
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
סקירה כללית
מחברת זו תדגים כיצד להשתמש בפונקציית TripletSemiHardLoss בתוספות TensorFlow.
אֶמְצָעִי:
- FaceNet: הטמעה מאוחדת לזיהוי פנים ואשכולות
- הבלוג של אוליבר מויינדרוט עושה עבודה מצוינת בתיאור האלגוריתם בפירוט
TripletLoss
כפי שהוצג לראשונה במאמר FaceNet, TripletLoss היא פונקציית אובדן המאמנת רשת עצבית להטמיע מקרוב תכונות של אותה מחלקה תוך מיקסום המרחק בין הטבעות של מחלקות שונות. לשם כך נבחר עוגן יחד עם מדגם אחד שלילי ואחד חיובי. 
פונקציית ההפסד מתוארת כפונקציית מרחק אוקלידית:
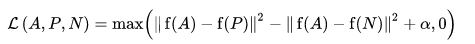
כאשר A הוא קלט העוגן שלנו, P הוא קלט הדגימה החיובי, N הוא קלט הדגימה השלילי, ואלפא הוא שוליים שבהם אתה משתמש כדי לציין מתי שלישייה הפכה ל"קלה" מדי ואינך רוצה יותר להתאים את המשקולות ממנו .
למידה מקוונת למחצה
כפי שמוצג במאמר, התוצאות הטובות ביותר הן משלישיות המכונה "חצי-קשה". אלה מוגדרים כשלישיות שבהן השלילי רחוק יותר מהעוגן מהחיובי, אך עדיין מייצר הפסד חיובי. כדי למצוא ביעילות את השלשות האלה, אתה משתמש בלמידה מקוונת ומתאמן רק מהדוגמאות החצי-קשות בכל אצווה.
להכין
pip install -q -U tensorflow-addons
import io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
הכן את הנתונים
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset 11.06 MiB (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
בנה את המודל

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
לאמן ולהעריך
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 21s 5ms/step - loss: 0.6983 Epoch 2/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4723 Epoch 3/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4298 Epoch 4/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4139 Epoch 5/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3938
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
מקרן הטבעה
קבצי הווקטור מטה ניתנים לטעינה מדמיינים כאן: https://projector.tensorflow.org/
אתה יכול לראות את התוצאות של נתוני הבדיקה המוטבעים שלנו כאשר הם מוצגים באמצעות UMAP: 