель для оценки. В частности, модель-эсимтатор возвращает свои выходные данные в форме dict, где ключ dict — это имя последнего выходного слоя в связанной модели keras (если имя не указано, keras выберет для вас имя по умолчанию). например, dense_1 или output_1 ). С точки зрения TFMA, это поведение похоже на то, что будет выводиться для модели с несколькими выходами, даже если модель для оценки может относиться только к одной модели. Чтобы учесть эту разницу, требуется дополнительный шаг для настройки имени выхода. Однако в качестве оценщика применяются те же три параметра.
Ниже приведен пример изменений, необходимых для конфигурации на основе оценщика:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
Как настроить TFMA для работы с заранее рассчитанными (т. е. независимыми от модели) прогнозами? ( TFRecord и tf.Example )
Чтобы настроить TFMA для работы с предварительно рассчитанными прогнозами, tfma.PredictExtractor по умолчанию должен быть отключен, а tfma.InputExtractor должен быть настроен для анализа прогнозов вместе с другими входными функциями. Это достигается путем настройки tfma.ModelSpec с использованием имени функционального ключа, используемого для прогнозов, а также меток и весов.
Ниже приведен пример настройки:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
См. метрики для получения дополнительной информации о метриках, которые можно настроить.
Обратите внимание: хотя tfma.ModelSpec настраивается, модель фактически не используется (т. е. tfma.EvalSharedModel отсутствует). Вызов для запуска анализа модели может выглядеть следующим образом:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
Как настроить TFMA для работы с заранее рассчитанными (т. е. независимыми от модели) прогнозами? ( pd.DataFrame )
Для небольших наборов данных, которые могут поместиться в памяти, альтернативой TFRecord является pandas.DataFrame s. TFMA может работать с pandas.DataFrame с использованием API tfma.analyze_raw_data . Объяснение tfma.MetricsSpec и tfma.SlicingSpec см. в руководстве по установке . См. метрики для получения дополнительной информации о метриках, которые можно настроить.
Ниже приведен пример настройки:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
Метрики
Какие типы метрик поддерживаются?
TFMA поддерживает широкий спектр показателей, включая:
- метрики регрессии
- метрики двоичной классификации
- метрики классификации с несколькими классами и несколькими метками
- микросредние/макросредние показатели
- метрики на основе запроса/рейтинга
Поддерживаются ли метрики моделей с несколькими выходами?
Да. Более подробную информацию можно найти в руководстве по метрикам .
Поддерживаются ли метрики из нескольких моделей?
Да. Более подробную информацию можно найти в руководстве по метрикам .
Можно ли настроить параметры метрики (имя и т. д.)?
Да. Параметры метрик можно настроить (например, установить определенные пороговые значения и т. д.), добавив параметры config в конфигурацию метрик. Подробную информацию см. в руководстве по метрикам .
Поддерживаются ли специальные метрики?
Да. Либо написав собственную реализацию tf.keras.metrics.Metric , либо написав собственную реализацию beam.CombineFn . Руководство по метрикам содержит более подробную информацию.
Какие типы метрик не поддерживаются?
Пока ваша метрика может быть вычислена с помощью beam.CombineFn , нет никаких ограничений на типы метрик, которые можно вычислить на основе tfma.metrics.Metric . При работе с метрикой, полученной из tf.keras.metrics.Metric , должны соблюдаться следующие критерии:
- Должна быть возможность вычислить достаточную статистику для метрики в каждом примере независимо, затем объединить эту достаточную статистику, сложив ее по всем примерам, и определить значение метрики исключительно на основе этой достаточной статистики.
- Например, для точности достаточной статистикой являются «полностью правильные» и «полные примеры». Можно вычислить эти два числа для отдельных примеров и сложить их для группы примеров, чтобы получить правильные значения для этих примеров. Окончательную точность можно рассчитать, используя «общее количество правильных примеров/общее количество примеров».
Дополнения
Могу ли я использовать TFMA для оценки справедливости или предвзятости моей модели?
TFMA включает надстройку FairnessIndicators , которая предоставляет метрики после экспорта для оценки последствий непреднамеренной систематической ошибки в моделях классификации.
Кастомизация
Что делать, если мне нужна дополнительная настройка?
TFMA очень гибок и позволяет настраивать практически все части конвейера с помощью пользовательских Extractors , Evaluators и/или Writers . Эти абстракции более подробно обсуждаются в документе по архитектуре .
Устранение неполадок, отладка и получение помощи
Почему метрики MultiClassConfusionMatrix не совпадают с бинаризованными метриками ConfusionMatrix
На самом деле это разные расчеты. Бинаризация выполняет сравнение для каждого идентификатора класса независимо (т. е. прогноз для каждого класса сравнивается отдельно с предоставленными пороговыми значениями). В этом случае два или более классов могут указать, что они соответствуют прогнозу, поскольку их прогнозируемое значение превышает пороговое значение (это будет еще более очевидно при более низких пороговых значениях). В случае многоклассовой матрицы путаницы по-прежнему существует только одно истинное предсказанное значение, и оно либо соответствует фактическому значению, либо нет. Порог используется только для того, чтобы прогноз не соответствовал ни одному классу, если он меньше порога. Чем выше порог, тем труднее сопоставить прогноз бинаризованного класса. Аналогично, чем ниже порог, тем легче сопоставить предсказания бинаризованного класса. Это означает, что при порогах > 0,5 бинаризованные значения и значения матрицы мультикласса будут ближе друг к другу, а при порогах < 0,5 они будут дальше друг от друга.
Например, предположим, что у нас есть 10 классов, где класс 2 был предсказан с вероятностью 0,8, но фактический класс был классом 1 с вероятностью 0,15. Если вы выполняете бинаризацию по классу 1 и используете пороговое значение 0,1, то класс 1 будет считаться правильным (0,15 > 0,1), поэтому он будет считаться TP. Однако в случае мультикласса класс 2 будет считаться правильным (0,8 > 0,1). 0.1), и поскольку фактическим был класс 1, это будет считаться FN. Поскольку при более низких пороговых значениях больше значений будут считаться положительными, в целом количество TP и FP для бинаризованной матрицы путаницы будет выше, чем для многоклассовой матрицы путаницы, и аналогично более низкие значения TN и FN.
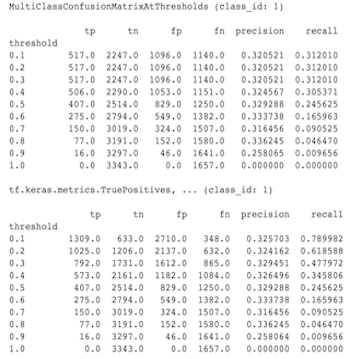
Ниже приведен пример наблюдаемых различий между MultiClassConfusionMatrixAtThresholds и соответствующими счетчиками при бинаризации одного из классов.
Почему мои показатели точности@1 и отзыва@1 имеют одинаковое значение?
При значении top k, равном 1, точность и отзыв — это одно и то же. Точность равна TP / (TP + FP) , а полнота равна TP / (TP + FN) . Верхний прогноз всегда положителен и будет либо соответствовать метке, либо не соответствовать ей. Другими словами, для N примеров TP + FP = N Однако, если метка не соответствует верхнему прогнозу, это также означает, что был сопоставлен прогноз, не являющийся верхним k, и если для верхнего k установлено значение 1, все прогнозы, не являющиеся верхними 1, будут равны 0. Это означает, что FN должно быть (N - TP) или N = TP + FN . Конечным результатом является precision@1 = TP / N = recall@1 . Обратите внимание, что это применимо только в том случае, если в каждом примере используется одна метка, а не несколько меток.
Почему мои показатели «mean_label» и «mean_prediction» всегда равны 0,5?
Скорее всего, это вызвано тем, что метрики настроены для задачи двоичной классификации, но модель выводит вероятности для обоих классов, а не только для одного. Это часто встречается при использовании API классификации tensorflow . Решение состоит в том, чтобы выбрать класс, на котором вы хотите, чтобы прогнозы были основаны, а затем бинаризировать этот класс. Например:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
Как интерпретировать MultiLabelConfusionMatrixPlot?
Учитывая конкретную метку, MultiLabelConfusionMatrixPlot (и связанный с ней MultiLabelConfusionMatrix ) можно использовать для сравнения результатов других меток и их прогнозов, когда выбранная метка действительно была верной. Например, предположим, что у нас есть три класса bird , plane и superman , и мы классифицируем изображения, чтобы указать, содержат ли они один или несколько из этих классов. MultiLabelConfusionMatrix вычисляет декартово произведение каждого фактического класса на каждый другой класс (называемый прогнозируемым классом). Обратите внимание, что хотя спаривание имеет вид (actual, predicted) , predicted класс не обязательно подразумевает положительный прогноз, он просто представляет прогнозируемый столбец в матрице фактического и прогнозируемого значений. Например, предположим, что мы вычислили следующие матрицы:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot имеет три способа отображения этих данных. Во всех случаях таблицу можно читать построчно с точки зрения реального класса.
1) Общее количество прогнозов
В этом случае для данной строки (т.е. фактического класса) каковы были значения TP + FP для других классов. Для приведенных выше подсчетов наше отображение будет следующим:
| Предсказанная птица | Прогнозируемый самолет | Предсказанный супермен | |
|---|---|---|---|
| Настоящая птица | 6 | 4 | 2 |
| Фактический самолет | 4 | 4 | 4 |
| Настоящий супермен | 5 | 5 | 4 |
Когда на картинках действительно была bird мы правильно предсказали 6 из них. В то же время мы также предсказали plane (верно или ошибочно) 4 раза и superman (верно или ошибочно) 2 раза.
2) Неправильный подсчет прогнозов
В этом случае для данной строки (т. е. фактического класса) каковы были значения FP для других классов. Для приведенных выше подсчетов наше отображение будет следующим:
| Предсказанная птица | Прогнозируемый самолет | Предсказанный супермен | |
|---|---|---|---|
| Настоящая птица | 0 | 2 | 1 |
| Фактический самолет | 1 | 0 | 3 |
| Настоящий супермен | 2 | 3 | 0 |
Когда на картинках действительно была bird мы 2 раза неверно предсказали plane и 1 раз superman .
3) Ложноотрицательный подсчет
В этом случае для данной строки (т.е. фактического класса) каковы были значения FN для других классов. Для приведенных выше подсчетов наше отображение будет следующим:
| Предсказанная птица | Прогнозируемый самолет | Предсказанный супермен | |
|---|---|---|---|
| Настоящая птица | 2 | 2 | 4 |
| Фактический самолет | 1 | 4 | 3 |
| Настоящий супермен | 2 | 2 | 5 |
Когда на картинках действительно была bird нам дважды не удалось ее предсказать. При этом нам не удалось предсказать plane 2 раза и superman 4 раза.
Почему я получаю сообщение о том, что ключ предсказания не найден?
Некоторые модели выводят свои предсказания в виде словаря. Например, оценщик TF для задачи двоичной классификации выводит словарь, содержащий probabilities , class_ids и т. д. В большинстве случаев TFMA имеет значения по умолчанию для поиска часто используемых имен ключей, таких как predictions , probabilities и т. д. Однако, если ваша модель очень настроена, она может выводить ключи под именами, неизвестными TFMA. В этих случаях в tfma.ModelSpec необходимо добавить параметр prediciton_key , чтобы определить имя ключа, под которым сохраняются выходные данные.