
টেনসরফ্লো সার্ভিং-এর কার্যকারিতা এটি যে অ্যাপ্লিকেশনটি চালায়, যে পরিবেশে এটি স্থাপন করা হয়েছে এবং অন্যান্য সফ্টওয়্যার যার সাথে এটি অন্তর্নিহিত হার্ডওয়্যার সংস্থানগুলিতে অ্যাক্সেস ভাগ করে তার উপর অত্যন্ত নির্ভরশীল। যেমন, এর পারফরম্যান্স টিউন করা কিছুটা কেস-নির্ভর এবং খুব কম সার্বজনীন নিয়ম রয়েছে যা সমস্ত সেটিংসে সর্বোত্তম কর্মক্ষমতা প্রদানের গ্যারান্টিযুক্ত। এটি বলার সাথে সাথে, এই নথির লক্ষ্য টেনসরফ্লো সার্ভিং চালানোর জন্য কিছু সাধারণ নীতি এবং সর্বোত্তম অনুশীলনগুলি ক্যাপচার করা।
অনুমান অনুরোধে আপনার মডেলের গণনার অন্তর্নিহিত আচরণ বুঝতে TensorBoard গাইড সহ প্রোফাইল ইনফরেন্স অনুরোধগুলি ব্যবহার করুন এবং এর কার্যকারিতাকে পুনরাবৃত্তিমূলকভাবে উন্নত করতে এই নির্দেশিকাটি ব্যবহার করুন।
দ্রুত টিপস
- প্রথম অনুরোধের বিলম্বিতা খুব বেশি? মডেল ওয়ার্মআপ সক্ষম করুন।
- উচ্চ সম্পদ ব্যবহার বা থ্রুপুট আগ্রহী? ব্যাচিং কনফিগার করুন
পারফরম্যান্স টিউনিং: উদ্দেশ্য এবং পরামিতি
TensorFlow Serving-এর পারফরম্যান্সকে ফাইন-টিউন করার সময়, সাধারণত আপনার কাছে 2 ধরনের উদ্দেশ্য থাকতে পারে এবং সেই উদ্দেশ্যগুলিকে উন্নত করার জন্য 3 টি প্যারামিটারের গ্রুপ থাকতে হবে।
উদ্দেশ্য
টেনসরফ্লো সার্ভিং মেশিন-লার্নড মডেলের জন্য একটি অনলাইন পরিবেশন ব্যবস্থা । অন্যান্য অনেক অনলাইন সার্ভিং সিস্টেমের মতো, এর প্রাথমিক কর্মক্ষমতা উদ্দেশ্য হল থ্রুপুটকে সর্বাধিক করা এবং নির্দিষ্ট সীমার নিচে লেল-লেটেন্সি রাখা । আপনার আবেদনের বিশদ বিবরণ এবং পরিপক্কতার উপর নির্ভর করে, আপনি tail-lateency এর চেয়ে গড় বিলম্বের বিষয়ে বেশি যত্নশীল হতে পারেন, কিন্তু কিছু লেটেন্সি এবং থ্রুপুট ধারণা সাধারণত সেই মেট্রিক যা আপনি কার্যক্ষমতার উদ্দেশ্য সেট করেন। মনে রাখবেন যে আমরা এই গাইডে প্রাপ্যতা নিয়ে আলোচনা করি না কারণ এটি স্থাপনার পরিবেশের আরও একটি ফাংশন।
পরামিতি
আমরা মোটামুটিভাবে প্যারামিটারের 3 টি গ্রুপ সম্পর্কে চিন্তা করতে পারি যার কনফিগারেশন পর্যবেক্ষণ করা কর্মক্ষমতা নির্ধারণ করে: 1) টেনসরফ্লো মডেল 2) অনুমান অনুরোধ এবং 3) সার্ভার (হার্ডওয়্যার এবং বাইনারি)।
1) টেনসরফ্লো মডেল
টেনসরফ্লো সার্ভিং প্রতিটি ইনকামিং অনুরোধ পাওয়ার পরে যে গণনাটি সম্পাদন করবে তা মডেলটি সংজ্ঞায়িত করে।
হুডের নিচে, TensorFlow সার্ভিং আপনার অনুরোধের প্রকৃত অনুমান করতে TensorFlow রানটাইম ব্যবহার করে। এর মানে হল TensorFlow সার্ভিং-এর মাধ্যমে একটি অনুরোধ পরিবেশনের গড় বিলম্বিতা সাধারণত কমপক্ষে TensorFlow-এর সাথে সরাসরি অনুমান করা হয়। এর মানে হল যদি একটি প্রদত্ত মেশিনে, একটি একক উদাহরণে অনুমান করতে 2 সেকেন্ড সময় লাগে এবং আপনার কাছে একটি সাব-সেকেন্ড লেটেন্সি টার্গেট থাকে, তাহলে আপনাকে অনুমানের অনুরোধগুলি প্রোফাইল করতে হবে, বুঝতে হবে কি TensorFlow অপস এবং আপনার মডেলের সাব-গ্রাফগুলি সেই লেটেন্সিতে সবচেয়ে বেশি অবদান রাখে , এবং মনের মধ্যে একটি নকশা সীমাবদ্ধতা হিসাবে অনুমান লেটেন্সি সহ আপনার মডেল পুনরায় ডিজাইন করুন৷
অনুগ্রহ করে মনে রাখবেন, TensorFlow সার্ভিং এর মাধ্যমে অনুমান করার গড় বিলম্ব সাধারণত TensorFlow ব্যবহার করার চেয়ে কম হয় না, যেখানে TensorFlow সার্ভিং অনেক ক্লায়েন্টের জন্য বিভিন্ন মডেলের অনুসন্ধানের জন্য টেল লেটেন্সি কমিয়ে রাখে, সব সময় থ্রুপুট সর্বাধিক করার জন্য অন্তর্নিহিত হার্ডওয়্যারকে দক্ষতার সাথে ব্যবহার করে .
2) অনুমান অনুরোধ
API সারফেস
TensorFlow Serving-এর দুটি API সারফেস রয়েছে (HTTP এবং gRPC), উভয়ই PredictionService API প্রয়োগ করে (HTTP সার্ভার বাদে MultiInference এন্ডপয়েন্ট প্রকাশ করে না)। উভয় এপিআই সারফেসই অত্যন্ত সুরক্ষিত এবং ন্যূনতম লেটেন্সি যোগ করে কিন্তু বাস্তবে, জিআরপিসি সারফেস কিছুটা বেশি পারফরম্যান্স দেখা যায়।
API পদ্ধতি
সাধারণভাবে, ক্লাসিফায়েড এবং রিগ্রেস এন্ডপয়েন্ট ব্যবহার করার পরামর্শ দেওয়া হয় কারণ তারা tf.Example গ্রহণ করে, যা একটি উচ্চ-স্তরের বিমূর্ততা; যাইহোক, বিরল ক্ষেত্রে বড় (O(Mb)) কাঠামোবদ্ধ অনুরোধের ক্ষেত্রে, বুদ্ধিমান ব্যবহারকারীরা PredictRequest ব্যবহার করে এবং তাদের Protobuf বার্তাগুলিকে একটি TensorProto-এ সরাসরি এনকোড করতে এবং tf থেকে সিরিয়ালাইজেশন এড়িয়ে যাওয়া এবং ডিসিরিয়ালাইজেশন এড়িয়ে যেতে পারে। উদাহরণ হল সামান্য কর্মক্ষমতা লাভের উৎস।
ব্যাচ আকার
ব্যাচিং আপনার কর্মক্ষমতা সাহায্য করতে পারে দুটি প্রাথমিক উপায় আছে. আপনি আপনার ক্লায়েন্টদের টেনসরফ্লো সার্ভিং-এ ব্যাচড অনুরোধ পাঠাতে কনফিগার করতে পারেন, অথবা আপনি পৃথক অনুরোধ পাঠাতে পারেন এবং একটি পূর্বনির্ধারিত সময় পর্যন্ত অপেক্ষা করার জন্য টেনসরফ্লো সার্ভিং কনফিগার করতে পারেন এবং সেই সময়ের মধ্যে একটি ব্যাচে আসা সমস্ত অনুরোধের অনুমান সম্পাদন করতে পারেন। পরের ধরনের ব্যাচিং কনফিগার করা আপনাকে টেনসরফ্লো সার্ভিংকে অত্যন্ত উচ্চ QPS-এ আঘাত করতে দেয়, যেখানে এটি বজায় রাখার জন্য প্রয়োজনীয় গণনা সংস্থানগুলিকে সাব-লিনিয়ারলি স্কেল করার অনুমতি দেয়। কনফিগারেশন গাইড এবং ব্যাচিং README- এ এটি আরও আলোচনা করা হয়েছে।
3) সার্ভার (হার্ডওয়্যার এবং বাইনারি)
টেনসরফ্লো সার্ভিং বাইনারি যে হার্ডওয়্যারের উপর এটি চলে তার মোটামুটি সুনির্দিষ্ট অ্যাকাউন্টিং করে। যেমন, আপনার একই মেশিনে অন্যান্য কম্পিউট- বা মেমরি-ইনটেনসিভ অ্যাপ্লিকেশানগুলি চালানো এড়াতে হবে, বিশেষত গতিশীল সম্পদ ব্যবহার সহ।
অন্যান্য অনেক ধরনের কাজের চাপের মতো, টেনসরফ্লো সার্ভিং আরও দক্ষ হয় যখন কম, বড় (বেশি সিপিইউ এবং র্যাম) মেশিনে মোতায়েন করা হয় (যেমন কুবারনেটের শর্তে নিম্ন replicas সহ একটি Deployment )। এটি হার্ডওয়্যার ব্যবহার করার জন্য মাল্টি-টেন্যান্ট স্থাপনার একটি ভাল সম্ভাবনা এবং কম নির্দিষ্ট খরচ (RPC সার্ভার, TensorFlow রানটাইম, ইত্যাদি) এর কারণে।
এক্সিলারেটর
যদি আপনার হোস্টের একটি এক্সেলারেটরে অ্যাক্সেস থাকে, তবে নিশ্চিত করুন যে আপনি অ্যাক্সিলারেটরে ঘন গণনা করার জন্য আপনার মডেলটি প্রয়োগ করেছেন - আপনি যদি উচ্চ-স্তরের টেনসরফ্লো API ব্যবহার করেন তবে এটি স্বয়ংক্রিয়ভাবে করা উচিত, তবে আপনি যদি কাস্টম গ্রাফ তৈরি করে থাকেন বা পিন করতে চান নির্দিষ্ট এক্সিলারেটরগুলিতে গ্রাফের নির্দিষ্ট অংশ, আপনাকে ম্যানুয়ালি কিছু সাবগ্রাফগুলিকে এক্সিলারেটরগুলিতে রাখতে হতে পারে (যেমন with tf.device('/device:GPU:0'): ... )।
আধুনিক সিপিইউ
আধুনিক CPUs SIMD (সিঙ্গেল ইন্সট্রাকশন মাল্টিপল ডেটা) এবং ঘন গণনার জন্য গুরুত্বপূর্ণ অন্যান্য বৈশিষ্ট্যগুলির জন্য সমর্থন উন্নত করতে x86 নির্দেশনা সেট আর্কিটেকচারকে ক্রমাগত প্রসারিত করেছে (যেমন একটি ঘড়ি চক্রে একটি গুণ এবং যোগ)। যাইহোক, সামান্য পুরানো মেশিনে চালানোর জন্য, TensorFlow এবং TensorFlow সার্ভিং এই বিনয়ী অনুমান নিয়ে তৈরি করা হয়েছে যে এই বৈশিষ্ট্যগুলির মধ্যে নতুনটি হোস্ট CPU দ্বারা সমর্থিত নয়।
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
আপনি যদি টেনসরফ্লো সার্ভিং স্টার্ট-আপে এই লগ এন্ট্রি (সম্ভবত তালিকাভুক্ত 2টির চেয়ে ভিন্ন এক্সটেনশন) দেখেন, তাহলে এর অর্থ হল আপনি টেনসরফ্লো সার্ভিং পুনর্নির্মাণ করতে পারেন এবং আপনার নির্দিষ্ট হোস্টের প্ল্যাটফর্মকে লক্ষ্য করে এবং আরও ভাল পারফরম্যান্স উপভোগ করতে পারেন। ডকার ব্যবহার করে উৎস থেকে টেনসরফ্লো পরিবেশন করা তুলনামূলকভাবে সহজ এবং এখানে নথিভুক্ত করা হয়েছে।
বাইনারি কনফিগারেশন
টেনসরফ্লো সার্ভিং অনেকগুলি কনফিগারেশন নব অফার করে যা তার রানটাইম আচরণকে নিয়ন্ত্রণ করে, বেশিরভাগ কমান্ড-লাইন পতাকার মাধ্যমে সেট করা হয়। এর মধ্যে কিছু (সবচেয়ে উল্লেখযোগ্যভাবে tensorflow_intra_op_parallelism এবং tensorflow_inter_op_parallelism ) TensorFlow রানটাইম কনফিগার করার জন্য পাস করা হয় এবং স্বয়ংক্রিয়ভাবে কনফিগার করা হয়, যা সচেতন ব্যবহারকারীরা অনেক পরীক্ষা-নিরীক্ষা করে এবং তাদের নির্দিষ্ট কাজের চাপ এবং পরিবেশের জন্য সঠিক কনফিগারেশন খুঁজে বের করে ওভাররাইড করতে পারে।
একটি টেনসরফ্লো পরিবেশন অনুমানের অনুরোধের জীবন
চলুন সংক্ষেপে টেনসরফ্লো সার্ভিং ইনফারেন্স রিকোয়েস্টের একটি প্রোটোটাইপিক্যাল উদাহরণের জীবনের মধ্য দিয়ে যাওয়া যাক যা একটি সাধারণ অনুরোধের মধ্য দিয়ে যায় তা দেখতে। আমাদের উদাহরণের জন্য, আমরা 2.0.0 TensorFlow সার্ভিং gRPC API পৃষ্ঠের দ্বারা প্রাপ্ত একটি পূর্বাভাস অনুরোধে ডুব দেব।
আসুন প্রথমে একটি কম্পোনেন্ট-লেভেল সিকোয়েন্স ডায়াগ্রাম দেখি, এবং তারপরে সেই কোডে ঝাঁপ দাও যা এই সিরিজের মিথস্ক্রিয়া বাস্তবায়ন করে।
তথ্যচিত্র
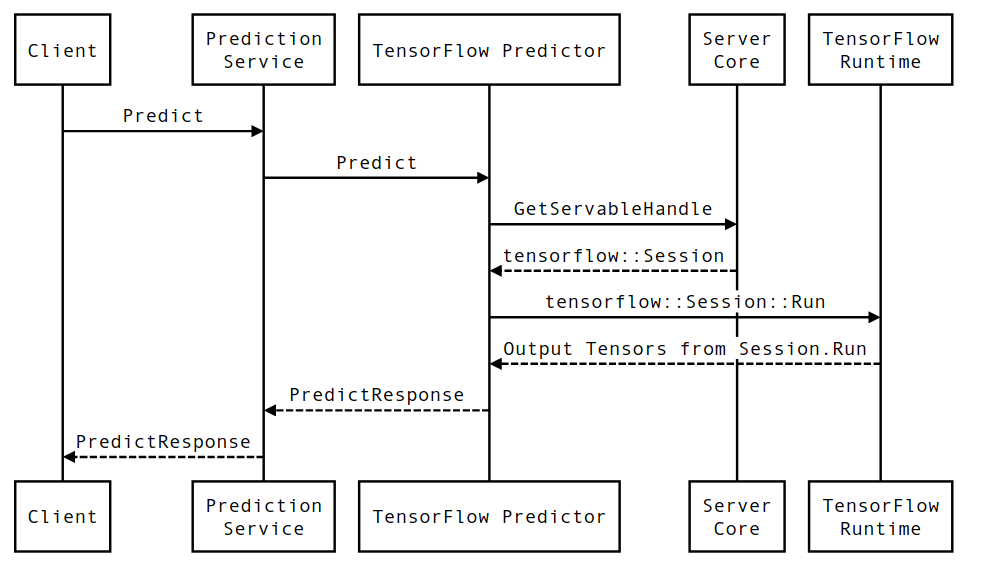
মনে রাখবেন যে ক্লায়েন্ট হল ব্যবহারকারীর মালিকানাধীন একটি উপাদান, ভবিষ্যদ্বাণী পরিষেবা, সার্ভেবলস এবং সার্ভার কোর টেনসরফ্লো সার্ভিংয়ের মালিকানাধীন এবং টেনসরফ্লো রানটাইম কোর টেনসরফ্লো- এর মালিকানাধীন।
ক্রম বিবরণ
-
PredictionServiceImpl::PredictPredictRequestগ্রহণ করে - আমরা
TensorflowPredictor::Predict, gRPC অনুরোধ থেকে অনুরোধের সময়সীমা প্রচার করে (যদি একটি সেট করা থাকে) আহ্বান করি। -
TensorflowPredictor::Predictএর ভিতরে, আমরা সার্ভেবল (মডেল) সন্ধান করি যে অনুরোধটি অনুমান সম্পাদন করতে চাইছে, যেখান থেকে আমরা সংরক্ষিত মডেল সম্পর্কে তথ্য পুনরুদ্ধার করি এবং আরও গুরুত্বপূর্ণভাবে,Sessionঅবজেক্টের একটি হ্যান্ডেল যেখানে মডেল গ্রাফটি (সম্ভবত আংশিকভাবে) লোড এই পরিবেশনযোগ্য বস্তুটি তৈরি করা হয়েছিল এবং মেমরিতে প্রতিশ্রুতিবদ্ধ হয়েছিল যখন মডেলটি টেনসরফ্লো সার্ভিং দ্বারা লোড করা হয়েছিল। আমরা তখন অভ্যন্তরীণ::রানপ্রেডিক্টকে ভবিষ্যদ্বাণী করতে আহ্বান করি। -
internal::RunPredictএ, অনুরোধটি যাচাইকরণ এবং প্রিপ্রসেস করার পরে, আমরা Session::Run- এ একটি ব্লকিং কল ব্যবহার করে অনুমান সম্পাদন করতেSessionঅবজেক্ট ব্যবহার করি, যেখানে আমরা মূল TensorFlow-এর কোডবেস প্রবেশ করি।Session::Runরিটার্নের পরে এবং আমাদেরoutputsটেনসরগুলি পপুলেট করা হয়েছে, আমরা আউটপুটগুলিকে একটিPredictionResponseরূপান্তর করি এবং ফলাফলটি কল স্ট্যাকের উপরে ফিরিয়ে দিই।