
Gli ultimi anni hanno visto un aumento di nuovi livelli grafici differenziabili che possono essere inseriti nelle architetture di reti neurali. Dai trasformatori spaziali ai renderer grafici differenziabili, questi nuovi livelli sfruttano le conoscenze acquisite in anni di visione artificiale e ricerca grafica per costruire architetture di rete nuove e più efficienti. La modellazione esplicita di priorità e vincoli geometrici nelle reti neurali apre le porte ad architetture che possono essere addestrate in modo robusto, efficiente e, soprattutto, in modo auto-supervisionato.
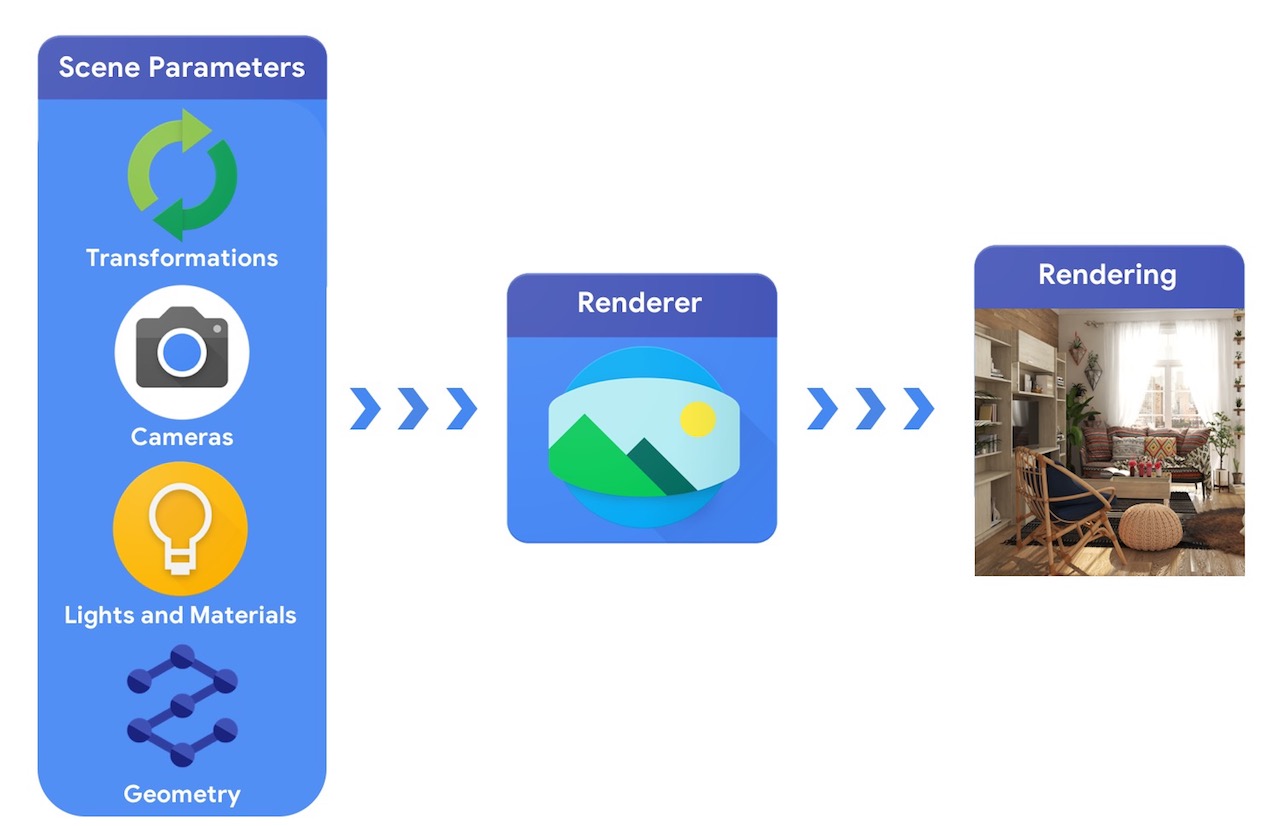
Ad alto livello, una pipeline di computer grafica richiede una rappresentazione degli oggetti 3D e il loro posizionamento assoluto nella scena, una descrizione del materiale di cui sono fatti, luci e una telecamera. Questa descrizione della scena viene quindi interpretata da un renderer per generare un rendering sintetico.
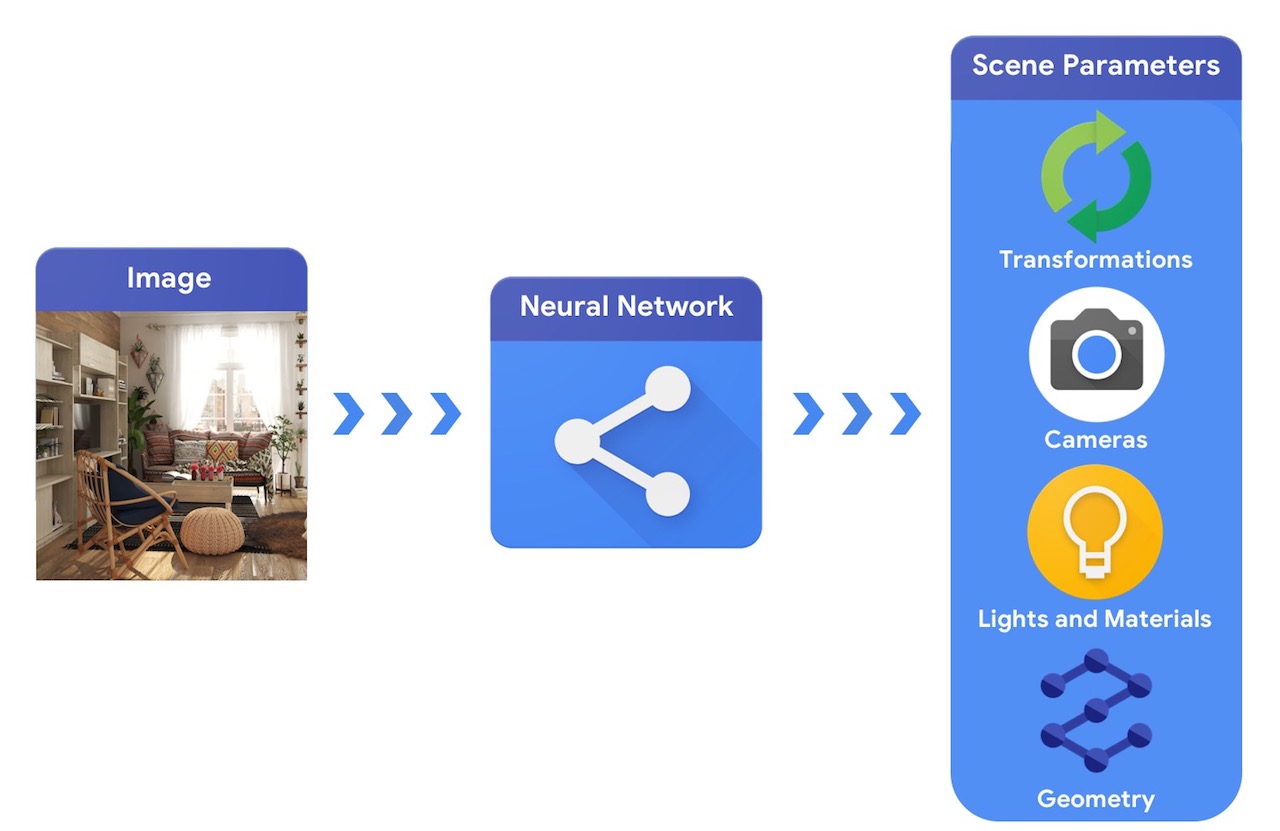
In confronto, un sistema di visione artificiale partirebbe da un'immagine e proverebbe a dedurre i parametri della scena. Ciò consente di prevedere quali oggetti si trovano nella scena, di quali materiali sono fatti e la posizione e l'orientamento tridimensionali.
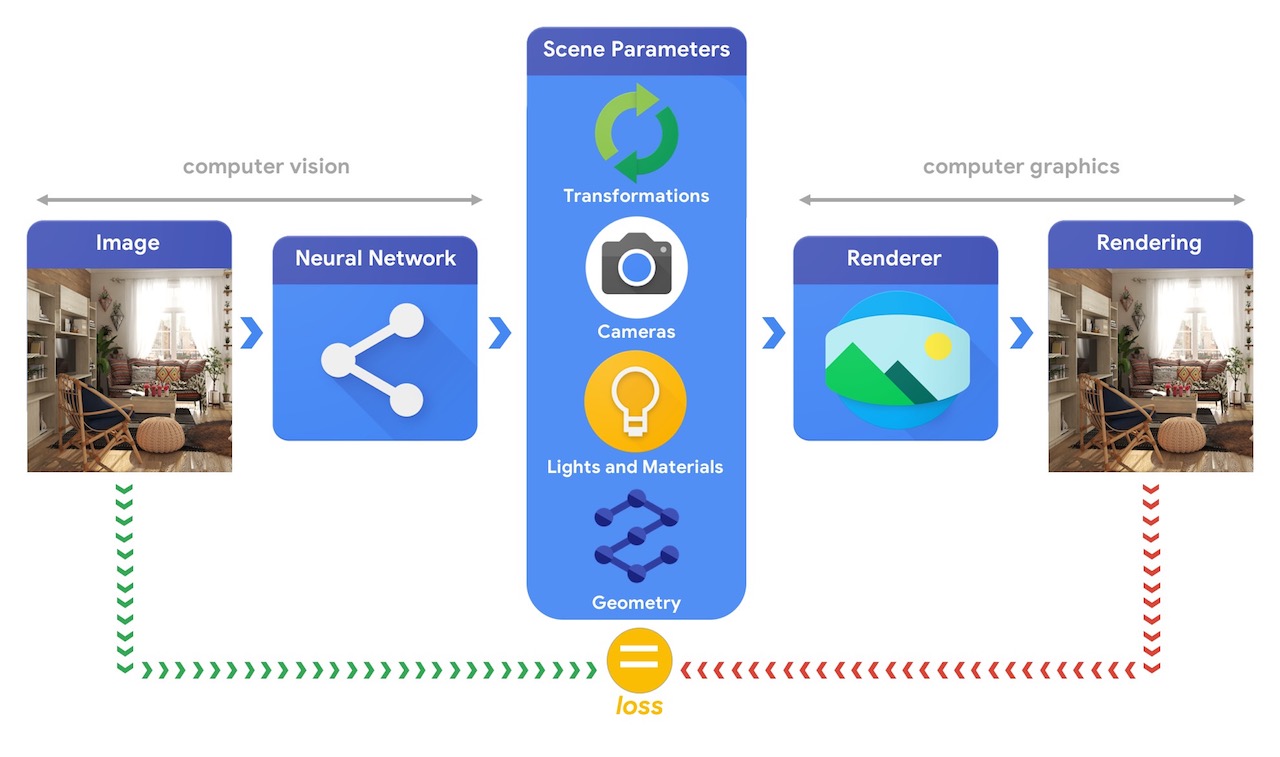
La formazione di sistemi di apprendimento automatico in grado di risolvere questi complessi compiti di visione 3D richiede molto spesso grandi quantità di dati. Poiché l'etichettatura dei dati è un processo costoso e complesso, è importante disporre di meccanismi per progettare modelli di apprendimento automatico in grado di comprendere il mondo tridimensionale mentre vengono addestrati senza molta supervisione. La combinazione di tecniche di visione artificiale e computer grafica offre un'opportunità unica per sfruttare le grandi quantità di dati non etichettati prontamente disponibili. Come illustrato nell'immagine seguente, ciò può essere ottenuto, ad esempio, mediante l'analisi per sintesi in cui il sistema di visione estrae i parametri della scena e il sistema grafico restituisce un'immagine basata su di essi. Se il rendering corrisponde all'immagine originale, il sistema di visione ha estratto accuratamente i parametri della scena. In questa configurazione, visione artificiale e computer grafica vanno di pari passo, formando un unico sistema di apprendimento automatico simile a un autoencoder, che può essere addestrato in modo auto-supervisionato.
Tensorflow Graphics è stato sviluppato per aiutare ad affrontare questo tipo di sfide e per farlo, fornisce una serie di livelli differenziabili di grafica e geometria (ad es. telecamere, modelli di riflettanza, trasformazioni spaziali, convoluzioni di mesh) e funzionalità di visualizzazione 3D (ad es. TensorBoard 3D) che può essere utilizzato per addestrare ed eseguire il debug dei tuoi modelli di apprendimento automatico preferiti.