
Wydajność TensorFlow Serving w dużym stopniu zależy od uruchomionej aplikacji, środowiska, w którym jest wdrożona, oraz innego oprogramowania, z którym dzieli dostęp do podstawowych zasobów sprzętowych. W związku z tym dostrajanie jego wydajności zależy w pewnym stopniu od przypadku i istnieje bardzo niewiele uniwersalnych zasad, które gwarantują optymalną wydajność we wszystkich ustawieniach. Mając to na uwadze, niniejszy dokument ma na celu uchwycenie niektórych ogólnych zasad i najlepszych praktyk dotyczących obsługi TensorFlow.
Skorzystaj z przewodnika dotyczącego żądań wnioskowania profilu z TensorBoard, aby zrozumieć podstawowe zachowanie obliczeń modelu w przypadku żądań wnioskowania i skorzystaj z tego przewodnika, aby iteracyjnie poprawić jego wydajność.
Szybkie porady
- Opóźnienie pierwszego żądania jest zbyt duże? Włącz rozgrzewanie modelu .
- Interesuje Cię większe wykorzystanie zasobów lub przepustowość? Skonfiguruj przetwarzanie wsadowe
Strojenie wydajności: cele i parametry
Podczas dostrajania wydajności TensorFlow Serving zwykle można mieć 2 rodzaje celów i 3 grupy parametrów, które można dostosować, aby ulepszyć te cele.
Cele
TensorFlow Serving to internetowy system obsługi modeli uczących się maszynowo. Podobnie jak w przypadku wielu innych systemów serwowania online, jego głównym celem jest maksymalizacja przepustowości przy jednoczesnym utrzymaniu opóźnień końcowych poniżej pewnych granic . W zależności od szczegółów i dojrzałości aplikacji może bardziej zależeć Ci na średnim opóźnieniu niż na opóźnieniu końcowym , ale pewne pojęcia opóźnienia i przepustowości są zazwyczaj metrykami, na podstawie których ustalasz cele wydajności. Należy pamiętać, że w tym przewodniku nie omawiamy dostępności, ponieważ jest to raczej funkcja środowiska wdrażania.
Parametry
Możemy z grubsza pomyśleć o 3 grupach parametrów, których konfiguracja determinuje obserwowaną wydajność: 1) model TensorFlow 2) żądania wnioskowania i 3) serwer (sprzęt i plik binarny).
1) Model TensorFlow
Model definiuje obliczenia, które TensorFlow Serving wykona po otrzymaniu każdego przychodzącego żądania.
Pod maską TensorFlow Serving wykorzystuje środowisko wykonawcze TensorFlow do wyciągania rzeczywistych wniosków na temat Twoich żądań. Oznacza to, że średnie opóźnienie w obsłudze żądania za pomocą TensorFlow Serving jest zwykle co najmniej takie, jak w przypadku wnioskowania bezpośrednio za pomocą TensorFlow. Oznacza to, że jeśli na danej maszynie wnioskowanie na pojedynczym przykładzie zajmuje 2 sekundy, a docelowy poziom opóźnienia wynosi mniej niż sekundę, musisz sprofilować żądania wnioskowania, zrozumieć, które operacje TensorFlow i podgrafy Twojego modelu przyczyniają się najbardziej do tego opóźnienia i przeprojektuj swój model, mając na uwadze opóźnienie wnioskowania jako ograniczenie projektowe.
Należy pamiętać, że chociaż średnie opóźnienie wykonywania wnioskowania za pomocą TensorFlow Serving nie jest zwykle mniejsze niż przy bezpośrednim użyciu TensorFlow, gdzie TensorFlow Serving błyszczy, zmniejszając opóźnienie końcowe dla wielu klientów wysyłających zapytania do wielu różnych modeli, a wszystko to przy jednoczesnym efektywnym wykorzystaniu podstawowego sprzętu w celu maksymalizacji przepustowości .
2) Żądania wnioskowania
Powierzchnie API
TensorFlow Serving ma dwie powierzchnie API (HTTP i gRPC), z których obie implementują interfejs API PredictionService (z wyjątkiem serwera HTTP, który nie udostępnia punktu końcowego MultiInference ). Obie powierzchnie API są wysoce dostrojone i dodają minimalne opóźnienia, ale w praktyce powierzchnia gRPC jest nieco bardziej wydajna.
Metody API
Ogólnie rzecz biorąc, zaleca się używanie punktów końcowych Classify i Regress, ponieważ akceptują one tf.Example , co jest abstrakcją wyższego poziomu; jednakże w rzadkich przypadkach dużych żądań strukturalnych (O(Mb)) doświadczeni użytkownicy mogą znaleźć użycie PredictRequest i bezpośrednie kodowanie swoich komunikatów Protobuf do TensorProto oraz pomijanie serializacji do i deserializacji z tf. Przykład jest źródłem niewielkiego wzrostu wydajności.
Rozmiar partii
Istnieją dwa podstawowe sposoby, w jakie przetwarzanie wsadowe może poprawić wydajność. Możesz skonfigurować swoich klientów tak, aby wysyłali żądania zbiorcze do TensorFlow Serving lub możesz wysyłać indywidualne żądania i konfigurować TensorFlow Serving tak, aby czekał przez z góry określony czas i przeprowadzał wnioskowanie na temat wszystkich żądań przychodzących w tym okresie w jednej partii. Skonfigurowanie tego drugiego rodzaju przetwarzania wsadowego umożliwia uruchomienie usługi TensorFlow Serving z wyjątkowo dużą liczbą klatek na sekundę, umożliwiając jednocześnie subliniowe skalowanie zasobów obliczeniowych potrzebnych do dotrzymania kroku. Jest to szczegółowo omówione w przewodniku konfiguracji i pliku README dotyczącym przetwarzania wsadowego .
3) Serwer (sprzętowy i binarny)
Plik binarny TensorFlow Serving dość precyzyjnie rozlicza sprzęt, na którym działa. W związku z tym należy unikać uruchamiania innych aplikacji wymagających dużej mocy obliczeniowej lub pamięci na tym samym komputerze, szczególnie tych, które korzystają z zasobów dynamicznych.
Podobnie jak w przypadku wielu innych typów obciążeń, udostępnianie TensorFlow jest bardziej wydajne, gdy jest wdrażane na mniejszej liczbie, większych maszynach (z większym procesorem i pamięcią RAM) (tj. Deployment z mniejszą liczbą replicas w kategoriach Kubernetes). Wynika to z większego potencjału wdrożenia z wieloma dzierżawcami w celu wykorzystania sprzętu i niższych kosztów stałych (serwer RPC, środowisko wykonawcze TensorFlow itp.).
Akceleratory
Jeśli Twój host ma dostęp do akceleratora, upewnij się, że zaimplementowałeś swój model w celu umieszczenia gęstych obliczeń w akceleratorze — powinno to zostać zrobione automatycznie, jeśli korzystałeś z wysokopoziomowych interfejsów API TensorFlow, ale jeśli zbudowałeś niestandardowe wykresy lub chcesz przypiąć określonych części wykresów na określonych akceleratorach, może zaistnieć potrzeba ręcznego umieszczenia niektórych podgrafów na akceleratorach (tj. with tf.device('/device:GPU:0'): ... ).
Nowoczesne procesory
Nowoczesne procesory stale rozszerzają architekturę zestawu instrukcji x86, aby ulepszyć obsługę SIMD (Single Order Multiple Data) i innych funkcji krytycznych dla gęstych obliczeń (np. mnożenie i dodawanie w jednym cyklu zegara). Aby jednak działać na nieco starszych maszynach, TensorFlow i TensorFlow Serving są budowane przy skromnym założeniu, że najnowsze z tych funkcji nie są obsługiwane przez procesor hosta.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Jeśli zobaczysz ten wpis w dzienniku (prawdopodobnie inne rozszerzenia niż 2 wymienione) podczas uruchamiania TensorFlow Serving, oznacza to, że możesz odbudować TensorFlow Serving i skierować się na platformę konkretnego hosta i cieszyć się lepszą wydajnością. Budowanie obsługi TensorFlow ze źródła jest stosunkowo łatwe przy użyciu Dockera i jest udokumentowane tutaj .
Konfiguracja binarna
TensorFlow Serving oferuje szereg pokręteł konfiguracyjnych, które regulują zachowanie w czasie wykonywania, głównie ustawiane za pomocą flag wiersza poleceń . Niektóre z nich (w szczególności tensorflow_intra_op_parallelism i tensorflow_inter_op_parallelism ) są przekazywane w celu skonfigurowania środowiska wykonawczego TensorFlow i są konfigurowane automatycznie, co doświadczeni użytkownicy mogą obejść, wykonując wiele eksperymentów i znajdując odpowiednią konfigurację dla swojego konkretnego obciążenia i środowiska.
Życie żądania wnioskowania dotyczącego obsługi TensorFlow
Przyjrzyjmy się pokrótce działaniu prototypowego przykładu żądania wnioskowania TensorFlow Serving, aby zobaczyć, jaką podróż przechodzi typowe żądanie. W naszym przykładzie przyjrzymy się żądaniu prognozy odbieranemu przez powierzchnię API gRPC obsługującą TensorFlow w wersji 2.0.0.
Przyjrzyjmy się najpierw diagramowi sekwencji na poziomie komponentu, a następnie przejdźmy do kodu, który implementuje tę serię interakcji.
Diagram sekwencyjny
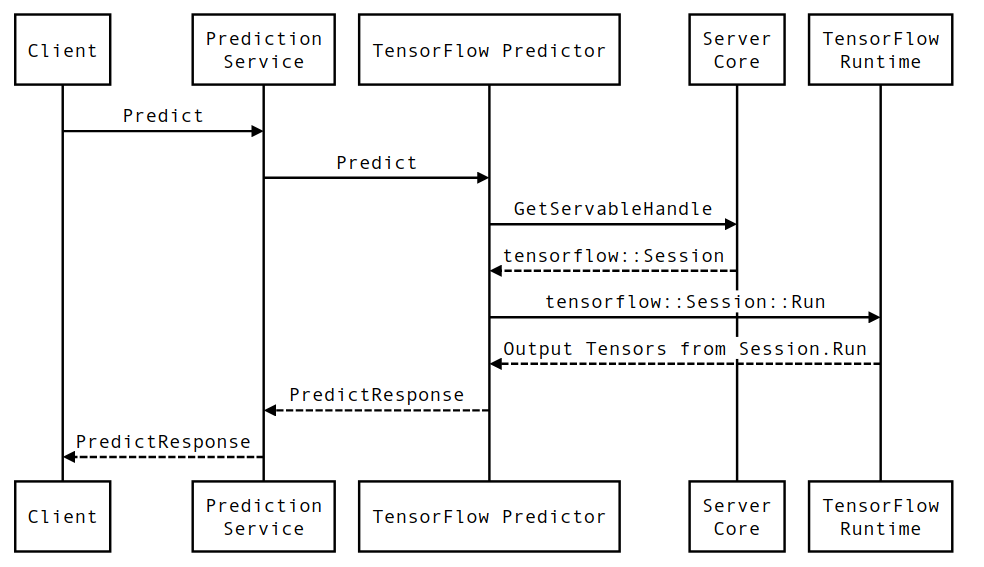
Należy pamiętać, że Klient jest komponentem należącym do użytkownika, usługa Prediction Service, Servables i Server Core są własnością TensorFlow Serving, a TensorFlow Runtime jest własnością Core TensorFlow .
Szczegóły sekwencji
-
PredictionServiceImpl::PredictodbieraPredictRequest - Wywołujemy
TensorflowPredictor::Predict, propagując termin żądania z żądania gRPC (jeśli taki został ustawiony). - Wewnątrz
TensorflowPredictor::Predictwyszukujemy Servable (model), na podstawie którego żądanie chce przeprowadzić wnioskowanie, z którego pobieramy informacje o SavedModel i, co ważniejsze, uchwyt do obiektuSession, w którym znajduje się wykres modelu (prawdopodobnie częściowo). załadowany. Ten obiekt Servable został utworzony i zatwierdzony w pamięci podczas ładowania modelu przez udostępnianie TensorFlow. Następnie wywołujemy funkcję internal::RunPredict w celu przeprowadzenia prognozy. - W
internal::RunPredictpo sprawdzeniu poprawności i wstępnym przetworzeniu żądania używamy obiektuSessionw celu przeprowadzenia wnioskowania za pomocą wywołania blokującego Session::Run , w którym to momencie wprowadzamy podstawową bazę kodu TensorFlow. Po powrocieSession::Runi wypełnieniu tensorówoutputskonwertujemy dane wyjściowe naPredictionResponsei zwracamy wynik na stos wywołań.