
सार्वजनिक अंतिम वर्ग पैरेललडायनामिकस्टिच
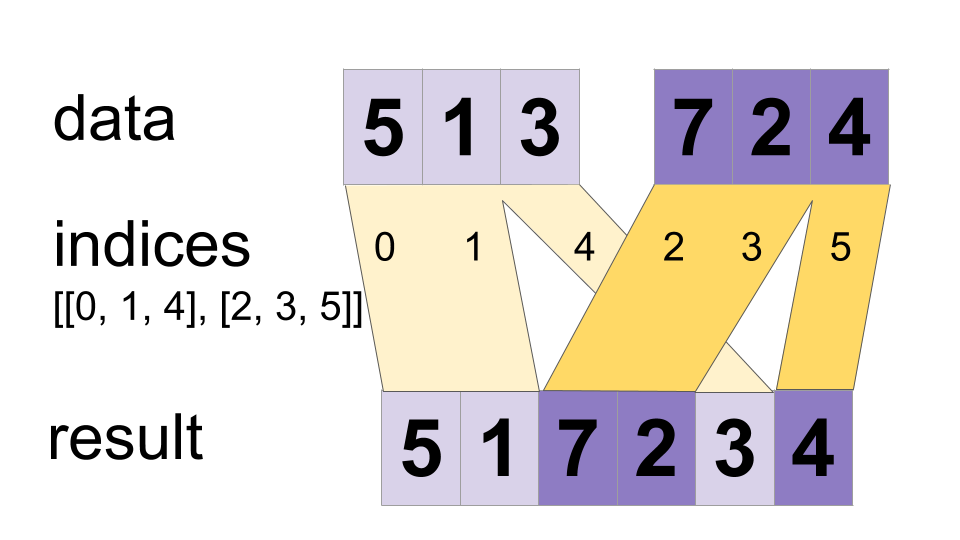
`डेटा` टेंसर से मानों को एक टेंसर में इंटरलीव करें।
एक मर्ज किया हुआ टेंसर इस प्रकार बनाता है
merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...]
# Scalar indices:
merged[indices[m], ...] = data[m][...]
# Vector indices:
merged[indices[m][i], ...] = data[m][i, ...]
मर्ज.आकार = [अधिकतम(सूचकांक)] + स्थिरांक
मानों को समानांतर में मर्ज किया जा सकता है, इसलिए यदि कोई सूचकांक `सूचकांक[m][i]` और `सूचकांक[n][j]` दोनों में दिखाई देता है, तो परिणाम अमान्य हो सकता है। यह सामान्य डायनामिकस्टिच ऑपरेटर से भिन्न है जो उस मामले में व्यवहार को परिभाषित करता है।
उदाहरण के लिए:
indices[0] = 6
indices[1] = [4, 1]
indices[2] = [[5, 2], [0, 3]]
data[0] = [61, 62]
data[1] = [[41, 42], [11, 12]]
data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]]
merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42],
[51, 52], [61, 62]]
# Apply function (increments x_i) on elements for which a certain condition
# apply (x_i != -1 in this example).
x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4])
condition_mask=tf.not_equal(x,tf.constant(-1.))
partitioned_data = tf.dynamic_partition(
x, tf.cast(condition_mask, tf.int32) , 2)
partitioned_data[1] = partitioned_data[1] + 1.0
condition_indices = tf.dynamic_partition(
tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2)
x = tf.dynamic_stitch(condition_indices, partitioned_data)
# Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain
# unchanged.
सार्वजनिक तरीके
| आउटपुट <T> | आउटपुट के रूप में () टेंसर का प्रतीकात्मक हैंडल लौटाता है। |
| स्थिर <टी> समानांतर गतिशील सिलाई <टी> | |
| आउटपुट <T> | विलय होना () |
विरासत में मिले तरीके
सार्वजनिक तरीके
सार्वजनिक आउटपुट <T> asOutput ()
टेंसर का प्रतीकात्मक हैंडल लौटाता है।
TensorFlow संचालन के इनपुट किसी अन्य TensorFlow ऑपरेशन के आउटपुट हैं। इस पद्धति का उपयोग एक प्रतीकात्मक हैंडल प्राप्त करने के लिए किया जाता है जो इनपुट की गणना का प्रतिनिधित्व करता है।
सार्वजनिक स्थैतिक ParallelDynamicStitch <T> बनाएं ( स्कोप स्कोप, Iterable< ऑपरेंड <Integer>> इंडेक्स, Iterable< ऑपरेंड <T>> डेटा)
एक नया ParallelDynamicStitch ऑपरेशन लपेटकर एक क्लास बनाने की फ़ैक्टरी विधि।
पैरामीटर
| दायरा | वर्तमान दायरा |
|---|
रिटर्न
- ParallelDynamicStitch का एक नया उदाहरण