
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Diferensiasi dan Gradien Otomatis
Diferensiasi otomatis berguna untuk menerapkan algoritma pembelajaran mesin seperti backpropagation untuk melatih jaringan saraf.
Dalam panduan ini, Anda akan mempelajari cara menghitung gradien dengan TensorFlow, terutama dalam eksekusi bersemangat .
Mempersiapkan
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
Gradien komputasi
Untuk membedakan secara otomatis, TensorFlow perlu mengingat operasi apa yang terjadi dalam urutan apa selama forward pass. Kemudian, selama lintasan mundur , TensorFlow menelusuri daftar operasi ini dalam urutan terbalik untuk menghitung gradien.
Pita gradien
TensorFlow menyediakan tf.GradientTape API untuk diferensiasi otomatis; yaitu, menghitung gradien perhitungan sehubungan dengan beberapa input, biasanya tf.Variable s. TensorFlow "merekam" operasi relevan yang dijalankan di dalam konteks tf.GradientTape ke "pita". TensorFlow kemudian menggunakan pita itu untuk menghitung gradien komputasi "yang direkam" menggunakan diferensiasi mode terbalik .
Berikut adalah contoh sederhana:
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
Setelah Anda merekam beberapa operasi, gunakan GradientTape.gradient(target, sources) untuk menghitung gradien beberapa target (seringkali kerugian) relatif terhadap beberapa sumber (seringkali variabel model):
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
6.0
Contoh di atas menggunakan skalar, tetapi tf.GradientTape bekerja dengan mudah pada tensor apa pun:
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
Untuk mendapatkan gradien loss sehubungan dengan kedua variabel, Anda dapat meneruskan keduanya sebagai sumber ke metode gradient . Rekaman itu fleksibel tentang bagaimana sumber dilewatkan dan akan menerima kombinasi daftar atau kamus apa pun dan mengembalikan gradien yang terstruktur dengan cara yang sama (lihat tf.nest ).
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
Gradien sehubungan dengan setiap sumber memiliki bentuk sumber:
print(w.shape)
print(dl_dw.shape)
(3, 2) (3, 2)
Berikut adalah perhitungan gradien lagi, kali ini melewati kamus variabel:
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([-1.6920902, -3.2363236], dtype=float32)>
Gradien sehubungan dengan model
Adalah umum untuk mengumpulkan tf.Variables ke dalam tf.Module atau salah satu subkelasnya ( layers.Layer , keras.Model ) untuk checkpointing dan exporting .
Dalam kebanyakan kasus, Anda akan ingin menghitung gradien sehubungan dengan variabel model yang dapat dilatih. Karena semua subkelas tf.Module menggabungkan variabelnya dalam properti Module.trainable_variables , Anda dapat menghitung gradien ini dalam beberapa baris kode:
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
dense/kernel:0, shape: (3, 2) dense/bias:0, shape: (2,)
Mengontrol apa yang dilihat oleh rekaman itu
Perilaku default adalah merekam semua operasi setelah mengakses tf.Variable yang dapat dilatih. Alasan untuk ini adalah:
- Rekaman itu perlu mengetahui operasi mana yang harus direkam pada lintasan maju untuk menghitung gradien pada lintasan mundur.
- Rekaman itu menyimpan referensi ke keluaran antara, jadi Anda tidak ingin merekam operasi yang tidak perlu.
- Kasus penggunaan yang paling umum melibatkan penghitungan gradien kerugian sehubungan dengan semua variabel yang dapat dilatih dari model.
Misalnya, berikut ini gagal menghitung gradien karena tf.Tensor tidak "diawasi" secara default, dan tf.Variable tidak dapat dilatih:
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
tf.Tensor(6.0, shape=(), dtype=float32) None None None
Anda dapat membuat daftar variabel yang sedang ditonton oleh kaset menggunakan metode GradientTape.watched_variables :
[var.name for var in tape.watched_variables()]
['x0:0']
tf.GradientTape menyediakan pengait yang memberi pengguna kendali atas apa yang ditonton atau tidak.
Untuk merekam gradien sehubungan dengan tf.Tensor , Anda perlu memanggil GradientTape.watch(x) :
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
6.0
Sebaliknya, untuk menonaktifkan perilaku default menonton semua tf.Variables , setel watch_accessed_variables=False saat membuat pita gradien. Perhitungan ini menggunakan dua variabel, tetapi hanya menghubungkan gradien untuk salah satu variabel:
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
Karena GradientTape.watch tidak dipanggil pada x0 , tidak ada gradien yang dihitung sehubungan dengan itu:
# dys/dx1 = exp(x1) / (1 + exp(x1)) = sigmoid(x1)
grad = tape.gradient(ys, {'x0': x0, 'x1': x1})
print('dy/dx0:', grad['x0'])
print('dy/dx1:', grad['x1'].numpy())
dy/dx0: None dy/dx1: 0.9999546
Hasil antara
Anda juga dapat meminta gradien keluaran sehubungan dengan nilai antara yang dihitung di dalam konteks tf.GradientTape .
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x * x
z = y * y
# Use the tape to compute the gradient of z with respect to the
# intermediate value y.
# dz_dy = 2 * y and y = x ** 2 = 9
print(tape.gradient(z, y).numpy())
18.0
Secara default, sumber daya yang dimiliki oleh GradientTape dilepaskan segera setelah metode GradientTape.gradient dipanggil. Untuk menghitung beberapa gradien melalui perhitungan yang sama, buat pita gradien dengan persistent=True . Hal ini memungkinkan beberapa panggilan ke metode gradient sebagai sumber daya dilepaskan ketika objek tape adalah sampah yang dikumpulkan. Sebagai contoh:
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
print(tape.gradient(z, x).numpy()) # [4.0, 108.0] (4 * x**3 at x = [1.0, 3.0])
print(tape.gradient(y, x).numpy()) # [2.0, 6.0] (2 * x at x = [1.0, 3.0])
[ 4. 108.] [2. 6.]
del tape # Drop the reference to the tape
Catatan tentang kinerja
Ada overhead kecil yang terkait dengan melakukan operasi di dalam konteks pita gradien. Untuk eksekusi yang paling bersemangat, ini tidak akan menjadi biaya yang nyata, tetapi Anda masih harus menggunakan konteks pita di sekitar area hanya di mana diperlukan.
Pita gradien menggunakan memori untuk menyimpan hasil antara, termasuk masukan dan keluaran, untuk digunakan selama lintasan mundur.
Untuk efisiensi, beberapa ops (seperti
ReLU) tidak perlu mempertahankan hasil antara dan mereka dipangkas selama forward pass. Namun, jika Anda menggunakanpersistent=Truepada kaset Anda, tidak ada yang dibuang dan penggunaan memori puncak Anda akan lebih tinggi.
Gradien target non-skalar
Gradien pada dasarnya adalah operasi pada skalar.
x = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient(y0, x).numpy())
print(tape.gradient(y1, x).numpy())
4.0 -0.25
Jadi, jika Anda meminta gradien beberapa target, hasil untuk setiap sumber adalah:
- Gradien jumlah target, atau setara
- Jumlah gradien setiap target.
x = tf.Variable(2.0)
with tf.GradientTape() as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy())
3.75
Demikian pula, jika target bukan skalar, gradien jumlah dihitung:
x = tf.Variable(2.)
with tf.GradientTape() as tape:
y = x * [3., 4.]
print(tape.gradient(y, x).numpy())
7.0
Ini membuatnya mudah untuk mengambil gradien jumlah kumpulan kerugian, atau gradien jumlah dari perhitungan kerugian elemen-bijaksana.
Jika Anda membutuhkan gradien terpisah untuk setiap item, lihat Jacobian .
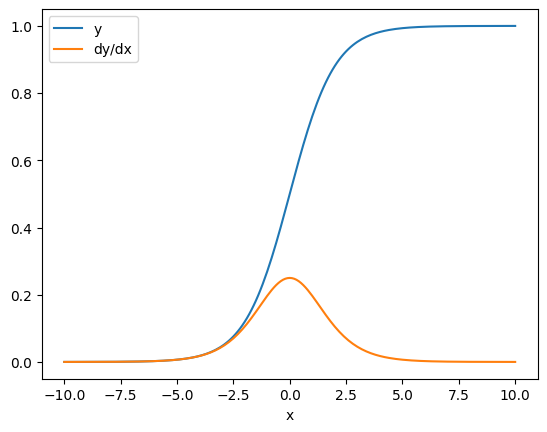
Dalam beberapa kasus, Anda dapat melewatkan Jacobian. Untuk perhitungan elemen-bijaksana, gradien jumlah memberikan turunan dari setiap elemen sehubungan dengan elemen inputnya, karena setiap elemen independen:
x = tf.linspace(-10.0, 10.0, 200+1)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.nn.sigmoid(x)
dy_dx = tape.gradient(y, x)
plt.plot(x, y, label='y')
plt.plot(x, dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
Kontrol aliran
Karena pita gradien merekam operasi saat dijalankan, aliran kontrol Python ditangani secara alami (misalnya, pernyataan if dan while ).
Di sini variabel yang berbeda digunakan pada setiap cabang if . Gradien hanya terhubung ke variabel yang digunakan:
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
tf.Tensor(1.0, shape=(), dtype=float32) None
Ingatlah bahwa pernyataan kontrol itu sendiri tidak dapat dibedakan, sehingga tidak terlihat oleh pengoptimal berbasis gradien.
Bergantung pada nilai x dalam contoh di atas, pita merekam result = v0 atau result = v1**2 . Gradien terhadap x selalu None .
dx = tape.gradient(result, x)
print(dx)
None
Mendapatkan gradien None
Ketika target tidak terhubung ke sumber, Anda akan mendapatkan gradien None .
x = tf.Variable(2.)
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y * y
print(tape.gradient(z, x))
None
Di sini z jelas tidak terhubung ke x , tetapi ada beberapa cara yang kurang jelas bahwa gradien dapat diputuskan.
1. Mengganti variabel dengan tensor
Di bagian "mengontrol apa yang ditonton kaset" Anda melihat bahwa kaset akan secara otomatis menonton tf.Variable tetapi bukan tf.Tensor .
Satu kesalahan umum adalah secara tidak sengaja mengganti tf.Variable dengan tf.Tensor , daripada menggunakan Variable.assign untuk memperbarui tf.Variable . Berikut ini contohnya:
x = tf.Variable(2.0)
for epoch in range(2):
with tf.GradientTape() as tape:
y = x+1
print(type(x).__name__, ":", tape.gradient(y, x))
x = x + 1 # This should be `x.assign_add(1)`
ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32) EagerTensor : None
2. Melakukan perhitungan di luar TensorFlow
Kaset tidak dapat merekam jalur gradien jika perhitungan keluar dari TensorFlow. Sebagai contoh:
x = tf.Variable([[1.0, 2.0],
[3.0, 4.0]], dtype=tf.float32)
with tf.GradientTape() as tape:
x2 = x**2
# This step is calculated with NumPy
y = np.mean(x2, axis=0)
# Like most ops, reduce_mean will cast the NumPy array to a constant tensor
# using `tf.convert_to_tensor`.
y = tf.reduce_mean(y, axis=0)
print(tape.gradient(y, x))
None
3. Mengambil gradien melalui bilangan bulat atau string
Integer dan string tidak dapat dibedakan. Jika jalur perhitungan menggunakan tipe data ini, tidak akan ada gradien.
Tidak ada yang mengharapkan string untuk dibedakan, tetapi mudah untuk secara tidak sengaja membuat konstanta atau variabel int jika Anda tidak menentukan dtype .
x = tf.constant(10)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
print(g.gradient(y, x))
WARNING:tensorflow:The dtype of the watched tensor must be floating (e.g. tf.float32), got tf.int32 WARNING:tensorflow:The dtype of the target tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 WARNING:tensorflow:The dtype of the source tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 None
TensorFlow tidak secara otomatis mentransmisikan antar jenis, jadi, dalam praktiknya, Anda akan sering mendapatkan kesalahan jenis alih-alih gradien yang hilang.
4. Mengambil gradien melalui objek stateful
Negara menghentikan gradien. Ketika Anda membaca dari objek stateful, kaset hanya dapat mengamati keadaan saat ini, bukan sejarah yang mengarah ke sana.
tf.Tensor tidak dapat diubah. Anda tidak dapat mengubah tensor setelah dibuat. Ini memiliki nilai , tetapi tidak ada status . Semua operasi yang dibahas sejauh ini juga tidak memiliki status: output dari tf.matmul hanya bergantung pada inputnya.
Sebuah tf.Variable memiliki status internal—nilainya. Saat Anda menggunakan variabel, status dibaca. Menghitung gradien terhadap variabel adalah hal yang normal, tetapi status variabel menghalangi penghitungan gradien untuk mundur lebih jauh. Sebagai contoh:
x0 = tf.Variable(3.0)
x1 = tf.Variable(0.0)
with tf.GradientTape() as tape:
# Update x1 = x1 + x0.
x1.assign_add(x0)
# The tape starts recording from x1.
y = x1**2 # y = (x1 + x0)**2
# This doesn't work.
print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x0)
None
Demikian pula, iterator tf.data.Dataset dan tf.queue s adalah stateful, dan akan menghentikan semua gradien pada tensor yang melewatinya.
Tidak ada gradien yang terdaftar
Beberapa tf.Operation s terdaftar sebagai non-diferensiabel dan akan mengembalikan None . Lainnya tidak memiliki gradien terdaftar .
Halaman tf.raw_ops menunjukkan operasi tingkat rendah mana yang memiliki gradien terdaftar.
Jika Anda mencoba mengambil gradien melalui operasi float yang tidak memiliki gradien yang terdaftar, rekaman itu akan memunculkan kesalahan alih-alih mengembalikan None secara diam-diam. Dengan cara ini Anda tahu ada yang tidak beres.
Misalnya, fungsi tf.image.adjust_contrast membungkus raw_ops.AdjustContrastv2 , yang dapat memiliki gradien tetapi gradien tidak diterapkan:
image = tf.Variable([[[0.5, 0.0, 0.0]]])
delta = tf.Variable(0.1)
with tf.GradientTape() as tape:
new_image = tf.image.adjust_contrast(image, delta)
try:
print(tape.gradient(new_image, [image, delta]))
assert False # This should not happen.
except LookupError as e:
print(f'{type(e).__name__}: {e}')
LookupError: gradient registry has no entry for: AdjustContrastv2
Jika Anda perlu membedakan melalui operasi ini, Anda harus mengimplementasikan gradien dan mendaftarkannya (menggunakan tf.RegisterGradient ) atau mengimplementasikan kembali fungsi menggunakan operasi lain.
Nol bukannya Tidak Ada
Dalam beberapa kasus akan lebih mudah untuk mendapatkan 0 daripada None untuk gradien yang tidak terhubung. Anda dapat memutuskan apa yang akan dikembalikan ketika Anda memiliki gradien yang tidak terhubung menggunakan argumen unconnected_gradients :
x = tf.Variable([2., 2.])
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y**2
print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO))
tf.Tensor([0. 0.], shape=(2,), dtype=float32)