
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub |
L'API tf.data consente di creare pipeline di input complesse da parti semplici e riutilizzabili. Ad esempio, la pipeline per un modello di immagine potrebbe aggregare dati da file in un file system distribuito, applicare perturbazioni casuali a ciascuna immagine e unire immagini selezionate casualmente in un batch per l'addestramento. La pipeline per un modello di testo potrebbe comportare l'estrazione di simboli da dati di testo non elaborati, la loro conversione in identificatori incorporati con una tabella di ricerca e il raggruppamento di sequenze di lunghezze diverse. L'API tf.data consente di gestire grandi quantità di dati, leggere da diversi formati di dati ed eseguire trasformazioni complesse.
L'API tf.data introduce un'astrazione tf.data.Dataset che rappresenta una sequenza di elementi, in cui ogni elemento è costituito da uno o più componenti. Ad esempio, in una pipeline di immagini, un elemento potrebbe essere un singolo esempio di addestramento, con una coppia di componenti tensoriali che rappresentano l'immagine e la relativa etichetta.
Esistono due modi distinti per creare un set di dati:
Un'origine dati costruisce un
Datasetdi dati dai dati archiviati in memoria o in uno o più file.Una trasformazione dei dati costruisce un set di dati da uno o più oggetti
tf.data.Dataset.
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.set_printoptions(precision=4)
Meccanica di base
Per creare una pipeline di input, devi iniziare con un'origine dati. Ad esempio, per costruire un Dataset dai dati in memoria, puoi usare tf.data.Dataset.from_tensors() o tf.data.Dataset.from_tensor_slices() . In alternativa, se i dati di input sono archiviati in un file nel formato TFRecord consigliato, è possibile utilizzare tf.data.TFRecordDataset() .
Una volta che hai un oggetto Dataset , puoi trasformarlo in un nuovo Dataset concatenando le chiamate al metodo sull'oggetto tf.data.Dataset . Ad esempio, puoi applicare trasformazioni per elemento come Dataset.map() e trasformazioni multielemento come Dataset.batch() . Vedere la documentazione per tf.data.Dataset per un elenco completo delle trasformazioni.
L'oggetto Dataset è un iterabile Python. Ciò rende possibile consumare i suoi elementi utilizzando un ciclo for:
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
dataset
<TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.int32, name=None)>
for elem in dataset:
print(elem.numpy())
8 3 0 8 2 1
Oppure creando esplicitamente un iteratore Python usando iter e consumando i suoi elementi usando next :
it = iter(dataset)
print(next(it).numpy())
8
In alternativa, gli elementi del set di dati possono essere utilizzati utilizzando la trasformazione reduce , che riduce tutti gli elementi per produrre un unico risultato. L'esempio seguente illustra come utilizzare la trasformazione reduce per calcolare la somma di un set di dati di numeri interi.
print(dataset.reduce(0, lambda state, value: state + value).numpy())
22
Struttura del set di dati
Un set di dati produce una sequenza di elementi , in cui ogni elemento è la stessa struttura (nidificata) dei componenti . I singoli componenti della struttura possono essere di qualsiasi tipo rappresentabile da tf.TypeSpec , inclusi tf.Tensor , tf.sparse.SparseTensor , tf.RaggedTensor , tf.TensorArray o tf.data.Dataset .
I costrutti Python che possono essere usati per esprimere la struttura (nidificata) degli elementi includono tuple , dict , NamedTuple e OrderedDict . In particolare, list non è un costrutto valido per esprimere la struttura degli elementi del set di dati. Questo perché i primi utenti di tf.data sentivano fortemente che gli input list (ad esempio passati a tf.data.Dataset.from_tensors ) venivano automaticamente impacchettati come tensori e gli output list (ad esempio valori di ritorno di funzioni definite dall'utente) venivano forzati in una tuple . Di conseguenza, se si desidera che l'input di un list venga trattato come una struttura, è necessario convertirlo in tuple e se si desidera che l'output di un list sia un singolo componente, è necessario comprimerlo in modo esplicito utilizzando tf.stack .
La proprietà Dataset.element_spec consente di controllare il tipo di ogni componente dell'elemento. La proprietà restituisce una struttura nidificata di oggetti tf.TypeSpec , corrispondente alla struttura dell'elemento, che può essere un singolo componente, una tupla di componenti o una tupla nidificata di componenti. Per esempio:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random.uniform([4, 10]))
dataset1.element_spec
TensorSpec(shape=(10,), dtype=tf.float32, name=None)
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2.element_spec
(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3.element_spec
(TensorSpec(shape=(10,), dtype=tf.float32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))
# Dataset containing a sparse tensor.
dataset4 = tf.data.Dataset.from_tensors(tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]))
dataset4.element_spec
SparseTensorSpec(TensorShape([3, 4]), tf.int32)
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
tensorflow.python.framework.sparse_tensor.SparseTensor
Le trasformazioni Dataset supportano dataset di qualsiasi struttura. Quando si utilizzano le Dataset.map() e Dataset.filter() , che applicano una funzione a ciascun elemento, la struttura dell'elemento determina gli argomenti della funzione:
dataset1 = tf.data.Dataset.from_tensor_slices(
tf.random.uniform([4, 10], minval=1, maxval=10, dtype=tf.int32))
dataset1
<TensorSliceDataset element_spec=TensorSpec(shape=(10,), dtype=tf.int32, name=None)>
for z in dataset1:
print(z.numpy())
[3 3 7 5 9 8 4 2 3 7] [8 9 6 7 5 6 1 6 2 3] [9 8 4 4 8 7 1 5 6 7] [5 9 5 4 2 5 7 8 8 8]
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))>
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3
<ZipDataset element_spec=(TensorSpec(shape=(10,), dtype=tf.int32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))>
for a, (b,c) in dataset3:
print('shapes: {a.shape}, {b.shape}, {c.shape}'.format(a=a, b=b, c=c))
shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,)
Lettura dei dati di input
Consumo di array NumPy
Vedi Caricamento di array NumPy per altri esempi.
Se tutti i dati di input rientrano nella memoria, il modo più semplice per creare un Dataset da essi è convertirli in oggetti tf.Tensor e utilizzare Dataset.from_tensor_slices() .
train, test = tf.keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset
<TensorSliceDataset element_spec=(TensorSpec(shape=(28, 28), dtype=tf.float64, name=None), TensorSpec(shape=(), dtype=tf.uint8, name=None))>
Consumo di generatori Python
Un'altra origine dati comune che può essere facilmente assimilata come tf.data.Dataset è il generatore python.
def count(stop):
i = 0
while i<stop:
yield i
i += 1
for n in count(5):
print(n)
0 1 2 3 4
Il costruttore Dataset.from_generator converte il generatore python in un tf.data.Dataset completamente funzionale.
Il costruttore accetta un callable come input, non un iteratore. Ciò gli consente di riavviare il generatore quando raggiunge la fine. Richiede un argomento args facoltativo, che viene passato come argomenti del callable.
L'argomento output_types è obbligatorio perché tf.data crea internamente un tf.Graph e gli spigoli del grafico richiedono un tf.dtype .
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
L'argomento output_shapes non è obbligatorio ma è altamente consigliato poiché molte operazioni TensorFlow non supportano tensori con un rango sconosciuto. Se la lunghezza di un particolare asse è sconosciuta o variabile, impostala come None in output_shapes .
È anche importante notare che output_shapes e output_types seguono le stesse regole di nidificazione degli altri metodi di set di dati.
Ecco un generatore di esempio che dimostra entrambi gli aspetti, restituisce tuple di array, dove il secondo array è un vettore con lunghezza sconosciuta.
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
0 : [0.3939] 1 : [ 0.9282 -0.0158 1.0096 0.7155 0.0491 0.6697 -0.2565 0.487 ] 2 : [-0.4831 0.37 -1.3918 -0.4786 0.7425 -0.3299] 3 : [ 0.1427 -1.0438 0.821 -0.8766 -0.8369 0.4168] 4 : [-1.4984 -1.8424 0.0337 0.0941 1.3286 -1.4938] 5 : [-1.3158 -1.2102 2.6887 -1.2809] 6 : []
Il primo output è un int32 il secondo è un float32 .
Il primo elemento è uno scalare, shape () , e il secondo è un vettore di lunghezza sconosciuta, shape (None,)
ds_series = tf.data.Dataset.from_generator(
gen_series,
output_types=(tf.int32, tf.float32),
output_shapes=((), (None,)))
ds_series
<FlatMapDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(None,), dtype=tf.float32, name=None))>
Ora può essere utilizzato come un normale tf.data.Dataset . Si noti che quando si esegue il batch di un set di dati con una forma variabile, è necessario utilizzare Dataset.padded_batch .
ds_series_batch = ds_series.shuffle(20).padded_batch(10)
ids, sequence_batch = next(iter(ds_series_batch))
print(ids.numpy())
print()
print(sequence_batch.numpy())
[ 8 10 18 1 5 19 22 17 21 25] [[-0.6098 0.1366 -2.15 -0.9329 0. 0. ] [ 1.0295 -0.033 -0.0388 0. 0. 0. ] [-0.1137 0.3552 0.4363 -0.2487 -1.1329 0. ] [ 0. 0. 0. 0. 0. 0. ] [-1.0466 0.624 -1.7705 1.4214 0.9143 -0.62 ] [-0.9502 1.7256 0.5895 0.7237 1.5397 0. ] [ 0.3747 1.2967 0. 0. 0. 0. ] [-0.4839 0.292 -0.7909 -0.7535 0.4591 -1.3952] [-0.0468 0.0039 -1.1185 -1.294 0. 0. ] [-0.1679 -0.3375 0. 0. 0. 0. ]]
Per un esempio più realistico, prova a eseguire il wrapping di preprocessing.image.ImageDataGenerator come tf.data.Dataset .
Per prima cosa scarica i dati:
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 10s 0us/step 228827136/228813984 [==============================] - 10s 0us/step
Crea l' image.ImageDataGenerator
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
Found 3670 images belonging to 5 classes.
print(images.dtype, images.shape)
print(labels.dtype, labels.shape)
float32 (32, 256, 256, 3) float32 (32, 5)
ds = tf.data.Dataset.from_generator(
lambda: img_gen.flow_from_directory(flowers),
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
ds.element_spec
(TensorSpec(shape=(32, 256, 256, 3), dtype=tf.float32, name=None), TensorSpec(shape=(32, 5), dtype=tf.float32, name=None))
for images, label in ds.take(1):
print('images.shape: ', images.shape)
print('labels.shape: ', labels.shape)
Found 3670 images belonging to 5 classes. images.shape: (32, 256, 256, 3) labels.shape: (32, 5)
Consumo di dati TFRecord
Vedere Caricamento di TFRecords per un esempio end-to-end.
L'API tf.data supporta una varietà di formati di file in modo da poter elaborare set di dati di grandi dimensioni che non rientrano nella memoria. Ad esempio, il formato file TFRecord è un semplice formato binario orientato al record utilizzato da molte applicazioni TensorFlow per i dati di addestramento. La classe tf.data.TFRecordDataset consente di eseguire lo streaming del contenuto di uno o più file TFRecord come parte di una pipeline di input.
Ecco un esempio che utilizza il file di prova del French Street Name Signs (FSNS).
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001 7905280/7904079 [==============================] - 1s 0us/step 7913472/7904079 [==============================] - 1s 0us/step
L'argomento dei filenames dei file dell'inizializzatore TFRecordDataset può essere una stringa, un elenco di stringhe o un tf.Tensor di stringhe. Pertanto, se hai due set di file per scopi di training e validazione, puoi creare un metodo factory che produca il set di dati, prendendo i nomi dei file come argomento di input:
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Molti progetti TensorFlow utilizzano record tf.train.Example serializzati nei loro file TFRecord. Questi devono essere decodificati prima di poter essere ispezionati:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
bytes_list {
value: "Rue Perreyon"
}
Consumo di dati di testo
Vedere Caricamento del testo per un esempio end-to-end.
Molti set di dati sono distribuiti come uno o più file di testo. tf.data.TextLineDataset fornisce un modo semplice per estrarre righe da uno o più file di testo. Dato uno o più nomi di file, un TextLineDataset produrrà un elemento con valori di stringa per riga di quei file.
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt 819200/815980 [==============================] - 0s 0us/step 827392/815980 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt 811008/809730 [==============================] - 0s 0us/step 819200/809730 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt 811008/807992 [==============================] - 0s 0us/step 819200/807992 [==============================] - 0s 0us/step
dataset = tf.data.TextLineDataset(file_paths)
Ecco le prime righe del primo file:
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
Per alternare le righe tra i file, utilizzare Dataset.interleave . Questo rende più facile mescolare i file insieme. Ecco la prima, la seconda e la terza riga di ciascuna traduzione:
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought' b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send' b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
Per impostazione predefinita, un TextLineDataset restituisce ogni riga di ogni file, il che potrebbe non essere desiderabile, ad esempio, se il file inizia con una riga di intestazione o contiene commenti. Queste righe possono essere rimosse utilizzando le Dataset.skip() o Dataset.filter() . Qui salti la prima riga, quindi filtri per trovare solo i sopravvissuti.
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
for line in titanic_lines.take(10):
print(line.numpy())
b'survived,sex,age,n_siblings_spouses,parch,fare,class,deck,embark_town,alone' b'0,male,22.0,1,0,7.25,Third,unknown,Southampton,n' b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'0,male,28.0,0,0,8.4583,Third,unknown,Queenstown,y' b'0,male,2.0,3,1,21.075,Third,unknown,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n'
def survived(line):
return tf.not_equal(tf.strings.substr(line, 0, 1), "0")
survivors = titanic_lines.skip(1).filter(survived)
for line in survivors.take(10):
print(line.numpy())
b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n' b'1,male,28.0,0,0,13.0,Second,unknown,Southampton,y' b'1,female,28.0,0,0,7.225,Third,unknown,Cherbourg,y' b'1,male,28.0,0,0,35.5,First,A,Southampton,y' b'1,female,38.0,1,5,31.3875,Third,unknown,Southampton,n'
Consumo di dati CSV
Vedi Caricamento di file CSV e Caricamento di Pandas DataFrames per altri esempi.
Il formato di file CSV è un formato popolare per la memorizzazione di dati tabulari in testo normale.
Per esempio:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file)
df.head()
Se i tuoi dati rientrano nella memoria, lo stesso metodo Dataset.from_tensor_slices funziona sui dizionari, consentendo di importare facilmente questi dati:
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived' : 0 'sex' : b'male' 'age' : 22.0 'n_siblings_spouses': 1 'parch' : 0 'fare' : 7.25 'class' : b'Third' 'deck' : b'unknown' 'embark_town' : b'Southampton' 'alone' : b'n'
Un approccio più scalabile consiste nel caricare dal disco secondo necessità.
Il modulo tf.data fornisce metodi per estrarre i record da uno o più file CSV conformi a RFC 4180 .
La funzione experimental.make_csv_dataset è l'interfaccia di alto livello per la lettura di set di file CSV. Supporta l'inferenza del tipo di colonna e molte altre funzionalità, come il batching e la mescolanza, per semplificarne l'utilizzo.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived")
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 0 0 0] features: 'sex' : [b'female' b'female' b'male' b'male'] 'age' : [32. 28. 37. 50.] 'n_siblings_spouses': [0 3 0 0] 'parch' : [0 1 1 0] 'fare' : [13. 25.4667 29.7 13. ] 'class' : [b'Second' b'Third' b'First' b'Second'] 'deck' : [b'unknown' b'unknown' b'C' b'unknown'] 'embark_town' : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton'] 'alone' : [b'y' b'n' b'n' b'y']
Puoi utilizzare l'argomento select_columns se hai bisogno solo di un sottoinsieme di colonne.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [0 1 1 0] 'fare' : [ 7.05 15.5 26.25 8.05] 'class' : [b'Third' b'Third' b'Second' b'Third']
Esiste anche una classe experimental.CsvDataset di livello inferiore che fornisce un controllo più dettagliato. Non supporta l'inferenza del tipo di colonna. Invece è necessario specificare il tipo di ciascuna colonna.
titanic_types = [tf.int32, tf.string, tf.float32, tf.int32, tf.int32, tf.float32, tf.string, tf.string, tf.string, tf.string]
dataset = tf.data.experimental.CsvDataset(titanic_file, titanic_types , header=True)
for line in dataset.take(10):
print([item.numpy() for item in line])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 38.0, 1, 0, 71.2833, b'First', b'C', b'Cherbourg', b'n'] [1, b'female', 26.0, 0, 0, 7.925, b'Third', b'unknown', b'Southampton', b'y'] [1, b'female', 35.0, 1, 0, 53.1, b'First', b'C', b'Southampton', b'n'] [0, b'male', 28.0, 0, 0, 8.4583, b'Third', b'unknown', b'Queenstown', b'y'] [0, b'male', 2.0, 3, 1, 21.075, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 27.0, 0, 2, 11.1333, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 14.0, 1, 0, 30.0708, b'Second', b'unknown', b'Cherbourg', b'n'] [1, b'female', 4.0, 1, 1, 16.7, b'Third', b'G', b'Southampton', b'n'] [0, b'male', 20.0, 0, 0, 8.05, b'Third', b'unknown', b'Southampton', b'y']
Se alcune colonne sono vuote, questa interfaccia di basso livello consente di fornire valori predefiniti anziché tipi di colonna.
%%writefile missing.csv
1,2,3,4
,2,3,4
1,,3,4
1,2,,4
1,2,3,
,,,
Writing missing.csv
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(4,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[1 2 3 4] [999 2 3 4] [ 1 999 3 4] [ 1 2 999 4] [ 1 2 3 999] [999 999 999 999]
Per impostazione predefinita, un CsvDataset restituisce ogni colonna di ogni riga del file, il che potrebbe non essere desiderabile, ad esempio se il file inizia con una riga di intestazione che dovrebbe essere ignorata o se alcune colonne non sono richieste nell'input. Queste righe e campi possono essere rimossi rispettivamente con gli argomenti header e select_cols .
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(2,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[2 4] [2 4] [999 4] [2 4] [ 2 999] [999 999]
Consumo di set di file
Esistono molti set di dati distribuiti come un insieme di file, in cui ogni file è un esempio.
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
La directory principale contiene una directory per ogni classe:
for item in flowers_root.glob("*"):
print(item.name)
sunflowers daisy LICENSE.txt roses tulips dandelion
I file in ogni directory di classe sono esempi:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/5018120483_cc0421b176_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/8642679391_0805b147cb_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/8266310743_02095e782d_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/13176521023_4d7cc74856_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/19437578578_6ab1b3c984.jpg'
Leggi i dati usando la funzione tf.io.read_file ed estrai l'etichetta dal percorso, restituendo coppie (image, label) :
def process_path(file_path):
label = tf.strings.split(file_path, os.sep)[-2]
return tf.io.read_file(file_path), label
labeled_ds = list_ds.map(process_path)
for image_raw, label_text in labeled_ds.take(1):
print(repr(image_raw.numpy()[:100]))
print()
print(label_text.numpy())
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xe2\x0cXICC_PROFILE\x00\x01\x01\x00\x00\x0cHLino\x02\x10\x00\x00mntrRGB XYZ \x07\xce\x00\x02\x00\t\x00\x06\x001\x00\x00acspMSFT\x00\x00\x00\x00IEC sRGB\x00\x00\x00\x00\x00\x00' b'daisy'
Batch di elementi del set di dati
Dosaggio semplice
La forma più semplice di batch raggruppa n elementi consecutivi di un set di dati in un singolo elemento. La trasformazione Dataset.batch() fa esattamente questo, con gli stessi vincoli dell'operatore tf.stack() , applicato a ogni componente degli elementi: cioè per ogni componente i , tutti gli elementi devono avere un tensore della stessa identica forma.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
[array([0, 1, 2, 3]), array([ 0, -1, -2, -3])] [array([4, 5, 6, 7]), array([-4, -5, -6, -7])] [array([ 8, 9, 10, 11]), array([ -8, -9, -10, -11])] [array([12, 13, 14, 15]), array([-12, -13, -14, -15])]
Mentre tf.data tenta di propagare le informazioni sulla forma, le impostazioni predefinite di Dataset.batch determinano una dimensione batch sconosciuta perché l'ultimo batch potrebbe non essere pieno. Nota il None nella forma:
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))>
Usa l'argomento drop_remainder per ignorare l'ultimo batch e ottenere la propagazione completa della forma:
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(7,), dtype=tf.int64, name=None), TensorSpec(shape=(7,), dtype=tf.int64, name=None))>
Tensori di dosaggio con imbottitura
La ricetta sopra funziona per tensori che hanno tutti la stessa dimensione. Tuttavia, molti modelli (ad es. modelli di sequenza) funzionano con dati di input che possono avere dimensioni variabili (ad es. sequenze di diversa lunghezza). Per gestire questo caso, la trasformazione Dataset.padded_batch consente di eseguire il batch di tensori di forma diversa specificando una o più dimensioni in cui possono essere riempiti.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
[[0 0 0] [1 0 0] [2 2 0] [3 3 3]] [[4 4 4 4 0 0 0] [5 5 5 5 5 0 0] [6 6 6 6 6 6 0] [7 7 7 7 7 7 7]]
La trasformazione Dataset.padded_batch consente di impostare un riempimento diverso per ciascuna dimensione di ciascun componente e può essere a lunghezza variabile (indicata da None nell'esempio sopra) o a lunghezza costante. È anche possibile sovrascrivere il valore di riempimento, che per impostazione predefinita è 0.
Flussi di lavoro di formazione
Elaborazione di più epoche
L'API tf.data offre due modi principali per elaborare più epoche degli stessi dati.
Il modo più semplice per scorrere un set di dati in più epoche consiste nell'utilizzare la trasformazione Dataset.repeat() . Innanzitutto, crea un set di dati di dati titanici:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
L'applicazione della trasformazione Dataset.repeat() senza argomenti ripeterà l'input all'infinito.
La trasformazione Dataset.repeat concatena i suoi argomenti senza segnalare la fine di un'epoca e l'inizio dell'epoca successiva. Per questo motivo un Dataset.batch applicato dopo Dataset.repeat produrrà batch che si trovano a cavallo dei confini dell'epoca:
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
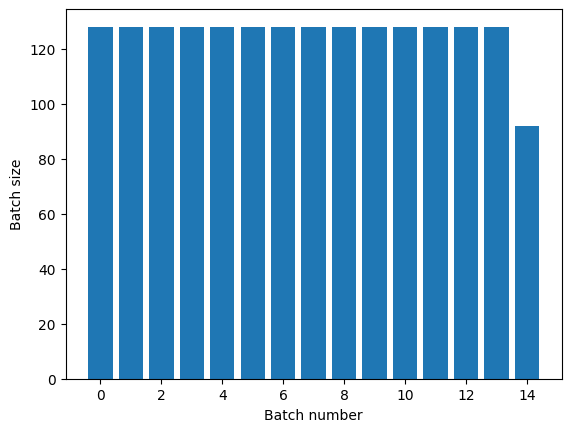
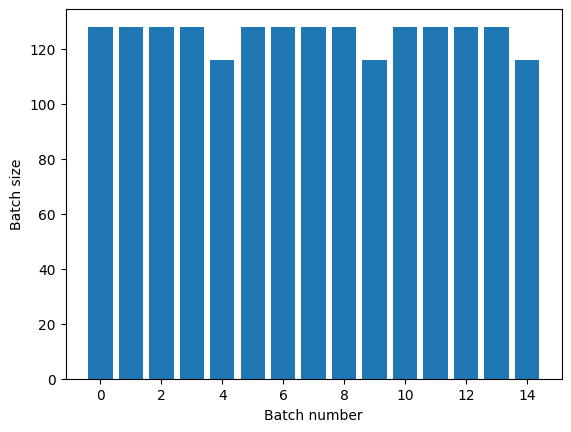
Se hai bisogno di una chiara separazione dell'epoca, metti Dataset.batch prima della ripetizione:
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
Se desideri eseguire un calcolo personalizzato (ad es. per raccogliere statistiche) alla fine di ogni epoca, è più semplice riavviare l'iterazione del set di dati su ogni epoca:
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
Mischiare casualmente i dati di input
La trasformazione Dataset.shuffle() mantiene un buffer di dimensione fissa e sceglie l'elemento successivo in modo uniforme e casuale da quel buffer.
Aggiungi un indice al set di dati in modo da poter vedere l'effetto:
lines = tf.data.TextLineDataset(titanic_file)
counter = tf.data.experimental.Counter()
dataset = tf.data.Dataset.zip((counter, lines))
dataset = dataset.shuffle(buffer_size=100)
dataset = dataset.batch(20)
dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.string, name=None))>
Poiché buffer_size è 100 e la dimensione del batch è 20, il primo batch non contiene elementi con un indice superiore a 120.
n,line_batch = next(iter(dataset))
print(n.numpy())
[ 52 94 22 70 63 96 56 102 38 16 27 104 89 43 41 68 42 61 112 8]
Come con Dataset.batch , l'ordine relativo a Dataset.repeat importante.
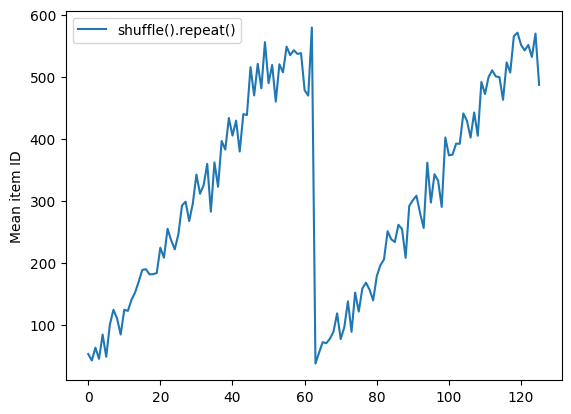
Dataset.shuffle non segnala la fine di un'epoca finché il buffer shuffle non è vuoto. Quindi un shuffle posizionato prima di una ripetizione mostrerà ogni elemento di un'epoca prima di passare a quella successiva:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
Here are the item ID's near the epoch boundary: [509 595 537 550 555 591 480 627 482 519] [522 619 538 581 569 608 531 558 461 496] [548 489 379 607 611 622 234 525] [ 59 38 4 90 73 84 27 51 107 12] [77 72 91 60 7 62 92 47 70 67]
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e7061c650>
Ma una ripetizione prima di un shuffle mescola insieme i confini dell'epoca:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
Here are the item ID's near the epoch boundary: [ 6 8 528 604 13 492 308 441 569 475] [ 5 626 615 568 20 554 520 454 10 607] [510 542 0 363 32 446 395 588 35 4] [ 7 15 28 23 39 559 585 49 252 556] [581 617 25 43 26 548 29 460 48 41] [ 19 64 24 300 612 611 36 63 69 57] [287 605 21 512 442 33 50 68 608 47] [625 90 91 613 67 53 606 344 16 44] [453 448 89 45 465 2 31 618 368 105] [565 3 586 114 37 464 12 627 30 621] [ 82 117 72 75 84 17 571 610 18 600] [107 597 575 88 623 86 101 81 456 102] [122 79 51 58 80 61 367 38 537 113] [ 71 78 598 152 143 620 100 158 133 130] [155 151 144 135 146 121 83 27 103 134]
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e706013d0>

Preelaborazione dei dati
La trasformazione Dataset.map(f) produce un nuovo set di dati applicando una determinata funzione f a ciascun elemento del set di dati di input. Si basa sulla funzione map() che viene comunemente applicata alle liste (e ad altre strutture) nei linguaggi di programmazione funzionale. La funzione f prende gli oggetti tf.Tensor che rappresentano un singolo elemento nell'input e restituisce gli oggetti tf.Tensor che rappresenteranno un singolo elemento nel nuovo set di dati. La sua implementazione utilizza le operazioni TensorFlow standard per trasformare un elemento in un altro.
Questa sezione illustra esempi comuni di utilizzo di Dataset.map() .
Decodificare i dati dell'immagine e ridimensionarli
Quando si addestra una rete neurale su dati di immagini del mondo reale, è spesso necessario convertire immagini di dimensioni diverse in una dimensione comune, in modo che possano essere raggruppate in una dimensione fissa.
Ricostruisci il set di dati dei nomi dei file dei fiori:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
Scrivere una funzione che manipola gli elementi del set di dati.
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, os.sep)
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.io.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
Prova che funziona.
file_path = next(iter(list_ds))
image, label = parse_image(file_path)
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
show(image, label)

Mappalo sul set di dati.
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)


Applicazione della logica Python arbitraria
Per motivi di prestazioni, utilizzare le operazioni TensorFlow per la preelaborazione dei dati quando possibile. Tuttavia, a volte è utile chiamare librerie Python esterne durante l'analisi dei dati di input. È possibile utilizzare l'operazione tf.py_function() in una trasformazione Dataset.map() .
Ad esempio, se vuoi applicare una rotazione casuale, il modulo tf.image ha solo tf.image.rot90 , che non è molto utile per l'aumento dell'immagine.
Per dimostrare tf.py_function , prova invece a utilizzare la funzione scipy.ndimage.rotate :
import scipy.ndimage as ndimage
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
image, label = next(iter(images_ds))
image = random_rotate_image(image)
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Per utilizzare questa funzione con Dataset.map si applicano le stesse avvertenze di Dataset.from_generator , è necessario descrivere le forme e i tipi restituiti quando si applica la funzione:
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).


Analisi dei messaggi del buffer di protocollo di tf.Example
Molte pipeline di input estraggono i messaggi del buffer del protocollo tf.train.Example da un formato TFRecord. Ogni record tf.train.Example contiene una o più "caratteristiche" e la pipeline di input in genere converte queste funzionalità in tensori.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Puoi lavorare con tf.train.Example al di fuori di un tf.data.Dataset per comprendere i dati:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
feature = parsed.features.feature
raw_img = feature['image/encoded'].bytes_list.value[0]
img = tf.image.decode_png(raw_img)
plt.imshow(img)
plt.axis('off')
_ = plt.title(feature["image/text"].bytes_list.value[0])

raw_example = next(iter(dataset))
def tf_parse(eg):
example = tf.io.parse_example(
eg[tf.newaxis], {
'image/encoded': tf.io.FixedLenFeature(shape=(), dtype=tf.string),
'image/text': tf.io.FixedLenFeature(shape=(), dtype=tf.string)
})
return example['image/encoded'][0], example['image/text'][0]
img, txt = tf_parse(raw_example)
print(txt.numpy())
print(repr(img.numpy()[:20]), "...")
b'Rue Perreyon' b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02X' ...
decoded = dataset.map(tf_parse)
decoded
<MapDataset element_spec=(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
image_batch, text_batch = next(iter(decoded.batch(10)))
image_batch.shape
TensorShape([10])
Finestratura di serie temporali
Per un esempio di serie temporali end-to-end, vedere: Previsione delle serie temporali .
I dati delle serie temporali sono spesso organizzati con l'asse temporale intatto.
Usa un semplice Dataset.range per dimostrare:
range_ds = tf.data.Dataset.range(100000)
In genere, i modelli basati su questo tipo di dati richiedono un intervallo di tempo contiguo.
L'approccio più semplice sarebbe quello di raggruppare i dati:
Usando batch
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]
Oppure, per fare previsioni dettagliate un passo nel futuro, potresti spostare le caratteristiche e le etichette di un passo l'una rispetto all'altra:
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18] => [11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28] => [21 22 23 24 25 26 27 28 29]
Per prevedere un'intera finestra invece di un offset fisso, puoi dividere i lotti in due parti:
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Inputs: All except the last 5 steps
batch[-5:]) # Labels: The last 5 steps
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] => [25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] => [40 41 42 43 44]
Per consentire una certa sovrapposizione tra le funzionalità di un batch e le etichette di un altro, utilizzare Dataset.zip :
feature_length = 10
label_length = 3
features = range_ds.batch(feature_length, drop_remainder=True)
labels = range_ds.batch(feature_length).skip(1).map(lambda labels: labels[:label_length])
predicted_steps = tf.data.Dataset.zip((features, labels))
for features, label in predicted_steps.take(5):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12] [10 11 12 13 14 15 16 17 18 19] => [20 21 22] [20 21 22 23 24 25 26 27 28 29] => [30 31 32] [30 31 32 33 34 35 36 37 38 39] => [40 41 42] [40 41 42 43 44 45 46 47 48 49] => [50 51 52]
Usando window
Durante l'utilizzo Dataset.batch funziona, ci sono situazioni in cui potrebbe essere necessario un controllo più preciso. Il metodo Dataset.window ti dà il controllo completo, ma richiede una certa attenzione: restituisce un Dataset of Datasets . Vedere la struttura del set di dati per i dettagli.
window_size = 5
windows = range_ds.window(window_size, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
<_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)>
Il metodo Dataset.flat_map può prendere un set di dati di set di dati e appiattirlo in un unico set di dati:
for x in windows.flat_map(lambda x: x).take(30):
print(x.numpy(), end=' ')
0 1 2 3 4 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
In quasi tutti i casi, vorrai prima eseguire il .batch del set di dati:
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]
Ora puoi vedere che l'argomento shift controlla quanto si sposta ogni finestra.
Mettendolo insieme potresti scrivere questa funzione:
def make_window_dataset(ds, window_size=5, shift=1, stride=1):
windows = ds.window(window_size, shift=shift, stride=stride)
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
windows = windows.flat_map(sub_to_batch)
return windows
ds = make_window_dataset(range_ds, window_size=10, shift = 5, stride=3)
for example in ds.take(10):
print(example.numpy())
[ 0 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34 37] [15 18 21 24 27 30 33 36 39 42] [20 23 26 29 32 35 38 41 44 47] [25 28 31 34 37 40 43 46 49 52] [30 33 36 39 42 45 48 51 54 57] [35 38 41 44 47 50 53 56 59 62] [40 43 46 49 52 55 58 61 64 67] [45 48 51 54 57 60 63 66 69 72]
Quindi è facile estrarre le etichette, come prima:
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
[ 0 3 6 9 12 15 18 21 24] => [ 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29] => [ 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34] => [13 16 19 22 25 28 31 34 37]
Ricampionamento
Quando si lavora con un set di dati molto sbilanciato in termini di classi, potresti voler ricampionare il set di dati. tf.data fornisce due metodi per farlo. Il set di dati sulle frodi con carta di credito è un buon esempio di questo tipo di problema.
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip',
fname='creditcard.zip',
extract=True)
csv_path = zip_path.replace('.zip', '.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip 69156864/69155632 [==============================] - 2s 0us/step 69165056/69155632 [==============================] - 2s 0us/step
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
Ora, controlla la distribuzione delle classi, è molto distorta:
def count(counts, batch):
features, labels = batch
class_1 = labels == 1
class_1 = tf.cast(class_1, tf.int32)
class_0 = labels == 0
class_0 = tf.cast(class_0, tf.int32)
counts['class_0'] += tf.reduce_sum(class_0)
counts['class_1'] += tf.reduce_sum(class_1)
return counts
counts = creditcard_ds.take(10).reduce(
initial_state={'class_0': 0, 'class_1': 0},
reduce_func = count)
counts = np.array([counts['class_0'].numpy(),
counts['class_1'].numpy()]).astype(np.float32)
fractions = counts/counts.sum()
print(fractions)
[0.9956 0.0044]
Un approccio comune all'allenamento con un set di dati sbilanciato consiste nel bilanciarlo. tf.data include alcuni metodi che abilitano questo flusso di lavoro:
Campionamento dei set di dati
Un approccio al ricampionamento di un set di dati consiste nell'usare sample_from_datasets . Questo è più applicabile quando si dispone di un data.Dataset separato per ogni classe.
Qui, usa semplicemente il filtro per generarli dai dati sulle frodi con carta di credito:
negative_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==0)
.repeat())
positive_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==1)
.repeat())
for features, label in positive_ds.batch(10).take(1):
print(label.numpy())
[1 1 1 1 1 1 1 1 1 1]
Per utilizzare tf.data.Dataset.sample_from_datasets , passare i set di dati e il peso per ciascuno:
balanced_ds = tf.data.Dataset.sample_from_datasets(
[negative_ds, positive_ds], [0.5, 0.5]).batch(10)
Ora il set di dati produce esempi di ogni classe con probabilità 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
[1 0 1 0 1 0 1 1 1 1] [0 0 1 1 0 1 1 1 1 1] [1 1 1 1 0 0 1 0 1 0] [1 1 1 0 1 0 0 1 1 1] [0 1 0 1 1 1 0 1 1 0] [0 1 0 0 0 1 0 0 0 0] [1 1 1 1 1 0 0 1 1 0] [0 0 0 1 0 1 1 1 0 0] [0 0 1 1 1 1 0 1 1 1] [1 0 0 1 1 1 1 0 1 1]
Ricampionamento del rifiuto
Un problema con l'approccio Dataset.sample_from_datasets di cui sopra è che necessita di un tf.data.Dataset separato per classe. È possibile utilizzare Dataset.filter per creare questi due set di dati, ma ciò comporta il caricamento di tutti i dati due volte.
Il metodo data.Dataset.rejection_resample può essere applicato a un set di dati per ribilanciarlo, caricandolo solo una volta. Gli elementi verranno eliminati dal set di dati per raggiungere l'equilibrio.
data.Dataset.rejection_resample accetta un argomento class_func . Questa class_func viene applicata a ciascun elemento del set di dati e viene utilizzata per determinare a quale classe appartiene un esempio ai fini del bilanciamento.
L'obiettivo qui è bilanciare la distribuzione dell'etichetta e gli elementi di creditcard_ds sono già coppie (features, label) . Quindi class_func deve solo restituire quelle etichette:
def class_func(features, label):
return label
Il metodo di ricampionamento si occupa di singoli esempi, quindi in questo caso è necessario unbatch il batch del set di dati prima di applicare quel metodo.
Il metodo richiede una distribuzione target e, facoltativamente, una stima della distribuzione iniziale come input.
resample_ds = (
creditcard_ds
.unbatch()
.rejection_resample(class_func, target_dist=[0.5,0.5],
initial_dist=fractions)
.batch(10))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:5797: Print (from tensorflow.python.ops.logging_ops) is deprecated and will be removed after 2018-08-20. Instructions for updating: Use tf.print instead of tf.Print. Note that tf.print returns a no-output operator that directly prints the output. Outside of defuns or eager mode, this operator will not be executed unless it is directly specified in session.run or used as a control dependency for other operators. This is only a concern in graph mode. Below is an example of how to ensure tf.print executes in graph mode:
Il metodo rejection_resample restituisce (class, example) coppie in cui la class è l'output di class_func . In questo caso, l' example era già una coppia (feature, label) , quindi usa la map per eliminare la copia extra delle etichette:
balanced_ds = resample_ds.map(lambda extra_label, features_and_label: features_and_label)
Ora il set di dati produce esempi di ogni classe con probabilità 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] [0 1 1 1 0 1 1 0 1 1] [1 1 0 1 0 0 0 0 1 1] [1 1 1 1 0 0 0 0 1 1] [1 0 0 1 0 0 1 0 1 1] [1 0 0 0 0 1 0 0 0 0] [1 0 0 1 1 0 1 1 1 0] [1 1 0 0 0 0 0 0 0 1] [0 0 1 0 0 0 1 0 1 1] [0 1 0 1 0 1 0 0 0 1] [0 0 0 0 0 0 0 0 1 1]
Checkpoint dell'iteratore
Tensorflow supporta l' acquisizione di checkpoint in modo che quando il processo di addestramento viene riavviato, possa ripristinare l'ultimo checkpoint per recuperare la maggior parte dei suoi progressi. Oltre a controllare le variabili del modello, puoi anche controllare l'avanzamento dell'iteratore del set di dati. Questo potrebbe essere utile se si dispone di un set di dati di grandi dimensioni e non si desidera avviare il set di dati dall'inizio a ogni riavvio. Si noti tuttavia che i checkpoint dell'iteratore possono essere grandi, poiché trasformazioni come shuffle e prefetch richiedono elementi di buffering all'interno dell'iteratore.
Per includere il tuo iteratore in un checkpoint, passa l'iteratore al costruttore tf.train.Checkpoint .
range_ds = tf.data.Dataset.range(20)
iterator = iter(range_ds)
ckpt = tf.train.Checkpoint(step=tf.Variable(0), iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, '/tmp/my_ckpt', max_to_keep=3)
print([next(iterator).numpy() for _ in range(5)])
save_path = manager.save()
print([next(iterator).numpy() for _ in range(5)])
ckpt.restore(manager.latest_checkpoint)
print([next(iterator).numpy() for _ in range(5)])
[0, 1, 2, 3, 4] [5, 6, 7, 8, 9] [5, 6, 7, 8, 9]
Utilizzo di tf.data con tf.keras
L'API tf.keras semplifica molti aspetti della creazione e dell'esecuzione di modelli di machine learning. Le sue .fit() e .evaluate() e .predict() supportano i set di dati come input. Ecco un rapido set di dati e configurazione del modello:
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255.0
labels = labels.astype(np.int32)
fmnist_train_ds = tf.data.Dataset.from_tensor_slices((images, labels))
fmnist_train_ds = fmnist_train_ds.shuffle(5000).batch(32)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Il passaggio di un set di dati di coppie (feature, label) è tutto ciò che serve per Model.fit e Model.evaluate :
model.fit(fmnist_train_ds, epochs=2)
Epoch 1/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5984 - accuracy: 0.7973 Epoch 2/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4607 - accuracy: 0.8430 <keras.callbacks.History at 0x7f7e70283110>
Se passi un set di dati infinito, ad esempio chiamando Dataset.repeat() , devi solo passare anche l'argomento steps_per_epoch :
model.fit(fmnist_train_ds.repeat(), epochs=2, steps_per_epoch=20)
Epoch 1/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4574 - accuracy: 0.8672 Epoch 2/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4216 - accuracy: 0.8562 <keras.callbacks.History at 0x7f7e144948d0>
Per la valutazione puoi superare il numero di fasi di valutazione:
loss, accuracy = model.evaluate(fmnist_train_ds)
print("Loss :", loss)
print("Accuracy :", accuracy)
1875/1875 [==============================] - 4s 2ms/step - loss: 0.4350 - accuracy: 0.8524 Loss : 0.4350026249885559 Accuracy : 0.8524333238601685
Per set di dati lunghi, imposta il numero di passaggi da valutare:
loss, accuracy = model.evaluate(fmnist_train_ds.repeat(), steps=10)
print("Loss :", loss)
print("Accuracy :", accuracy)
10/10 [==============================] - 0s 2ms/step - loss: 0.4345 - accuracy: 0.8687 Loss : 0.43447819352149963 Accuracy : 0.8687499761581421
Le etichette non sono obbligatorie quando si chiama Model.predict .
predict_ds = tf.data.Dataset.from_tensor_slices(images).batch(32)
result = model.predict(predict_ds, steps = 10)
print(result.shape)
(320, 10)
Ma le etichette vengono ignorate se si passa un set di dati che le contiene:
result = model.predict(fmnist_train_ds, steps = 10)
print(result.shape)
(320, 10)