
Copyright 2020 Autorzy TF-Agenci.
Zaczynaj
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ustawiać
Jeśli nie zainstalowałeś następujących zależności, uruchom:
pip install tf-agents
Import
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
Wstęp
Problem wielorękiego bandyty (MAB) to szczególny przypadek uczenia się przez wzmacnianie: agent zbiera nagrody w środowisku, wykonując pewne czynności po zaobserwowaniu pewnego stanu środowiska. Główna różnica między ogólnym RL a MAB polega na tym, że w MAB zakładamy, że działanie podjęte przez agenta nie ma wpływu na kolejny stan środowiska. Dlatego agenci nie modelują zmian stanów, nie przypisują nagród do przeszłych działań ani nie „planują z wyprzedzeniem”, aby dostać się do stanów bogatych w nagrody.
Podobnie jak w innych dziedzinach RL, celem środka MAB jest znalezienie politykę, która zbiera tyle nagroda, jak to możliwe. Błędem byłoby jednak zawsze próbować wykorzystać działanie, które obiecuje najwyższą nagrodę, ponieważ wtedy istnieje szansa, że przegapimy lepsze działania, jeśli nie będziemy wystarczająco eksplorować. To jest główny problem, który należy rozwiązać w (MAB), często nazywany dylemat poszukiwawczo-eksploatacyjnych.
Bandit środowiska, polityka i środki dla MAB można znaleźć w podkatalogach tf_agents / bandytów .
Środowiska
W TF-pełnomocników, klasa środowisko służy rolę udzielanie informacji na temat aktualnego stanu (nazywa się to obserwacja lub kontekst), odbieranie działanie jako wejście, wykonując przejście stanu i wyprowadzania nagrodę. Ta klasa zajmuje się również resetowaniem po zakończeniu odcinka, aby mógł rozpocząć się nowy odcinek. Jest to realizowane poprzez wywołanie reset funkcji, gdy stan jest oznaczony jako „ostatni” epizodu.
Aby uzyskać więcej informacji, zobacz poradnik TF-agentów środowiskach .
Jak wspomniano powyżej, MAB różni się od ogólnego RL tym, że działania nie wpływają na następną obserwację. Kolejna różnica polega na tym, że w Bandits nie ma „epizodów”: każdy krok czasowy zaczyna się od nowej obserwacji, niezależnie od poprzednich kroków czasowych.
Aby upewnić się, że obserwacje są niezależne i abstrakcyjnego oddalony koncepcji odcinków RL, wprowadzamy podklasy PyEnvironment i TFEnvironment : BanditPyEnvironment i BanditTFEnvironment . Te klasy udostępniają dwie prywatne funkcje składowe, które pozostają do zaimplementowania przez użytkownika:
@abc.abstractmethod
def _observe(self):
oraz
@abc.abstractmethod
def _apply_action(self, action):
_observe funkcja zwraca obserwację. Następnie polityka wybiera akcję na podstawie tej obserwacji. _apply_action otrzymuje że działanie na wejściu i zwraca odpowiedni nagrody. Te prywatne funkcje składowe nazywane są przez funkcje reset i step , odpowiednio.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
Powyższe streszczenie okresowych narzędzi klasy PyEnvironment „s _reset i _step funkcje i naraża abstrakcyjne funkcje _observe i _apply_action być realizowane przez podklasy.
Prosta przykładowa klasa środowiska
Poniższa klasa daje bardzo proste środowisko, dla którego obserwacja jest losową liczbą całkowitą od -2 do 2, istnieją 3 możliwe akcje (0, 1, 2), a nagroda jest iloczynem akcji i obserwacji.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
Teraz możemy wykorzystać to środowisko do zbierania obserwacji i otrzymywania nagród za nasze działania.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
Środowiska TF
Można zdefiniować środowisko bandytów przez instacji BanditTFEnvironment , albo podobnie do środowisk RL, można zdefiniować BanditPyEnvironment i owinąć go TFPyEnvironment . Dla uproszczenia, w tym samouczku wybieramy tę drugą opcję.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
Zasady
Polityka w błąd Bandytów działa w ten sam sposób jak w błąd RL: zapewnia działanie (lub rozłożenie działań), biorąc pod obserwacją jako wejście.
Aby uzyskać więcej informacji, zobacz poradnik TF-Biura Polityki .
Podobnie jak w przypadku środowisk, istnieją dwa sposoby określenia polityki: Można utworzyć PyPolicy i owinąć go TFPyPolicy lub bezpośrednio utworzyć TFPolicy . Tutaj wybieramy metodę bezpośrednią.
Ponieważ ten przykład jest dość prosty, optymalną politykę możemy zdefiniować ręcznie. Działanie zależy tylko od znaku obserwacji, 0 gdy jest ujemny, a 2 gdy jest dodatni.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
Teraz możemy poprosić otoczenie o obserwację, wywołać polisę w celu wybrania działania, wtedy środowisko wypłaci nagrodę:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
Sposób implementacji środowisk bandytów sprawia, że za każdym razem, gdy robimy krok, otrzymujemy nie tylko nagrodę za podjęte działanie, ale także kolejną obserwację.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
Agenci
Teraz, gdy mamy środowiska bandytów i polityki bandytów, nadszedł czas na zdefiniowanie agentów bandytów, którzy zajmą się zmianą polityki na podstawie próbek szkoleniowych.
API dla agentów bandyckich nie różni się od agentów RL: agent po prostu musi wdrożyć _initialize i _train metody i zdefiniowanie policy i collect_policy .
Bardziej skomplikowane środowisko
Zanim napiszemy naszego agenta bandytów, musimy mieć środowisko, które jest nieco trudniejsze do rozszyfrowania. Aby urozmaicić rzeczy po prostu się trochę, następnym środowisko albo będzie zawsze dać reward = observation * action lub reward = -observation * action . Decyzja zostanie podjęta podczas inicjowania środowiska.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
Bardziej skomplikowana polityka
Bardziej skomplikowane środowisko wymaga bardziej skomplikowanej polityki. Potrzebujemy polityki, która wykrywa zachowanie środowiska bazowego. Zasady muszą radzić sobie z trzema sytuacjami:
- Agent nie wykrył jeszcze, która wersja środowiska jest uruchomiona.
- Agent wykrył, że działa oryginalna wersja środowiska.
- Agent wykrył, że działa odwrócona wersja środowiska.
Definiujemy tf_variable nazwie _situation przechowywać te informacje zakodowane jako wartości w [0, 2] , a następnie dokonać zachowywać polityki odpowiednio.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
Agent
Teraz czas na zdefiniowanie agenta, który wykryje znak środowiska i odpowiednio ustawi politykę.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
W powyższym kodzie, agent określa politykę i zmienna situation jest dzielona przez agenta i polityki.
Również parametr experience z _train funkcji jest trajektoria:
Trajektorie
W TF-pełnomocników, trajectories są nazwane krotki, które zawierają próbki z poprzednich krokach podjętych. Te próbki są następnie używane przez agenta do trenowania i aktualizowania zasad. W RL trajektorie muszą zawierać informacje o aktualnym stanie, następnym stanie oraz o tym, czy bieżący odcinek się zakończył. Ponieważ w świecie Bandit nie potrzebujemy tych rzeczy, ustawiliśmy funkcję pomocniczą, aby stworzyć trajektorię:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
Szkolenie agenta
Teraz wszystkie elementy są gotowe do szkolenia naszego agenta bandytów.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Z danych wyjściowych widać, że po drugim kroku (chyba, że obserwacja w pierwszym kroku była 0), polityka wybiera akcję we właściwy sposób, a zatem zebrana nagroda jest zawsze nieujemna.
Prawdziwy kontekstowy przykład bandyty
W pozostałej części tego poradnika, używamy wcześniej wdrożył środowisk i środków biblioteki TF-Agenci bandytów.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
Stacjonarne środowisko stochastyczne z liniowymi funkcjami wypłaty
Środowisko użyta w tym przykładzie jest StationaryStochasticPyEnvironment . To środowisko przyjmuje jako parametr (zwykle zaszumioną) funkcję do przekazywania obserwacji (kontekst), a dla każdego ramienia przyjmuje (również zaszumioną) funkcję, która oblicza nagrodę w oparciu o daną obserwację. W naszym przykładzie próbkujemy kontekst jednolicie z d-wymiarowego sześcianu, a funkcje nagrody są funkcjami liniowymi kontekstu plus trochę szumu Gaussa.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
Agent LinUCB
Środek poniżej implementuje LinUCB algorytmu.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
Wskaźnik żalu
Najważniejszą metryczny bandytów jest żal, obliczony jako różnica pomiędzy wynagrodzeniem zebranych przez agenta i oczekiwanego nagrodę polityki oracle, który ma dostęp do funkcji nagrody środowiska. RegretMetric zatem potrzebuje funkcji baseline_reward_fn który oblicza najlepszą osiągalną oczekiwaną nagrodę daną obserwacja. W naszym przykładzie musimy wziąć maksimum bezszumowych ekwiwalentów funkcji nagrody, które już zdefiniowaliśmy dla środowiska.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
Trening
Teraz połączyliśmy wszystkie komponenty, które wprowadziliśmy powyżej: środowisko, politykę i agenta. Prowadzimy politykę w dziedzinie środowiska naturalnego i szkoleniowych wyjście danych z pomocą kierowcy i wyszkolić agenta danych.
Zauważ, że istnieją dwa parametry, które łącznie określają liczbę wykonanych kroków. num_iterations Określa, ile razy możemy uruchomić pętlę trener, podczas gdy kierowca weźmie steps_per_loop kroki za iteracji. Głównym powodem zachowania obu tych parametrów jest to, że niektóre operacje są wykonywane na iterację, podczas gdy niektóre są wykonywane przez sterownik na każdym kroku. Na przykład agenta train funkcja jest wywoływana tylko raz na iteracji. Kompromis polega na tym, że jeśli trenujemy częściej, to nasza polityka jest „świeższa”, z drugiej strony szkolenie w większych partiach może być bardziej efektywne czasowo.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
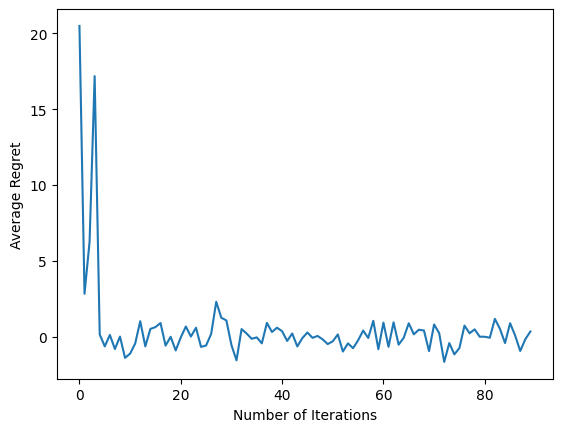
Po uruchomieniu ostatniego fragmentu kodu wynikowy wykres (miejmy nadzieję) pokazuje, że średni żal maleje, gdy agent jest szkolony, a polityka staje się coraz lepsza w określaniu właściwego działania, biorąc pod uwagę obserwację.
Co dalej?
Aby zobaczyć więcej przykładów roboczych, zobacz Bandyci / agentów / przykłady katalogu, który jest gotowy do uruchomienia przykładów dla różnych czynników i warunków.
Biblioteka TF-Agents jest również zdolna do obsługi wielorękich bandytów z funkcjami na ramię. W tym celu odsyłamy czytelnika do per-ramię bandit tutorialu .