
Po wdrożeniu usługi TensorFlow Serving i wydaniu żądań od klienta możesz zauważyć, że żądania trwają dłużej niż oczekiwano lub nie osiągasz oczekiwanej przepustowości.
W tym przewodniku użyjemy Profilera TensorBoard, którego możesz już używać do profilowania uczenia modelu , aby śledzić żądania wnioskowania, aby pomóc nam w debugowaniu i ulepszaniu wydajności wnioskowania.
Powinieneś używać tego przewodnika w połączeniu z najlepszymi praktykami opisanymi w Przewodniku po wydajności , aby zoptymalizować swój model, żądania i instancję udostępniania TensorFlow.
Przegląd
Na wysokim poziomie wskażemy narzędzie profilowania TensorBoard na serwer gRPC TensorFlow Serving. Kiedy wyślemy żądanie wnioskowania do Tensorflow Serving, jednocześnie użyjemy interfejsu użytkownika TensorBoard, aby poprosić go o przechwycenie śladów tego żądania. Za kulisami TensorBoard porozmawia z TensorFlow Serving za pośrednictwem gRPC i poprosi go o szczegółowe śledzenie czasu życia żądania wnioskowania. TensorBoard będzie następnie wizualizować aktywność każdego wątku na każdym urządzeniu obliczeniowym (uruchamiający kod zintegrowany z profiler::TraceMe ) przez cały okres istnienia żądania w interfejsie użytkownika TensorBoard, abyśmy mogli je wykorzystać.
Warunki wstępne
-
Tensorflow>=2.0.0 - TensorBoard (należy zainstalować, jeśli TF został zainstalowany przez
pip) - Docker (którego użyjemy do pobrania i uruchomienia obrazu TF>=2.1.0)
Wdróż model za pomocą usługi TensorFlow Serving
W tym przykładzie użyjemy Dockera, zalecanego sposobu wdrożenia Tensorflow Serving, do hostowania modelu zabawki, który oblicza f(x) = x / 2 + 2 znalezionego w repozytorium Tensorflow Serving Github .
Pobierz źródło udostępniania TensorFlow.
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
Uruchom obsługę TensorFlow za pośrednictwem platformy Docker i wdróż model half_plus_two.
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
W innym terminalu wykonaj zapytanie dotyczące modelu, aby upewnić się, że model został poprawnie wdrożony
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
Skonfiguruj Profiler TensorBoard
W innym terminalu uruchom narzędzie TensorBoard na swoim komputerze, udostępniając katalog do zapisywania zdarzeń śledzenia wnioskowania w:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
Przejdź do http://localhost:6006/, aby wyświetlić interfejs użytkownika TensorBoard. Użyj menu rozwijanego u góry, aby przejść do karty Profil. Kliknij opcję Przechwyć profil i podaj adres serwera gRPC Tensorflow Serving.
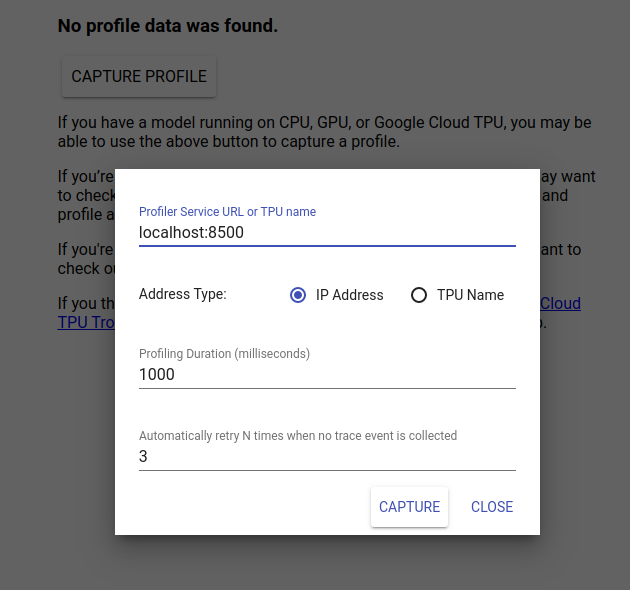
Gdy tylko naciśniesz „Przechwyć”, TensorBoard rozpocznie wysyłanie żądań profilu do serwera modelu. W powyższym oknie dialogowym możesz ustawić zarówno ostateczny termin dla każdego żądania, jak i całkowitą liczbę ponownych prób Tensorboard, jeśli nie zostaną zebrane żadne zdarzenia śledzenia. Jeśli profilujesz kosztowny model, możesz wydłużyć termin, aby mieć pewność, że żądanie profilu nie przekroczy limitu czasu przed zakończeniem żądania wnioskowania.
Wyślij i sprofiluj żądanie wnioskowania
Naciśnij Przechwyć w interfejsie użytkownika TensorBoard i szybko wyślij żądanie wnioskowania do TF Serving.
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
Powinieneś zobaczyć komunikat „Pomyślnie przechwyć profil. Odśwież”. tosty pojawią się na dole ekranu. Oznacza to, że TensorBoard był w stanie pobrać zdarzenia śledzenia z TensorFlow Serving i zapisać je w logdir . Odśwież stronę, aby zwizualizować żądanie wnioskowania za pomocą przeglądarki Trace Viewer programu Profiler, jak pokazano w następnej sekcji.
Przeanalizuj ślad żądania wnioskowania

Możesz teraz łatwo zobaczyć, jakie obliczenia mają miejsce w wyniku żądania wnioskowania. Możesz powiększyć i kliknąć dowolny prostokąt (śledzenie zdarzeń), aby uzyskać więcej informacji, takich jak dokładny czas rozpoczęcia i czas trwania ściany.
Na wysokim poziomie widzimy dwa wątki należące do środowiska uruchomieniowego TensorFlow i trzeci należący do serwera REST, obsługujący odbiór żądania HTTP i tworzący sesję TensorFlow.
Możemy powiększyć, aby zobaczyć, co dzieje się wewnątrz SessionRun.

W drugim wątku widzimy początkowe wywołanie ExecutorState::Process, w którym nie są uruchamiane żadne operacje TensorFlow, ale wykonywane są kroki inicjujące.
W pierwszym wątku widzimy wywołanie odczytu pierwszej zmiennej, a gdy druga zmienna jest już dostępna, wykonuje mnożenie i po kolei dodaje jądra. Na koniec Executor sygnalizuje, że obliczenia zostały wykonane poprzez wywołanie DoneCallback i sesja może zostać zamknięta.
Następne kroki
Chociaż jest to prosty przykład, możesz użyć tego samego procesu do profilowania znacznie bardziej złożonych modeli, co pozwoli Ci zidentyfikować powolne operacje lub wąskie gardła w architekturze modelu i poprawić jego wydajność.
Pełniejszy samouczek dotyczący funkcji TensorBoard Profiler i Przewodnik po wydajności obsługi TensorFlow można znaleźć w Przewodniku po profilowaniu TensorBoard, aby dowiedzieć się więcej na temat optymalizacji wydajności wnioskowania.