
|
|
|
 View on GitHub View on GitHub
|
|
|
Welcome to the Intermediate Colab for TensorFlow Decision Forests (TF-DF). In this colab, you will learn about some more advanced capabilities of TF-DF, including how to deal with natural language features.
This colab assumes you are familiar with the concepts presented the Beginner colab, notably about the installation about TF-DF.
In this colab, you will:
Train a Random Forest that consumes text features natively as categorical sets.
Train a Random Forest that consumes text features using a TensorFlow Hub module. In this setting (transfer learning), the module is already pre-trained on a large text corpus.
Train a Gradient Boosted Decision Trees (GBDT) and a Neural Network together. The GBDT will consume the output of the Neural Network.
Setup
# Install TensorFlow Dececision Forestspip install tensorflow_decision_forests
Wurlitzer is needed to display the detailed training logs in Colabs (when using verbose=2 in the model constructor).
pip install wurlitzerImport the necessary libraries.
import os
# Keep using Keras 2
os.environ['TF_USE_LEGACY_KERAS'] = '1'
import tensorflow_decision_forests as tfdf
import numpy as np
import pandas as pd
import tensorflow as tf
import tf_keras
import math
2026-01-12 14:03:19.771892: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:467] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered WARNING: All log messages before absl::InitializeLog() is called are written to STDERR E0000 00:00:1768226599.794652 145231 cuda_dnn.cc:8579] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered E0000 00:00:1768226599.802084 145231 cuda_blas.cc:1407] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered W0000 00:00:1768226599.820724 145231 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once. W0000 00:00:1768226599.820743 145231 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once. W0000 00:00:1768226599.820746 145231 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once. W0000 00:00:1768226599.820748 145231 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
The hidden code cell limits the output height in colab.
from IPython.core.magic import register_line_magic
from IPython.display import Javascript
from IPython.display import display as ipy_display
# Some of the model training logs can cover the full
# screen if not compressed to a smaller viewport.
# This magic allows setting a max height for a cell.
@register_line_magic
def set_cell_height(size):
ipy_display(
Javascript("google.colab.output.setIframeHeight(0, true, {maxHeight: " +
str(size) + "})"))
Use raw text as features
TF-DF can consume categorical-set features natively. Categorical-sets represent text features as bags of words (or n-grams).
For example: "The little blue dog" → {"the", "little", "blue", "dog"}
In this example, you'll will train a Random Forest on the Stanford Sentiment Treebank (SST) dataset. The objective of this dataset is to classify sentences as carrying a positive or negative sentiment. You'll will use the binary classification version of the dataset curated in TensorFlow Datasets.
# Install the TensorFlow Datasets packagepip install tensorflow-datasets -U --quiet
# Load the dataset
import tensorflow_datasets as tfds
all_ds = tfds.load("glue/sst2")
# Display the first 3 examples of the test fold.
for example in all_ds["test"].take(3):
print({attr_name: attr_tensor.numpy() for attr_name, attr_tensor in example.items()})
I0000 00:00:1768226606.195691 145231 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 13638 MB memory: -> device: 0, name: Tesla T4, pci bus id: 0000:00:05.0, compute capability: 7.5
I0000 00:00:1768226606.197996 145231 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:1 with 13756 MB memory: -> device: 1, name: Tesla T4, pci bus id: 0000:00:06.0, compute capability: 7.5
I0000 00:00:1768226606.200199 145231 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:2 with 13756 MB memory: -> device: 2, name: Tesla T4, pci bus id: 0000:00:07.0, compute capability: 7.5
I0000 00:00:1768226606.202342 145231 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:3 with 13756 MB memory: -> device: 3, name: Tesla T4, pci bus id: 0000:00:08.0, compute capability: 7.5
{'idx': np.int32(163), 'label': np.int64(-1), 'sentence': b'not even the hanson brothers can save it'}
{'idx': np.int32(131), 'label': np.int64(-1), 'sentence': b'strong setup and ambitious goals fade as the film descends into unsophisticated scare tactics and b-film thuggery .'}
{'idx': np.int32(1579), 'label': np.int64(-1), 'sentence': b'too timid to bring a sense of closure to an ugly chapter of the twentieth century .'}
2026-01-12 14:03:26.846767: W tensorflow/core/kernels/data/cache_dataset_ops.cc:916] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
The dataset is modified as follows:
- The raw labels are integers in
{-1, 1}, but the learning algorithm expects positive integer labels e.g.{0, 1}. Therefore, the labels are transformed as follows:new_labels = (original_labels + 1) / 2. - A batch-size of 64 is applied to make reading the dataset more efficient.
- The
sentenceattribute needs to be tokenized, i.e."hello world" -> ["hello", "world"].
Details: Some decision forest learning algorithms do not need a validation dataset (e.g. Random Forests) while others do (e.g. Gradient Boosted Trees in some cases). Since each learning algorithm under TF-DF can use validation data differently, TF-DF handles train/validation splits internally. As a result, when you have a training and validation sets, they can always be concatenated as input to the learning algorithm.
def prepare_dataset(example):
label = (example["label"] + 1) // 2
return {"sentence" : tf.strings.split(example["sentence"])}, label
train_ds = all_ds["train"].batch(100).map(prepare_dataset)
test_ds = all_ds["validation"].batch(100).map(prepare_dataset)
Finally, train and evaluate the model as usual. TF-DF automatically detects multi-valued categorical features as categorical-set.
%set_cell_height 300
# Specify the model.
model_1 = tfdf.keras.RandomForestModel(num_trees=30, verbose=2)
# Train the model.
model_1.fit(x=train_ds)
<IPython.core.display.Javascript object>
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpptsslxr7 as temporary training directory
Reading training dataset...
Training tensor examples:
Features: {'sentence': tf.RaggedTensor(values=Tensor("data:0", shape=(None,), dtype=string), row_splits=Tensor("data_1:0", shape=(None,), dtype=int64))}
Label: Tensor("data_2:0", shape=(None,), dtype=int64)
Weights: None
Normalized tensor features:
{'sentence': SemanticTensor(semantic=<Semantic.CATEGORICAL_SET: 4>, tensor=tf.RaggedTensor(values=Tensor("data:0", shape=(None,), dtype=string), row_splits=Tensor("data_1:0", shape=(None,), dtype=int64)))}
Training dataset read in 0:00:04.512591. Found 67349 examples.
Training model...
Standard output detected as not visible to the user e.g. running in a notebook. Creating a training log redirection. If training gets stuck, try calling tfdf.keras.set_training_logs_redirection(False).
Model trained in 0:00:57.327382
Compiling model...
Model compiled.
<tf_keras.src.callbacks.History at 0x7fcccc017d00>
In the previous logs, note that sentence is a CATEGORICAL_SET feature.
The model is evaluated as usual:
model_1.compile(metrics=["accuracy"])
evaluation = model_1.evaluate(test_ds)
print(f"BinaryCrossentropyloss: {evaluation[0]}")
print(f"Accuracy: {evaluation[1]}")
9/9 [==============================] - 1s 5ms/step - loss: 0.0000e+00 - accuracy: 0.7638 BinaryCrossentropyloss: 0.0 Accuracy: 0.7637614607810974
The training logs looks are follow:
import matplotlib.pyplot as plt
logs = model_1.make_inspector().training_logs()
plt.plot([log.num_trees for log in logs], [log.evaluation.accuracy for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("Out-of-bag accuracy")
pass
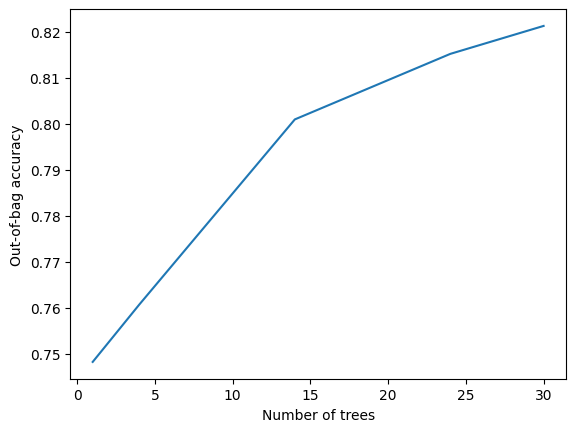
More trees would probably be beneficial (I am sure of it because I tried :p).
Use a pretrained text embedding
The previous example trained a Random Forest using raw text features. This example will use a pre-trained TF-Hub embedding to convert text features into a dense embedding, and then train a Random Forest on top of it. In this situation, the Random Forest will only "see" the numerical output of the embedding (i.e. it will not see the raw text).
In this experiment, will use the Universal-Sentence-Encoder. Different pre-trained embeddings might be suited for different types of text (e.g. different language, different task) but also for other type of structured features (e.g. images).
The embedding module can be applied in one of two places:
- During the dataset preparation.
- In the pre-processing stage of the model.
The second option is often preferable: Packaging the embedding in the model makes the model easier to use (and harder to misuse).
First install TF-Hub:
pip install --upgrade tensorflow-hubUnlike before, you don't need to tokenize the text.
def prepare_dataset(example):
label = (example["label"] + 1) // 2
return {"sentence" : example["sentence"]}, label
train_ds = all_ds["train"].batch(100).map(prepare_dataset)
test_ds = all_ds["validation"].batch(100).map(prepare_dataset)
%set_cell_height 300
import tensorflow_hub as hub
# NNLM (https://tfhub.dev/google/nnlm-en-dim128/2) is also a good choice.
hub_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
embedding = hub.KerasLayer(hub_url)
sentence = tf_keras.layers.Input(shape=(), name="sentence", dtype=tf.string)
embedded_sentence = embedding(sentence)
raw_inputs = {"sentence": sentence}
processed_inputs = {"embedded_sentence": embedded_sentence}
preprocessor = tf_keras.Model(inputs=raw_inputs, outputs=processed_inputs)
model_2 = tfdf.keras.RandomForestModel(
preprocessing=preprocessor,
num_trees=100)
model_2.fit(x=train_ds)
<IPython.core.display.Javascript object>
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_hub/__init__.py:61: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
from pkg_resources import parse_version
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpycpyqk0x as temporary training directory
Reading training dataset...
Training dataset read in 0:00:21.852133. Found 67349 examples.
Training model...
I0000 00:00:1768226709.610559 145231 kernel.cc:782] Start Yggdrasil model training
I0000 00:00:1768226709.610630 145231 kernel.cc:783] Collect training examples
I0000 00:00:1768226709.610639 145231 kernel.cc:795] Dataspec guide:
column_guides {
column_name_pattern: "^__LABEL$"
type: CATEGORICAL
categorial {
min_vocab_frequency: 0
max_vocab_count: -1
}
}
default_column_guide {
categorial {
max_vocab_count: 2000
}
discretized_numerical {
maximum_num_bins: 255
}
}
ignore_columns_without_guides: false
detect_numerical_as_discretized_numerical: false
I0000 00:00:1768226709.611935 145231 kernel.cc:401] Number of batches: 674
I0000 00:00:1768226709.611960 145231 kernel.cc:402] Number of examples: 67349
I0000 00:00:1768226709.847912 145231 kernel.cc:802] Training dataset:
Number of records: 67349
Number of columns: 513
Number of columns by type:
NUMERICAL: 512 (99.8051%)
CATEGORICAL: 1 (0.194932%)
Columns:
NUMERICAL: 512 (99.8051%)
1: "embedded_sentence.0" NUMERICAL mean:-0.00405803 min:-0.110598 max:0.113378 sd:0.0382544
2: "embedded_sentence.1" NUMERICAL mean:0.0020755 min:-0.120324 max:0.106003 sd:0.0434171
3: "embedded_sentence.10" NUMERICAL mean:0.0143459 min:-0.1118 max:0.118193 sd:0.039633
4: "embedded_sentence.100" NUMERICAL mean:0.003884 min:-0.104019 max:0.127238 sd:0.0431
5: "embedded_sentence.101" NUMERICAL mean:-0.0132592 min:-0.133774 max:0.125128 sd:0.0465773
6: "embedded_sentence.102" NUMERICAL mean:0.00732224 min:-0.114158 max:0.135181 sd:0.0462208
7: "embedded_sentence.103" NUMERICAL mean:-0.00316622 min:-0.115661 max:0.110651 sd:0.0393422
8: "embedded_sentence.104" NUMERICAL mean:-0.000406039 min:-0.115186 max:0.115727 sd:0.0404569
9: "embedded_sentence.105" NUMERICAL mean:0.01286 min:-0.10478 max:0.116059 sd:0.0408527
10: "embedded_sentence.106" NUMERICAL mean:-0.0200857 min:-0.112344 max:0.115696 sd:0.0348447
11: "embedded_sentence.107" NUMERICAL mean:-0.0008812 min:-0.117538 max:0.128118 sd:0.0397207
12: "embedded_sentence.108" NUMERICAL mean:-0.0153816 min:-0.119853 max:0.111478 sd:0.0408014
13: "embedded_sentence.109" NUMERICAL mean:0.0226631 min:-0.115775 max:0.109245 sd:0.0344709
14: "embedded_sentence.11" NUMERICAL mean:7.16192e-05 min:-0.10631 max:0.107239 sd:0.0399338
15: "embedded_sentence.110" NUMERICAL mean:-0.0117186 min:-0.12628 max:0.0972872 sd:0.043443
16: "embedded_sentence.111" NUMERICAL mean:-0.0195 min:-0.138677 max:0.111032 sd:0.0530712
17: "embedded_sentence.112" NUMERICAL mean:-0.00883525 min:-0.125434 max:0.115491 sd:0.039556
18: "embedded_sentence.113" NUMERICAL mean:-0.0004395 min:-0.106039 max:0.1141 sd:0.0441183
19: "embedded_sentence.114" NUMERICAL mean:-0.00404027 min:-0.131798 max:0.106558 sd:0.040391
20: "embedded_sentence.115" NUMERICAL mean:0.0164961 min:-0.137229 max:0.11088 sd:0.0396261
21: "embedded_sentence.116" NUMERICAL mean:-0.0163338 min:-0.109692 max:0.115104 sd:0.0396108
22: "embedded_sentence.117" NUMERICAL mean:-0.000866381 min:-0.111258 max:0.110021 sd:0.0413076
23: "embedded_sentence.118" NUMERICAL mean:0.00925641 min:-0.117275 max:0.109073 sd:0.0392531
24: "embedded_sentence.119" NUMERICAL mean:0.0111224 min:-0.108271 max:0.11018 sd:0.0438516
25: "embedded_sentence.12" NUMERICAL mean:-0.0115011 min:-0.115238 max:0.115996 sd:0.039107
26: "embedded_sentence.120" NUMERICAL mean:-0.0109583 min:-0.117243 max:0.113314 sd:0.03753
27: "embedded_sentence.121" NUMERICAL mean:0.0143342 min:-0.109885 max:0.121471 sd:0.0401907
28: "embedded_sentence.122" NUMERICAL mean:-0.00603129 min:-0.111126 max:0.106422 sd:0.0401383
29: "embedded_sentence.123" NUMERICAL mean:-0.00175511 min:-0.115219 max:0.103571 sd:0.0388962
30: "embedded_sentence.124" NUMERICAL mean:-0.0119755 min:-0.119062 max:0.122632 sd:0.0447561
31: "embedded_sentence.125" NUMERICAL mean:0.00210507 min:-0.116783 max:0.125758 sd:0.0469827
32: "embedded_sentence.126" NUMERICAL mean:-0.0166424 min:-0.109771 max:0.13027 sd:0.0399639
33: "embedded_sentence.127" NUMERICAL mean:-0.0462275 min:-0.137916 max:0.106133 sd:0.0478679
34: "embedded_sentence.128" NUMERICAL mean:0.0101449 min:-0.134851 max:0.118003 sd:0.0415072
35: "embedded_sentence.129" NUMERICAL mean:0.0119622 min:-0.106398 max:0.122529 sd:0.047894
36: "embedded_sentence.13" NUMERICAL mean:-0.0179365 min:-0.133052 max:0.120982 sd:0.0461472
37: "embedded_sentence.130" NUMERICAL mean:-0.0109302 min:-0.127096 max:0.102555 sd:0.0407236
38: "embedded_sentence.131" NUMERICAL mean:-2.30421e-05 min:-0.0958128 max:0.116109 sd:0.0393919
39: "embedded_sentence.132" NUMERICAL mean:0.00622466 min:-0.118524 max:0.171935 sd:0.0435631
40: "embedded_sentence.133" NUMERICAL mean:0.00537511 min:-0.0999398 max:0.143991 sd:0.0431652
41: "embedded_sentence.134" NUMERICAL mean:0.0111946 min:-0.101547 max:0.105716 sd:0.0365295
42: "embedded_sentence.135" NUMERICAL mean:-0.0123165 min:-0.118347 max:0.113619 sd:0.0422525
43: "embedded_sentence.136" NUMERICAL mean:0.00882626 min:-0.118642 max:0.115052 sd:0.0393646
44: "embedded_sentence.137" NUMERICAL mean:0.0106701 min:-0.108036 max:0.109746 sd:0.0405698
45: "embedded_sentence.138" NUMERICAL mean:-0.0130655 min:-0.148064 max:0.118745 sd:0.047092
46: "embedded_sentence.139" NUMERICAL mean:0.00256777 min:-0.108547 max:0.102547 sd:0.0388182
47: "embedded_sentence.14" NUMERICAL mean:0.00090757 min:-0.124092 max:0.111964 sd:0.0393761
48: "embedded_sentence.140" NUMERICAL mean:-0.00255201 min:-0.113298 max:0.120327 sd:0.0469564
49: "embedded_sentence.141" NUMERICAL mean:-0.0123127 min:-0.124039 max:0.110528 sd:0.047218
50: "embedded_sentence.142" NUMERICAL mean:0.00659571 min:-0.106909 max:0.126327 sd:0.0444828
51: "embedded_sentence.143" NUMERICAL mean:0.00838607 min:-0.121819 max:0.108286 sd:0.0409403
52: "embedded_sentence.144" NUMERICAL mean:-0.00504916 min:-0.117741 max:0.109832 sd:0.0402179
53: "embedded_sentence.145" NUMERICAL mean:-0.0135 min:-0.112358 max:0.108238 sd:0.0393695
54: "embedded_sentence.146" NUMERICAL mean:-0.00551706 min:-0.108132 max:0.103118 sd:0.0375181
55: "embedded_sentence.147" NUMERICAL mean:0.00226707 min:-0.109358 max:0.117688 sd:0.0416268
56: "embedded_sentence.148" NUMERICAL mean:-0.0083477 min:-0.113886 max:0.105174 sd:0.0379074
57: "embedded_sentence.149" NUMERICAL mean:-0.0029158 min:-0.104327 max:0.10898 sd:0.0394245
58: "embedded_sentence.15" NUMERICAL mean:-0.0465314 min:-0.127274 max:0.115007 sd:0.0410307
59: "embedded_sentence.150" NUMERICAL mean:-0.00857055 min:-0.11757 max:0.108206 sd:0.0416898
60: "embedded_sentence.151" NUMERICAL mean:0.00697777 min:-0.104269 max:0.109967 sd:0.0353302
61: "embedded_sentence.152" NUMERICAL mean:-0.0220037 min:-0.122602 max:0.105503 sd:0.0429071
62: "embedded_sentence.153" NUMERICAL mean:-0.00103943 min:-0.109326 max:0.112115 sd:0.0413219
63: "embedded_sentence.154" NUMERICAL mean:-0.010306 min:-0.106116 max:0.112624 sd:0.0392094
64: "embedded_sentence.155" NUMERICAL mean:-0.0128503 min:-0.133511 max:0.129721 sd:0.0417087
65: "embedded_sentence.156" NUMERICAL mean:-0.00796016 min:-0.10801 max:0.111555 sd:0.0401771
66: "embedded_sentence.157" NUMERICAL mean:-0.0263644 min:-0.135057 max:0.131898 sd:0.0473006
67: "embedded_sentence.158" NUMERICAL mean:0.0157188 min:-0.109795 max:0.13194 sd:0.0423631
68: "embedded_sentence.159" NUMERICAL mean:0.00616692 min:-0.0996693 max:0.121898 sd:0.0405747
69: "embedded_sentence.16" NUMERICAL mean:0.0122186 min:-0.132531 max:0.112023 sd:0.0412513
70: "embedded_sentence.160" NUMERICAL mean:0.00140896 min:-0.125797 max:0.10415 sd:0.0422833
71: "embedded_sentence.161" NUMERICAL mean:-0.00968098 min:-0.107129 max:0.109673 sd:0.0389125
72: "embedded_sentence.162" NUMERICAL mean:0.0174977 min:-0.102559 max:0.117249 sd:0.0394065
73: "embedded_sentence.163" NUMERICAL mean:-0.01559 min:-0.117529 max:0.132716 sd:0.0422287
74: "embedded_sentence.164" NUMERICAL mean:0.0103332 min:-0.131635 max:0.117116 sd:0.0432647
75: "embedded_sentence.165" NUMERICAL mean:0.0164754 min:-0.111395 max:0.106868 sd:0.03591
76: "embedded_sentence.166" NUMERICAL mean:-0.0300909 min:-0.110079 max:0.138071 sd:0.0393771
77: "embedded_sentence.167" NUMERICAL mean:-0.00284721 min:-0.113047 max:0.1113 sd:0.0402787
78: "embedded_sentence.168" NUMERICAL mean:0.0128449 min:-0.123295 max:0.101678 sd:0.035443
79: "embedded_sentence.169" NUMERICAL mean:-0.0018307 min:-0.113497 max:0.108755 sd:0.0385736
80: "embedded_sentence.17" NUMERICAL mean:0.0112924 min:-0.118483 max:0.109047 sd:0.0411375
81: "embedded_sentence.170" NUMERICAL mean:-0.0154471 min:-0.123997 max:0.0995884 sd:0.039095
82: "embedded_sentence.171" NUMERICAL mean:-0.0115266 min:-0.135629 max:0.111586 sd:0.0564499
83: "embedded_sentence.172" NUMERICAL mean:-0.00305818 min:-0.108149 max:0.125287 sd:0.0416153
84: "embedded_sentence.173" NUMERICAL mean:-0.0192183 min:-0.128661 max:0.111586 sd:0.0445312
85: "embedded_sentence.174" NUMERICAL mean:-0.00547071 min:-0.106778 max:0.107318 sd:0.0412694
86: "embedded_sentence.175" NUMERICAL mean:0.00303105 min:-0.114183 max:0.11671 sd:0.037753
87: "embedded_sentence.176" NUMERICAL mean:0.0200632 min:-0.119154 max:0.12262 sd:0.0449386
88: "embedded_sentence.177" NUMERICAL mean:0.00830421 min:-0.106867 max:0.108159 sd:0.04212
89: "embedded_sentence.178" NUMERICAL mean:0.0087977 min:-0.119236 max:0.0975504 sd:0.0365596
90: "embedded_sentence.179" NUMERICAL mean:-0.0224472 min:-0.141699 max:0.121597 sd:0.0451563
91: "embedded_sentence.18" NUMERICAL mean:0.0161367 min:-0.103659 max:0.106467 sd:0.0396646
92: "embedded_sentence.180" NUMERICAL mean:0.00700458 min:-0.122243 max:0.106828 sd:0.0406674
93: "embedded_sentence.181" NUMERICAL mean:0.015665 min:-0.123784 max:0.117493 sd:0.0423638
94: "embedded_sentence.182" NUMERICAL mean:0.00455087 min:-0.130433 max:0.129947 sd:0.0468312
95: "embedded_sentence.183" NUMERICAL mean:0.00469912 min:-0.105513 max:0.115268 sd:0.0422015
96: "embedded_sentence.184" NUMERICAL mean:0.00118913 min:-0.132085 max:0.119005 sd:0.0425006
97: "embedded_sentence.185" NUMERICAL mean:-0.0091211 min:-0.105384 max:0.107321 sd:0.0394833
98: "embedded_sentence.186" NUMERICAL mean:0.00847289 min:-0.100142 max:0.11416 sd:0.0354507
99: "embedded_sentence.187" NUMERICAL mean:0.00401229 min:-0.0997345 max:0.0985512 sd:0.0330015
100: "embedded_sentence.188" NUMERICAL mean:0.0375059 min:-0.107009 max:0.147423 sd:0.0457626
101: "embedded_sentence.189" NUMERICAL mean:-0.0108558 min:-0.158798 max:0.124698 sd:0.0429543
102: "embedded_sentence.19" NUMERICAL mean:0.000475908 min:-0.126049 max:0.109106 sd:0.0416907
103: "embedded_sentence.190" NUMERICAL mean:0.0055649 min:-0.102637 max:0.112907 sd:0.0428818
104: "embedded_sentence.191" NUMERICAL mean:0.0115727 min:-0.0992453 max:0.114756 sd:0.0385606
105: "embedded_sentence.192" NUMERICAL mean:0.0188207 min:-0.10799 max:0.126446 sd:0.0480458
106: "embedded_sentence.193" NUMERICAL mean:-0.0231128 min:-0.125829 max:0.098485 sd:0.0413616
107: "embedded_sentence.194" NUMERICAL mean:-0.0125518 min:-0.118983 max:0.111524 sd:0.0394032
108: "embedded_sentence.195" NUMERICAL mean:-0.00734374 min:-0.140773 max:0.124731 sd:0.048662
109: "embedded_sentence.196" NUMERICAL mean:0.0147101 min:-0.109208 max:0.114207 sd:0.0392372
110: "embedded_sentence.197" NUMERICAL mean:0.00382817 min:-0.0960263 max:0.109744 sd:0.0343786
111: "embedded_sentence.198" NUMERICAL mean:0.0148358 min:-0.121261 max:0.137886 sd:0.0396124
112: "embedded_sentence.199" NUMERICAL mean:0.0139377 min:-0.133057 max:0.129123 sd:0.0434494
113: "embedded_sentence.2" NUMERICAL mean:0.00763253 min:-0.102393 max:0.126418 sd:0.0391092
114: "embedded_sentence.20" NUMERICAL mean:0.0067624 min:-0.117482 max:0.140442 sd:0.0473874
115: "embedded_sentence.200" NUMERICAL mean:-0.022174 min:-0.135182 max:0.0998059 sd:0.0447171
116: "embedded_sentence.201" NUMERICAL mean:0.00918432 min:-0.129768 max:0.104146 sd:0.0407455
117: "embedded_sentence.202" NUMERICAL mean:6.68973e-05 min:-0.108528 max:0.112123 sd:0.039669
118: "embedded_sentence.203" NUMERICAL mean:-0.0211792 min:-0.138447 max:0.151201 sd:0.0475548
119: "embedded_sentence.204" NUMERICAL mean:0.0149458 min:-0.114192 max:0.121993 sd:0.0451805
120: "embedded_sentence.205" NUMERICAL mean:-0.000877425 min:-0.106281 max:0.110069 sd:0.0399283
121: "embedded_sentence.206" NUMERICAL mean:0.00135042 min:-0.122458 max:0.133155 sd:0.0490798
122: "embedded_sentence.207" NUMERICAL mean:-0.00564686 min:-0.0980346 max:0.124534 sd:0.0381495
123: "embedded_sentence.208" NUMERICAL mean:-0.0137386 min:-0.104712 max:0.116268 sd:0.0380542
124: "embedded_sentence.209" NUMERICAL mean:-0.000932724 min:-0.120575 max:0.106782 sd:0.0389735
125: "embedded_sentence.21" NUMERICAL mean:-0.0103802 min:-0.141084 max:0.11384 sd:0.0543033
126: "embedded_sentence.210" NUMERICAL mean:-0.0221436 min:-0.11615 max:0.110612 sd:0.0375885
127: "embedded_sentence.211" NUMERICAL mean:0.00739621 min:-0.107881 max:0.139283 sd:0.0380559
128: "embedded_sentence.212" NUMERICAL mean:0.000771754 min:-0.130277 max:0.118151 sd:0.0457612
129: "embedded_sentence.213" NUMERICAL mean:-0.00631693 min:-0.113811 max:0.122369 sd:0.0420019
130: "embedded_sentence.214" NUMERICAL mean:-0.0190752 min:-0.130814 max:0.12256 sd:0.0462656
131: "embedded_sentence.215" NUMERICAL mean:0.00351438 min:-0.119497 max:0.112531 sd:0.0389063
132: "embedded_sentence.216" NUMERICAL mean:-0.00563816 min:-0.113327 max:0.108573 sd:0.0398438
133: "embedded_sentence.217" NUMERICAL mean:-0.0128165 min:-0.152494 max:0.112129 sd:0.0435284
134: "embedded_sentence.218" NUMERICAL mean:-0.000746105 min:-0.115932 max:0.103357 sd:0.0396475
135: "embedded_sentence.219" NUMERICAL mean:0.00706257 min:-0.105737 max:0.115808 sd:0.0415758
136: "embedded_sentence.22" NUMERICAL mean:0.00470285 min:-0.108062 max:0.127381 sd:0.0465233
137: "embedded_sentence.220" NUMERICAL mean:0.000614336 min:-0.120866 max:0.10502 sd:0.036915
138: "embedded_sentence.221" NUMERICAL mean:-0.00315481 min:-0.110209 max:0.126778 sd:0.0398762
139: "embedded_sentence.222" NUMERICAL mean:-0.0055338 min:-0.112974 max:0.111057 sd:0.0367833
140: "embedded_sentence.223" NUMERICAL mean:0.0129532 min:-0.108908 max:0.112232 sd:0.0406737
141: "embedded_sentence.224" NUMERICAL mean:-0.0195448 min:-0.112833 max:0.122565 sd:0.0423641
142: "embedded_sentence.225" NUMERICAL mean:0.00715641 min:-0.136763 max:0.123146 sd:0.0455536
143: "embedded_sentence.226" NUMERICAL mean:0.0105978 min:-0.121166 max:0.125465 sd:0.0433322
144: "embedded_sentence.227" NUMERICAL mean:-0.00822156 min:-0.131487 max:0.125193 sd:0.0440489
145: "embedded_sentence.228" NUMERICAL mean:0.0119113 min:-0.109956 max:0.107868 sd:0.0382855
146: "embedded_sentence.229" NUMERICAL mean:-0.00739044 min:-0.116468 max:0.109886 sd:0.0406385
147: "embedded_sentence.23" NUMERICAL mean:0.00203851 min:-0.116632 max:0.116226 sd:0.0400387
148: "embedded_sentence.230" NUMERICAL mean:0.00819752 min:-0.100016 max:0.125019 sd:0.041894
149: "embedded_sentence.231" NUMERICAL mean:-0.00420582 min:-0.139816 max:0.138647 sd:0.0446602
150: "embedded_sentence.232" NUMERICAL mean:0.00810722 min:-0.11301 max:0.106853 sd:0.0400325
151: "embedded_sentence.233" NUMERICAL mean:0.0561205 min:-0.110581 max:0.182054 sd:0.0645425
152: "embedded_sentence.234" NUMERICAL mean:0.0202212 min:-0.109987 max:0.116562 sd:0.0374199
153: "embedded_sentence.235" NUMERICAL mean:-0.0125547 min:-0.104766 max:0.115993 sd:0.0383767
154: "embedded_sentence.236" NUMERICAL mean:0.00228544 min:-0.126092 max:0.125991 sd:0.0403744
155: "embedded_sentence.237" NUMERICAL mean:-0.00306858 min:-0.107907 max:0.109284 sd:0.0409564
156: "embedded_sentence.238" NUMERICAL mean:-0.009308
I0000 00:00:1768226709.848315 145231 kernel.cc:818] Configure learner
I0000 00:00:1768226709.848852 145231 kernel.cc:831] Training config:
learner: "RANDOM_FOREST"
features: "^embedded_sentence\\.0$"
features: "^embedded_sentence\\.1$"
features: "^embedded_sentence\\.10$"
features: "^embedded_sentence\\.100$"
features: "^embedded_sentence\\.101$"
features: "^embedded_sentence\\.102$"
features: "^embedded_sentence\\.103$"
features: "^embedded_sentence\\.104$"
features: "^embedded_sentence\\.105$"
features: "^embedded_sentence\\.106$"
features: "^embedded_sentence\\.107$"
features: "^embedded_sentence\\.108$"
features: "^embedded_sentence\\.109$"
features: "^embedded_sentence\\.11$"
features: "^embedded_sentence\\.110$"
features: "^embedded_sentence\\.111$"
features: "^embedded_sentence\\.112$"
features: "^embedded_sentence\\.113$"
features: "^embedded_sentence\\.114$"
features: "^embedded_sentence\\.115$"
features: "^embedded_sentence\\.116$"
features: "^embedded_sentence\\.117$"
features: "^embedded_sentence\\.118$"
features: "^embedded_sentence\\.119$"
features: "^embedded_sentence\\.12$"
features: "^embedded_sentence\\.120$"
features: "^embedded_sentence\\.121$"
features: "^embedded_sentence\\.122$"
features: "^embedded_sentence\\.123$"
features: "^embedded_sentence\\.124$"
features: "^embedded_sentence\\.125$"
features: "^embedded_sentence\\.126$"
features: "^embedded_sentence\\.127$"
features: "^embedded_sentence\\.128$"
features: "^embedded_sentence\\.129$"
features: "^embedded_sentence\\.13$"
features: "^embedded_sentence\\.130$"
features: "^embedded_sentence\\.131$"
features: "^embedded_sentence\\.132$"
features: "^embedded_sentence\\.133$"
features: "^embedded_sentence\\.134$"
features: "^embedded_sentence\\.135$"
features: "^embedded_sentence\\.136$"
features: "^embedded_sentence\\.137$"
features: "^embedded_sentence\\.138$"
features: "^embedded_sentence\\.139$"
features: "^embedded_sentence\\.14$"
features: "^embedded_sentence\\.140$"
features: "^embedded_sentence\\.141$"
features: "^embedded_sentence\\.142$"
features: "^embedded_sentence\\.143$"
features: "^embedded_sentence\\.144$"
features: "^embedded_sentence\\.145$"
features: "^embedded_sentence\\.146$"
features: "^embedded_sentence\\.147$"
features: "^embedded_sentence\\.148$"
features: "^embedded_sentence\\.149$"
features: "^embedded_sentence\\.15$"
features: "^embedded_sentence\\.150$"
features: "^embedded_sentence\\.151$"
features: "^embedded_sentence\\.152$"
features: "^embedded_sentence\\.153$"
features: "^embedded_sentence\\.154$"
features: "^embedded_sentence\\.155$"
features: "^embedded_sentence\\.156$"
features: "^embedded_sentence\\.157$"
features: "^embedded_sentence\\.158$"
features: "^embedded_sentence\\.159$"
features: "^embedded_sentence\\.16$"
features: "^embedded_sentence\\.160$"
features: "^embedded_sentence\\.161$"
features: "^embedded_sentence\\.162$"
features: "^embedded_sentence\\.163$"
features: "^embedded_sentence\\.164$"
features: "^embedded_sentence\\.165$"
features: "^embedded_sentence\\.166$"
features: "^embedded_sentence\\.167$"
features: "^embedded_sentence\\.168$"
features: "^embedded_sentence\\.169$"
features: "^embedded_sentence\\.17$"
features: "^embedded_sentence\\.170$"
features: "^embedded_sentence\\.171$"
features: "^embedded_sentence\\.172$"
features: "^embedded_sentence\\.173$"
features: "^embedded_sentence\\.174$"
features: "^embedded_sentence\\.175$"
features: "^embedded_sentence\\.176$"
features: "^embedded_sentence\\.177$"
features: "^embedded_sentence\\.178$"
features: "^embedded_sentence\\.179$"
features: "^embedded_sentence\\.18$"
features: "^embedded_sentence\\.180$"
features: "^embedded_sentence\\.181$"
features: "^embedded_sentence\\.182$"
features: "^embedded_sentence\\.183$"
features: "^embedded_sentence\\.184$"
features: "^embedded_sentence\\.185$"
features: "^embedded_sentence\\.186$"
features: "^embedded_sentence\\.187$"
features: "^embedded_sentence\\.188$"
features: "^embedded_sentence\\.189$"
features: "^embedded_sentence\\.19$"
features: "^embedded_sentence\\.190$"
features: "^embedded_sentence\\.191$"
features: "^embedded_sentence\\.192$"
features: "^embedded_sentence\\.193$"
features: "^embedded_sentence\\.194$"
features: "^embedded_sentence\\.195$"
features: "^embedded_sentence\\.196$"
features: "^embedded_sentence\\.197$"
features: "^embedded_sentence\\.198$"
features: "^embedded_sentence\\.199$"
features: "^embedded_sentence\\.2$"
features: "^embedded_sentence\\.20$"
features: "^embedded_sentence\\.200$"
features: "^embedded_sentence\\.201$"
features: "^embedded_sentence\\.202$"
features: "^embedded_sentence\\.203$"
features: "^embedded_sentence\\.204$"
features: "^embedded_sentence\\.205$"
features: "^embedded_sentence\\.206$"
features: "^embedded_sentence\\.207$"
features: "^embedded_sentence\\.208$"
features: "^embedded_sentence\\.209$"
features: "^embedded_sentence\\.21$"
features: "^embedded_sentence\\.210$"
features: "^embedded_sentence\\.211$"
features: "^embedded_sentence\\.212$"
features: "^embedded_sentence\\.213$"
features: "^embedded_sentence\\.214$"
features: "^embedded_sentence\\.215$"
features: "^embedded_sentence\\.216$"
features: "^embedded_sentence\\.217$"
features: "^embedded_sentence\\.218$"
features: "^embedded_sentence\\.219$"
features: "^embedded_sentence\\.22$"
features: "^embedded_sentence\\.220$"
features: "^embedded_sentence\\.221$"
features: "^embedded_sentence\\.222$"
features: "^embedded_sentence\\.223$"
features: "^embedded_sentence\\.224$"
features: "^embedded_sentence\\.225$"
features: "^embedded_sentence\\.226$"
features: "^embedded_sentence\\.227$"
features: "^embedded_sentence\\.228$"
features: "^embedded_sentence\\.229$"
features: "^embedded_sentence\\.23$"
features: "^embedded_sentence\\.230$"
features: "^embedded_sentence\\.231$"
features: "^embedded_sentence\\.232$"
features: "^embedded_sentence\\.233$"
features: "^embedded_sentence\\.234$"
features: "^embedded_sentence\\.235$"
features: "^embedded_sentence\\.236$"
features: "^embedded_sentence\\.237$"
features: "^embedded_sentence\\.238$"
features: "^embedded_sentence\\.239$"
features: "^embedded_sentence\\.24$"
features: "^embedded_sentence\\.240$"
features: "^embedded_sentence\\.241$"
features: "^embedded_sentence\\.242$"
features: "^embedded_sentence\\.243$"
features: "^embedded_sentence\\.244$"
features: "^embedded_sentence\\.245$"
features: "^embedded_sentence\\.246$"
features: "^embedded_sentence\\.247$"
features: "^embedded_sentence\\.248$"
features: "^embedded_sentence\\.249$"
features: "^embedded_sentence\\.25$"
features: "^embedded_sentence\\.250$"
features: "^embedded_sentence\\.251$"
features: "^embedded_sentence\\.252$"
features: "^embedded_sentence\\.253$"
features: "^embedded_sentence\\.254$"
features: "^embedded_sentence\\.255$"
features: "^embedded_sentence\\.256$"
features: "^embedded_sentence\\.257$"
features: "^embedded_sentence\\.258$"
features: "^embedded_sentence\\.259$"
features: "^embedded_sentence\\.26$"
features: "^embedded_sentence\\.260$"
features: "^embedded_sentence\\.261$"
features: "^embedded_sentence\\.262$"
features: "^embedded_sentence\\.263$"
features: "^embedded_sentence\\.264$"
features: "^embedded_sentence\\.265$"
features: "^embedded_sentence\\.266$"
features: "^embedded_sentence\\.267$"
features: "^embedded_sentence\\.268$"
features: "^embedded_sentence\\.269$"
features: "^embedded_sentence\\.27$"
features: "^embedded_sentence\\.270$"
features: "^embedded_sentence\\.271$"
features: "^embedded_sentence\\.272$"
features: "^embedded_sentence\\.273$"
features: "^embedded_sentence\\.274$"
features: "^embedded_sentence\\.275$"
features: "^embedded_sentence\\.276$"
features: "^embedded_sentence\\.277$"
features: "^embedded_sentence\\.278$"
features: "^embedded_sentence\\.279$"
features: "^embedded_sentence\\.28$"
features: "^embedded_sentence\\.280$"
features: "^embedded_sentence\\.281$"
features: "^embedded_sentence\\.282$"
features: "^embedded_sentence\\.283$"
features: "^embedded_sentence\\.284$"
features: "^embedded_sentence\\.285$"
features: "^embedded_sentence\\.286$"
features: "^embedded_sentence\\.287$"
features: "^embedded_sentence\\.288$"
features: "^embedded_sentence\\.289$"
features: "^embedded_sentence\\.29$"
features: "^embedded_sentence\\.290$"
features: "^embedded_sentence\\.291$"
features: "^embedded_sentence\\.292$"
features: "^embedded_sentence\\.293$"
features: "^embedded_sentence\\.294$"
features: "^embedded_sentence\\.295$"
features: "^embedded_sentence\\.296$"
features: "^embedded_sentence\\.297$"
features: "^embedded_sentence\\.298$"
features: "^embedded_sentence\\.299$"
features: "^embedded_sentence\\.3$"
features: "^embedded_sentence\\.30$"
features: "^embedded_sentence\\.300$"
features: "^embedded_sentence\\.301$"
features: "^embedded_sentence\\.302$"
features: "^embedded_sentence\\.303$"
features: "^embedded_sentence\\.304$"
features: "^embedded_sentence\\.305$"
features: "^embedded_sentence\\.306$"
features: "^embedded_sentence\\.307$"
features: "^embedded_sentence\\.308$"
features: "^embedded_sentence\\.309$"
features: "^embedded_sentence\\.31$"
features: "^embedded_sentence\\.310$"
features: "^embedded_sentence\\.311$"
features: "^embedded_sentence\\.312$"
features: "^embedded_sentence\\.313$"
features: "^embedded_sentence\\.314$"
features: "^embedded_sentence\\.315$"
features: "^embedded_sentence\\.316$"
features: "^embedded_sentence\\.317$"
features: "^embedded_sentence\\.318$"
features: "^embedded_sentence\\.319$"
features: "^embedded_sentence\\.32$"
features: "^embedded_sentence\\.320$"
features: "^embedded_sentence\\.321$"
features: "^embedded_sentence\\.322$"
features: "^embedded_sentence\\.323$"
features: "^embedded_sentence\\.324$"
features: "^embedded_sentence\\.325$"
features: "^embedded_sentence\\.326$"
features: "^embedded_sentence\\.327$"
features: "^embedded_sentence\\.328$"
features: "^embedded_sentence\\.329$"
features: "^embedded_sentence\\.33$"
features: "^embedded_sentence\\.330$"
features: "^embedded_sentence\\.331$"
features: "^embedded_sentence\\.332$"
features: "^embedded_sentence\\.333$"
features: "^embedded_sentence\\.334$"
features: "^embedded_sentence\\.335$"
features: "^embedded_sentence\\.336$"
features: "^embedded_sentence\\.337$"
features: "^embedded_sentence\\.338$"
features: "^embedded_sentence\\.339$"
features: "^embedded_sentence\\.34$"
features: "^embedded_sentence\\.340$"
features: "^embedded_sentence\\.341$"
features: "^embedded_sentence\\.342$"
features: "^embedded_sentence\\.343$"
features: "^embedded_sentence\\.344$"
features: "^embedded_sentence\\.345$"
features: "^embedded_sentence\\.346$"
features: "^embedded_sentence\\.347$"
features: "^embedded_sentence\\.348$"
features: "^embedded_sentence\\.349$"
features: "^embedded_sentence\\.35$"
features: "^embedded_sentence\\.350$"
features: "^embedded_sentence\\.351$"
features: "^embedded_sentence\\.352$"
features: "^embedded_sentence\\.353$"
features: "^embedded_sentence\\.354$"
features: "^embedded_sentence\\.355$"
features: "^embedded_sentence\\.356$"
features: "^embedded_sentence\\.357$"
features: "^embedded_sentence\\.358$"
features: "^embedded_sentence\\.359$"
features: "^embedded_sentence\\.36$"
features: "^embedded_sentence\\.360$"
features: "^embedded_sentence\\.361$"
features: "^embedded_sentence\\.362$"
features: "^embedded_sentence\\.363$"
features: "^embedded_sentence\\.364$"
features: "^embedded_sentence\\.365$"
features: "^embedded_sentence\\.366$"
features: "^embedded_sentence\\.367$"
features: "^embedded_sentence\\.368$"
features: "^embedded_sentence\\.369$"
features: "^embedded_sentence\\.37$"
features: "^embedded_sentence\\.370$"
features: "^embedded_sentence\\.371$"
features: "^embedded_sentence\\.372$"
features: "^embedded_sentence\\.373$"
features: "^embedded_sentence\\.374$"
features: "^embedded_sentence\\.375$"
features: "^embedded_sentence\\.376$"
features: "^embedded_sentence\\.377$"
features: "^embedded_sentence\\.378$"
features: "^embedded_sentence\\.379$"
features: "^embedded_sentence\\.38$"
features: "^embedded_sentence\\.380$"
features: "^embedded_sentence\\.381$"
features: "^embedded_sentence\\.382$"
features: "^embedded_sentence\\.383$"
features: "^embedded_sentence\\.384$"
features: "^embedded_sentence\\.385$"
features: "^embedded_sentence\\.386$"
features: "^embedded_sentence\\.387$"
features: "^embedded_sentence\\.388$"
features: "^embedded_sentence\\.389$"
features: "^embedded_sentence\\.39$"
features: "^embedded_sentence\\.390$"
features: "^embedded_sentence\\.391$"
features: "^embedded_sentence\\.392$"
features: "^embedded_sentence\\.393$"
features: "^embedded_sentence\\.394$"
features: "^embedded_sentence\\.395$"
features: "^embedded_sentence\\.396$"
features: "^embedded_sentence\\.397$"
features: "^embedded_sentence\\.398$"
features: "^embedded_sentence\\.399$"
features: "^embedded_sentence\\.4$"
features: "^embedded_sentence\\.40$"
features: "^embedded_sentence\\.400$"
features: "^embedded_sentence\\.401$"
features: "^embedded_sentence\\.402$"
features: "^embedded_sentence\\.403$"
features: "^embedded_sentence\\.404$"
features: "^embedded_sentence\\.405$"
features: "^embedded_sentence\\.406$"
features: "^embedded_sentence\\.407$"
features: "^embedded_sentence\\.408$"
features: "^embedded_sentence\\.409$"
features: "^embedded_sentence\\.41$"
features: "^embedded_sentence\\.410$"
features: "^embedded_sentence\\.411$"
features: "^embedded_sentence\\.412$"
features: "^embedded_sentence\\.413$"
features: "^embedded_sentence\\.414$"
features: "^embedded_sentence\\.415$"
features: "^embedded_sentence\\.416$"
features: "^embedded_sentence\\.417$"
features: "^embedded_sentence\\.418$"
features: "^embedded_sentence\\.419$"
features: "^embedded_sentence\\.42$"
features: "^embedded_sentence\\.420$"
features: "^embedded_sentence\\.421$"
features: "^embedded_sentence\\.422$"
features: "^embedded_sentence\\.423$"
features: "^embedded_sentence\\.424$"
features: "^embedded_sentence\\.425$"
features: "^embedded_sentence\\.426$"
features: "^embedded_sentence\\.427$"
features: "^embedded_sentence\\.428$"
features: "^embedded_sentence\\.429$"
features: "^embedded_sentence\\.43$"
features: "^embedded_sentence\\.430$"
features: "^embedded_sentence\\.431$"
features: "^embedded_sentence\\.432$"
features: "^embedded_sentence\\.433$"
features: "^embedded_sentence\\.434$"
features: "^embedded_sentence\\.435$"
features: "^embedded_sentence\\.436$"
features: "^embedded_sentence\\.437$"
features: "^embedded_sentence\\.438$"
features: "^embedded_sentence\\.439$"
features: "^embedded_sentence\\.44$"
features: "^embedded_sentence\\.440$"
features: "^embedded_sentence\\.441$"
features: "^embedded_sentence\\.442$"
features: "^embedded_sentence\\.443$"
features: "^embedded_sentence\\.444$"
features: "^embedded_sentence\\.445$"
features: "^embedded_sentence\\.446$"
features: "^embedded_sentence\\.447$"
features: "^embedded_sentence\\.448$"
features: "^embedded_sentence\\.449$"
features: "^embedded_sentence\\.45$"
features: "^embedded_sentence\\.450$"
features: "^embedded_sentence\\.451$"
features: "^emb
I0000 00:00:1768226709.849055 145231 kernel.cc:834] Deployment config:
cache_path: "/tmpfs/tmp/tmpycpyqk0x/working_cache"
num_threads: 32
try_resume_training: true
I0000 00:00:1768226709.849240 146055 kernel.cc:895] Train model
I0000 00:00:1768226709.885396 146055 random_forest.cc:438] Training random forest on 67349 example(s) and 512 feature(s).
I0000 00:00:1768226710.031084 146055 gpu.cc:93] Cannot initialize GPU: Not compiled with GPU support
I0000 00:00:1768226712.676282 146116 random_forest.cc:865] Train tree 1/100 accuracy:0.748707 logloss:9.05753 [index:28 total:2.64s tree:2.64s]
I0000 00:00:1768226713.002599 146109 random_forest.cc:865] Train tree 11/100 accuracy:0.792823 logloss:2.00535 [index:21 total:2.97s tree:2.97s]
I0000 00:00:1768226713.376319 146100 random_forest.cc:865] Train tree 21/100 accuracy:0.827198 logloss:0.715875 [index:12 total:3.34s tree:3.34s]
I0000 00:00:1768226713.767007 146095 random_forest.cc:865] Train tree 31/100 accuracy:0.841542 logloss:0.46829 [index:7 total:3.73s tree:3.73s]
I0000 00:00:1768226715.438123 146096 random_forest.cc:865] Train tree 41/100 accuracy:0.851356 logloss:0.41005 [index:41 total:5.40s tree:2.47s]
I0000 00:00:1768226716.011113 146108 random_forest.cc:865] Train tree 51/100 accuracy:0.856895 logloss:0.386523 [index:51 total:5.98s tree:2.68s]
I0000 00:00:1768226716.399312 146094 random_forest.cc:865] Train tree 61/100 accuracy:0.860161 logloss:0.372076 [index:60 total:6.36s tree:2.72s]
I0000 00:00:1768226718.026808 146111 random_forest.cc:865] Train tree 71/100 accuracy:0.862745 logloss:0.36749 [index:70 total:7.99s tree:2.67s]
I0000 00:00:1768226718.460841 146106 random_forest.cc:865] Train tree 81/100 accuracy:0.864942 logloss:0.36519 [index:80 total:8.43s tree:2.64s]
I0000 00:00:1768226718.807606 146094 random_forest.cc:865] Train tree 91/100 accuracy:0.867095 logloss:0.361846 [index:92 total:8.77s tree:2.41s]
I0000 00:00:1768226719.892202 146090 random_forest.cc:865] Train tree 100/100 accuracy:0.866991 logloss:0.359675 [index:99 total:9.86s tree:1.99s]
I0000 00:00:1768226719.893055 146055 random_forest.cc:949] Final OOB metrics: accuracy:0.866991 logloss:0.359675
I0000 00:00:1768226725.113578 146055 kernel.cc:926] Export model in log directory: /tmpfs/tmp/tmpycpyqk0x with prefix 4cf2ffac08ed4353
I0000 00:00:1768226725.493019 146055 kernel.cc:944] Save model in resources
I0000 00:00:1768226725.497529 145231 abstract_model.cc:921] Model self evaluation:
Number of predictions (without weights): 67349
Number of predictions (with weights): 67349
Task: CLASSIFICATION
Label: __LABEL
Accuracy: 0.866991 CI95[W][0.86482 0.869139]
LogLoss: : 0.359675
ErrorRate: : 0.133009
Default Accuracy: : 0.557826
Default LogLoss: : 0.686445
Default ErrorRate: : 0.442174
Confusion Table:
truth\prediction
1 2
1 25189 4591
2 4367 33202
Total: 67349
Model trained in 0:00:17.978271
Compiling model...
I0000 00:00:1768226727.407098 145231 decision_forest.cc:808] Model loaded with 100 root(s), 567326 node(s), and 512 input feature(s).
I0000 00:00:1768226727.407287 145231 abstract_model.cc:1439] Engine "RandomForestOptPred" built
Model compiled.
<tf_keras.src.callbacks.History at 0x7fcacebd3250>
model_2.compile(metrics=["accuracy"])
evaluation = model_2.evaluate(test_ds)
print(f"BinaryCrossentropyloss: {evaluation[0]}")
print(f"Accuracy: {evaluation[1]}")
9/9 [==============================] - 2s 18ms/step - loss: 0.0000e+00 - accuracy: 0.7890 BinaryCrossentropyloss: 0.0 Accuracy: 0.78899085521698
Note that categorical sets represent text differently from a dense embedding, so it may be useful to use both strategies jointly.
Train a decision tree and neural network together
The previous example used a pre-trained Neural Network (NN) to process the text features before passing them to the Random Forest. This example will train both the Neural Network and the Random Forest from scratch.
TF-DF's Decision Forests do not back-propagate gradients (although this is the subject of ongoing research). Therefore, the training happens in two stages:
- Train the neural-network as a standard classification task:
example → [Normalize] → [Neural Network*] → [classification head] → prediction
*: Training.
- Replace the Neural Network's head (the last layer and the soft-max) with a Random Forest. Train the Random Forest as usual:
example → [Normalize] → [Neural Network] → [Random Forest*] → prediction
*: Training.
Prepare the dataset
This example uses the Palmer's Penguins dataset. See the Beginner colab for details.
First, download the raw data:
wget -q https://storage.googleapis.com/download.tensorflow.org/data/palmer_penguins/penguins.csv -O /tmp/penguins.csvLoad a dataset into a Pandas Dataframe.
dataset_df = pd.read_csv("/tmp/penguins.csv")
# Display the first 3 examples.
dataset_df.head(3)
Prepare the dataset for training.
label = "species"
# Replaces numerical NaN (representing missing values in Pandas Dataframe) with 0s.
# ...Neural Nets don't work well with numerical NaNs.
for col in dataset_df.columns:
if dataset_df[col].dtype not in [str, object]:
dataset_df[col] = dataset_df[col].fillna(0)
# Split the dataset into a training and testing dataset.
def split_dataset(dataset, test_ratio=0.30):
"""Splits a panda dataframe in two."""
test_indices = np.random.rand(len(dataset)) < test_ratio
return dataset[~test_indices], dataset[test_indices]
train_ds_pd, test_ds_pd = split_dataset(dataset_df)
print("{} examples in training, {} examples for testing.".format(
len(train_ds_pd), len(test_ds_pd)))
# Convert the datasets into tensorflow datasets
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label=label)
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_ds_pd, label=label)
239 examples in training, 105 examples for testing.
Build the models
Next create the neural network model using Keras' functional style.
To keep the example simple this model only uses two inputs.
input_1 = tf_keras.Input(shape=(1,), name="bill_length_mm", dtype="float")
input_2 = tf_keras.Input(shape=(1,), name="island", dtype="string")
nn_raw_inputs = [input_1, input_2]
Use preprocessing layers to convert the raw inputs to inputs appropriate for the neural network.
# Normalization.
Normalization = tf_keras.layers.Normalization
CategoryEncoding = tf_keras.layers.CategoryEncoding
StringLookup = tf_keras.layers.StringLookup
values = train_ds_pd["bill_length_mm"].values[:, tf.newaxis]
input_1_normalizer = Normalization()
input_1_normalizer.adapt(values)
values = train_ds_pd["island"].values
input_2_indexer = StringLookup(max_tokens=32)
input_2_indexer.adapt(values)
input_2_onehot = CategoryEncoding(output_mode="binary", max_tokens=32)
normalized_input_1 = input_1_normalizer(input_1)
normalized_input_2 = input_2_onehot(input_2_indexer(input_2))
nn_processed_inputs = [normalized_input_1, normalized_input_2]
WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
Build the body of the neural network:
y = tf_keras.layers.Concatenate()(nn_processed_inputs)
y = tf_keras.layers.Dense(16, activation=tf.nn.relu6)(y)
last_layer = tf_keras.layers.Dense(8, activation=tf.nn.relu, name="last")(y)
# "3" for the three label classes. If it were a binary classification, the
# output dim would be 1.
classification_output = tf_keras.layers.Dense(3)(y)
nn_model = tf_keras.models.Model(nn_raw_inputs, classification_output)
This nn_model directly produces classification logits.
Next create a decision forest model. This will operate on the high level features that the neural network extracts in the last layer before that classification head.
# To reduce the risk of mistakes, group both the decision forest and the
# neural network in a single keras model.
nn_without_head = tf_keras.models.Model(inputs=nn_model.inputs, outputs=last_layer)
df_and_nn_model = tfdf.keras.RandomForestModel(preprocessing=nn_without_head)
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. Use /tmpfs/tmp/tmpqj02hmvr as temporary training directory
Train and evaluate the models
The model will be trained in two stages. First train the neural network with its own classification head:
%set_cell_height 300
nn_model.compile(
optimizer=tf_keras.optimizers.Adam(),
loss=tf_keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"])
nn_model.fit(x=train_ds, validation_data=test_ds, epochs=10)
nn_model.summary()
<IPython.core.display.Javascript object>
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tf_keras/src/engine/functional.py:641: UserWarning: Input dict contained keys ['bill_depth_mm', 'flipper_length_mm', 'body_mass_g', 'sex', 'year'] which did not match any model input. They will be ignored by the model.
inputs = self._flatten_to_reference_inputs(inputs)
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1768226734.849085 145398 service.cc:152] XLA service 0x7fcb1c29c910 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
I0000 00:00:1768226734.849121 145398 service.cc:160] StreamExecutor device (0): Tesla T4, Compute Capability 7.5
I0000 00:00:1768226734.849125 145398 service.cc:160] StreamExecutor device (1): Tesla T4, Compute Capability 7.5
I0000 00:00:1768226734.849128 145398 service.cc:160] StreamExecutor device (2): Tesla T4, Compute Capability 7.5
I0000 00:00:1768226734.849131 145398 service.cc:160] StreamExecutor device (3): Tesla T4, Compute Capability 7.5
I0000 00:00:1768226734.887498 145398 cuda_dnn.cc:529] Loaded cuDNN version 91701
I0000 00:00:1768226735.013693 145398 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
1/1 [==============================] - 2s 2s/step - loss: 1.0608 - accuracy: 0.4226 - val_loss: 1.0202 - val_accuracy: 0.4762
Epoch 2/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0554 - accuracy: 0.4310 - val_loss: 1.0150 - val_accuracy: 0.4952
Epoch 3/10
1/1 [==============================] - 0s 24ms/step - loss: 1.0500 - accuracy: 0.4393 - val_loss: 1.0098 - val_accuracy: 0.5048
Epoch 4/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0447 - accuracy: 0.4477 - val_loss: 1.0047 - val_accuracy: 0.5143
Epoch 5/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0394 - accuracy: 0.4603 - val_loss: 0.9996 - val_accuracy: 0.5333
Epoch 6/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0341 - accuracy: 0.4644 - val_loss: 0.9946 - val_accuracy: 0.5333
Epoch 7/10
1/1 [==============================] - 0s 21ms/step - loss: 1.0289 - accuracy: 0.4644 - val_loss: 0.9896 - val_accuracy: 0.5429
Epoch 8/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0238 - accuracy: 0.4770 - val_loss: 0.9848 - val_accuracy: 0.5429
Epoch 9/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0187 - accuracy: 0.4854 - val_loss: 0.9799 - val_accuracy: 0.5429
Epoch 10/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0137 - accuracy: 0.4937 - val_loss: 0.9751 - val_accuracy: 0.5429
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
island (InputLayer) [(None, 1)] 0 []
bill_length_mm (InputLayer [(None, 1)] 0 []
)
string_lookup (StringLooku (None, 1) 0 ['island[0][0]']
p)
normalization (Normalizati (None, 1) 3 ['bill_length_mm[0][0]']
on)
category_encoding (Categor (None, 32) 0 ['string_lookup[0][0]']
yEncoding)
concatenate (Concatenate) (None, 33) 0 ['normalization[0][0]',
'category_encoding[0][0]']
dense (Dense) (None, 16) 544 ['concatenate[0][0]']
dense_1 (Dense) (None, 3) 51 ['dense[0][0]']
==================================================================================================
Total params: 598 (2.34 KB)
Trainable params: 595 (2.32 KB)
Non-trainable params: 3 (16.00 Byte)
__________________________________________________________________________________________________
The neural network layers are shared between the two models. So now that the neural network is trained the decision forest model will be fit to the trained output of the neural network layers:
%set_cell_height 300
df_and_nn_model.fit(x=train_ds)
<IPython.core.display.Javascript object>
Reading training dataset...
Training dataset read in 0:00:00.257645. Found 239 examples.
Training model...
Model trained in 0:00:00.040573
Compiling model...
Model compiled.
I0000 00:00:1768226736.089211 145231 kernel.cc:782] Start Yggdrasil model training
I0000 00:00:1768226736.089247 145231 kernel.cc:783] Collect training examples
I0000 00:00:1768226736.089255 145231 kernel.cc:795] Dataspec guide:
column_guides {
column_name_pattern: "^__LABEL$"
type: CATEGORICAL
categorial {
min_vocab_frequency: 0
max_vocab_count: -1
}
}
default_column_guide {
categorial {
max_vocab_count: 2000
}
discretized_numerical {
maximum_num_bins: 255
}
}
ignore_columns_without_guides: false
detect_numerical_as_discretized_numerical: false
I0000 00:00:1768226736.089321 145231 kernel.cc:401] Number of batches: 1
I0000 00:00:1768226736.089326 145231 kernel.cc:402] Number of examples: 239
I0000 00:00:1768226736.089358 145231 kernel.cc:802] Training dataset:
Number of records: 239
Number of columns: 9
Number of columns by type:
NUMERICAL: 8 (88.8889%)
CATEGORICAL: 1 (11.1111%)
Columns:
NUMERICAL: 8 (88.8889%)
1: "model_2/last/Relu:0.0" NUMERICAL mean:0.0116771 min:0 max:0.0908058 sd:0.0274422
2: "model_2/last/Relu:0.1" NUMERICAL mean:0.0025694 min:0 max:0.147406 sd:0.0138769
3: "model_2/last/Relu:0.2" NUMERICAL mean:0.027983 min:0 max:0.850803 sd:0.0745998
4: "model_2/last/Relu:0.3" NUMERICAL mean:0.097366 min:0 max:1.80832 sd:0.17252
5: "model_2/last/Relu:0.4" NUMERICAL mean:0.173951 min:0 max:1.21527 sd:0.123289
6: "model_2/last/Relu:0.5" NUMERICAL mean:0 min:0 max:0 sd:0
7: "model_2/last/Relu:0.6" NUMERICAL mean:0.375323 min:0 max:0.546174 sd:0.124559
8: "model_2/last/Relu:0.7" NUMERICAL mean:0.153118 min:0 max:0.5156 sd:0.16761
CATEGORICAL: 1 (11.1111%)
0: "__LABEL" CATEGORICAL integerized vocab-size:4 no-ood-item
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute whose type is manually defined by the user, i.e., the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
I0000 00:00:1768226736.089375 145231 kernel.cc:818] Configure learner
I0000 00:00:1768226736.089547 145231 kernel.cc:831] Training config:
learner: "RANDOM_FOREST"
features: "^model_2/last/Relu:0\\.0$"
features: "^model_2/last/Relu:0\\.1$"
features: "^model_2/last/Relu:0\\.2$"
features: "^model_2/last/Relu:0\\.3$"
features: "^model_2/last/Relu:0\\.4$"
features: "^model_2/last/Relu:0\\.5$"
features: "^model_2/last/Relu:0\\.6$"
features: "^model_2/last/Relu:0\\.7$"
label: "^__LABEL$"
task: CLASSIFICATION
random_seed: 123456
metadata {
framework: "TF Keras"
}
pure_serving_model: false
[yggdrasil_decision_forests.model.random_forest.proto.random_forest_config] {
num_trees: 300
decision_tree {
max_depth: 16
min_examples: 5
in_split_min_examples_check: true
keep_non_leaf_label_distribution: true
num_candidate_attributes: 0
missing_value_policy: GLOBAL_IMPUTATION
allow_na_conditions: false
categorical_set_greedy_forward {
sampling: 0.1
max_num_items: -1
min_item_frequency: 1
}
growing_strategy_local {
}
categorical {
cart {
}
}
axis_aligned_split {
}
internal {
sorting_strategy: PRESORTED
}
uplift {
min_examples_in_treatment: 5
split_score: KULLBACK_LEIBLER
}
numerical_vector_sequence {
max_num_test_examples: 1000
num_random_selected_anchors: 100
}
}
winner_take_all_inference: true
compute_oob_performances: true
compute_oob_variable_importances: false
num_oob_variable_importances_permutations: 1
bootstrap_training_dataset: true
bootstrap_size_ratio: 1
adapt_bootstrap_size_ratio_for_maximum_training_duration: false
sampling_with_replacement: true
}
I0000 00:00:1768226736.089613 145231 kernel.cc:834] Deployment config:
cache_path: "/tmpfs/tmp/tmpqj02hmvr/working_cache"
num_threads: 32
try_resume_training: true
I0000 00:00:1768226736.089847 147652 kernel.cc:895] Train model
I0000 00:00:1768226736.090025 147652 random_forest.cc:438] Training random forest on 239 example(s) and 8 feature(s).
I0000 00:00:1768226736.090754 147652 gpu.cc:93] Cannot initialize GPU: Not compiled with GPU support
I0000 00:00:1768226736.092077 147662 random_forest.cc:865] Train tree 1/300 accuracy:0.925 logloss:2.70327 [index:1 total:0.00s tree:0.00s]
I0000 00:00:1768226736.092369 147670 random_forest.cc:865] Train tree 11/300 accuracy:0.941176 logloss:1.24563 [index:9 total:0.00s tree:0.00s]
I0000 00:00:1768226736.092527 147692 random_forest.cc:865] Train tree 21/300 accuracy:0.941423 logloss:1.0967 [index:22 total:0.00s tree:0.00s]
I0000 00:00:1768226736.092709 147672 random_forest.cc:865] Train tree 33/300 accuracy:0.949791 logloss:0.951258 [index:34 total:0.00s tree:0.00s]
I0000 00:00:1768226736.092911 147691 random_forest.cc:865] Train tree 45/300 accuracy:0.949791 logloss:0.670202 [index:44 total:0.00s tree:0.00s]
I0000 00:00:1768226736.093193 147686 random_forest.cc:865] Train tree 55/300 accuracy:0.949791 logloss:0.673256 [index:52 total:0.00s tree:0.00s]
I0000 00:00:1768226736.093502 147667 random_forest.cc:865] Train tree 66/300 accuracy:0.945607 logloss:0.672664 [index:66 total:0.00s tree:0.00s]
I0000 00:00:1768226736.093824 147661 random_forest.cc:865] Train tree 77/300 accuracy:0.945607 logloss:0.676255 [index:78 total:0.00s tree:0.00s]
I0000 00:00:1768226736.094125 147688 random_forest.cc:865] Train tree 87/300 accuracy:0.941423 logloss:0.676693 [index:87 total:0.00s tree:0.00s]
I0000 00:00:1768226736.094341 147673 random_forest.cc:865] Train tree 97/300 accuracy:0.945607 logloss:0.676926 [index:96 total:0.00s tree:0.00s]
I0000 00:00:1768226736.094788 147692 random_forest.cc:865] Train tree 107/300 accuracy:0.945607 logloss:0.674531 [index:108 total:0.00s tree:0.00s]
I0000 00:00:1768226736.094953 147683 random_forest.cc:865] Train tree 118/300 accuracy:0.945607 logloss:0.674044 [index:117 total:0.00s tree:0.00s]
I0000 00:00:1768226736.095407 147690 random_forest.cc:865] Train tree 133/300 accuracy:0.945607 logloss:0.670936 [index:133 total:0.00s tree:0.00s]
I0000 00:00:1768226736.095766 147678 random_forest.cc:865] Train tree 143/300 accuracy:0.945607 logloss:0.6713 [index:144 total:0.00s tree:0.00s]
I0000 00:00:1768226736.096030 147690 random_forest.cc:865] Train tree 154/300 accuracy:0.945607 logloss:0.670578 [index:154 total:0.01s tree:0.00s]
I0000 00:00:1768226736.096325 147671 random_forest.cc:865] Train tree 165/300 accuracy:0.945607 logloss:0.671616 [index:164 total:0.01s tree:0.00s]
I0000 00:00:1768226736.096610 147690 random_forest.cc:865] Train tree 176/300 accuracy:0.949791 logloss:0.67153 [index:178 total:0.01s tree:0.00s]
I0000 00:00:1768226736.096914 147689 random_forest.cc:865] Train tree 188/300 accuracy:0.949791 logloss:0.671441 [index:186 total:0.01s tree:0.00s]
I0000 00:00:1768226736.097181 147678 random_forest.cc:865] Train tree 198/300 accuracy:0.945607 logloss:0.671592 [index:197 total:0.01s tree:0.00s]
I0000 00:00:1768226736.097499 147673 random_forest.cc:865] Train tree 208/300 accuracy:0.945607 logloss:0.672467 [index:207 total:0.01s tree:0.00s]
I0000 00:00:1768226736.097739 147673 random_forest.cc:865] Train tree 218/300 accuracy:0.941423 logloss:0.672014 [index:217 total:0.01s tree:0.00s]
I0000 00:00:1768226736.097996 147679 random_forest.cc:865] Train tree 229/300 accuracy:0.941423 logloss:0.672292 [index:226 total:0.01s tree:0.00s]
I0000 00:00:1768226736.098285 147679 random_forest.cc:865] Train tree 239/300 accuracy:0.949791 logloss:0.670894 [index:237 total:0.01s tree:0.00s]
I0000 00:00:1768226736.098427 147666 random_forest.cc:865] Train tree 249/300 accuracy:0.949791 logloss:0.670515 [index:246 total:0.01s tree:0.00s]
I0000 00:00:1768226736.098855 147668 random_forest.cc:865] Train tree 259/300 accuracy:0.949791 logloss:0.672044 [index:258 total:0.01s tree:0.00s]
I0000 00:00:1768226736.099188 147668 random_forest.cc:865] Train tree 271/300 accuracy:0.945607 logloss:0.540731 [index:270 total:0.01s tree:0.00s]
I0000 00:00:1768226736.099362 147673 random_forest.cc:865] Train tree 282/300 accuracy:0.949791 logloss:0.539921 [index:281 total:0.01s tree:0.00s]
I0000 00:00:1768226736.099667 147675 random_forest.cc:865] Train tree 292/300 accuracy:0.949791 logloss:0.540329 [index:291 total:0.01s tree:0.00s]
I0000 00:00:1768226736.100790 147682 random_forest.cc:865] Train tree 300/300 accuracy:0.945607 logloss:0.54268 [index:299 total:0.01s tree:0.00s]
I0000 00:00:1768226736.100964 147652 random_forest.cc:949] Final OOB metrics: accuracy:0.945607 logloss:0.54268
I0000 00:00:1768226736.102221 147652 kernel.cc:926] Export model in log directory: /tmpfs/tmp/tmpqj02hmvr with prefix 3cdec1f350da49ee
I0000 00:00:1768226736.105776 147652 kernel.cc:944] Save model in resources
I0000 00:00:1768226736.107557 145231 abstract_model.cc:921] Model self evaluation:
Number of predictions (without weights): 239
Number of predictions (with weights): 239
Task: CLASSIFICATION
Label: __LABEL
Accuracy: 0.945607 CI95[W][0.914911 0.96753]
LogLoss: : 0.54268
ErrorRate: : 0.0543933
Default Accuracy: : 0.435146
Default LogLoss: : 1.04977
Default ErrorRate: : 0.564854
Confusion Table:
truth\prediction
1 2 3
1 97 2 5
2 2 45 0
3 4 0 84
Total: 239
I0000 00:00:1768226736.126741 145231 decision_forest.cc:808] Model loaded with 300 root(s), 4466 node(s), and 7 input feature(s).
<tf_keras.src.callbacks.History at 0x7fcace891790>
Now evaluate the composed model:
df_and_nn_model.compile(metrics=["accuracy"])
print("Evaluation:", df_and_nn_model.evaluate(test_ds))
1/1 [==============================] - 0s 150ms/step - loss: 0.0000e+00 - accuracy: 0.9714 Evaluation: [0.0, 0.9714285731315613]
Compare it to the Neural Network alone:
print("Evaluation :", nn_model.evaluate(test_ds))
1/1 [==============================] - 0s 15ms/step - loss: 0.9751 - accuracy: 0.5429 Evaluation : [0.9751155376434326, 0.5428571701049805]