
Este guia demonstra como usar as ferramentas disponíveis com o TensorFlow Profiler para monitorar o desempenho dos seus modelos do TensorFlow. Você aprenderá como entender o desempenho do seu modelo no host (CPU), no dispositivo (GPU) ou em uma combinação do host e do(s) dispositivo(s).
A criação de perfil ajuda a entender o consumo de recursos de hardware (tempo e memória) das diversas operações (ops) do TensorFlow em seu modelo e a resolver gargalos de desempenho e, em última análise, tornar a execução do modelo mais rápida.
Este guia orientará você sobre como instalar o Profiler, as diversas ferramentas disponíveis, os diferentes modos de como o Profiler coleta dados de desempenho e algumas práticas recomendadas para otimizar o desempenho do modelo.
Se você quiser criar um perfil de desempenho do seu modelo em Cloud TPUs, consulte o guia do Cloud TPU .
Instale os pré-requisitos do Profiler e da GPU
Instale o plugin Profiler para TensorBoard com pip. Observe que o Profiler requer as versões mais recentes do TensorFlow e do TensorBoard (>=2.2).
pip install -U tensorboard_plugin_profile
Para criar perfil na GPU, você deve:
- Atenda aos drivers de GPU NVIDIA® e aos requisitos do kit de ferramentas CUDA® listados em Requisitos de software de suporte de GPU do TensorFlow .
Certifique-se de que a NVIDIA® CUDA® Profiling Tools Interface (CUPTI) exista no caminho:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
Se você não tiver CUPTI no caminho, anexe seu diretório de instalação à variável de ambiente $LD_LIBRARY_PATH executando:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
Em seguida, execute o comando ldconfig acima novamente para verificar se a biblioteca CUPTI foi encontrada.
Resolver problemas de privilégio
Ao executar a criação de perfil com o CUDA Toolkit em um ambiente Docker ou no Linux, você pode encontrar problemas relacionados a privilégios CUPTI insuficientes ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ). Acesse os documentos do desenvolvedor NVIDIA para saber mais sobre como você pode resolver esses problemas no Linux.
Para resolver problemas de privilégio CUPTI em um ambiente Docker, execute
docker run option '--privileged=true'
Ferramentas de criação de perfil
Acesse o Profiler na guia Profile no TensorBoard, que aparece somente depois de você capturar alguns dados do modelo.
O Profiler possui uma seleção de ferramentas para ajudar na análise de desempenho:
- Página de visão geral
- Analisador de pipeline de entrada
- Estatísticas do TensorFlow
- Visualizador de rastreamento
- Estatísticas do kernel da GPU
- Ferramenta de perfil de memória
- Visualizador de pods
Página de visão geral
A página de visão geral fornece uma visão de nível superior do desempenho do seu modelo durante a execução de um perfil. A página mostra uma página de visão geral agregada para seu host e todos os dispositivos, além de algumas recomendações para melhorar o desempenho do treinamento do modelo. Você também pode selecionar hosts individuais no menu suspenso Host.
A página de visão geral exibe os dados da seguinte forma:
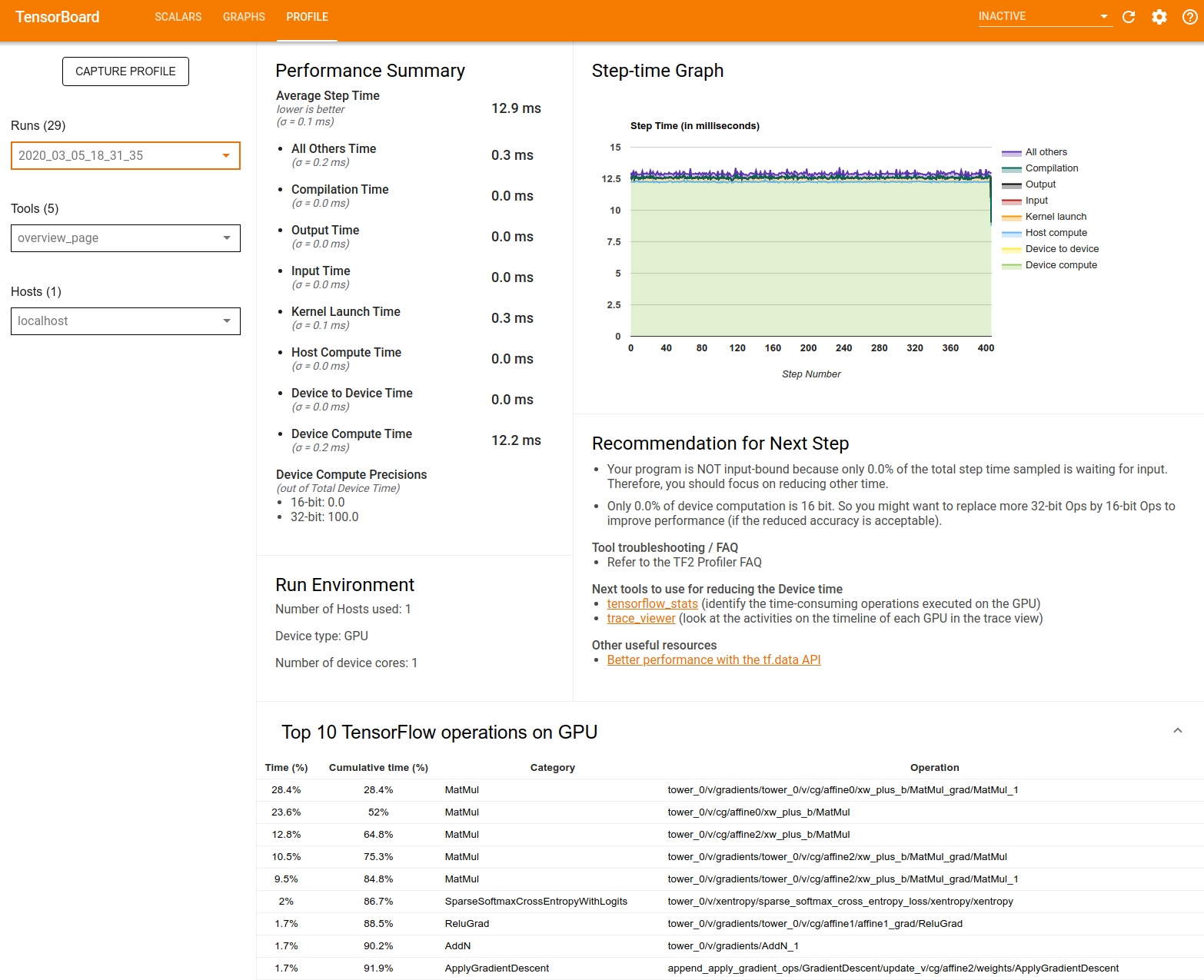
Resumo de desempenho : exibe um resumo de alto nível do desempenho do seu modelo. O resumo de desempenho tem duas partes:
Detalhamento do tempo da etapa: divide o tempo médio da etapa em várias categorias de onde o tempo é gasto:
- Compilação: Tempo gasto compilando kernels.
- Entrada: Tempo gasto na leitura dos dados de entrada.
- Saída: Tempo gasto na leitura dos dados de saída.
- Lançamento do kernel: Tempo gasto pelo host para lançar kernels
- Tempo de computação do host.
- Tempo de comunicação entre dispositivos.
- Tempo de computação no dispositivo.
- Todos os outros, incluindo sobrecarga do Python.
Precisões de computação do dispositivo – Informa a porcentagem do tempo de computação do dispositivo que usa cálculos de 16 e 32 bits.
Gráfico de tempo de passo : exibe um gráfico do tempo de passo do dispositivo (em milissegundos) em todas as etapas amostradas. Cada etapa é dividida em múltiplas categorias (com cores diferentes) de onde o tempo é gasto. A área vermelha corresponde à parte do tempo em que os dispositivos ficaram ociosos aguardando dados de entrada do host. A área verde mostra quanto tempo o dispositivo realmente funcionou.
As 10 principais operações do TensorFlow no dispositivo (por exemplo, GPU) : exibe as operações no dispositivo que foram executadas por mais tempo.
Cada linha exibe o tempo próprio de uma operação (como a porcentagem de tempo gasto por todas as operações), tempo acumulado, categoria e nome.
Ambiente de execução : exibe um resumo de alto nível do ambiente de execução do modelo, incluindo:
- Número de hosts usados.
- Tipo de dispositivo (GPU/TPU).
- Número de núcleos do dispositivo.
Recomendação para a próxima etapa : informa quando um modelo é vinculado à entrada e recomenda ferramentas que você pode usar para localizar e resolver gargalos de desempenho do modelo.
Analisador de pipeline de entrada
Quando um programa do TensorFlow lê dados de um arquivo, ele começa na parte superior do gráfico do TensorFlow em pipeline. O processo de leitura é dividido em múltiplos estágios de processamento de dados conectados em série, onde a saída de um estágio é a entrada do próximo. Este sistema de leitura de dados é chamado de pipeline de entrada .
Um pipeline típico para leitura de registros de arquivos possui os seguintes estágios:
- Leitura de arquivos.
- Pré-processamento de arquivo (opcional).
- Transferência de arquivos do host para o dispositivo.
Um pipeline de entrada ineficiente pode desacelerar gravemente seu aplicativo. Um aplicativo é considerado vinculado à entrada quando passa uma parte significativa do tempo no pipeline de entrada. Use os insights obtidos do analisador de pipeline de entrada para entender onde o pipeline de entrada é ineficiente.
O analisador de pipeline de entrada informa imediatamente se o seu programa está vinculado à entrada e orienta você na análise do lado do dispositivo e do host para depurar gargalos de desempenho em qualquer estágio do pipeline de entrada.
Verifique as orientações sobre o desempenho do pipeline de entrada para conhecer as práticas recomendadas para otimizar seus pipelines de entrada de dados.
Painel do pipeline de entrada
Para abrir o analisador de pipeline de entrada, selecione Perfil e, em seguida, selecione input_pipeline_analyzer no menu suspenso Ferramentas .
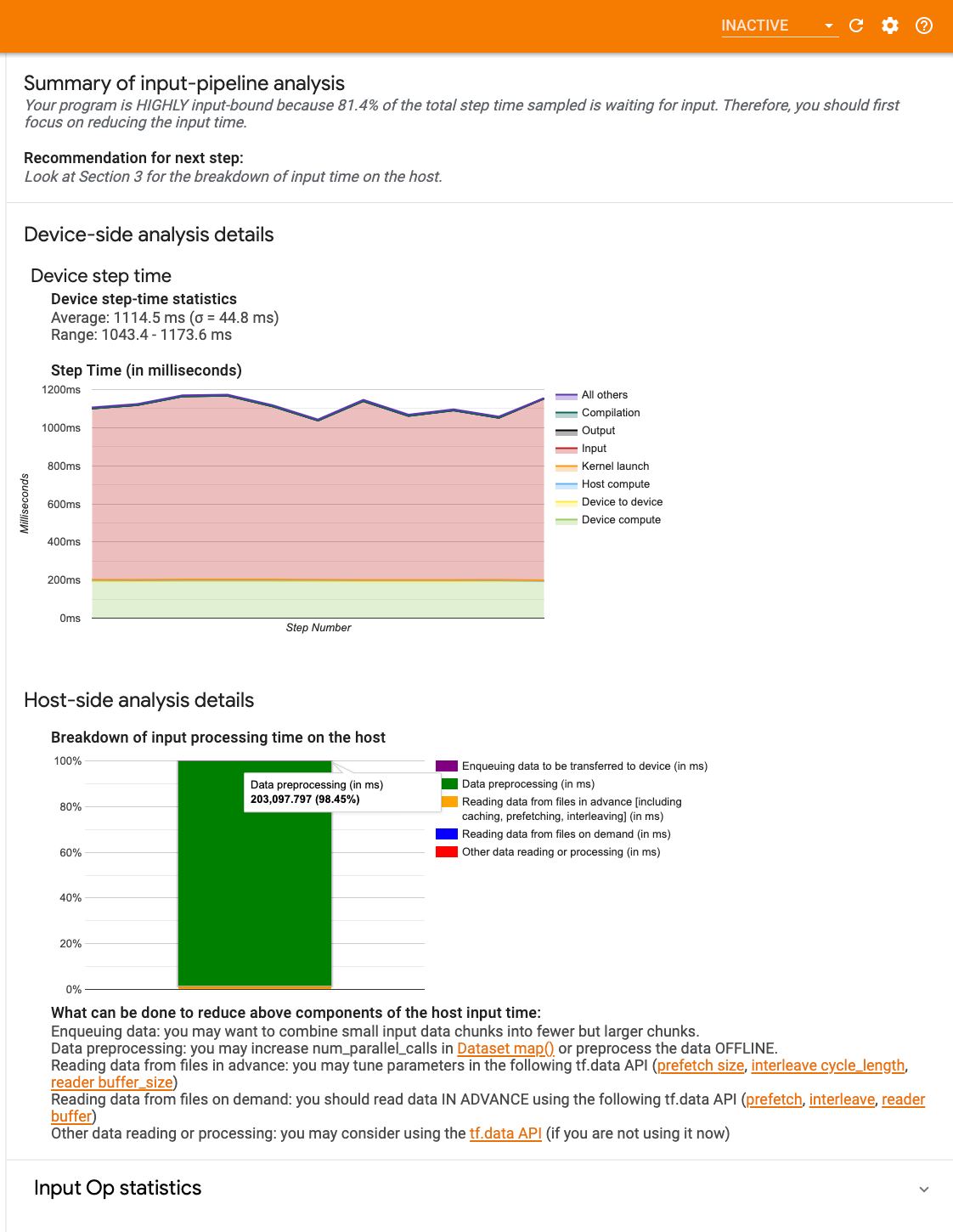
O painel contém três seções:
- Resumo : resume o pipeline de entrada geral com informações sobre se seu aplicativo está vinculado à entrada e, em caso afirmativo, por quanto.
- Análise do lado do dispositivo : exibe resultados detalhados da análise do lado do dispositivo, incluindo o tempo de etapa do dispositivo e o intervalo de tempo gasto pelo dispositivo aguardando dados de entrada nos núcleos em cada etapa.
- Análise do lado do host : mostra uma análise detalhada do lado do host, incluindo um detalhamento do tempo de processamento de entrada no host.
Resumo do pipeline de entrada
O Resumo informa se o seu programa está vinculado à entrada, apresentando a porcentagem de tempo do dispositivo gasto aguardando a entrada do host. Se você estiver usando um pipeline de entrada padrão que foi instrumentado, a ferramenta informará onde é gasto a maior parte do tempo de processamento de entrada.
Análise do lado do dispositivo
A análise do lado do dispositivo fornece insights sobre o tempo gasto no dispositivo versus no host e quanto tempo o dispositivo foi gasto aguardando dados de entrada do host.
- Tempo da etapa plotado em relação ao número da etapa : Exibe um gráfico do tempo da etapa do dispositivo (em milissegundos) em todas as etapas amostradas. Cada etapa é dividida em múltiplas categorias (com cores diferentes) de onde o tempo é gasto. A área vermelha corresponde à parte do tempo em que os dispositivos ficaram ociosos aguardando dados de entrada do host. A área verde mostra quanto tempo o dispositivo realmente funcionou.
- Estatísticas de tempo de passo : relata a média, o desvio padrão e o intervalo ([mínimo, máximo]) do tempo de passo do dispositivo.
Análise do lado do host
A análise do lado do host relata um detalhamento do tempo de processamento de entrada (o tempo gasto nas operações da API tf.data ) no host em várias categorias:
- Leitura de dados de arquivos sob demanda : tempo gasto na leitura de dados de arquivos sem armazenamento em cache, pré-busca e intercalação.
- Lendo dados de arquivos antecipadamente : tempo gasto na leitura de arquivos, incluindo armazenamento em cache, pré-busca e intercalação.
- Pré-processamento de dados : tempo gasto em operações de pré-processamento, como descompactação de imagens.
- Enfileirando dados a serem transferidos para o dispositivo : Tempo gasto colocando dados em uma fila de alimentação antes de transferi-los para o dispositivo.
Expanda Estatísticas de operações de entrada para inspecionar as estatísticas de operações de entrada individuais e suas categorias divididas por tempo de execução.
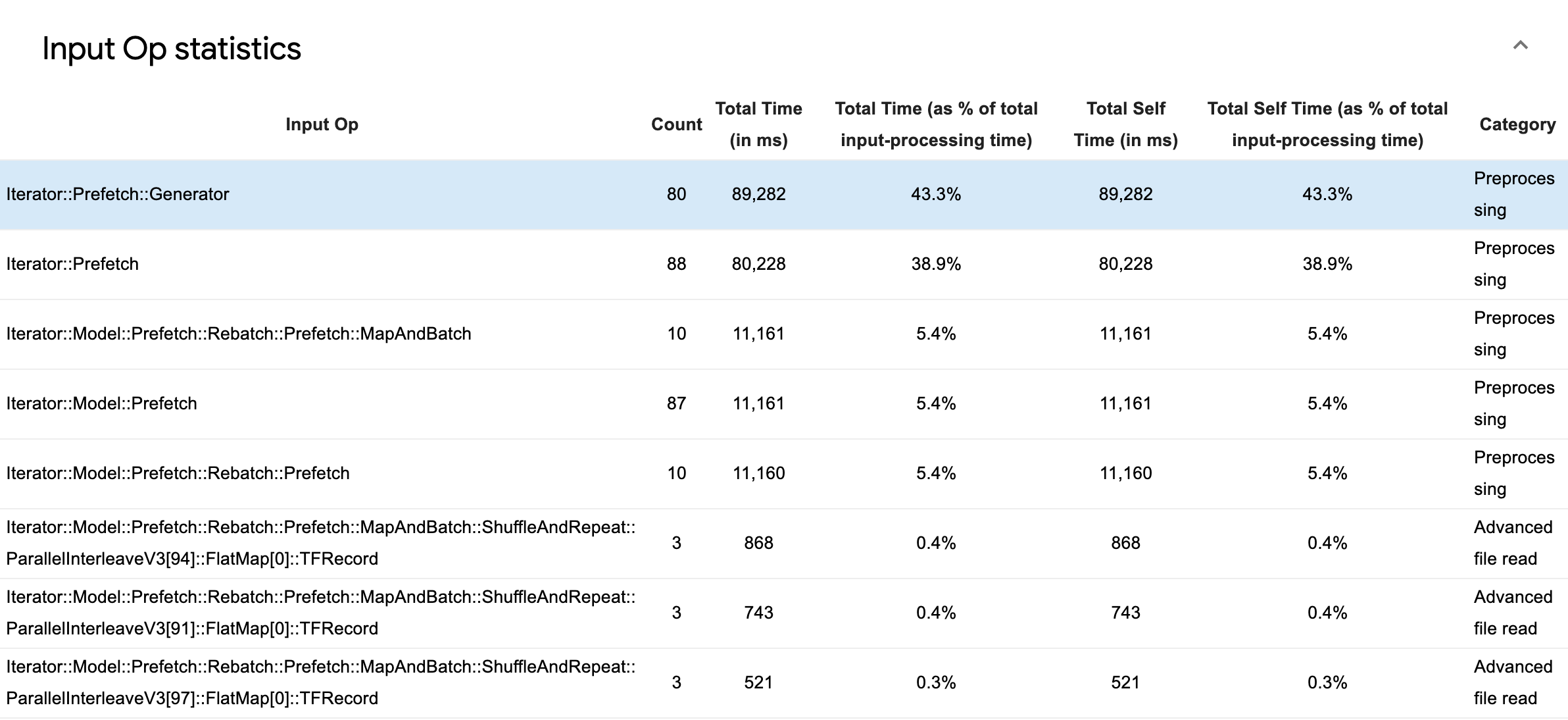
Uma tabela de dados de origem aparecerá com cada entrada contendo as seguintes informações:
- Op de entrada : mostra o nome da operação do TensorFlow da operação de entrada.
- Contagem : mostra o número total de instâncias de execução operacional durante o período de criação de perfil.
- Tempo total (em ms) : mostra a soma cumulativa do tempo gasto em cada uma dessas instâncias.
- % de tempo total : mostra o tempo total gasto em uma operação como uma fração do tempo total gasto no processamento de entrada.
- Tempo próprio total (em ms) : mostra a soma cumulativa do tempo próprio gasto em cada uma dessas instâncias. O tempo próprio aqui mede o tempo gasto dentro do corpo da função, excluindo o tempo gasto na função que ele chama.
- % de tempo próprio total . Mostra o tempo total próprio como uma fração do tempo total gasto no processamento de entrada.
- Categoria . Mostra a categoria de processamento da operação de entrada.
Estatísticas do TensorFlow
A ferramenta TensorFlow Stats exibe o desempenho de cada operação (op) do TensorFlow executada no host ou dispositivo durante uma sessão de criação de perfil.
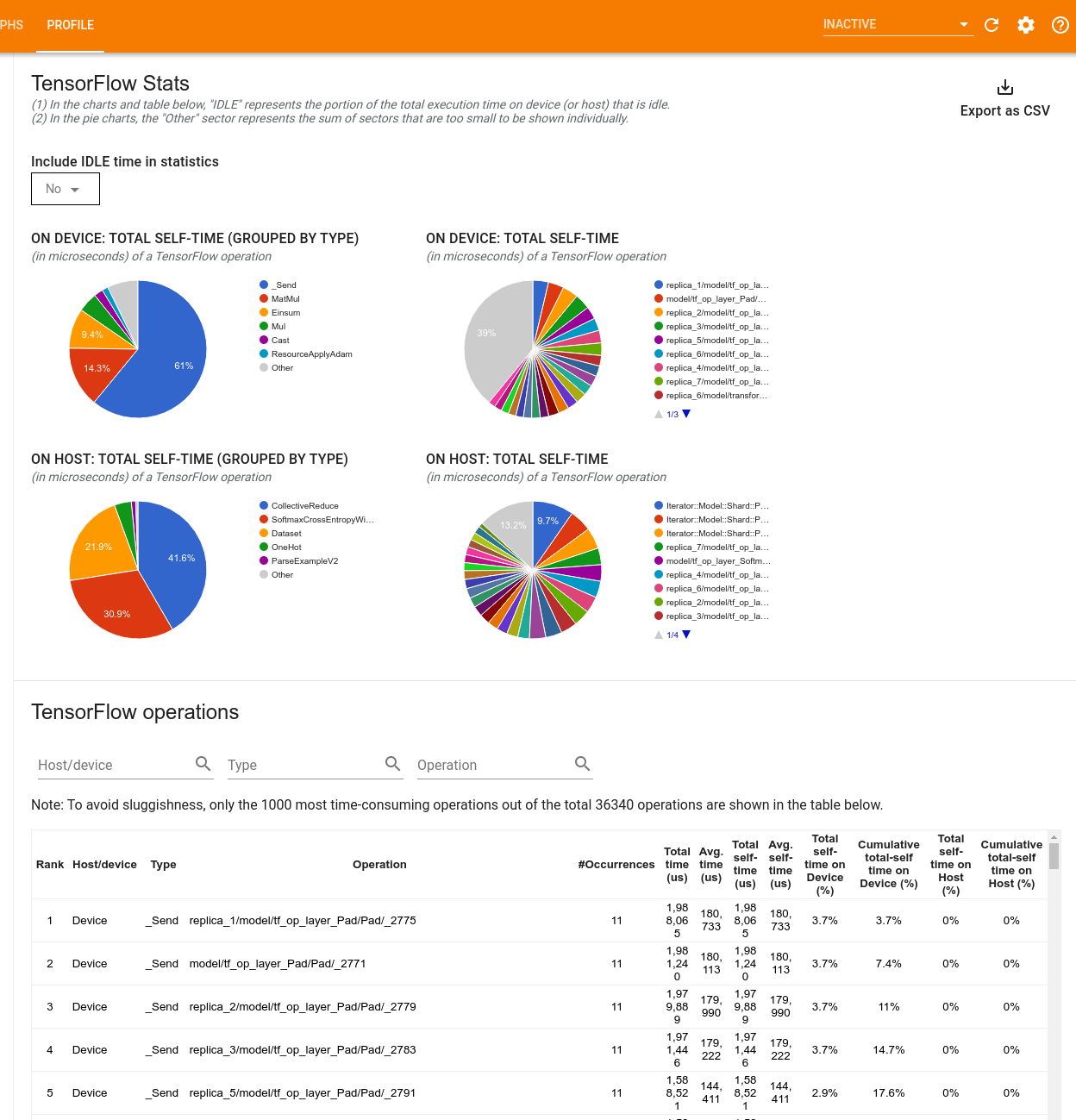
A ferramenta exibe informações de desempenho em dois painéis:
O painel superior exibe até quatro gráficos de pizza:
- A distribuição do tempo de autoexecução de cada operação no host.
- A distribuição do tempo de autoexecução de cada tipo de operação no host.
- A distribuição do tempo de autoexecução de cada operação no dispositivo.
- A distribuição do tempo de autoexecução de cada tipo de operação no dispositivo.
O painel inferior mostra uma tabela que relata dados sobre operações do TensorFlow com uma linha para cada operação e uma coluna para cada tipo de dados (classifique as colunas clicando no cabeçalho da coluna). Clique no botão Exportar como CSV no lado direito do painel superior para exportar os dados desta tabela como um arquivo CSV.
Observe que:
Se alguma operação tiver operações filhas:
- O tempo total “acumulado” de uma operação inclui o tempo gasto nas operações secundárias.
- O tempo "próprio" total de uma operação não inclui o tempo gasto nas operações secundárias.
Se uma operação for executada no host:
- A porcentagem do tempo total no dispositivo incorrido pela operação será 0.
- A porcentagem acumulada do tempo próprio total no dispositivo até esta operação inclusive será 0.
Se uma operação for executada no dispositivo:
- A porcentagem do tempo total no host incorrido por esta operação será 0.
- A porcentagem cumulativa do tempo total no host até esta operação inclusive será 0.
Você pode optar por incluir ou excluir o tempo ocioso nos gráficos de pizza e na tabela.
Visualizador de rastreamento
O visualizador de rastreamento exibe uma linha do tempo que mostra:
- Durações das operações executadas pelo seu modelo do TensorFlow
- Qual parte do sistema (host ou dispositivo) executou uma operação. Normalmente, o host executa operações de entrada, pré-processa os dados de treinamento e os transfere para o dispositivo, enquanto o dispositivo executa o treinamento do modelo real.
O visualizador de rastreamento permite identificar problemas de desempenho em seu modelo e, em seguida, tomar medidas para resolvê-los. Por exemplo, em alto nível, você pode identificar se o treinamento de entrada ou de modelo está demorando a maior parte do tempo. Aprofundando, você pode identificar quais operações demoram mais para serem executadas. Observe que o visualizador de rastreamento está limitado a 1 milhão de eventos por dispositivo.
Interface do visualizador de rastreamento
Quando você abre o visualizador de rastreamento, ele aparece exibindo sua execução mais recente:
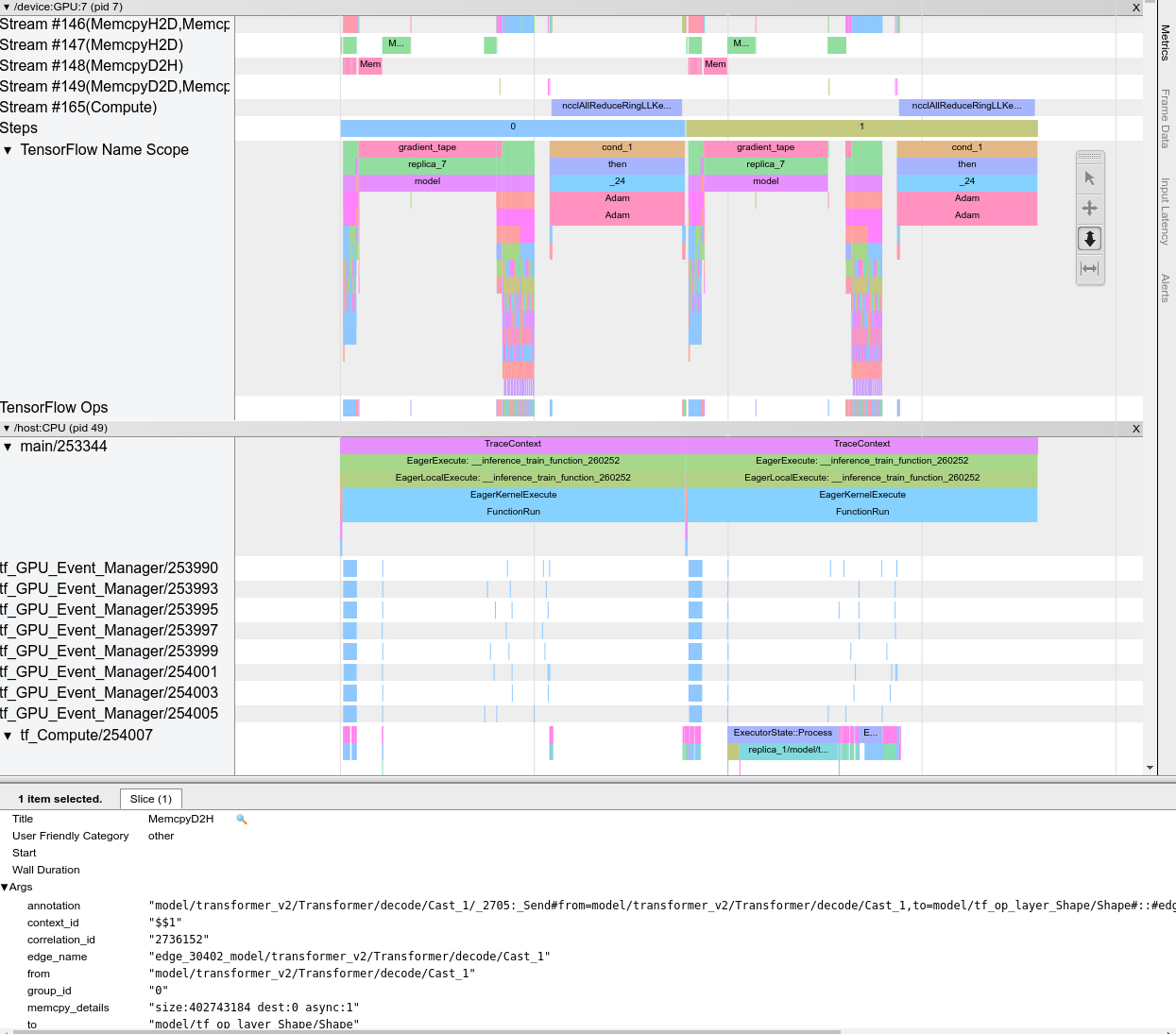
Esta tela contém os seguintes elementos principais:
- Painel Linha do tempo : mostra as operações que o dispositivo e o host executaram ao longo do tempo.
- Painel de detalhes : mostra informações adicionais para operações selecionadas no painel Linha do tempo.
O painel Linha do tempo contém os seguintes elementos:
- Barra superior : Contém vários controles auxiliares.
- Eixo do tempo : Mostra o tempo relativo ao início do traçado.
- Rótulos de seções e faixas : cada seção contém várias faixas e possui um triângulo à esquerda no qual você pode clicar para expandir e recolher a seção. Existe uma seção para cada elemento de processamento do sistema.
- Seletor de ferramentas : Contém várias ferramentas para interagir com o visualizador de traços, como Zoom, Pan, Selecionar e Tempo. Use a ferramenta Tempo para marcar um intervalo de tempo.
- Eventos : mostram o tempo durante o qual uma operação foi executada ou a duração dos metaeventos, como etapas de treinamento.
Seções e faixas
O visualizador de rastreamento contém as seguintes seções:
- Uma seção para cada nó do dispositivo , rotulada com o número do chip do dispositivo e o nó do dispositivo dentro do chip (por exemplo,
/device:GPU:0 (pid 0)). Cada seção do nó do dispositivo contém as seguintes faixas:- Etapa : mostra a duração das etapas de treinamento que estavam sendo executadas no dispositivo
- TensorFlow Ops : mostra as operações executadas no dispositivo
- Operações XLA : mostra operações (ops) XLA executadas no dispositivo se XLA for o compilador usado (cada operação do TensorFlow é traduzida em uma ou várias operações XLA. O compilador XLA traduz as operações XLA em código que é executado no dispositivo).
- Uma seção para threads em execução na CPU da máquina host, chamada "Host Threads" . A seção contém uma trilha para cada thread da CPU. Observe que você pode ignorar as informações exibidas ao lado dos rótulos das seções.
Eventos
Os eventos na linha do tempo são exibidos em cores diferentes; as cores em si não têm significado específico.
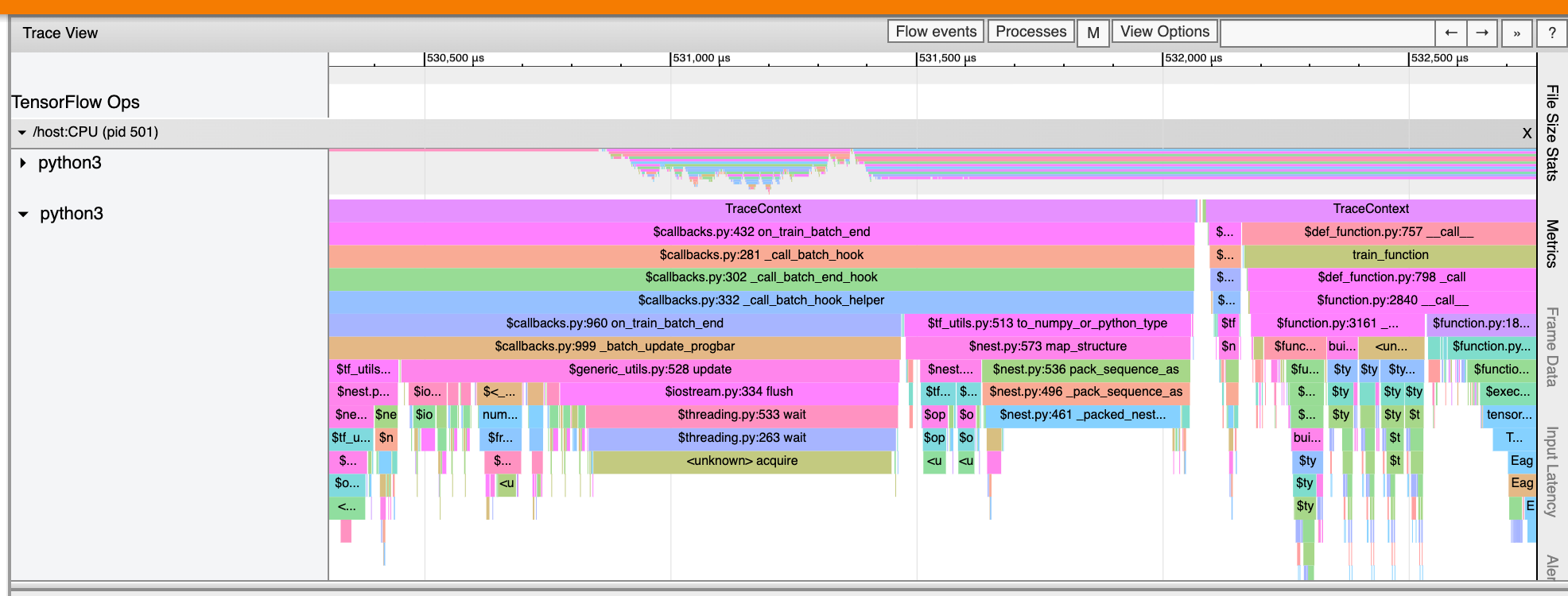
O visualizador de rastreamento também pode exibir rastreamentos de chamadas de função Python em seu programa TensorFlow. Se você usar a API tf.profiler.experimental.start , poderá ativar o rastreamento do Python usando ProfilerOptions nomeadotuple ao iniciar a criação de perfil. Como alternativa, se você usar o modo de amostragem para criação de perfil, poderá selecionar o nível de rastreamento usando as opções suspensas na caixa de diálogo Capturar perfil .
Estatísticas do kernel da GPU
Esta ferramenta mostra estatísticas de desempenho e a operação de origem para cada kernel acelerado por GPU.
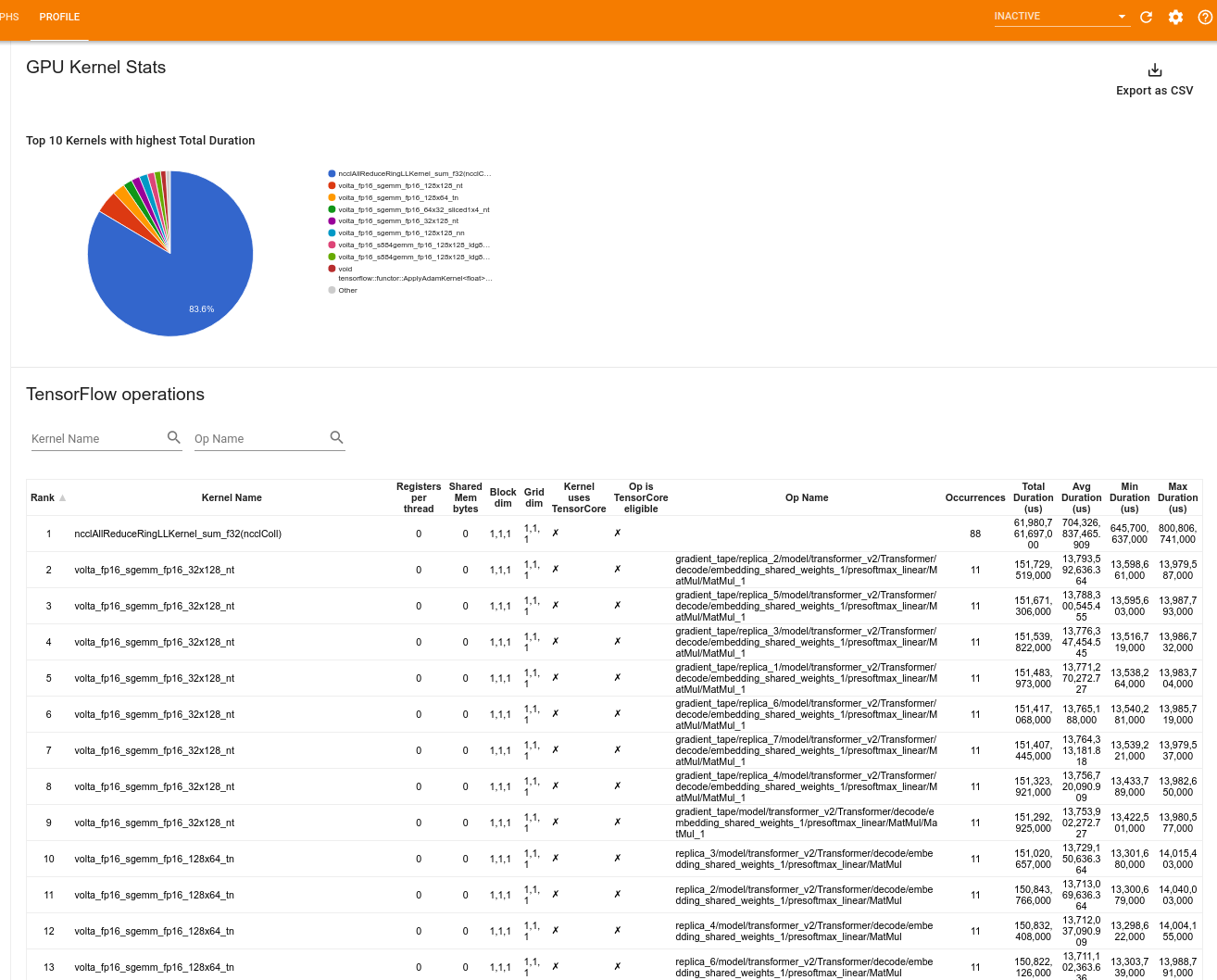
A ferramenta exibe informações em dois painéis:
O painel superior exibe um gráfico de pizza que mostra os kernels CUDA que têm o maior tempo total decorrido.
O painel inferior exibe uma tabela com os seguintes dados para cada par kernel-op exclusivo:
- Uma classificação em ordem decrescente da duração total decorrida da GPU agrupada por par de operações do kernel.
- O nome do kernel iniciado.
- O número de registros de GPU usados pelo kernel.
- O tamanho total da memória compartilhada (estática + dinâmica compartilhada) usada em bytes.
- A dimensão do bloco expressa como
blockDim.x, blockDim.y, blockDim.z. - As dimensões da grade expressas como
gridDim.x, gridDim.y, gridDim.z. - Se a operação é elegível para usar Tensor Cores .
- Se o kernel contém instruções do Tensor Core.
- O nome da operação que lançou este kernel.
- O número de ocorrências deste par kernel-op.
- O tempo total decorrido da GPU em microssegundos.
- O tempo médio decorrido da GPU em microssegundos.
- O tempo mínimo decorrido da GPU em microssegundos.
- O tempo máximo decorrido da GPU em microssegundos.
Ferramenta de perfil de memória
A ferramenta Memory Profile monitora o uso de memória do seu dispositivo durante o intervalo de criação de perfil. Você pode usar esta ferramenta para:
- Depure problemas de falta de memória (OOM), identificando o pico de uso de memória e a alocação de memória correspondente para operações do TensorFlow. Você também pode depurar problemas de OOM que podem surgir ao executar a inferência de multilocação .
- Depure problemas de fragmentação de memória.
A ferramenta de perfil de memória exibe dados em três seções:
- Resumo do perfil de memória
- Gráfico da linha do tempo da memória
- Tabela de divisão de memória
Resumo do perfil de memória
Esta seção exibe um resumo de alto nível do perfil de memória do seu programa TensorFlow, conforme mostrado abaixo:
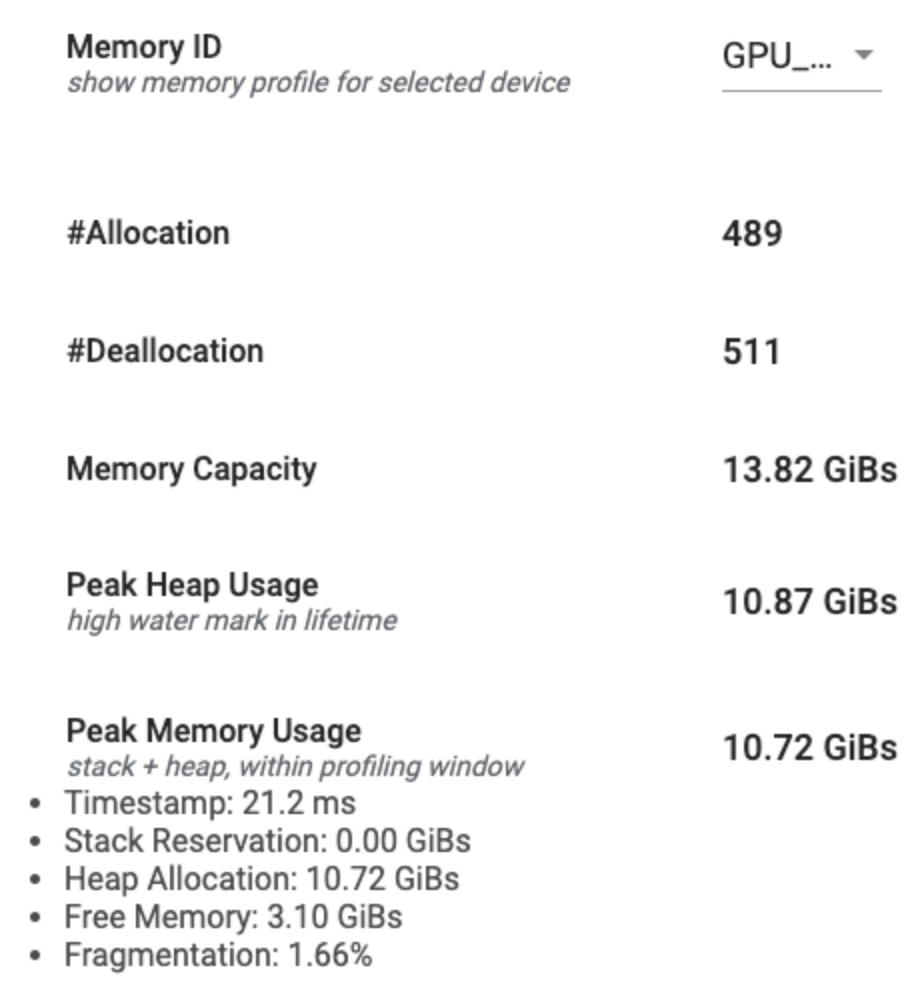
O resumo do perfil de memória possui seis campos:
- ID de memória : lista suspensa que lista todos os sistemas de memória de dispositivos disponíveis. Selecione o sistema de memória que deseja visualizar no menu suspenso.
- #Allocation : o número de alocações de memória feitas durante o intervalo de criação de perfil.
- #Deallocation : o número de desalocações de memória no intervalo de criação de perfil
- Capacidade de memória : a capacidade total (em GiBs) do sistema de memória selecionado.
- Uso máximo de heap : o uso máximo de memória (em GiBs) desde que o modelo começou a ser executado.
- Uso máximo de memória : o uso máximo de memória (em GiBs) no intervalo de criação de perfil. Este campo contém os seguintes subcampos:
- Timestamp : o carimbo de data/hora de quando ocorreu o pico de uso de memória no gráfico da linha do tempo.
- Reserva de pilha : quantidade de memória reservada na pilha (em GiBs).
- Alocação de heap : Quantidade de memória alocada no heap (em GiBs).
- Memória Livre : Quantidade de memória livre (em GiBs). A capacidade de memória é a soma total da reserva de pilha, alocação de heap e memória livre.
- Fragmentação : A porcentagem de fragmentação (quanto menor, melhor). É calculado como uma porcentagem de
(1 - Size of the largest chunk of free memory / Total free memory).
Gráfico da linha do tempo da memória
Esta seção exibe um gráfico do uso de memória (em GiBs) e a porcentagem de fragmentação versus tempo (em ms).
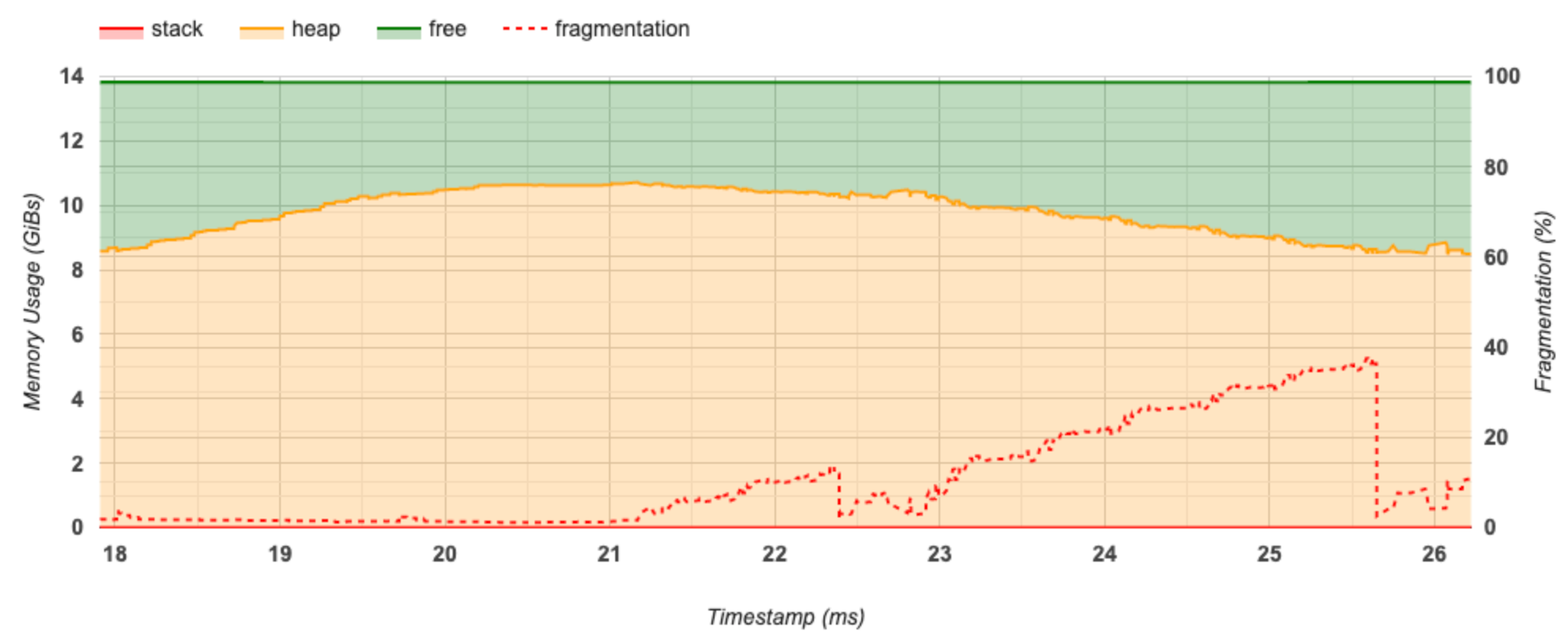
O eixo X representa a linha do tempo (em ms) do intervalo de criação de perfil. O eixo Y à esquerda representa o uso de memória (em GiBs) e o eixo Y à direita representa a porcentagem de fragmentação. Em cada momento no eixo X, a memória total é dividida em três categorias: pilha (em vermelho), heap (em laranja) e livre (em verde). Passe o mouse sobre um carimbo de data/hora específico para visualizar os detalhes sobre os eventos de alocação/desalocação de memória naquele ponto, como abaixo:
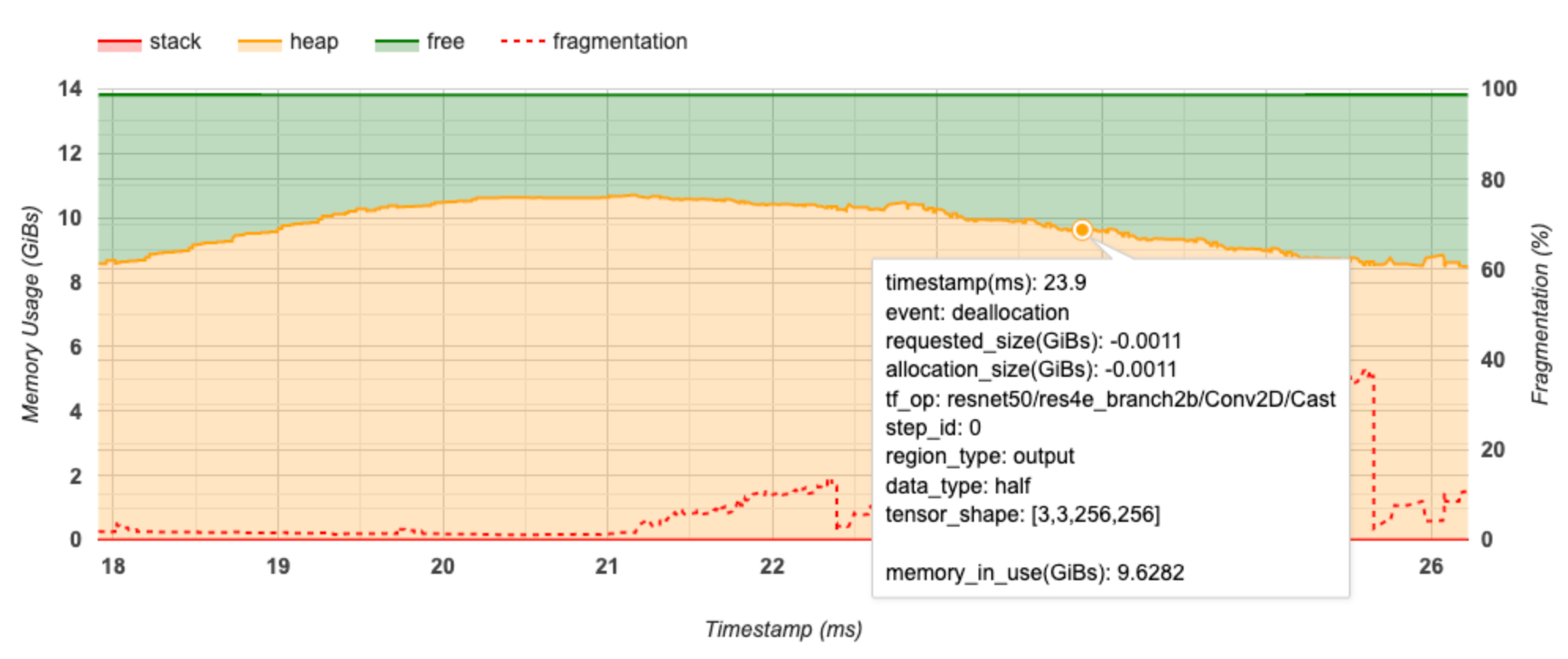
A janela pop-up exibe as seguintes informações:
- timestamp(ms) : A localização do evento selecionado na linha do tempo.
- event : O tipo de evento (alocação ou desalocação).
- request_size(GiBs) : A quantidade de memória solicitada. Este será um número negativo para eventos de desalocação.
- alocação_size(GiBs) : A quantidade real de memória alocada. Este será um número negativo para eventos de desalocação.
- tf_op : a operação do TensorFlow que solicita a alocação/desalocação.
- step_id : a etapa de treinamento em que esse evento ocorreu.
- region_type : O tipo de entidade de dados para o qual se destina esta memória alocada. Os valores possíveis são
temppara temporários,outputpara ativações e gradientes epersist/dynamicpara pesos e constantes. - data_type : O tipo de elemento tensor (por exemplo, uint8 para inteiro não assinado de 8 bits).
- tensor_shape : A forma do tensor que está sendo alocado/desalocado.
- memory_in_use(GiBs) : A memória total que está em uso neste momento.
Tabela de detalhamento de memória
Esta tabela mostra as alocações de memória ativa no ponto de pico de uso de memória no intervalo de criação de perfil.
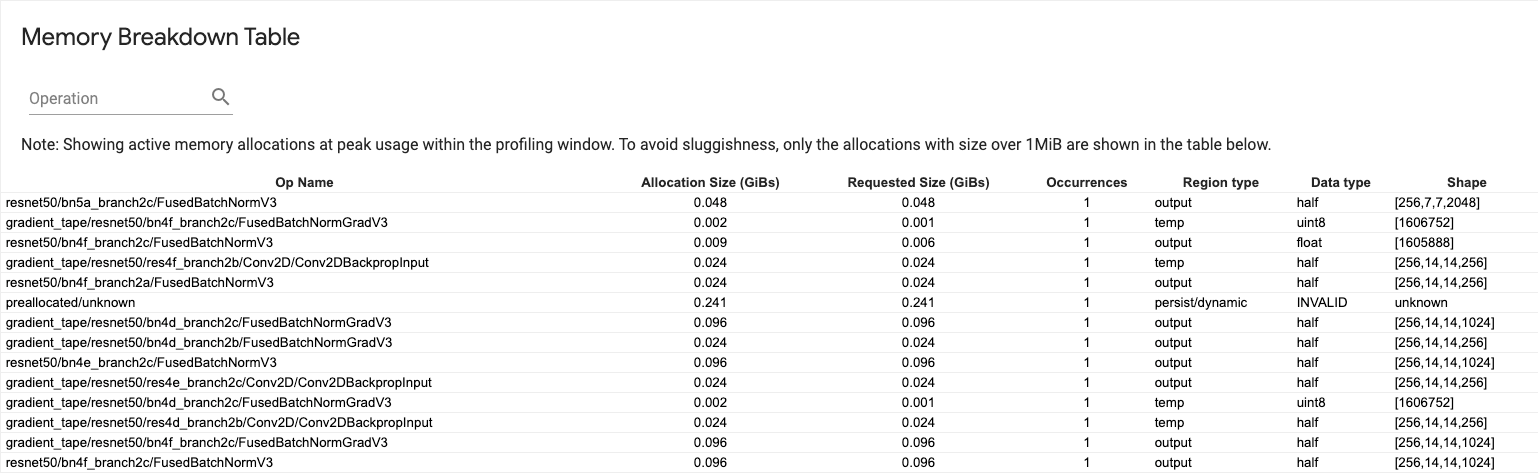
Há uma linha para cada TensorFlow Op e cada linha tem as seguintes colunas:
- Nome da operação : o nome da operação do TensorFlow.
- Allocation Size (GiBs) : A quantidade total de memória alocada para esta operação.
- Tamanho solicitado (GiBs) : a quantidade total de memória solicitada para esta operação.
- Ocorrências : o número de alocações para esta operação.
- Tipo de região : o tipo de entidade de dados ao qual se destina esta memória alocada. Os valores possíveis são
temppara temporários,outputpara ativações e gradientes epersist/dynamicpara pesos e constantes. - Tipo de dados : o tipo de elemento tensor.
- Forma : A forma dos tensores alocados.
Visualizador de pods
A ferramenta Pod Viewer mostra o detalhamento de uma etapa de treinamento para todos os trabalhadores.
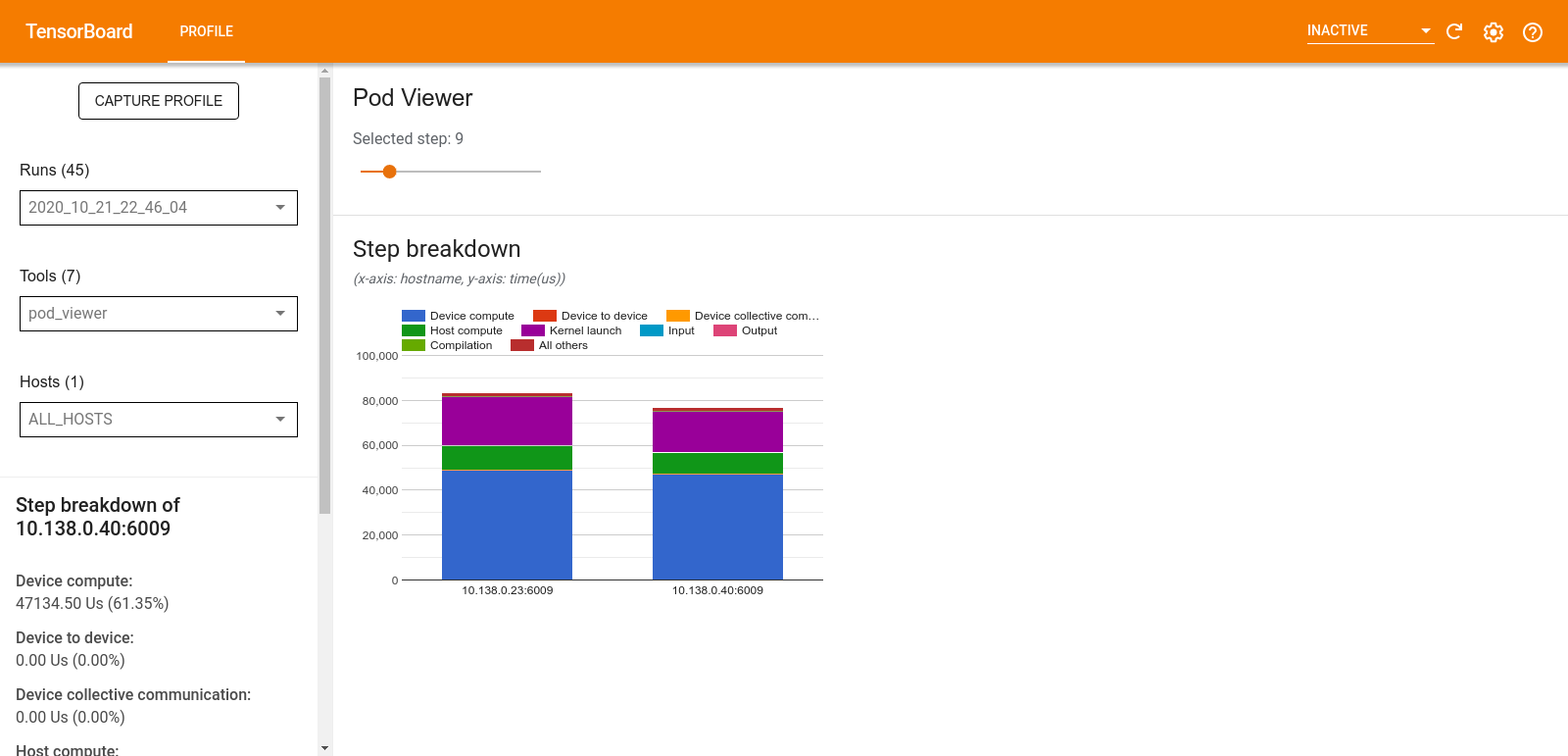
- O painel superior possui um controle deslizante para selecionar o número da etapa.
- O painel inferior exibe um gráfico de colunas empilhadas. Esta é uma visão de alto nível de categorias de tempo de passo divididas, colocadas umas sobre as outras. Cada coluna empilhada representa um trabalhador exclusivo.
- Quando você passa o mouse sobre uma coluna empilhada, o cartão à esquerda mostra mais detalhes sobre o detalhamento das etapas.
análise de gargalo tf.data
A ferramenta de análise de gargalos tf.data detecta automaticamente gargalos nos pipelines de entrada tf.data em seu programa e fornece recomendações sobre como corrigi-los. Funciona com qualquer programa usando tf.data independentemente da plataforma (CPU/GPU/TPU). A sua análise e recomendações baseiam-se neste guia .
Ele detecta um gargalo seguindo estas etapas:
- Encontre o host com maior limite de entrada.
- Encontre a execução mais lenta de um pipeline de entrada
tf.data. - Reconstrua o gráfico do pipeline de entrada a partir do rastreamento do criador de perfil.
- Encontre o caminho crítico no gráfico do pipeline de entrada.
- Identifique a transformação mais lenta no caminho crítico como um gargalo.
A IU é dividida em três seções: Resumo da análise de desempenho , Resumo de todos os pipelines de entrada e Gráfico do pipeline de entrada .
Resumo da análise de desempenho

Esta seção fornece o resumo da análise. Ele relata pipelines de entrada tf.data lentos detectados no perfil. Esta seção também mostra o host com maior limite de entrada e seu pipeline de entrada mais lento com a latência máxima. Mais importante ainda, identifica qual parte do pipeline de entrada é o gargalo e como corrigi-lo. As informações de gargalo são fornecidas com o tipo de iterador e seu nome longo.
Como ler o nome longo do iterador tf.data
Um nome longo é formatado como Iterator::<Dataset_1>::...::<Dataset_n> . No nome longo, <Dataset_n> corresponde ao tipo de iterador e os outros conjuntos de dados no nome longo representam transformações downstream.
Por exemplo, considere o seguinte conjunto de dados de pipeline de entrada:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
Os nomes longos dos iteradores do conjunto de dados acima serão:
| Tipo de iterador | Nome longo |
|---|---|
| Faixa | Iterador::Batch::Repeat::Map::Range |
| Mapa | Iterador::Lote::Repetir::Mapa |
| Repita | Iterador::Lote::Repetir |
| Lote | Iterador::Lote |
Resumo de todos os pipelines de entrada
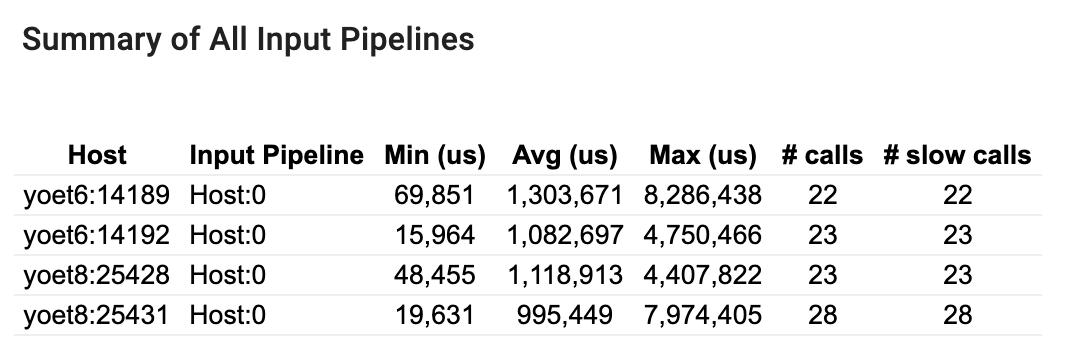
Esta seção fornece o resumo de todos os pipelines de entrada em todos os hosts. Normalmente há um pipeline de entrada. Ao usar a estratégia de distribuição, há um pipeline de entrada de host executando o código tf.data do programa e vários pipelines de entrada de dispositivo recuperando dados do pipeline de entrada de host e transferindo-os para os dispositivos.
Para cada pipeline de entrada, mostra as estatísticas de seu tempo de execução. Uma chamada é considerada lenta se demorar mais de 50 μs.
Gráfico de pipeline de entrada

Esta seção mostra o gráfico do pipeline de entrada com as informações do tempo de execução. Você pode usar "Host" e "Pipeline de entrada" para escolher qual host e pipeline de entrada ver. As execuções do pipeline de entrada são classificadas pelo tempo de execução em ordem decrescente, que você pode escolher usando o menu suspenso Classificação .
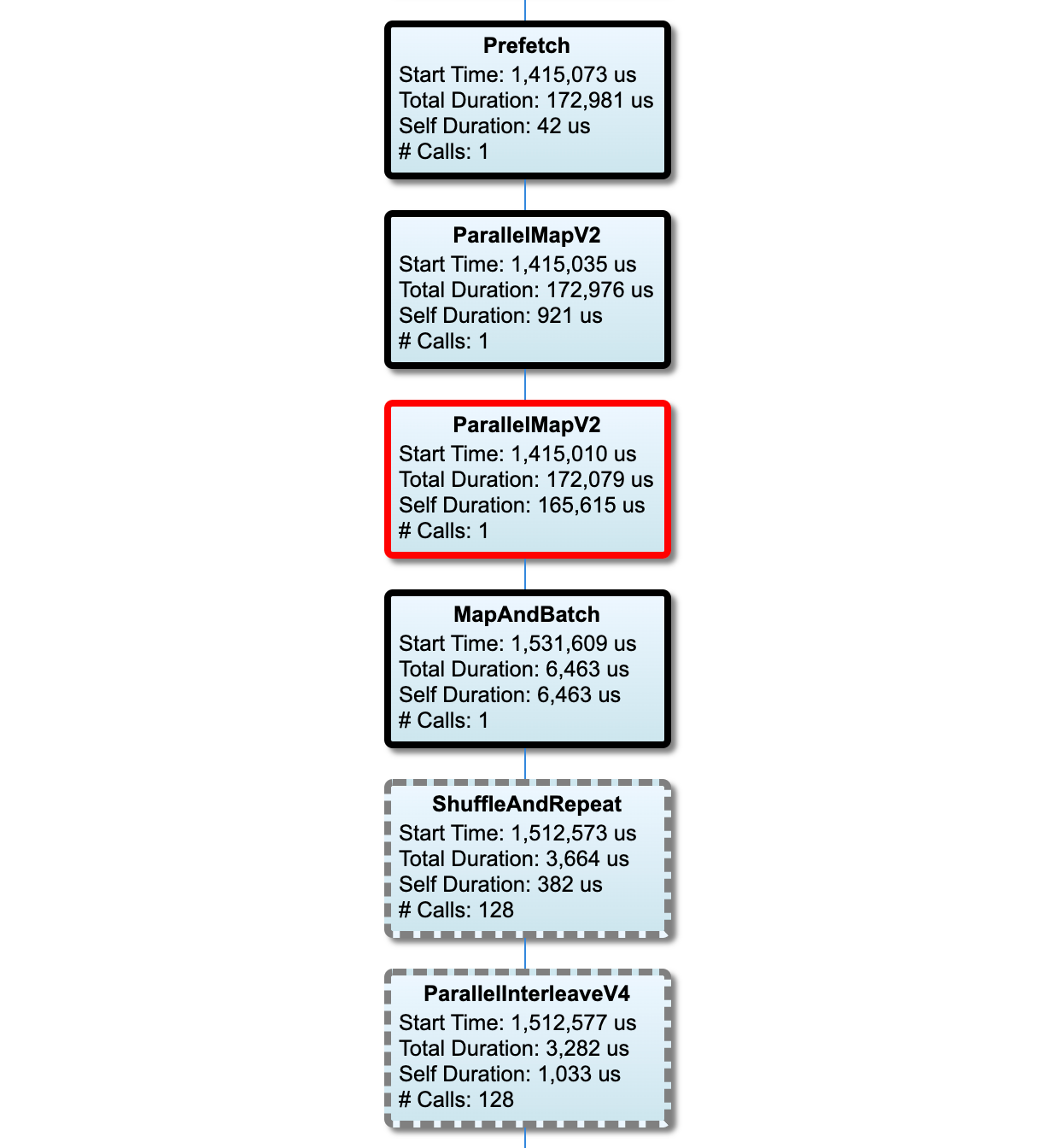
Os nós no caminho crítico têm contornos em negrito. O nó gargalo, que é o nó com o maior tempo próprio no caminho crítico, possui um contorno vermelho. Os outros nós não críticos têm contornos tracejados em cinza.
Em cada nó, Start Time indica a hora de início da execução. O mesmo nó pode ser executado várias vezes, por exemplo, se houver uma operação em Batch no pipeline de entrada. Se for executado várias vezes, será a hora de início da primeira execução.
A Duração Total é o tempo de parede da execução. Se for executado várias vezes, será a soma dos tempos de parede de todas as execuções.
O tempo próprio é o tempo total sem o tempo sobreposto com seus nós filhos imediatos.
"# Calls" é o número de vezes que o pipeline de entrada é executado.
Colete dados de desempenho
O TensorFlow Profiler coleta atividades de host e rastreamentos de GPU do seu modelo do TensorFlow. Você pode configurar o Profiler para coletar dados de desempenho por meio do modo programático ou do modo de amostragem.
Criação de perfil de APIs
Você pode usar as APIs a seguir para realizar a criação de perfil.
Modo programático usando o retorno de chamada TensorBoard Keras (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Modo programático usando a API de função
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Modo programático usando o gerenciador de contexto
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Modo de amostragem: execute a criação de perfil sob demanda usando
tf.profiler.experimental.server.startpara iniciar um servidor gRPC com a execução do modelo do TensorFlow. Depois de iniciar o servidor gRPC e executar seu modelo, você pode capturar um perfil por meio do botão Capture Profile no plugin de perfil TensorBoard. Use o script na seção Instalar profiler acima para iniciar uma instância do TensorBoard se ela ainda não estiver em execução.Como um exemplo,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Um exemplo de criação de perfil de vários trabalhadores:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
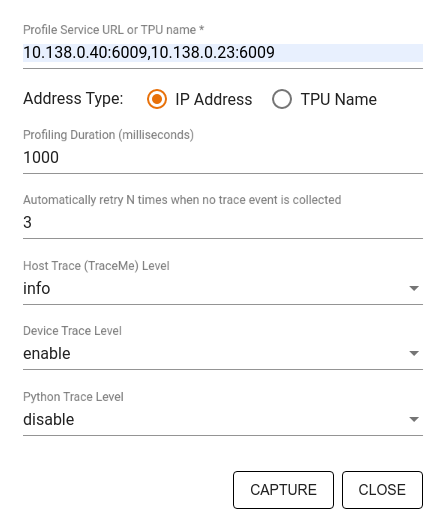
Use a caixa de diálogo Capturar perfil para especificar:
- Uma lista delimitada por vírgulas de URLs de serviço de perfil ou nomes de TPU.
- Uma duração de perfil.
- O nível de rastreamento de chamada de dispositivo, host e função Python.
- Quantas vezes você deseja que o Profiler tente capturar perfis novamente se não tiver êxito inicialmente.
Criação de perfil de loops de treinamento personalizados
Para criar o perfil de loops de treinamento personalizados em seu código do TensorFlow, instrumente o loop de treinamento com a API tf.profiler.experimental.Trace para marcar os limites das etapas do Profiler.
O argumento name é usado como um prefixo para os nomes das etapas, o argumento da palavra-chave step_num é anexado aos nomes das etapas e o argumento da palavra-chave _r faz com que esse evento de rastreamento seja processado como um evento de etapa pelo Profiler.
Como um exemplo,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Isso permitirá a análise de desempenho baseada em etapas do Profiler e fará com que os eventos de etapas apareçam no visualizador de rastreamento.
Certifique-se de incluir o iterador do conjunto de dados no contexto tf.profiler.experimental.Trace para uma análise precisa do pipeline de entrada.
O trecho de código abaixo é um antipadrão:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Criação de perfil de casos de uso
O criador de perfil cobre vários casos de uso em quatro eixos diferentes. Algumas das combinações são atualmente suportadas e outras serão adicionadas no futuro. Alguns dos casos de uso são:
- Criação de perfil local versus remota : essas são duas maneiras comuns de configurar seu ambiente de criação de perfil. Na criação de perfil local, a API de criação de perfil é chamada na mesma máquina que seu modelo está executando, por exemplo, uma estação de trabalho local com GPUs. Na criação de perfil remoto, a API de criação de perfil é chamada em uma máquina diferente daquela em que seu modelo está sendo executado, por exemplo, em um Cloud TPU.
- Criação de perfil de vários trabalhadores : você pode criar perfil de várias máquinas ao usar os recursos de treinamento distribuído do TensorFlow.
- Plataforma de hardware : perfil de CPUs, GPUs e TPUs.
A tabela abaixo fornece uma visão geral rápida dos casos de uso compatíveis com TensorFlow mencionados acima:
| API de perfil | Local | Controlo remoto | Vários trabalhadores | Plataformas de hardware |
|---|---|---|---|---|
| Retorno de chamada do TensorBoard Keras | Suportado | Não suportado | Não suportado | CPU, GPU |
API de início/parada tf.profiler.experimental | Suportado | Não suportado | Não suportado | CPU, GPU |
API tf.profiler.experimental client.trace | Suportado | Suportado | Suportado | CPU, GPU, TPU |
| API do gerenciador de contexto | Suportado | Não suportado | Não suportado | CPU, GPU |
Melhores práticas para desempenho ideal do modelo
Use as recomendações a seguir, conforme aplicável aos seus modelos do TensorFlow, para obter o desempenho ideal.
Em geral, execute todas as transformações no dispositivo e certifique-se de usar a versão compatível mais recente de bibliotecas como cuDNN e Intel MKL para sua plataforma.
Otimize o pipeline de dados de entrada
Use os dados do [#input_pipeline_analyzer] para otimizar seu pipeline de entrada de dados. Um pipeline de entrada de dados eficiente pode melhorar drasticamente a velocidade de execução do seu modelo, reduzindo o tempo ocioso do dispositivo. Tente incorporar as práticas recomendadas detalhadas no guia Melhor desempenho com a API tf.data e abaixo para tornar seu pipeline de entrada de dados mais eficiente.
Em geral, paralelizar quaisquer operações que não precisem ser executadas sequencialmente pode otimizar significativamente o pipeline de entrada de dados.
Em muitos casos, ajuda alterar a ordem de algumas chamadas ou ajustar os argumentos para que funcione melhor para o seu modelo. Ao otimizar o pipeline de dados de entrada, compare apenas o carregador de dados sem as etapas de treinamento e retropropagação para quantificar o efeito das otimizações de forma independente.
Tente executar seu modelo com dados sintéticos para verificar se o pipeline de entrada é um gargalo de desempenho.
Use
tf.data.Dataset.shardpara treinamento multi-GPU. Certifique-se de fragmentar bem no início do loop de entrada para evitar reduções na taxa de transferência. Ao trabalhar com TFRecords, certifique-se de fragmentar a lista de TFRecords e não o conteúdo dos TFRecords.Paralelize várias operações definindo dinamicamente o valor de
num_parallel_callsusandotf.data.AUTOTUNE.Considere limitar o uso de
tf.data.Dataset.from_generator, pois é mais lento em comparação com operações puras do TensorFlow.Considere limitar o uso de
tf.py_function, pois ele não pode ser serializado e não tem suporte para execução no TensorFlow distribuído.Use
tf.data.Optionspara controlar otimizações estáticas no pipeline de entrada.
Leia também o guia de análise de desempenho tf.data para obter mais orientações sobre como otimizar seu pipeline de entrada.
Otimize o aumento de dados
Ao trabalhar com dados de imagem, torne o aumento de dados mais eficiente lançando para diferentes tipos de dados após aplicar transformações espaciais, como inversão, corte, rotação, etc.
Usar NVIDIA® DALI
Em alguns casos, como quando você tem um sistema com uma alta proporção de GPU para CPU, todas as otimizações acima podem não ser suficientes para eliminar gargalos no carregador de dados causados devido a limitações de ciclos de CPU.
Se você estiver usando GPUs NVIDIA® para aplicativos de visão computacional e aprendizado profundo de áudio, considere usar a Biblioteca de Carregamento de Dados ( DALI ) para acelerar o pipeline de dados.
Verifique a documentação NVIDIA® DALI: Operations para obter uma lista de operações DALI suportadas.
Use threading e execução paralela
Execute operações em vários threads de CPU com a API tf.config.threading para executá-los mais rapidamente.
O TensorFlow define automaticamente o número de threads de paralelismo por padrão. O pool de threads disponível para execução de operações do TensorFlow depende do número de threads de CPU disponíveis.
Controle a aceleração paralela máxima para uma única operação usando tf.config.threading.set_intra_op_parallelism_threads . Observe que se você executar várias operações em paralelo, todas elas compartilharão o pool de threads disponível.
Se você tiver operações independentes sem bloqueio (operações sem caminho direcionado entre elas no gráfico), use tf.config.threading.set_inter_op_parallelism_threads para executá-las simultaneamente usando o pool de threads disponível.
Diversos
Ao trabalhar com modelos menores em GPUs NVIDIA®, você pode definir tf.compat.v1.ConfigProto.force_gpu_compatible=True para forçar todos os tensores de CPU a serem alocados com memória fixada CUDA para dar um impulso significativo ao desempenho do modelo. No entanto, tenha cuidado ao usar esta opção para modelos desconhecidos/muito grandes, pois isso pode impactar negativamente o desempenho do host (CPU).
Melhore o desempenho do dispositivo
Siga as práticas recomendadas detalhadas aqui e no guia de otimização de desempenho de GPU para otimizar o desempenho do modelo TensorFlow no dispositivo.
Se você estiver usando GPUs NVIDIA, registre a utilização da GPU e da memória em um arquivo CSV executando:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
Configurar layout de dados
Ao trabalhar com dados que contêm informações do canal (como imagens), otimize o formato do layout dos dados para preferir os canais por último (NHWC em vez de NCHW).
Os formatos de dados do último canal melhoram a utilização do Tensor Core e fornecem melhorias significativas de desempenho, especialmente em modelos convolucionais, quando acoplados ao AMP. Os layouts de dados NCHW ainda podem ser operados por Tensor Cores, mas introduzem sobrecarga adicional devido às operações de transposição automática.
Você pode otimizar o layout de dados para preferir layouts NHWC definindo data_format="channels_last" para camadas como tf.keras.layers.Conv2D , tf.keras.layers.Conv3D e tf.keras.layers.RandomRotation .
Use tf.keras.backend.set_image_data_format para definir o formato de layout de dados padrão para a API de backend Keras.
Maximize o cache L2
Ao trabalhar com GPUs NVIDIA®, execute o snippet de código abaixo antes do loop de treinamento para maximizar a granularidade de busca L2 para 128 bytes.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
Configurar o uso do thread da GPU
O modo de thread de GPU decide como os threads de GPU são usados.
Defina o modo de thread como gpu_private para garantir que o pré-processamento não roube todos os threads da GPU. Isso reduzirá o atraso na inicialização do kernel durante o treinamento. Você também pode definir o número de threads por GPU. Defina esses valores usando variáveis de ambiente.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
Configurar opções de memória da GPU
Em geral, aumente o tamanho do lote e dimensione o modelo para utilizar melhor as GPUs e obter maior taxa de transferência. Observe que o aumento do tamanho do lote alterará a precisão do modelo, para que o modelo precise ser escalado ajustando os hiperparâmetros, como a taxa de aprendizado para atender à precisão do alvo.
Além disso, use tf.config.experimental.set_memory_growth para permitir que a memória da GPU cresça para impedir que toda a memória disponível seja totalmente alocada para operações que requerem apenas uma fração da memória. Isso permite que outros processos que consomem memória GPU são executados no mesmo dispositivo.
Para saber mais, consulte a orientação limitadora de crescimento da memória da GPU no guia da GPU para saber mais.
Diversos
Aumente o tamanho do mini-lote de treinamento (número de amostras de treinamento utilizadas por dispositivo em uma iteração do loop de treinamento) à quantidade máxima que se encaixa sem um erro fora da memória (OOM) na GPU. Aumentar o tamanho do lote afeta a precisão do modelo - e certifique -se de escalar o modelo ajustando os hiperparâmetros para atender à precisão do alvo.
Desative os erros de OOM de relatórios durante a alocação do tensor no código de produção. Definir
report_tensor_allocations_upon_oom=Falseemtf.compat.v1.RunOptions.Para modelos com camadas de convolução, remova a adição de viés se estiver usando normalização em lote. A normalização do lote muda os valores por sua média e isso remove a necessidade de ter um termo de viés constante.
Use as estatísticas do TF para descobrir a execução do OPS de dispositivo eficientemente.
Use
tf.functionpara executar cálculos e, opcionalmente, habilite ojit_compile=TrueFLAG (tf.function(jit_compile=True). Para saber mais, vá usar o XLA TF.Function .Minimize as operações do Host Python entre as etapas e reduza os retornos de chamada. Calcule métricas a cada poucas etapas, em vez de em todas as etapas.
Mantenha as unidades de computação do dispositivo ocupadas.
Envie dados para vários dispositivos em paralelo.
Considere o uso de representações numéricas de 16 bits , como
fp16-o formato de ponto flutuante de meia precisão especificado por IEEE-ou o formato BFLOAT16 de ponto flutuante do cérebro.
Recursos adicionais
- O Tensorflow Profiler: Profile Model Performance Tutorial com Keras e Tensorboard, onde você pode aplicar os conselhos neste guia.
- O perfil de desempenho no Tensorflow 2 fala do Tensorflow Dev Summit 2020.
- A demonstração do Profiler Tensorflow da Summit de DevFlow Dev 2020.
Limitações conhecidas
Profiling múltiplo GPUs no Tensorflow 2.2 e Tensorflow 2.3
O Tensorflow 2.2 e 2.3 suporta vários perfis de GPU apenas para sistemas de host único; Vários perfis de GPU para sistemas multi-host não são suportados. Para perfilar as configurações de GPU de vários trabalhos, cada trabalhador deve ser perfilado de forma independente. Do tensorflow 2.4 Múltiplos trabalhadores podem ser perfilados usando a API tf.profiler.experimental.client.trace .
CUDA® Toolkit 10.2 ou posterior é necessário para o perfil de várias GPUs. Como as versões Tensorflow 2.2 e 2.3 suportam o CUDA® Toolkit apenas até 10.1, você precisa criar links simbólicos para libcudart.so.10.1 e libcupti.so.10.1 :
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1