
Telif Hakkı 2020 TF-Agents Yazarları.
Başlamak
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Kurmak
Aşağıdaki bağımlılıkları yüklemediyseniz, çalıştırın:
pip install tf-agents
ithalat
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
Tanıtım
Çok Silahlı Haydut sorunu (MAB), Güçlendirmeli Öğrenmenin özel bir durumudur: bir aracı, ortamın bazı durumlarını gözlemledikten sonra bazı eylemlerde bulunarak bir ortamda ödüller toplar. Genel RL ve MAB arasındaki temel fark, MAB'de, etmen tarafından gerçekleştirilen eylemin ortamın sonraki durumunu etkilemediğini varsaymamızdır. Bu nedenle, aracılar durum geçişlerini modellemez, ödülleri geçmiş eylemlere kredilendirmez veya ödül açısından zengin durumlara ulaşmak için "ileriye dönük planlama" yapmazlar.
Diğer RL etki alanlarında olduğu gibi, bir MAB maddesinin amacı bir politika bulmak olduğunu toplar mümkün olduğunca ödül olarak. Bununla birlikte, her zaman en yüksek ödülü vaat eden eylemden yararlanmaya çalışmak bir hata olur, çünkü o zaman yeterince araştırmazsak daha iyi eylemleri kaçırma şansımız olur. Bu genellikle arama-işleme ikilem olarak adlandırılan, (MAB) içerisinde çözülmesi gereken ana bir sorundur.
MAB için Bandit ortamları, politikaları ve ajanlar alt dizinlerinde bulunabilir tf_agents / haydutlar .
ortamlar
TF-Agents, ortam sınıfı, girdi olarak bir işlem alan bir durum geçişini gerçekleştirmek ve bir ödül çıkış olarak verilmesi, (bu gözlem veya içerik olarak adlandırılır) durumuyla ilgili bilgiler veren rol oynar. Bu sınıf ayrıca yeni bir bölümün başlayabilmesi için bir bölüm bittiğinde sıfırlama ile ilgilenir. Bu arayarak gerçekleştirilmiştir reset devlet bölümün "son" olarak etiketlenmiş edildiğinde işlevi.
Daha fazla ayrıntı için bkz TF-Agents ortamlar öğretici .
Yukarıda bahsedildiği gibi, MAB, eylemlerin bir sonraki gözlemi etkilememesi bakımından genel RL'den farklıdır. Diğer bir fark, Haydutlarda "bölüm" olmamasıdır: her zaman adımı, önceki zaman adımlarından bağımsız olarak yeni bir gözlemle başlar.
Emin gözlemler bağımsız ve soyut koyma RL bölüm kavramı şunlardır hale getirmek için, alt sınıflarını tanıtmak PyEnvironment ve TFEnvironment : BanditPyEnvironment ve BanditTFEnvironment . Bu sınıflar, kullanıcı tarafından uygulanmaya devam eden iki özel üye işlevi sunar:
@abc.abstractmethod
def _observe(self):
ve
@abc.abstractmethod
def _apply_action(self, action):
_observe işlevi bir gözlem döndürür. Ardından, politika bu gözleme dayalı olarak bir eylem seçer. _apply_action bir girdi olarak bu işlem alır ve karşılık gelen ödül verir. Bunlar özel üye işlevler işlevler tarafından çağrılan reset ve step sırasıyla.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
Ara soyut sınıf uygular yukarıda PyEnvironment sitesindeki _reset ve _step fonksiyonları ve arka fonksiyonlar ortaya koyar _observe ve _apply_action alt sınıflar tarafından uygulanacaktır.
Basit Bir Örnek Ortam Sınıfı
Aşağıdaki sınıf, gözlemin -2 ile 2 arasında rastgele bir tamsayı olduğu, 3 olası eylemin (0, 1, 2) olduğu ve ödülün eylem ve gözlemin ürünü olduğu çok basit bir ortam verir.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
Artık bu ortamı gözlemler almak ve eylemlerimiz için ödüller almak için kullanabiliriz.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
TF Ortamları
Bir sınıflara göre bir haydut ortamı tanımlayabilir BanditTFEnvironment veya benzer RL ortamları için, tek bir tanımlayabilir BanditPyEnvironment ile sarın TFPyEnvironment . Sadelik adına, bu eğitimde ikinci seçeneğe geçiyoruz.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
Politikalar
Haydut problem bir ilke bir RL problem aynı şekilde çalışır: bu giriş olarak bir gözlem verilen bir işlem (veya eylemlerin bir dağılım) içerir.
Daha fazla ayrıntı için bkz TF-Ajanlar Politikası öğretici .
Biri oluşturabilirsiniz: ortamlarda gibi bir politika oluşturmak için iki yol vardır PyPolicy ve ile sarın TFPyPolicy veya doğrudan bir oluşturmak TFPolicy . Burada doğrudan yöntemle gitmeyi seçiyoruz.
Bu örnek oldukça basit olduğu için optimal politikayı manuel olarak tanımlayabiliriz. Eylem sadece gözlemin işaretine bağlıdır, 0 negatif olduğunda ve 2 pozitif olduğunda.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
Şimdi ortamdan bir gözlem talep edebiliriz, bir eylem seçmek için politikayı çağırabiliriz, sonra çevre ödülü verir:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
Haydut ortamlarının uygulanma şekli, her adım attığımızda, yalnızca yaptığımız eylemin ödülünü değil, aynı zamanda bir sonraki gözlemi de almamızı sağlar.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
Temsilciler
Artık haydut ortamları ve haydut politikalarımız olduğuna göre, eğitim örneklerine dayalı olarak politikayı değiştirmeye özen gösteren haydut ajanlarını da tanımlamanın zamanı geldi.
Eşkıya ajanlar için API RL ajanların o farklı değildir: ajan sadece uygulaması gerekmektedir _initialize ve _train bir yöntemlerini ve tanımlamak policy ve collect_policy .
Daha Karmaşık Bir Ortam
Haydut ajanımızı yazmadan önce, anlaşılması biraz daha zor bir ortama ihtiyacımız var. Şeyler birazcık renklendirmek için, bir sonraki ortam ya hep verecek reward = observation * action veya reward = -observation * action . Bu, ortam başlatıldığında kararlaştırılacaktır.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
Daha Karmaşık Bir Politika
Daha karmaşık bir ortam, daha karmaşık bir politika gerektirir. Temel ortamın davranışını algılayan bir ilkeye ihtiyacımız var. Politikanın ele alması gereken üç durum vardır:
- Aracı, ortamın hangi sürümünün çalıştığını henüz algılamadı.
- Aracı, ortamın orijinal sürümünün çalıştığını algıladı.
- Aracı, ortamın çevrilmiş sürümünün çalıştığını algıladı.
Biz tanımlayan tf_variable adında _situation değerler olarak kodlanmış bu bilgileri saklamak için [0, 2] Daha sonra, buna göre politika davranmaya olun.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
Ajan
Şimdi sıra ortamın işaretini algılayan ve politikayı uygun şekilde ayarlayan aracıyı tanımlamaya geldi.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
Yukarıdaki kodda, ajan politikasını belirlemekte, değişken situation ajan ve ilke tarafından paylaşılır.
Ayrıca, parametre experience ait _train fonksiyonu bir yörünge geçerli:
yörüngeler
TF-Ajanlar olarak, trajectories alınan önceki adımlardan örnekleri içeren dizilerini adlandırılır. Bu örnekler daha sonra aracı tarafından ilkeyi eğitmek ve güncellemek için kullanılır. RL'de yörüngeler, mevcut durum, sonraki durum ve mevcut bölümün bitip bitmediği hakkında bilgi içermelidir. Haydut dünyasında bunlara ihtiyacımız olmadığından, bir yörünge oluşturmak için bir yardımcı fonksiyon kurduk:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
Temsilci Eğitimi
Artık haydut ajanımızı eğitmek için tüm parçalar hazır.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Çıktıdan, ikinci adımdan sonra (ilk adımda gözlem 0 olmadığı sürece), politikanın eylemi doğru şekilde seçtiği ve dolayısıyla toplanan ödülün her zaman negatif olmadığı görülebilir.
Gerçek Bir Bağlamsal Eşkıya Örneği
Bu eğiticinin geri kalan, biz önceden uygulanan kullanmak ortamları ve ajanları TF-Ajanlar Bandits kütüphane.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
Doğrusal Ödeme Fonksiyonlu Durağan Stokastik Ortam
Bu örnekte kullanılan ortam StationaryStochasticPyEnvironment . Bu ortam, parametre olarak gözlemler (bağlam) vermek için (genellikle gürültülü) bir fonksiyon alır ve her kol için verilen gözleme dayalı olarak ödülü hesaplayan (ayrıca gürültülü) bir fonksiyon alır. Örneğimizde, d-boyutlu bir küpten bağlamı tek tip olarak örnekliyoruz ve ödül işlevleri, bağlamın doğrusal işlevleri ile bir miktar Gauss gürültüsüdür.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
LinUCB Temsilcisi
Uygular aşağıdaki madde LinUCB algoritması.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
pişmanlık metriği
Bandits' en önemli ölçüt ajan tarafından toplanan ödül ve çevre ödül işlevlerine erişimi olan bir kahin politikasının beklenen ödül arasındaki fark olarak hesaplanan pişmanlık. RegretMetric böylece bir gözlem verilen elde edilebilen en iyi beklenen ödül hesaplayan bir baseline_reward_fn işlevi gereklidir. Örneğimiz için, daha önce çevre için tanımladığımız ödül işlevlerinin gürültüsüz eşdeğerlerinin maksimumunu almamız gerekiyor.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
Eğitim
Şimdi yukarıda tanıttığımız tüm bileşenleri bir araya getirdik: ortam, politika ve aracı. Elimizde sürücünün yardımıyla çevre ve çıkış eğitimi verilerine politikasını çalıştırın ve veriler üzerinde ajan yetiştirmek.
Birlikte atılan adım sayısını belirten iki parametre olduğunu unutmayın. num_iterations sürücü alacak ederken, eğitmen döngü çalıştırmak kaç kez belirtir steps_per_loop yinelemesi başına adımlar. Bu parametrelerin her ikisinin de tutulmasının ana nedeni, bazı işlemlerin yineleme başına yapılması, bazılarının ise her adımda sürücü tarafından yapılmasıdır. Örneğin, vekilin train işlevi yalnızca yineleme başına bir kez denir. Buradaki ödün, daha sık antrenman yaparsak politikamız "daha taze" olur, diğer yandan daha büyük gruplar halinde eğitim daha verimli olabilir.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
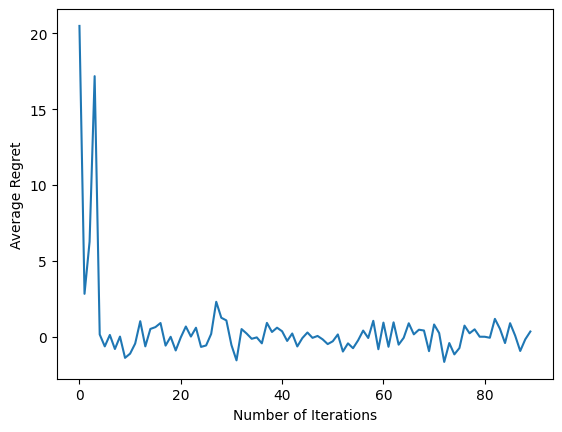
Son kod parçacığını çalıştırdıktan sonra, ortaya çıkan grafik (umarım), aracı eğitildikçe ortalama pişmanlığın azaldığını ve gözleme göre doğru eylemin ne olduğunu bulmada politikanın daha iyi hale geldiğini gösterir.
Sıradaki ne?
Daha çalışma örnekleri görmek için lütfen haydutlar / ajanları / örnekler farklı ajanlar ve ortamlar için hazır çalıştırmak örnekler vardır dizini.
TF-Agents kitaplığı ayrıca, kol başına özelliklere sahip Çok Silahlı Haydutları işleyebilir. Bu amaçla, biz başı kol eşkıya okuyucu bakın öğretici .