
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
La guía Introducción a los degradados y diferenciación automática incluye todo lo necesario para calcular degradados en TensorFlow. Esta guía se enfoca en características más profundas y menos comunes de la API tf.GradientTape .
Configuración
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['figure.figsize'] = (8, 6)
Control de grabación de gradiente
En la guía de diferenciación automática , vio cómo controlar qué variables y tensores vigila la cinta mientras construye el cálculo del gradiente.
La cinta también tiene métodos para manipular la grabación.
Para de grabar
Si desea detener la grabación de gradientes, puede usar tf.GradientTape.stop_recording para suspender temporalmente la grabación.
Esto puede ser útil para reducir los gastos generales si no desea diferenciar una operación complicada en medio de su modelo. Esto podría incluir el cálculo de una métrica o un resultado intermedio:
x = tf.Variable(2.0)
y = tf.Variable(3.0)
with tf.GradientTape() as t:
x_sq = x * x
with t.stop_recording():
y_sq = y * y
z = x_sq + y_sq
grad = t.gradient(z, {'x': x, 'y': y})
print('dz/dx:', grad['x']) # 2*x => 4
print('dz/dy:', grad['y'])
dz/dx: tf.Tensor(4.0, shape=(), dtype=float32) dz/dy: None
Restablecer/comenzar a grabar desde cero
Si desea comenzar de nuevo por completo, use tf.GradientTape.reset . Simplemente salir del bloque de cinta de degradado y reiniciar suele ser más fácil de leer, pero puede usar el método de reset cuando salir del bloque de cinta es difícil o imposible.
x = tf.Variable(2.0)
y = tf.Variable(3.0)
reset = True
with tf.GradientTape() as t:
y_sq = y * y
if reset:
# Throw out all the tape recorded so far.
t.reset()
z = x * x + y_sq
grad = t.gradient(z, {'x': x, 'y': y})
print('dz/dx:', grad['x']) # 2*x => 4
print('dz/dy:', grad['y'])
dz/dx: tf.Tensor(4.0, shape=(), dtype=float32) dz/dy: None
Detenga el flujo de gradiente con precisión
A diferencia de los controles de cinta globales anteriores, la función tf.stop_gradient es mucho más precisa. Se puede usar para evitar que los gradientes fluyan a lo largo de un camino particular, sin necesidad de acceder a la cinta en sí:
x = tf.Variable(2.0)
y = tf.Variable(3.0)
with tf.GradientTape() as t:
y_sq = y**2
z = x**2 + tf.stop_gradient(y_sq)
grad = t.gradient(z, {'x': x, 'y': y})
print('dz/dx:', grad['x']) # 2*x => 4
print('dz/dy:', grad['y'])
dz/dx: tf.Tensor(4.0, shape=(), dtype=float32) dz/dy: None
Gradientes personalizados
En algunos casos, es posible que desee controlar exactamente cómo se calculan los gradientes en lugar de utilizar el valor predeterminado. Estas situaciones incluyen:
- No hay un gradiente definido para una nueva operación que está escribiendo.
- Los cálculos predeterminados son numéricamente inestables.
- Desea almacenar en caché un cálculo costoso del pase hacia adelante.
- Desea modificar un valor (por ejemplo, usando
tf.clip_by_valueotf.math.round) sin modificar el degradado.
Para el primer caso, para escribir una nueva operación, puede usar tf.RegisterGradient para configurar la suya propia (consulte los documentos de la API para obtener más detalles). (Tenga en cuenta que el registro de gradiente es global, así que cámbielo con precaución).
Para los últimos tres casos, puede usar tf.custom_gradient .
Aquí hay un ejemplo que aplica tf.clip_by_norm al gradiente intermedio:
# Establish an identity operation, but clip during the gradient pass.
@tf.custom_gradient
def clip_gradients(y):
def backward(dy):
return tf.clip_by_norm(dy, 0.5)
return y, backward
v = tf.Variable(2.0)
with tf.GradientTape() as t:
output = clip_gradients(v * v)
print(t.gradient(output, v)) # calls "backward", which clips 4 to 2
tf.Tensor(2.0, shape=(), dtype=float32)
Consulte los documentos de la API del decorador tf.custom_gradient para obtener más detalles.
Gradientes personalizados en modelo guardado
Los degradados personalizados se pueden guardar en el modelo guardado mediante la opción tf.saved_model.SaveOptions(experimental_custom_gradients=True) .
Para guardarse en el modelo guardado, la función de gradiente debe ser rastreable (para obtener más información, consulte la guía Mejor rendimiento con tf.function ).
class MyModule(tf.Module):
@tf.function(input_signature=[tf.TensorSpec(None)])
def call_custom_grad(self, x):
return clip_gradients(x)
model = MyModule()
tf.saved_model.save(
model,
'saved_model',
options=tf.saved_model.SaveOptions(experimental_custom_gradients=True))
# The loaded gradients will be the same as the above example.
v = tf.Variable(2.0)
loaded = tf.saved_model.load('saved_model')
with tf.GradientTape() as t:
output = loaded.call_custom_grad(v * v)
print(t.gradient(output, v))
INFO:tensorflow:Assets written to: saved_model/assets tf.Tensor(2.0, shape=(), dtype=float32)
Una nota sobre el ejemplo anterior: si intenta reemplazar el código anterior con tf.saved_model.SaveOptions(experimental_custom_gradients=False) , el degradado aún producirá el mismo resultado al cargar. El motivo es que el registro de degradados todavía contiene el degradado personalizado que se usa en la función call_custom_op . Sin embargo, si reinicia el tiempo de ejecución después de guardar sin gradientes personalizados, ejecutar el modelo cargado bajo tf.GradientTape generará el error: LookupError: No gradient defined for operation 'IdentityN' (op type: IdentityN) .
Múltiples cintas
Múltiples cintas interactúan sin problemas.
Por ejemplo, aquí cada cinta observa un conjunto diferente de tensores:
x0 = tf.constant(0.0)
x1 = tf.constant(0.0)
with tf.GradientTape() as tape0, tf.GradientTape() as tape1:
tape0.watch(x0)
tape1.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.sigmoid(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
tape0.gradient(ys, x0).numpy() # cos(x) => 1.0
1.0
tape1.gradient(ys, x1).numpy() # sigmoid(x1)*(1-sigmoid(x1)) => 0.25
0.25
Gradientes de orden superior
Las operaciones dentro del administrador de contexto tf.GradientTape se registran para la diferenciación automática. Si los gradientes se calculan en ese contexto, el cálculo del gradiente también se registra. Como resultado, la misma API también funciona para gradientes de orden superior.
Por ejemplo:
x = tf.Variable(1.0) # Create a Tensorflow variable initialized to 1.0
with tf.GradientTape() as t2:
with tf.GradientTape() as t1:
y = x * x * x
# Compute the gradient inside the outer `t2` context manager
# which means the gradient computation is differentiable as well.
dy_dx = t1.gradient(y, x)
d2y_dx2 = t2.gradient(dy_dx, x)
print('dy_dx:', dy_dx.numpy()) # 3 * x**2 => 3.0
print('d2y_dx2:', d2y_dx2.numpy()) # 6 * x => 6.0
dy_dx: 3.0 d2y_dx2: 6.0
Si bien eso le da la segunda derivada de una función escalar , este patrón no se generaliza para producir una matriz hessiana, ya que tf.GradientTape.gradient solo calcula el gradiente de un escalar. Para construir una matriz hessiana , vaya al ejemplo hessiano en la sección jacobiana .
"Llamadas anidadas a tf.GradientTape.gradient " es un buen patrón cuando está calculando un escalar a partir de un gradiente, y luego el escalar resultante actúa como una fuente para un segundo cálculo de gradiente, como en el siguiente ejemplo.
Ejemplo: regularización del gradiente de entrada
Muchos modelos son susceptibles de "ejemplos adversarios". Esta colección de técnicas modifica la entrada del modelo para confundir la salida del modelo. La implementación más simple, como el ejemplo de Adversarial que usa el método de ataque Fast Gradient Signed Method, toma un solo paso a lo largo del gradiente de la salida con respecto a la entrada; el "gradiente de entrada".
Una técnica para aumentar la solidez de los ejemplos contradictorios es la regularización del gradiente de entrada (Finlay & Oberman, 2019), que intenta minimizar la magnitud del gradiente de entrada. Si el gradiente de entrada es pequeño, entonces el cambio en la salida también debería ser pequeño.
A continuación se muestra una implementación ingenua de la regularización del gradiente de entrada. La implementación es:
- Calcular el gradiente de la salida con respecto a la entrada utilizando una cinta interior.
- Calcule la magnitud de ese gradiente de entrada.
- Calcular el gradiente de esa magnitud con respecto al modelo.
x = tf.random.normal([7, 5])
layer = tf.keras.layers.Dense(10, activation=tf.nn.relu)
with tf.GradientTape() as t2:
# The inner tape only takes the gradient with respect to the input,
# not the variables.
with tf.GradientTape(watch_accessed_variables=False) as t1:
t1.watch(x)
y = layer(x)
out = tf.reduce_sum(layer(x)**2)
# 1. Calculate the input gradient.
g1 = t1.gradient(out, x)
# 2. Calculate the magnitude of the input gradient.
g1_mag = tf.norm(g1)
# 3. Calculate the gradient of the magnitude with respect to the model.
dg1_mag = t2.gradient(g1_mag, layer.trainable_variables)
[var.shape for var in dg1_mag]
[TensorShape([5, 10]), TensorShape([10])]
Jacobianos
Todos los ejemplos anteriores tomaron los gradientes de un objetivo escalar con respecto a algún tensor fuente.
La matriz jacobiana representa los gradientes de una función vectorial. Cada fila contiene el degradado de uno de los elementos del vector.
El método tf.GradientTape.jacobian le permite calcular eficientemente una matriz jacobiana.
Tenga en cuenta que:
- Como
gradient: el argumento de lassourcespuede ser un tensor o un contenedor de tensores. - A diferencia de
gradient: el tensor detargetdebe ser un solo tensor.
fuente escalar
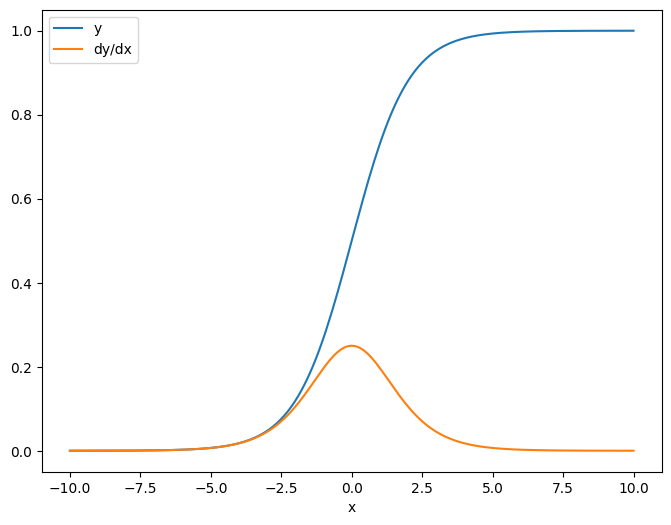
Como primer ejemplo, aquí está el jacobiano de un objetivo vectorial con respecto a una fuente escalar.
x = tf.linspace(-10.0, 10.0, 200+1)
delta = tf.Variable(0.0)
with tf.GradientTape() as tape:
y = tf.nn.sigmoid(x+delta)
dy_dx = tape.jacobian(y, delta)
Cuando toma el jacobiano con respecto a un escalar, el resultado tiene la forma del objetivo y da el gradiente de cada elemento con respecto a la fuente:
print(y.shape)
print(dy_dx.shape)
(201,) (201,)
plt.plot(x.numpy(), y, label='y')
plt.plot(x.numpy(), dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
fuente tensor
Ya sea que la entrada sea escalar o tensor, tf.GradientTape.jacobian calcula de manera eficiente el gradiente de cada elemento de la fuente con respecto a cada elemento de los objetivos.
Por ejemplo, la salida de esta capa tiene la forma de (10, 7) :
x = tf.random.normal([7, 5])
layer = tf.keras.layers.Dense(10, activation=tf.nn.relu)
with tf.GradientTape(persistent=True) as tape:
y = layer(x)
y.shape
TensorShape([7, 10])
Y la forma del núcleo de la capa es (5, 10) :
layer.kernel.shape
TensorShape([5, 10])
La forma del jacobiano de la salida con respecto al kernel son esas dos formas concatenadas juntas:
j = tape.jacobian(y, layer.kernel)
j.shape
TensorShape([7, 10, 5, 10])
Si sumas las dimensiones del objetivo, te queda el gradiente de la suma que habría sido calculado por tf.GradientTape.gradient :
g = tape.gradient(y, layer.kernel)
print('g.shape:', g.shape)
j_sum = tf.reduce_sum(j, axis=[0, 1])
delta = tf.reduce_max(abs(g - j_sum)).numpy()
assert delta < 1e-3
print('delta:', delta)
g.shape: (5, 10) delta: 2.3841858e-07
Ejemplo: arpillera
Si bien tf.GradientTape no brinda un método explícito para construir una matriz hessiana , es posible construir una usando el método tf.GradientTape.jacobian .
x = tf.random.normal([7, 5])
layer1 = tf.keras.layers.Dense(8, activation=tf.nn.relu)
layer2 = tf.keras.layers.Dense(6, activation=tf.nn.relu)
with tf.GradientTape() as t2:
with tf.GradientTape() as t1:
x = layer1(x)
x = layer2(x)
loss = tf.reduce_mean(x**2)
g = t1.gradient(loss, layer1.kernel)
h = t2.jacobian(g, layer1.kernel)
print(f'layer.kernel.shape: {layer1.kernel.shape}')
print(f'h.shape: {h.shape}')
layer.kernel.shape: (5, 8) h.shape: (5, 8, 5, 8)
Para usar este hessiano para un paso del método de Newton , primero aplanaría sus ejes en una matriz y aplanaría el gradiente en un vector:
n_params = tf.reduce_prod(layer1.kernel.shape)
g_vec = tf.reshape(g, [n_params, 1])
h_mat = tf.reshape(h, [n_params, n_params])
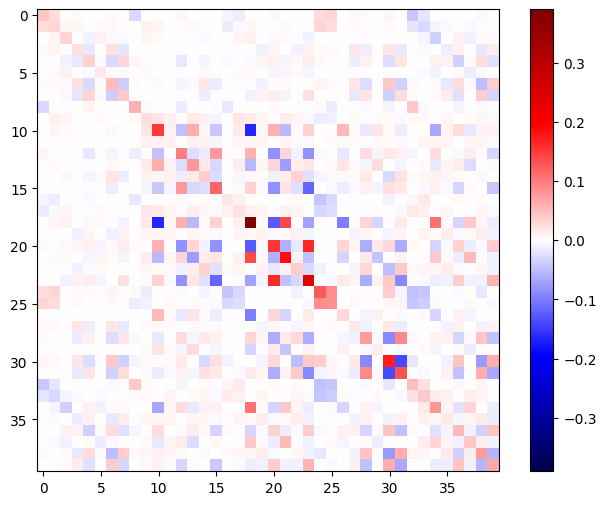
La matriz hessiana debe ser simétrica:
def imshow_zero_center(image, **kwargs):
lim = tf.reduce_max(abs(image))
plt.imshow(image, vmin=-lim, vmax=lim, cmap='seismic', **kwargs)
plt.colorbar()
imshow_zero_center(h_mat)
El paso de actualización del método de Newton se muestra a continuación:
eps = 1e-3
eye_eps = tf.eye(h_mat.shape[0])*eps
# X(k+1) = X(k) - (∇²f(X(k)))^-1 @ ∇f(X(k))
# h_mat = ∇²f(X(k))
# g_vec = ∇f(X(k))
update = tf.linalg.solve(h_mat + eye_eps, g_vec)
# Reshape the update and apply it to the variable.
_ = layer1.kernel.assign_sub(tf.reshape(update, layer1.kernel.shape))
Si bien esto es relativamente simple para una sola tf.Variable , aplicar esto a un modelo no trivial requeriría una concatenación y un corte cuidadosos para producir un hessiano completo en múltiples variables.
Lote jacobiano
En algunos casos, desea tomar el jacobiano de cada uno de una pila de objetivos con respecto a una pila de fuentes, donde los jacobianos para cada par objetivo-fuente son independientes.
Por ejemplo, aquí la entrada x tiene forma (batch, ins) y la salida y tiene forma (batch, outs) :
x = tf.random.normal([7, 5])
layer1 = tf.keras.layers.Dense(8, activation=tf.nn.elu)
layer2 = tf.keras.layers.Dense(6, activation=tf.nn.elu)
with tf.GradientTape(persistent=True, watch_accessed_variables=False) as tape:
tape.watch(x)
y = layer1(x)
y = layer2(y)
y.shape
TensorShape([7, 6])
El jacobiano completo de y con respecto a x tiene una forma de (batch, ins, batch, outs) , incluso si solo desea (batch, ins, outs) :
j = tape.jacobian(y, x)
j.shape
TensorShape([7, 6, 7, 5])
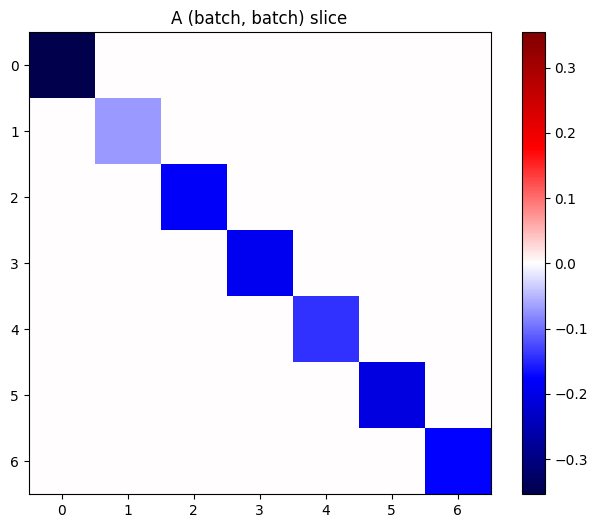
Si los gradientes de cada elemento de la pila son independientes, entonces cada segmento (batch, batch) de este tensor es una matriz diagonal:
imshow_zero_center(j[:, 0, :, 0])
_ = plt.title('A (batch, batch) slice')
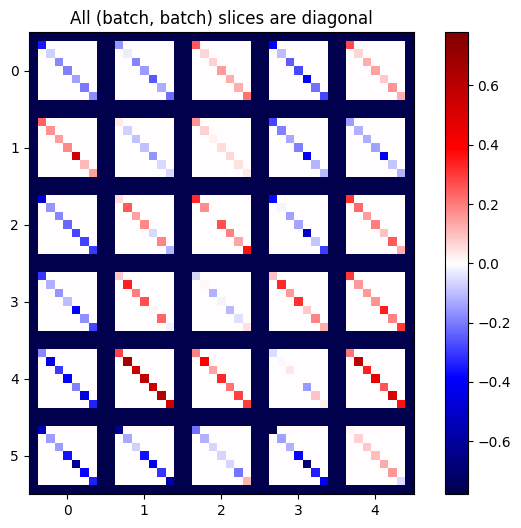
def plot_as_patches(j):
# Reorder axes so the diagonals will each form a contiguous patch.
j = tf.transpose(j, [1, 0, 3, 2])
# Pad in between each patch.
lim = tf.reduce_max(abs(j))
j = tf.pad(j, [[0, 0], [1, 1], [0, 0], [1, 1]],
constant_values=-lim)
# Reshape to form a single image.
s = j.shape
j = tf.reshape(j, [s[0]*s[1], s[2]*s[3]])
imshow_zero_center(j, extent=[-0.5, s[2]-0.5, s[0]-0.5, -0.5])
plot_as_patches(j)
_ = plt.title('All (batch, batch) slices are diagonal')
Para obtener el resultado deseado, puede sumar sobre la dimensión del batch duplicado, o seleccionar las diagonales usando tf.einsum :
j_sum = tf.reduce_sum(j, axis=2)
print(j_sum.shape)
j_select = tf.einsum('bxby->bxy', j)
print(j_select.shape)
(7, 6, 5) (7, 6, 5)
Sería mucho más eficiente hacer el cálculo sin la dimensión adicional en primer lugar. El método tf.GradientTape.batch_jacobian hace exactamente eso:
jb = tape.batch_jacobian(y, x)
jb.shape
WARNING:tensorflow:5 out of the last 5 calls to <function pfor.<locals>.f at 0x7f7d601250e0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details. TensorShape([7, 6, 5])
error = tf.reduce_max(abs(jb - j_sum))
assert error < 1e-3
print(error.numpy())
0.0
x = tf.random.normal([7, 5])
layer1 = tf.keras.layers.Dense(8, activation=tf.nn.elu)
bn = tf.keras.layers.BatchNormalization()
layer2 = tf.keras.layers.Dense(6, activation=tf.nn.elu)
with tf.GradientTape(persistent=True, watch_accessed_variables=False) as tape:
tape.watch(x)
y = layer1(x)
y = bn(y, training=True)
y = layer2(y)
j = tape.jacobian(y, x)
print(f'j.shape: {j.shape}')
WARNING:tensorflow:6 out of the last 6 calls to <function pfor.<locals>.f at 0x7f7cf062fa70> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details. j.shape: (7, 6, 7, 5)
plot_as_patches(j)
_ = plt.title('These slices are not diagonal')
_ = plt.xlabel("Don't use `batch_jacobian`")
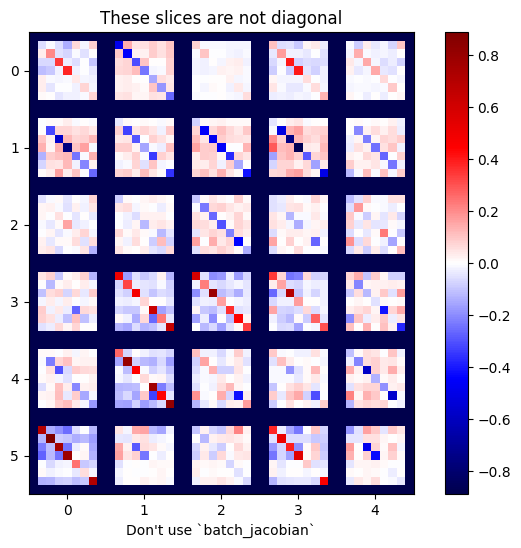
En este caso, batch_jacobian todavía se ejecuta y devuelve algo con la forma esperada, pero su contenido tiene un significado poco claro:
jb = tape.batch_jacobian(y, x)
print(f'jb.shape: {jb.shape}')
jb.shape: (7, 6, 5)