
এই টিউটোরিয়ালটি আপনাকে দেখায় কিভাবে মেশিন লার্নিং (ML) এর জন্য ডেটা প্রিপ্রসেসিং বাস্তবায়ন করতে TensorFlow Transform ( tf.Transform লাইব্রেরি) ব্যবহার করতে হয়। TensorFlow-এর জন্য tf.Transform লাইব্রেরি আপনাকে ডেটা প্রি-প্রসেসিং পাইপলাইনের মাধ্যমে ইনস্ট্যান্স-লেভেল এবং ফুল-পাস ডেটা ট্রান্সফর্মেশন উভয়ই সংজ্ঞায়িত করতে দেয়। এই পাইপলাইনগুলি দক্ষতার সাথে Apache Beam এর সাথে কার্যকর করা হয় এবং তারা উপজাত হিসাবে একটি TensorFlow গ্রাফ তৈরি করে যাতে ভবিষ্যদ্বাণীর সময় একই রূপান্তর প্রয়োগ করা হয় যখন মডেলটি পরিবেশন করা হয়।
এই টিউটোরিয়ালটি Apache Beam-এর জন্য একটি রানার হিসাবে Dataflow ব্যবহার করে একটি এন্ড-টু-এন্ড উদাহরণ প্রদান করে। এটা ধরে নেয় যে আপনি BigQuery , Dataflow, Vertex AI , এবং TensorFlow Keras API-এর সাথে পরিচিত। এটি অনুমান করে যে আপনার জুপিটার নোটবুকগুলি ব্যবহার করার কিছু অভিজ্ঞতা আছে, যেমন Vertex AI Workbench এর সাথে।
এই টিউটোরিয়ালটি অনুমান করে যে আপনি Google ক্লাউডে প্রিপ্রসেসিং ধরন, চ্যালেঞ্জ এবং বিকল্পগুলির ধারণার সাথে পরিচিত, যেমনটি ML-এর জন্য ডেটা প্রিপ্রসেসিং-এ বর্ণিত হয়েছে: বিকল্প এবং সুপারিশ ।
উদ্দেশ্য
-
tf.Transformলাইব্রেরি ব্যবহার করে Apache Beam পাইপলাইন বাস্তবায়ন করুন। - ডেটাফ্লোতে পাইপলাইন চালান।
-
tf.Transformলাইব্রেরি ব্যবহার করে TensorFlow মডেলটি প্রয়োগ করুন। - প্রশিক্ষণ দিন এবং ভবিষ্যদ্বাণীর জন্য মডেলটি ব্যবহার করুন।
খরচ
এই টিউটোরিয়ালটি Google ক্লাউডের নিম্নলিখিত বিলযোগ্য উপাদানগুলি ব্যবহার করে:
এই টিউটোরিয়ালটি চালানোর জন্য খরচ অনুমান করতে, ধরে নিই যে আপনি একটি পুরো দিনের জন্য প্রতিটি সংস্থান ব্যবহার করছেন, প্রাক কনফিগার করা মূল্য ক্যালকুলেটর ব্যবহার করুন।
আপনি শুরু করার আগে
Google ক্লাউড কনসোলে, প্রকল্প নির্বাচক পৃষ্ঠায়, একটি Google ক্লাউড প্রকল্প নির্বাচন করুন বা তৈরি করুন ।
নিশ্চিত করুন যে আপনার ক্লাউড প্রকল্পের জন্য বিলিং সক্ষম করা আছে৷ একটি প্রকল্পে বিলিং সক্ষম কিনা তা পরীক্ষা করতে শিখুন।
Dataflow, Vertex AI, এবং Notebooks APIs সক্ষম করুন। APIs সক্রিয় করুন
এই সমাধানের জন্য জুপিটার নোটবুক
নিম্নলিখিত জুপিটার নোটবুকগুলি বাস্তবায়নের উদাহরণ দেখায়:
- নোটবুক 1 ডেটা প্রিপ্রসেসিং কভার করে। বিস্তারিত পরে Apache Beam পাইপলাইন বাস্তবায়ন বিভাগে প্রদান করা হয়েছে।
- নোটবুক 2 মডেল প্রশিক্ষণ কভার করে। বিস্তারিত টেনসরফ্লো মডেল বিভাগে পরে দেওয়া হয়েছে।
নিম্নলিখিত বিভাগগুলিতে, আপনি এই নোটবুকগুলিকে ক্লোন করেন, এবং তারপর আপনি কীভাবে বাস্তবায়ন উদাহরণ কাজ করে তা শিখতে নোটবুকগুলি চালান৷
একটি ব্যবহারকারী-পরিচালিত নোটবুক উদাহরণ চালু করুন
Google ক্লাউড কনসোলে, Vertex AI Workbench পৃষ্ঠায় যান।
ব্যবহারকারী-পরিচালিত নোটবুক ট্যাবে, +নতুন নোটবুক-এ ক্লিক করুন।
উদাহরণ টাইপের জন্য GPU ছাড়া TensorFlow Enterprise 2.8 (LTS সহ) নির্বাচন করুন।
তৈরি করুন ক্লিক করুন।
আপনি নোটবুক তৈরি করার পর, JupyterLab-এ প্রক্সি শুরু করার জন্য অপেক্ষা করুন। এটি প্রস্তুত হলে, ওপেন JupyterLab নোটবুকের নামের পাশে প্রদর্শিত হয়।
নোটবুক ক্লোন করুন
ব্যবহারকারী-পরিচালিত নোটবুক ট্যাবে , নোটবুকের নামের পাশে, JupyterLab খুলুন ক্লিক করুন। JupyterLab ইন্টারফেস একটি নতুন ট্যাবে খোলে।
JupyterLab একটি বিল্ড প্রস্তাবিত ডায়ালগ প্রদর্শন করলে, প্রস্তাবিত বিল্ড প্রত্যাখ্যান করতে বাতিল ক্লিক করুন।
লঞ্চার ট্যাবে, টার্মিনাল ক্লিক করুন।
টার্মিনাল উইন্ডোতে, নোটবুকটি ক্লোন করুন:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Apache Beam পাইপলাইন বাস্তবায়ন করুন
এই বিভাগটি এবং পরবর্তী বিভাগটি রান দ্য পাইপলাইন ইন ডেটাফ্লো নোটবুক 1 এর জন্য একটি ওভারভিউ এবং প্রসঙ্গ প্রদান করে। নোটবুকটি ডেটা প্রিপ্রসেস করতে tf.Transform লাইব্রেরি কীভাবে ব্যবহার করতে হয় তা বর্ণনা করার জন্য একটি বাস্তব উদাহরণ প্রদান করে। এই উদাহরণটি Natality ডেটাসেট ব্যবহার করে, যা বিভিন্ন ইনপুটের উপর ভিত্তি করে শিশুর ওজনের পূর্বাভাস দিতে ব্যবহৃত হয়। BigQuery-এর সর্বজনীন জন্মের সারণীতে ডেটা সংরক্ষণ করা হয়।
নোটবুক 1 চালান
JupyterLab ইন্টারফেসে, File > Open from path এ ক্লিক করুন এবং তারপর নিম্নলিখিত পথটি প্রবেশ করান:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbসম্পাদনা করুন > সমস্ত আউটপুট সাফ করুন ক্লিক করুন।
প্রয়োজনীয় প্যাকেজ ইনস্টল করুন বিভাগে,
pip install apache-beamকমান্ড চালানোর জন্য প্রথম সেলটি চালান।আউটপুটের শেষ অংশটি নিম্নরূপ:
Successfully installed ...আপনি আউটপুট নির্ভরতা ত্রুটি উপেক্ষা করতে পারেন. আপনাকে এখনও কার্নেল পুনরায় চালু করতে হবে না।
pip install tensorflow-transformকমান্ড চালানোর জন্য দ্বিতীয় ঘরটি চালান। আউটপুটের শেষ অংশটি নিম্নরূপ:Successfully installed ... Note: you may need to restart the kernel to use updated packages.আপনি আউটপুট নির্ভরতা ত্রুটি উপেক্ষা করতে পারেন.
কার্নেল > রিস্টার্ট কার্নেল ক্লিক করুন।
ইনস্টল করা প্যাকেজগুলি নিশ্চিত করুন এবং ডেটাফ্লো কন্টেইনার বিভাগে প্যাকেজগুলি ইনস্টল করতে setup.py তৈরি করুন-এ সেলগুলি চালান।
সেট গ্লোবাল পতাকা বিভাগে,
PROJECTএবংBUCKETপাশে,your-projectআপনার ক্লাউড প্রকল্প আইডি দিয়ে প্রতিস্থাপন করুন এবং তারপরে সেলটি চালান।নোটবুকের শেষ কক্ষের মাধ্যমে অবশিষ্ট কোষগুলি চালান। প্রতিটি কক্ষে কি করতে হবে সে সম্পর্কে তথ্যের জন্য, নোটবুকের নির্দেশাবলী দেখুন।
পাইপলাইনের ওভারভিউ
নোটবুকের উদাহরণে, ডেটাফ্লো ডেটা প্রস্তুত করতে এবং রূপান্তর শিল্পকর্ম তৈরি করতে স্কেলে tf.Transform পাইপলাইন চালায়। এই নথির পরবর্তী বিভাগগুলি সেই ফাংশনগুলি বর্ণনা করে যা পাইপলাইনের প্রতিটি ধাপ সম্পাদন করে। পাইপলাইনের সামগ্রিক পদক্ষেপগুলি নিম্নরূপ:
- BigQuery থেকে প্রশিক্ষণের ডেটা পড়ুন।
-
tf.Transformলাইব্রেরি ব্যবহার করে প্রশিক্ষণ ডেটা বিশ্লেষণ এবং রূপান্তর করুন। - TFRecord ফরম্যাটে ক্লাউড স্টোরেজে রূপান্তরিত প্রশিক্ষণ ডেটা লিখুন।
- BigQuery থেকে মূল্যায়ন ডেটা পড়ুন।
- ধাপ 2 দ্বারা উত্পাদিত
transform_fnগ্রাফ ব্যবহার করে মূল্যায়ন ডেটা রূপান্তর করুন। - TFRecord ফরম্যাটে ক্লাউড স্টোরেজে রূপান্তরিত প্রশিক্ষণ ডেটা লিখুন।
- ক্লাউড সঞ্চয়স্থানে রূপান্তর নিদর্শনগুলি লিখুন যা পরে মডেল তৈরি এবং রপ্তানি করার জন্য ব্যবহার করা হবে৷
নিম্নলিখিত উদাহরণটি সামগ্রিক পাইপলাইনের জন্য পাইথন কোড দেখায়। অনুসরণ করা বিভাগগুলি প্রতিটি ধাপের জন্য ব্যাখ্যা এবং কোড তালিকা প্রদান করে।
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
BigQuery থেকে অশোধিত প্রশিক্ষণ ডেটা পড়ুন
প্রথম ধাপ হল read_from_bq ফাংশন ব্যবহার করে BigQuery থেকে অশোধিত প্রশিক্ষণের ডেটা পড়া। এই ফাংশনটি একটি raw_dataset অবজেক্ট প্রদান করে যা BigQuery থেকে বের করা হয়। আপনি একটি data_size মান পাস করেন এবং train বা eval একটি step মান পাস করেন। BigQuery সোর্স কোয়েরি get_source_query ফাংশন ব্যবহার করে তৈরি করা হয়েছে, যেমনটি নিম্নলিখিত উদাহরণে দেখানো হয়েছে:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
আপনি tf.Transform প্রিপ্রসেসিং সম্পাদন করার আগে, আপনাকে মানচিত্র, ফিল্টার, গ্রুপ এবং উইন্ডো প্রক্রিয়াকরণ সহ সাধারণ Apache Beam-ভিত্তিক প্রক্রিয়াকরণ করতে হবে। উদাহরণে, কোডটি beam.Map(prep_bq_row) পদ্ধতি ব্যবহার করে BigQuery থেকে পড়া রেকর্ডগুলি পরিষ্কার করে, যেখানে prep_bq_row একটি কাস্টম ফাংশন। এই কাস্টম ফাংশনটি একটি শ্রেণীবদ্ধ বৈশিষ্ট্যের জন্য সংখ্যাসূচক কোডকে মানব-পঠনযোগ্য লেবেলে রূপান্তর করে।
এছাড়াও, BigQuery থেকে নিষ্কাশিত raw_data অবজেক্ট বিশ্লেষণ এবং রূপান্তর করতে tf.Transform লাইব্রেরি ব্যবহার করতে, আপনাকে একটি raw_dataset অবজেক্ট তৈরি করতে হবে, যা raw_data এবং raw_metadata অবজেক্টের একটি টিপল। raw_metadata অবজেক্টটি create_raw_metadata ফাংশন ব্যবহার করে তৈরি করা হয়েছে, নিম্নরূপ:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
আপনি যখন নোটবুকে সেলটি চালান যা অবিলম্বে এই পদ্ধতিটি সংজ্ঞায়িত সেলটিকে অনুসরণ করে, raw_metadata.schema অবজেক্টের বিষয়বস্তু প্রদর্শিত হয়। এটি নিম্নলিখিত কলামগুলি অন্তর্ভুক্ত করে:
-
gestation_weeks(প্রকার:FLOAT) -
is_male(প্রকার:BYTES) -
mother_age(প্রকার:FLOAT) -
mother_race(প্রকার:BYTES) -
plurality(প্রকার:FLOAT) -
weight_pounds(প্রকার:FLOAT)
কাঁচা প্রশিক্ষণ তথ্য রূপান্তর
কল্পনা করুন যে আপনি ML-এর জন্য প্রস্তুত করার জন্য প্রশিক্ষণ ডেটার ইনপুট কাঁচা বৈশিষ্ট্যগুলিতে সাধারণ প্রিপ্রসেসিং রূপান্তরগুলি প্রয়োগ করতে চান। এই রূপান্তরগুলির মধ্যে পূর্ণ-পাস এবং ইনস্ট্যান্স-স্তরের ক্রিয়াকলাপ উভয়ই অন্তর্ভুক্ত, যেমনটি নিম্নলিখিত সারণীতে দেখানো হয়েছে:
| ইনপুট বৈশিষ্ট্য | রূপান্তর | পরিসংখ্যান প্রয়োজন | টাইপ | আউটপুট বৈশিষ্ট্য |
|---|---|---|---|---|
weight_pound | কোনোটিই নয় | কোনোটিই নয় | এন.এ | weight_pound |
mother_age | স্বাভাবিক করা | মানে, var | ফুল-পাস | mother_age_normalized |
mother_age | সমান আকার bucketization | কোয়ান্টাইল | ফুল-পাস | mother_age_bucketized |
mother_age | লগ গণনা | কোনোটিই নয় | দৃষ্টান্ত-স্তর | mother_age_log |
plurality | এটি একক বা একাধিক শিশু কিনা তা নির্দেশ করুন | কোনোটিই নয় | দৃষ্টান্ত-স্তর | is_multiple |
is_multiple | নামমাত্র মানকে সংখ্যাসূচক সূচকে রূপান্তর করুন | শব্দ | ফুল-পাস | is_multiple_index |
gestation_weeks | 0 এবং 1 এর মধ্যে স্কেল করুন | সর্বনিম্ন, সর্বোচ্চ | ফুল-পাস | gestation_weeks_scaled |
mother_race | নামমাত্র মানকে সংখ্যাসূচক সূচকে রূপান্তর করুন | শব্দ | ফুল-পাস | mother_race_index |
is_male | নামমাত্র মানকে সংখ্যাসূচক সূচকে রূপান্তর করুন | শব্দ | ফুল-পাস | is_male_index |
এই রূপান্তরগুলি একটি preprocess_fn ফাংশনে প্রয়োগ করা হয়, যা tensors ( input_features ) এর একটি অভিধান আশা করে এবং প্রক্রিয়াকৃত বৈশিষ্ট্যগুলির একটি অভিধান ( output_features ) প্রদান করে।
নিম্নলিখিত কোড tf.Transform ফুল-পাস ট্রান্সফরমেশন এপিআই ( tft. এর সাথে উপসর্গযুক্ত), এবং TensorFlow ( tf. এর সাথে উপসর্গযুক্ত) ইনস্ট্যান্স-লেভেল অপারেশন ব্যবহার করে preprocess_fn ফাংশনের বাস্তবায়ন দেখায়:
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
tf.Transform ফ্রেমওয়ার্কের পূর্ববর্তী উদাহরণের সাথে আরও অনেকগুলি রূপান্তর রয়েছে, যা নিম্নোক্ত সারণীতে তালিকাভুক্ত রয়েছে:
| রূপান্তর | প্রযোজ্য | বর্ণনা |
|---|---|---|
scale_by_min_max | সংখ্যাসূচক বৈশিষ্ট্য | একটি সংখ্যাসূচক কলামকে পরিসরে স্কেল করে [ output_min , output_max ] |
scale_to_0_1 | সংখ্যাসূচক বৈশিষ্ট্য | একটি কলাম ফেরত দেয় যা পরিসীমা [ 0 , 1 ] এর জন্য স্কেল করা ইনপুট কলাম। |
scale_to_z_score | সংখ্যাসূচক বৈশিষ্ট্য | গড় 0 এবং প্রকরণ 1 সহ একটি প্রমিত কলাম প্রদান করে |
tfidf | পাঠ্য বৈশিষ্ট্য | x- এ পদগুলিকে তাদের টার্ম ফ্রিকোয়েন্সি * ইনভার্স ডকুমেন্ট ফ্রিকোয়েন্সিতে ম্যাপ করে |
compute_and_apply_vocabulary | শ্রেণীবদ্ধ বৈশিষ্ট্য | একটি শ্রেণীবদ্ধ বৈশিষ্ট্যের জন্য একটি শব্দভান্ডার তৈরি করে এবং এই শব্দের সাথে একটি পূর্ণসংখ্যার সাথে মানচিত্র তৈরি করে |
ngrams | পাঠ্য বৈশিষ্ট্য | n-গ্রামের একটি SparseTensor তৈরি করে |
hash_strings | শ্রেণীবদ্ধ বৈশিষ্ট্য | Hashes বালতি মধ্যে স্ট্রিং |
pca | সংখ্যাসূচক বৈশিষ্ট্য | পক্ষপাতদুষ্ট কোভেরিয়েন্স ব্যবহার করে ডেটাসেটে PCA গণনা করে |
bucketize | সংখ্যাসূচক বৈশিষ্ট্য | প্রতিটি ইনপুটে বরাদ্দ করা একটি বালতি সূচক সহ একটি সমান-আকারের (পরিমাণ-ভিত্তিক) বালতিযুক্ত কলাম প্রদান করে |
পাইপলাইনের পূর্ববর্তী ধাপে উত্পাদিত raw_train_dataset অবজেক্টে preprocess_fn ফাংশনে বাস্তবায়িত রূপান্তরগুলি প্রয়োগ করার জন্য, আপনি AnalyzeAndTransformDataset পদ্ধতি ব্যবহার করেন। এই পদ্ধতিটি ইনপুট হিসাবে raw_dataset অবজেক্টের প্রত্যাশা করে, preprocess_fn ফাংশন প্রয়োগ করে এবং এটি transformed_dataset অবজেক্ট এবং transform_fn গ্রাফ তৈরি করে। নিম্নলিখিত কোড এই প্রক্রিয়াকরণ চিত্রিত করে:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
রূপান্তরগুলি দুটি পর্যায়ে কাঁচা ডেটাতে প্রয়োগ করা হয়: বিশ্লেষণ পর্যায় এবং রূপান্তর পর্ব। চিত্র 3 পরে এই নথিতে দেখায় কিভাবে AnalyzeAndTransformDataset পদ্ধতি AnalyzeDataset পদ্ধতি এবং TransformDataset পদ্ধতিতে পচে যায়।
বিশ্লেষণ পর্ব
বিশ্লেষণ পর্বে, রূপান্তরের জন্য প্রয়োজনীয় পরিসংখ্যানগুলি গণনা করার জন্য কাঁচা প্রশিক্ষণের ডেটা সম্পূর্ণ-পাস প্রক্রিয়ায় বিশ্লেষণ করা হয়। এর মধ্যে রয়েছে গড়, প্রকরণ, সর্বনিম্ন, সর্বোচ্চ, পরিমাণ এবং শব্দভাণ্ডার গণনা করা। বিশ্লেষণ প্রক্রিয়াটি একটি কাঁচা ডেটাসেট (কাঁচা ডেটা প্লাস কাঁচা মেটাডেটা) আশা করে এবং এটি দুটি আউটপুট তৈরি করে:
-
transform_fn: একটি টেনসরফ্লো গ্রাফ যা বিশ্লেষণ পর্ব থেকে গণনাকৃত পরিসংখ্যান এবং ট্রান্সফরমেশন লজিক (যা পরিসংখ্যান ব্যবহার করে) উদাহরণ-স্তরের ক্রিয়াকলাপ হিসাবে ধারণ করে। সেভ দ্য গ্রাফ -এ পরে আলোচনা করা হয়েছে,transform_fnগ্রাফ মডেলserving_fnফাংশনের সাথে সংযুক্ত করার জন্য সংরক্ষণ করা হয়েছে। এটি অনলাইন পূর্বাভাস ডেটা পয়েন্টগুলিতে একই রূপান্তর প্রয়োগ করা সম্ভব করে তোলে। -
transform_metadata: একটি বস্তু যা রূপান্তরের পরে ডেটার প্রত্যাশিত স্কিমা বর্ণনা করে।
বিশ্লেষণ পর্বটি নিম্নলিখিত চিত্র, চিত্র 1-এ চিত্রিত করা হয়েছে:

tf.Transform বিশ্লেষণ পর্ব। tf.Transform বিশ্লেষকগুলির মধ্যে রয়েছে min , max , sum , size , mean , var , covariance , quantiles , vocabulary , এবং pca ।
রূপান্তর পর্ব
ট্রান্সফর্ম ফেজে, transform_fn গ্রাফ যা বিশ্লেষণ ফেজ দ্বারা উত্পাদিত হয় তা রুপান্তরিত প্রশিক্ষণ ডেটা তৈরি করার জন্য একটি ইনস্ট্যান্স-লেভেল প্রক্রিয়ায় কাঁচা প্রশিক্ষণ ডেটা রূপান্তর করতে ব্যবহৃত হয়। transformed_train_dataset ডেটাসেট তৈরি করতে রূপান্তরিত প্রশিক্ষণের ডেটা রূপান্তরিত মেটাডেটা (বিশ্লেষণ পর্ব দ্বারা উত্পাদিত) সাথে যুক্ত করা হয়।
রূপান্তর পর্বটি নিম্নলিখিত চিত্র, চিত্র 2-এ চিত্রিত করা হয়েছে:

tf.Transform রূপান্তর পর্ব। বৈশিষ্ট্যগুলিকে প্রিপ্রসেস করার জন্য, আপনি preprocess_fn ফাংশনের বাস্তবায়নে প্রয়োজনীয় tensorflow_transform রূপান্তর (কোডে tft হিসাবে আমদানি করা) কল করুন। উদাহরণ স্বরূপ, আপনি যখন tft.scale_to_z_score অপারেশনে কল করেন, tf.Transform লাইব্রেরি এই ফাংশন কলটিকে গড় এবং প্রকরণ বিশ্লেষকগুলিতে অনুবাদ করে, বিশ্লেষণ পর্বে পরিসংখ্যান গণনা করে এবং তারপর রূপান্তর পর্বে সংখ্যাসূচক বৈশিষ্ট্যটিকে স্বাভাবিক করতে এই পরিসংখ্যানগুলি প্রয়োগ করে। AnalyzeAndTransformDataset(preprocess_fn) পদ্ধতিতে কল করার মাধ্যমে এটি স্বয়ংক্রিয়ভাবে সম্পন্ন হয়।
এই কল দ্বারা উত্পাদিত transformed_metadata.schema সত্তা নিম্নলিখিত কলামগুলি অন্তর্ভুক্ত করে:
-
gestation_weeks_scaled(প্রকার:FLOAT) -
is_male_index(প্রকার:INT, is_categorical:True) -
is_multiple_index(টাইপ:INT, is_categorical:True) -
mother_age_bucketized(টাইপ:INT, is_categorical:True) -
mother_age_log(প্রকার:FLOAT) -
mother_age_normalized(প্রকার:FLOAT) -
mother_race_index(টাইপ:INT, is_categorical:True) -
weight_pounds(প্রকার:FLOAT)
এই সিরিজের প্রথম অংশে প্রিপ্রসেসিং অপারেশনে যেমন ব্যাখ্যা করা হয়েছে, ফিচার ট্রান্সফরমেশন শ্রেণীগত বৈশিষ্ট্যকে একটি সংখ্যাসূচক উপস্থাপনায় রূপান্তরিত করে। রূপান্তরের পরে, শ্রেণীগত বৈশিষ্ট্যগুলি পূর্ণসংখ্যার মান দ্বারা উপস্থাপিত হয়। transformed_metadata.schema সত্তায়, INT প্রকারের কলামগুলির জন্য is_categorical পতাকা নির্দেশ করে যে কলামটি একটি শ্রেণীগত বৈশিষ্ট্য বা একটি সত্য সংখ্যাসূচক বৈশিষ্ট্য উপস্থাপন করে।
রূপান্তরিত প্রশিক্ষণ তথ্য লিখুন
প্রশিক্ষণের ডেটা বিশ্লেষণ এবং রূপান্তর পর্যায়গুলির মাধ্যমে preprocess_fn ফাংশনের সাথে প্রিপ্রসেস করার পরে, আপনি টেনসরফ্লো মডেলের প্রশিক্ষণের জন্য ব্যবহার করার জন্য একটি সিঙ্কে ডেটা লিখতে পারেন। যখন আপনি Dataflow ব্যবহার করে Apache Beam পাইপলাইন চালান, তখন সিঙ্কটি ক্লাউড স্টোরেজ। অন্যথায়, সিঙ্কটি স্থানীয় ডিস্ক। যদিও আপনি নির্দিষ্ট-প্রস্থের ফর্ম্যাট করা ফাইলগুলির একটি CSV ফাইল হিসাবে ডেটা লিখতে পারেন, TensorFlow ডেটাসেটের জন্য প্রস্তাবিত ফাইল ফর্ম্যাট হল TFRecord ফর্ম্যাট৷ এটি একটি সাধারণ রেকর্ড-ভিত্তিক বাইনারি বিন্যাস যা tf.train.Example প্রোটোকল বাফার বার্তা নিয়ে গঠিত।
প্রতিটি tf.train.Example রেকর্ডে এক বা একাধিক বৈশিষ্ট্য থাকে। প্রশিক্ষণের জন্য মডেলে খাওয়ানো হলে এগুলো টেনসরে রূপান্তরিত হয়। নিম্নলিখিত কোডটি নির্দিষ্ট অবস্থানে TFRecord ফাইলগুলিতে রূপান্তরিত ডেটাসেট লিখে:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
মূল্যায়ন ডেটা পড়ুন, রূপান্তর করুন এবং লিখুন
আপনি প্রশিক্ষণের ডেটা রূপান্তর করার পরে এবং transform_fn গ্রাফ তৈরি করার পরে, আপনি মূল্যায়ন ডেটা রূপান্তর করতে এটি ব্যবহার করতে পারেন। প্রথমে, আপনি BigQuery-এর থেকে raw প্রশিক্ষণ ডেটা পড়ুন- এ বর্ণিত read_from_bq ফাংশন ব্যবহার করে BigQuery থেকে মূল্যায়ন ডেটা পড়েন এবং পরিষ্কার করেন এবং step প্যারামিটারের জন্য eval মান পাস করেন। তারপর, আপনি নিম্নোক্ত কোড ব্যবহার করে কাঁচা মূল্যায়ন ডেটাসেট ( raw_dataset ) কে প্রত্যাশিত রূপান্তরিত বিন্যাসে রূপান্তর করতে পারেন ( transformed_dataset ):
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
যখন আপনি মূল্যায়নের ডেটা রূপান্তর করেন, তখন শুধুমাত্র ইনস্ট্যান্স-লেভেল অপারেশনগুলি প্রযোজ্য হয়, transform_fn গ্রাফের যুক্তি এবং প্রশিক্ষণের ডেটা বিশ্লেষণ পর্ব থেকে গণনা করা পরিসংখ্যান উভয়ই ব্যবহার করে। অন্য কথায়, আপনি নতুন পরিসংখ্যান গণনা করতে পূর্ণ-পাস ফ্যাশনে মূল্যায়ন ডেটা বিশ্লেষণ করেন না, যেমন মূল্যায়ন ডেটাতে সাংখ্যিক বৈশিষ্ট্যগুলির জেড-স্কোর স্বাভাবিককরণের গড় এবং পার্থক্য। পরিবর্তে, আপনি একটি উদাহরণ-স্তরের ফ্যাশনে মূল্যায়ন ডেটা রূপান্তর করতে প্রশিক্ষণের ডেটা থেকে গণনা করা পরিসংখ্যান ব্যবহার করেন।
অতএব, আপনি পরিসংখ্যান গণনা করতে এবং ডেটা রূপান্তর করতে প্রশিক্ষণের ডেটার প্রসঙ্গে AnalyzeAndTransform পদ্ধতি ব্যবহার করেন। একই সময়ে, আপনি প্রশিক্ষণ ডেটাতে গণনা করা পরিসংখ্যান ব্যবহার করে শুধুমাত্র ডেটা রূপান্তর করতে মূল্যায়ন ডেটা রূপান্তর করার প্রসঙ্গে TransformDataset পদ্ধতি ব্যবহার করেন।
তারপরে আপনি প্রশিক্ষণ প্রক্রিয়া চলাকালীন টেনসরফ্লো মডেলের মূল্যায়নের জন্য TFRecord বিন্যাসে একটি সিঙ্কে (ক্লাউড স্টোরেজ বা স্থানীয় ডিস্ক, রানারের উপর নির্ভর করে) ডেটা লিখুন। এটি করার জন্য, আপনি write_tfrecords ফাংশনটি ব্যবহার করেন যা Write transformed training data এ আলোচনা করা হয়েছে। নিম্নলিখিত চিত্র, চিত্র 3, দেখায় কিভাবে প্রশিক্ষণের ডেটা বিশ্লেষণের পর্যায়ে উত্পাদিত transform_fn গ্রাফটি মূল্যায়ন ডেটা রূপান্তর করতে ব্যবহৃত হয়।

transform_fn গ্রাফ ব্যবহার করে মূল্যায়ন ডেটা রূপান্তর করা।গ্রাফ সংরক্ষণ করুন
tf.Transform প্রিপ্রসেসিং পাইপলাইনের একটি চূড়ান্ত ধাপ হল শিল্পকর্মগুলি সংরক্ষণ করা, যার মধ্যে transform_fn গ্রাফ অন্তর্ভুক্ত যা প্রশিক্ষণের ডেটা বিশ্লেষণের পর্যায় দ্বারা উত্পাদিত হয়। আর্টিফ্যাক্টগুলি সংরক্ষণ করার জন্য কোডটি নিম্নলিখিত write_transform_artefacts ফাংশনে দেখানো হয়েছে:
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
এই নিদর্শনগুলি পরে মডেল প্রশিক্ষণ এবং পরিবেশনের জন্য রপ্তানির জন্য ব্যবহার করা হবে। নিম্নলিখিত শিল্পকর্মগুলিও উত্পাদিত হয়, যেমনটি পরবর্তী বিভাগে দেখানো হয়েছে:
-
saved_model.pb: TensorFlow গ্রাফের প্রতিনিধিত্ব করে যা ট্রান্সফর্মেশন লজিক (transform_fnগ্রাফ) অন্তর্ভুক্ত করে, যা ট্রান্সফর্মড ফরম্যাটে কাঁচা ডেটা পয়েন্টগুলিকে রূপান্তর করার জন্য মডেল পরিবেশন ইন্টারফেসের সাথে সংযুক্ত করতে হবে। -
variables: প্রশিক্ষণের ডেটা বিশ্লেষণের পর্যায়ে গণনা করা পরিসংখ্যান অন্তর্ভুক্ত করে এবংsaved_model.pbআর্টিফ্যাক্টে রূপান্তর যুক্তিতে ব্যবহৃত হয়। -
assets: শব্দভান্ডার ফাইলগুলি অন্তর্ভুক্ত করে, প্রতিটি শ্রেণীবদ্ধ বৈশিষ্ট্যের জন্য একটিcompute_and_apply_vocabularyপদ্ধতিতে প্রক্রিয়া করা হয়, একটি ইনপুট কাঁচা নামমাত্র মানকে একটি সংখ্যাসূচক সূচকে রূপান্তর করতে পরিবেশনের সময় ব্যবহার করা হবে। -
transformed_metadata: একটি ডিরেক্টরি যেখানেschema.jsonফাইল রয়েছে যা রূপান্তরিত ডেটার স্কিমা বর্ণনা করে।
ডেটাফ্লোতে পাইপলাইন চালান
আপনি tf.Transform পাইপলাইন সংজ্ঞায়িত করার পরে, আপনি Dataflow ব্যবহার করে পাইপলাইন চালান। নিম্নলিখিত চিত্র, চিত্র 4, উদাহরণে বর্ণিত tf.Transform পাইপলাইনের ডেটাফ্লো এক্সিকিউশন গ্রাফ দেখায়।
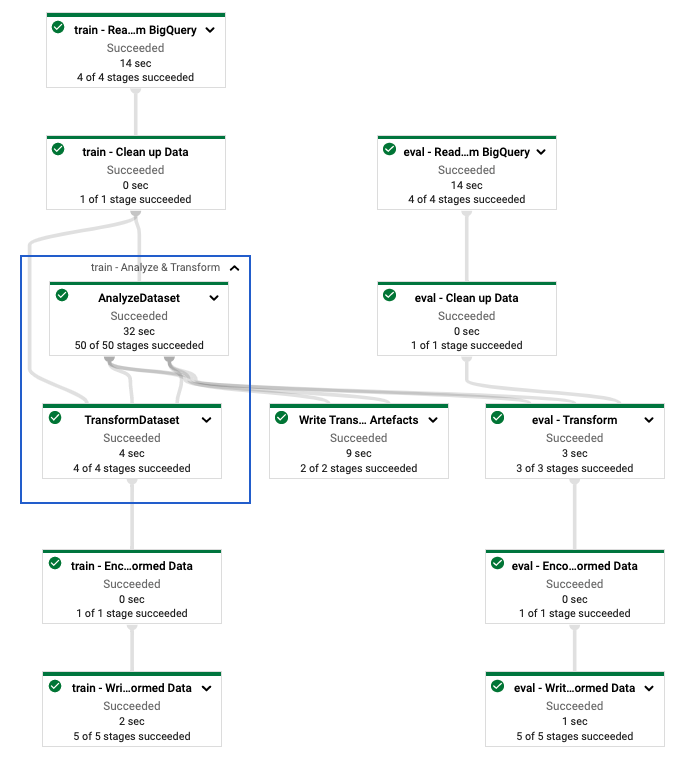
tf.Transform পাইপলাইনের ডেটাফ্লো এক্সিকিউশন গ্রাফ। প্রশিক্ষণ এবং মূল্যায়ন ডেটা প্রিপ্রসেস করার জন্য আপনি ডেটাফ্লো পাইপলাইন চালানোর পরে, আপনি নোটবুকের শেষ সেলটি কার্যকর করার মাধ্যমে ক্লাউড স্টোরেজে উত্পাদিত বস্তুগুলি অন্বেষণ করতে পারেন। এই বিভাগে কোড স্নিপেটগুলি ফলাফলগুলি দেখায়, যেখানে YOUR_BUCKET_NAME হল আপনার ক্লাউড স্টোরেজ বাকেটের নাম৷
TFRecord ফরম্যাটে রূপান্তরিত প্রশিক্ষণ এবং মূল্যায়ন ডেটা নিম্নলিখিত স্থানে সংরক্ষণ করা হয়:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
ট্রান্সফর্ম আর্টিফ্যাক্টগুলি নিম্নলিখিত স্থানে উত্পাদিত হয়:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
নিম্নলিখিত তালিকাটি পাইপলাইনের আউটপুট, উত্পাদিত ডেটা অবজেক্ট এবং আর্টিফ্যাক্টগুলি দেখায়:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
টেনসরফ্লো মডেলটি বাস্তবায়ন করুন
এই বিভাগ এবং পরবর্তী বিভাগ, ভবিষ্যদ্বাণীর জন্য মডেলটিকে প্রশিক্ষণ দিন এবং ব্যবহার করুন , নোটবুক 2-এর জন্য একটি ওভারভিউ এবং প্রসঙ্গ প্রদান করুন। নোটবুকটি শিশুর ওজন অনুমান করার জন্য একটি উদাহরণ ML মডেল প্রদান করে। এই উদাহরণে, কেরাস এপিআই ব্যবহার করে একটি টেনসরফ্লো মডেল প্রয়োগ করা হয়েছে। মডেলটি পূর্বে ব্যাখ্যা করা tf.Transform প্রিপ্রসেসিং পাইপলাইন দ্বারা উত্পাদিত ডেটা এবং শিল্পকর্ম ব্যবহার করে।
নোটবুক 2 চালান
JupyterLab ইন্টারফেসে, File > Open from path এ ক্লিক করুন এবং তারপর নিম্নলিখিত পথটি প্রবেশ করান:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbসম্পাদনা করুন > সমস্ত আউটপুট সাফ করুন ক্লিক করুন।
প্রয়োজনীয় প্যাকেজ ইনস্টল করুন বিভাগে,
pip install tensorflow-transformকমান্ড চালানোর জন্য প্রথম সেলটি চালান।আউটপুটের শেষ অংশটি নিম্নরূপ:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.আপনি আউটপুট নির্ভরতা ত্রুটি উপেক্ষা করতে পারেন.
কার্নেল মেনুতে, রিস্টার্ট কার্নেল নির্বাচন করুন।
ইনস্টল করা প্যাকেজগুলি নিশ্চিত করুন এবং ডেটাফ্লো কন্টেইনার বিভাগে প্যাকেজগুলি ইনস্টল করতে setup.py তৈরি করুন-এ সেলগুলি চালান।
সেট গ্লোবাল পতাকা বিভাগে,
PROJECTএবংBUCKETপাশে,your-projectআপনার ক্লাউড প্রকল্প আইডি দিয়ে প্রতিস্থাপন করুন এবং তারপরে সেলটি চালান।নোটবুকের শেষ কক্ষের মাধ্যমে অবশিষ্ট কোষগুলি চালান। প্রতিটি কক্ষে কি করতে হবে সে সম্পর্কে তথ্যের জন্য, নোটবুকের নির্দেশাবলী দেখুন।
মডেল তৈরির ওভারভিউ
মডেল তৈরির জন্য ধাপগুলি নিম্নরূপ:
-
transformed_metadataডিরেক্টরিতে সংরক্ষিত স্কিমা তথ্য ব্যবহার করে বৈশিষ্ট্য কলাম তৈরি করুন। - মডেলের ইনপুট হিসাবে বৈশিষ্ট্য কলাম ব্যবহার করে Keras API দিয়ে প্রশস্ত এবং গভীর মডেল তৈরি করুন।
- ট্রান্সফর্ম আর্টিফ্যাক্ট ব্যবহার করে প্রশিক্ষণ এবং মূল্যায়ন ডেটা পড়তে এবং পার্স করতে
tfrecords_input_fnফাংশন তৈরি করুন। - ট্রেন এবং মডেল মূল্যায়ন.
- একটি
serving_fnফাংশন সংজ্ঞায়িত করে প্রশিক্ষিত মডেলটি রপ্তানি করুন যার সাথেtransform_fnগ্রাফ সংযুক্ত আছে। -
saved_model_cliটুল ব্যবহার করে রপ্তানিকৃত মডেলটি পরিদর্শন করুন। - ভবিষ্যদ্বাণী জন্য রপ্তানি মডেল ব্যবহার করুন.
এই দস্তাবেজটি ব্যাখ্যা করে না যে কীভাবে মডেলটি তৈরি করতে হয়, তাই এটি কীভাবে মডেলটি তৈরি বা প্রশিক্ষণ দেওয়া হয়েছিল তা বিস্তারিতভাবে আলোচনা করে না। যাইহোক, নিম্নলিখিত বিভাগগুলি দেখায় কিভাবে transform_metadata ডিরেক্টরিতে সংরক্ষিত তথ্য-যা tf.Transform প্রক্রিয়া দ্বারা উত্পাদিত হয়-মডেলের বৈশিষ্ট্য কলাম তৈরি করতে ব্যবহৃত হয়। নথিটি আরও দেখায় কিভাবে transform_fn গ্রাফ—যা tf.Transform প্রক্রিয়া দ্বারাও তৈরি হয়—যখন মডেলটিকে পরিবেশনের জন্য রপ্তানি করা হয় তখন serving_fn ফাংশনে ব্যবহৃত হয়।
মডেল প্রশিক্ষণে উত্পন্ন রূপান্তর শিল্পকর্ম ব্যবহার করুন
আপনি যখন টেনসরফ্লো মডেলটি প্রশিক্ষণ দেন, আপনি পূর্ববর্তী ডেটা প্রক্রিয়াকরণ ধাপে উত্পাদিত রূপান্তরিত train এবং eval অবজেক্ট ব্যবহার করেন। এই বস্তুগুলি TFRecord বিন্যাসে শার্ড ফাইল হিসাবে সংরক্ষণ করা হয়। পূর্ববর্তী ধাপে উত্পন্ন transformed_metadata ডিরেক্টরির স্কিমা তথ্য প্রশিক্ষণ এবং মূল্যায়নের জন্য মডেলে ফিড করার জন্য ডেটা ( tf.train.Example অবজেক্ট) পার্সিং করতে কার্যকর হতে পারে।
ডেটা পার্স করুন
যেহেতু আপনি প্রশিক্ষণ এবং মূল্যায়ন ডেটা সহ মডেলকে ফিড করার জন্য TFRecord ফর্ম্যাটে ফাইলগুলি পড়েন, তাই বৈশিষ্ট্যগুলির একটি অভিধান (টেনসর) তৈরি করতে ফাইলগুলির প্রতিটি tf.train.Example অবজেক্টকে পার্স করতে হবে৷ এটি নিশ্চিত করে যে বৈশিষ্ট্যগুলি বৈশিষ্ট্য কলামগুলি ব্যবহার করে মডেল ইনপুট স্তরে ম্যাপ করা হয়েছে, যা মডেল প্রশিক্ষণ এবং মূল্যায়ন ইন্টারফেস হিসাবে কাজ করে। ডেটা পার্স করতে, আপনি TFTransformOutput অবজেক্ট ব্যবহার করেন যা পূর্ববর্তী ধাপে তৈরি করা শিল্পকর্ম থেকে তৈরি করা হয়েছে:
পূর্ববর্তী প্রিপ্রসেসিং ধাপে তৈরি এবং সংরক্ষিত আর্টিফ্যাক্টগুলি থেকে একটি
TFTransformOutputঅবজেক্ট তৈরি করুন, যেমনটি গ্রাফ সংরক্ষণ করুন বিভাগে বর্ণিত হয়েছে:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)TFTransformOutputঅবজেক্ট থেকে একটিfeature_specঅবজেক্ট বের করুন:tf_transform_output.transformed_feature_spec()tf.train.Exampleএ থাকা বৈশিষ্ট্যগুলি নির্দিষ্ট করতেfeature_specঅবজেক্ট ব্যবহার করুন।tfrecords_input_fnফাংশনের মতো উদাহরণ অবজেক্ট:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
বৈশিষ্ট্য কলাম তৈরি করুন
পাইপলাইন transformed_metadata ডিরেক্টরিতে স্কিমা তথ্য তৈরি করে যা রূপান্তরিত ডেটার স্কিমা বর্ণনা করে যা প্রশিক্ষণ এবং মূল্যায়নের জন্য মডেল দ্বারা প্রত্যাশিত। স্কিমাটিতে বৈশিষ্ট্যের নাম এবং ডেটা টাইপ রয়েছে, যেমন নিম্নলিখিত:
-
gestation_weeks_scaled(প্রকার:FLOAT) -
is_male_index(প্রকার:INT, is_categorical:True) -
is_multiple_index(টাইপ:INT, is_categorical:True) -
mother_age_bucketized(টাইপ:INT, is_categorical:True) -
mother_age_log(প্রকার:FLOAT) -
mother_age_normalized(প্রকার:FLOAT) -
mother_race_index(টাইপ:INT, is_categorical:True) -
weight_pounds(প্রকার:FLOAT)
এই তথ্য দেখতে, নিম্নলিখিত কমান্ড ব্যবহার করুন:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
নিম্নলিখিত কোডটি দেখায় যে আপনি বৈশিষ্ট্য কলাম তৈরি করতে বৈশিষ্ট্যের নাম কীভাবে ব্যবহার করেন:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
কোডটি সাংখ্যিক বৈশিষ্ট্যের জন্য একটি tf.feature_column.numeric_column কলাম এবং শ্রেণীগত বৈশিষ্ট্যের জন্য একটি tf.feature_column.categorical_column_with_identity কলাম তৈরি করে।
আপনি বর্ধিত বৈশিষ্ট্য কলামগুলিও তৈরি করতে পারেন, যেমনটি এই সিরিজের প্রথম অংশে বিকল্প সি: টেনসরফ্লোতে বর্ণিত হয়েছে। এই সিরিজের জন্য ব্যবহৃত উদাহরণে, tf.feature_column.crossed_column বৈশিষ্ট্য কলাম ব্যবহার করে mother_race এবং mother_age_bucketized বৈশিষ্ট্যগুলি অতিক্রম করে একটি নতুন বৈশিষ্ট্য তৈরি করা হয়েছে, mother_race_X_mother_age_bucketized । এই ক্রস করা বৈশিষ্ট্যটির নিম্ন-মাত্রিক, ঘন উপস্থাপনা tf.feature_column.embedding_column বৈশিষ্ট্য কলাম ব্যবহার করে তৈরি করা হয়েছে।
নিম্নলিখিত চিত্র, চিত্র 5, রূপান্তরিত ডেটা দেখায় এবং কীভাবে রূপান্তরিত মেটাডেটা টেনসরফ্লো মডেলকে সংজ্ঞায়িত এবং প্রশিক্ষণের জন্য ব্যবহার করা হয়:

ভবিষ্যদ্বাণী পরিবেশনের জন্য মডেল রপ্তানি করুন
আপনি কেরাস এপিআই-এর সাথে টেনসরফ্লো মডেলকে প্রশিক্ষণ দেওয়ার পরে, আপনি প্রশিক্ষিত মডেলটিকে একটি SavedModel অবজেক্ট হিসাবে রপ্তানি করেন, যাতে এটি পূর্বাভাসের জন্য নতুন ডেটা পয়েন্ট পরিবেশন করতে পারে। আপনি যখন মডেলটি রপ্তানি করেন, তখন আপনাকে এর ইন্টারফেসটি সংজ্ঞায়িত করতে হবে—অর্থাৎ, পরিবেশনের সময় প্রত্যাশিত ইনপুট বৈশিষ্ট্য স্কিমা। এই ইনপুট বৈশিষ্ট্য স্কিমা serving_fn ফাংশনে সংজ্ঞায়িত করা হয়েছে, যেমনটি নিম্নলিখিত কোডে দেখানো হয়েছে:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
পরিবেশন করার সময়, মডেলটি তাদের কাঁচা আকারে ডেটা পয়েন্ট আশা করে (অর্থাৎ, রূপান্তরের আগে কাঁচা বৈশিষ্ট্য)। অতএব, serving_fn ফাংশন কাঁচা বৈশিষ্ট্যগুলি গ্রহণ করে এবং একটি features বস্তুতে পাইথন অভিধান হিসাবে সংরক্ষণ করে। যাইহোক, যেমন আগে আলোচনা করা হয়েছে, প্রশিক্ষিত মডেল রূপান্তরিত স্কিমাতে ডেটা পয়েন্টগুলি আশা করে। মডেল ইন্টারফেসের দ্বারা প্রত্যাশিত transformed_features বস্তুগুলিতে কাঁচা বৈশিষ্ট্যগুলি রূপান্তর করতে, আপনি নিম্নলিখিত পদক্ষেপগুলি সহ features অবজেক্টে সংরক্ষিত transform_fn গ্রাফ প্রয়োগ করুন:
পূর্ববর্তী প্রিপ্রসেসিং ধাপে তৈরি এবং সংরক্ষিত আর্টিফ্যাক্টগুলি থেকে
TFTransformOutputঅবজেক্ট তৈরি করুন:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)TFTransformOutputঅবজেক্ট থেকে একটিTransformFeaturesLayerঅবজেক্ট তৈরি করুন:model.tft_layer = tf_transform_output.transform_features_layer()TransformFeaturesLayerঅবজেক্ট ব্যবহার করেtransform_fnগ্রাফ প্রয়োগ করুন:transformed_features = model.tft_layer(features)
নিম্নলিখিত চিত্র, চিত্র 6, পরিবেশনের জন্য একটি মডেল রপ্তানির চূড়ান্ত ধাপকে চিত্রিত করে:

transform_fn গ্রাফ সংযুক্ত করে পরিবেশনের জন্য মডেলটি রপ্তানি করা হচ্ছে। প্রশিক্ষণ দিন এবং ভবিষ্যদ্বাণীর জন্য মডেলটি ব্যবহার করুন
আপনি নোটবুকের কোষগুলি সম্পাদন করে স্থানীয়ভাবে মডেলটিকে প্রশিক্ষণ দিতে পারেন। Vertex AI ট্রেনিং ব্যবহার করে কীভাবে কোড প্যাকেজ করবেন এবং আপনার মডেলকে স্কেলে প্রশিক্ষণ দেবেন তার উদাহরণের জন্য, Google Cloud Cloudml-samples GitHub রিপোজিটরিতে নমুনা এবং গাইড দেখুন।
যখন আপনি saved_model_cli টুল ব্যবহার করে রপ্তানিকৃত SavedModel অবজেক্ট পরিদর্শন করেন, তখন আপনি দেখতে পান যে স্বাক্ষর সংজ্ঞা signature_def এর inputs উপাদানগুলি কাঁচা বৈশিষ্ট্যগুলিকে অন্তর্ভুক্ত করে, যেমনটি নিম্নলিখিত উদাহরণে দেখানো হয়েছে:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
নোটবুকের অবশিষ্ট কোষগুলি আপনাকে দেখায় যে কীভাবে স্থানীয় ভবিষ্যদ্বাণীর জন্য রপ্তানিকৃত মডেলটি ব্যবহার করতে হয় এবং ভার্টেক্স এআই পূর্বাভাস ব্যবহার করে মডেলটিকে মাইক্রোসার্ভিস হিসাবে কীভাবে স্থাপন করতে হয়। এটি হাইলাইট করা গুরুত্বপূর্ণ যে ইনপুট (নমুনা) ডেটা পয়েন্ট উভয় ক্ষেত্রেই কাঁচা স্কিমাতে রয়েছে।
পরিষ্কার করুন
এই টিউটোরিয়ালে ব্যবহৃত সংস্থানগুলির জন্য আপনার Google ক্লাউড অ্যাকাউন্টে অতিরিক্ত চার্জ এড়াতে, সংস্থানগুলি রয়েছে এমন প্রকল্পটি মুছুন৷
প্রকল্পটি মুছুন
Google ক্লাউড কনসোলে, সম্পদ পরিচালনা পৃষ্ঠাতে যান।
প্রকল্প তালিকায়, আপনি যে প্রকল্পটি মুছতে চান সেটি নির্বাচন করুন এবং তারপরে মুছুন ক্লিক করুন।
ডায়ালগে, প্রজেক্ট আইডি টাইপ করুন এবং তারপরে প্রোজেক্ট মুছে ফেলতে শাট ডাউন ক্লিক করুন।
এরপর কি
- Google ক্লাউডে মেশিন লার্নিংয়ের জন্য ডেটা প্রিপ্রসেসিংয়ের ধারণা, চ্যালেঞ্জ এবং বিকল্পগুলি সম্পর্কে জানতে, এই সিরিজের প্রথম নিবন্ধটি দেখুন, ML-এর জন্য ডেটা প্রিপ্রসেসিং: বিকল্প এবং সুপারিশ ।
- ডেটাফ্লোতে একটি tf.Transform পাইপলাইন কীভাবে প্রয়োগ করা যায়, প্যাকেজ করা যায় এবং চালানো যায় সে সম্পর্কে আরও তথ্যের জন্য, সেন্সাস ডেটাসেটের নমুনা সহ আয়ের পূর্বাভাস দেখুন।
- Google ক্লাউডে TensorFlow- এর সাথে ML-এ Coursera স্পেশালাইজেশন নিন।
- ML এর নিয়মে ML ইঞ্জিনিয়ারিং এর জন্য সেরা অনুশীলন সম্পর্কে জানুন।
- আরও রেফারেন্স আর্কিটেকচার, ডায়াগ্রাম এবং সর্বোত্তম অনুশীলনের জন্য, ক্লাউড আর্কিটেকচার সেন্টার অন্বেষণ করুন।