
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें |
एपीआई दस्तावेज़ीकरण: tf.RaggedTensor tf.ragged
सेट अप
import math
import tensorflow as tf
अवलोकन
आपका डेटा कई आकारों में आता है; आपके टेंसर भी चाहिए। रैग्ड टेंसर नेस्टेड वेरिएबल-लेंथ लिस्ट के TensorFlow समतुल्य हैं। वे गैर-समान आकृतियों के साथ डेटा को संग्रहीत और संसाधित करना आसान बनाते हैं, जिनमें शामिल हैं:
- चर-लंबाई की विशेषताएं, जैसे कि किसी फिल्म में अभिनेताओं का सेट।
- चर-लंबाई अनुक्रमिक इनपुट के बैच, जैसे वाक्य या वीडियो क्लिप।
- पदानुक्रमित इनपुट, जैसे पाठ दस्तावेज़ जो अनुभागों, अनुच्छेदों, वाक्यों और शब्दों में उप-विभाजित हैं।
- संरचित इनपुट में अलग-अलग फ़ील्ड, जैसे प्रोटोकॉल बफ़र्स।
आप रैग्ड टेंसर के साथ क्या कर सकते हैं
रैग्ड टेंसर सौ से अधिक TensorFlow संचालन द्वारा समर्थित हैं, जिसमें गणित संचालन (जैसे tf.add और tf.reduce_mean ), सरणी संचालन (जैसे tf.concat और tf.tile ), स्ट्रिंग हेरफेर ऑप्स (जैसे tf.substr ) शामिल हैं। ), नियंत्रण प्रवाह संचालन (जैसे tf. tf.while_loop और tf.map_fn ), और कई अन्य:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
कई विधियाँ और संचालन भी हैं जो रैग्ड टेंसर के लिए विशिष्ट हैं, जिनमें फ़ैक्टरी विधियाँ, रूपांतरण विधियाँ और मूल्य-मानचित्रण संचालन शामिल हैं। समर्थित ऑप्स की सूची के लिए, tf.ragged पैकेज दस्तावेज़ देखें।
रैग्ड टेंसर कई TensorFlow API द्वारा समर्थित हैं, जिनमें Keras , Datasets , tf.function , SavedModels और tf.Example शामिल हैं । अधिक जानकारी के लिए, नीचे TensorFlow APIs पर अनुभाग देखें।
सामान्य टेंसर की तरह, आप रैग्ड टेंसर के विशिष्ट स्लाइस तक पहुँचने के लिए पायथन-स्टाइल इंडेक्सिंग का उपयोग कर सकते हैं। अधिक जानकारी के लिए, नीचे अनुक्रमण पर अनुभाग देखें।
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
और सामान्य टेंसर की तरह, आप तत्व-वार संचालन करने के लिए पायथन अंकगणित और तुलना ऑपरेटरों का उपयोग कर सकते हैं। अधिक जानकारी के लिए, नीचे दिए गए ओवरलोडेड ऑपरेटरों पर अनुभाग देखें।
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
यदि आपको रैग्डटेन्सर के मूल्यों में एक तत्व के अनुसार परिवर्तन करने की आवश्यकता है, तो आप RaggedTensor का उपयोग कर सकते tf.ragged.map_flat_values , जो एक फ़ंक्शन प्लस एक या अधिक तर्क लेता है, और RaggedTensor के मानों को बदलने के लिए फ़ंक्शन को लागू करता है।
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
रैग्ड टेंसर को नेस्टेड पायथन list और न्यूमपी array में परिवर्तित किया जा सकता है:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
रैग्ड टेंसर का निर्माण
रैग्ड टेंसर के निर्माण का सबसे सरल तरीका tf.ragged.constant का उपयोग करना है, जो किसी दिए गए नेस्टेड पायथन list या NumPy array के अनुरूप RaggedTensor बनाता है:
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
रैग्ड टेंसर का निर्माण पंक्ति-विभाजन वाले टेंसर के साथ फ्लैट वैल्यू टेंसर को जोड़कर भी किया जा सकता है, यह दर्शाता है कि उन मानों को पंक्तियों में कैसे विभाजित किया जाना चाहिए, जैसे कि tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths , और tf.RaggedTensor.from_row_splits ।
tf.RaggedTensor.from_value_rowids
यदि आप जानते हैं कि प्रत्येक मान किस पंक्ति से संबंधित है, तो आप value_rowids पंक्ति-विभाजन टेंसर का उपयोग करके एक RaggedTensor टेंसर बना सकते हैं:
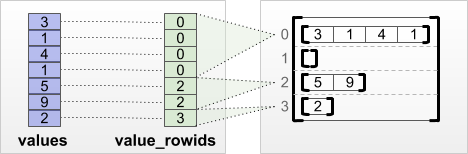
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
यदि आप जानते हैं कि प्रत्येक पंक्ति कितनी लंबी है, तो आप row_lengths पंक्ति-विभाजन टेंसर का उपयोग कर सकते हैं:
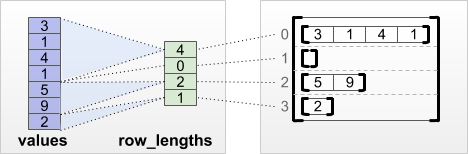
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
यदि आप उस सूचकांक को जानते हैं जहां प्रत्येक पंक्ति शुरू होती है और समाप्त होती है, तो आप एक row_splits पंक्ति-विभाजन टेंसर का उपयोग कर सकते हैं:
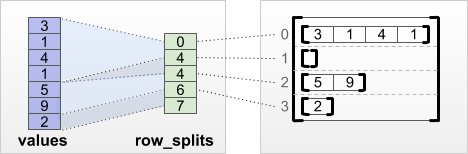
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
फ़ैक्टरी विधियों की पूरी सूची के लिए tf.RaggedTensor वर्ग दस्तावेज़ देखें।
आप रैग्ड टेंसर में क्या स्टोर कर सकते हैं
सामान्य Tensor s की तरह, RaggedTensor में सभी मान एक ही प्रकार के होने चाहिए; और मान सभी एक ही घोंसले की गहराई (टेंसर की रैंक ) पर होने चाहिए:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>प्लेसहोल्डर33 l10n-प्लेसहोल्डर
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
उदाहरण उपयोग केस
निम्न उदाहरण दर्शाता है कि प्रत्येक वाक्य की शुरुआत और अंत के लिए विशेष मार्करों का उपयोग करते हुए, चर-लंबाई वाले प्रश्नों के एक बैच के लिए यूनिग्राम और बिग्राम एम्बेडिंग के निर्माण और संयोजन के लिए RaggedTensor एस का उपयोग कैसे किया जा सकता है। इस उदाहरण में उपयोग किए गए ऑप्स के बारे में अधिक जानकारी के लिए, tf.ragged पैकेज दस्तावेज़ीकरण देखें।
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
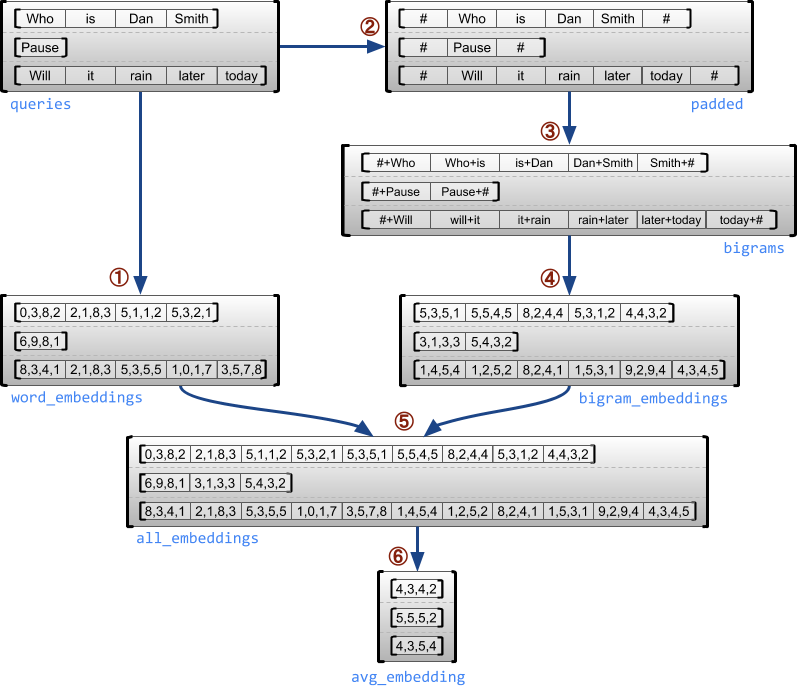
रैग्ड और समान आयाम
रैग्ड आयाम एक ऐसा आयाम है जिसके स्लाइस की लंबाई अलग-अलग हो सकती है। उदाहरण के लिए, rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] का आंतरिक (स्तंभ) आयाम रैग्ड है, क्योंकि कॉलम स्लाइस ( rt[0, :] , ..., rt[4, :] ) की लंबाई अलग-अलग होती है। वे आयाम जिनकी सभी स्लाइस की लंबाई समान होती है, समान आयाम कहलाते हैं।
रैग्ड टेंसर का सबसे बाहरी आयाम हमेशा एक समान होता है, क्योंकि इसमें एक ही टुकड़ा होता है (और, इसलिए, अलग-अलग स्लाइस की लंबाई की कोई संभावना नहीं है)। शेष आयाम या तो रैग्ड या एक समान हो सकते हैं। उदाहरण के लिए, आप प्रत्येक शब्द के लिए शब्द एम्बेडिंग को वाक्यों के एक बैच में आकार के साथ एक रैग्ड टेंसर का उपयोग करके स्टोर कर सकते हैं [num_sentences, (num_words), embedding_size] , जहां कोष्ठक (num_words) इंगित करते हैं कि आयाम रैग्ड है।
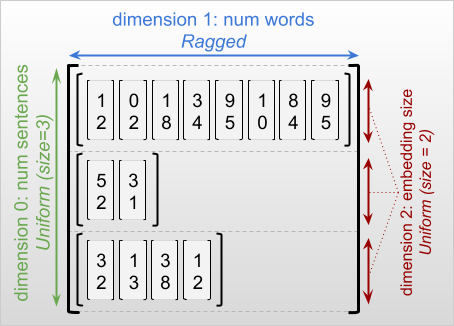
रैग्ड टेंसर में कई रैग्ड आयाम हो सकते हैं। उदाहरण के लिए, आप [num_documents, (num_paragraphs), (num_sentences), (num_words)] आकार वाले टेंसर का उपयोग करके संरचित टेक्स्ट दस्तावेज़ों के एक बैच को स्टोर कर सकते हैं (जहां फिर से कोष्ठक का उपयोग रैग्ड आयामों को इंगित करने के लिए किया जाता है)।
tf.Tensor की तरह, रैग्ड टेंसर की रैंक इसके आयामों की कुल संख्या (रैग्ड और एकसमान आयाम दोनों सहित) है। एक संभावित रैग्ड टेंसर एक ऐसा मान है जो या तो tf.Tensor या tf.RaggedTensor हो सकता है।
रैग्ड टेन्सर के आकार का वर्णन करते समय, रैग्ड आयामों को पारंपरिक रूप से कोष्ठक में संलग्न करके इंगित किया जाता है। उदाहरण के लिए, जैसा कि आपने ऊपर देखा, एक 3D RaggedTensor का आकार जो वाक्यों के एक बैच में प्रत्येक शब्द के लिए शब्द एम्बेडिंग को संग्रहीत करता है, को [num_sentences, (num_words), embedding_size] के रूप में लिखा जा सकता है।
RaggedTensor.shape विशेषता एक रैग्ड टेंसर के लिए एक tf.TensorShape लौटाती है जहाँ रैग्ड आयामों का आकार None होता है:
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
विधि tf.RaggedTensor.bounding_shape का उपयोग किसी दिए गए RaggedTensor के लिए एक तंग बाउंडिंग आकार खोजने के लिए किया जा सकता है:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
रैग्ड बनाम विरल
एक रैग्ड टेंसर को एक प्रकार के विरल टेंसर के रूप में नहीं माना जाना चाहिए। विशेष रूप से, विरल टेंसर tf.Tensor के लिए कुशल एन्कोडिंग हैं जो एक ही डेटा को एक कॉम्पैक्ट प्रारूप में मॉडल करते हैं; लेकिन रैग्ड टेंसर tf.Tensor का एक विस्तार है जो डेटा के एक विस्तारित वर्ग को मॉडल करता है। संचालन को परिभाषित करते समय यह अंतर महत्वपूर्ण है:
- एक विरल या घने टेंसर के लिए एक सेशन लागू करने से हमेशा एक ही परिणाम देना चाहिए।
- रैग्ड या विरल टेंसर पर ऑप लागू करने से अलग-अलग परिणाम मिल सकते हैं।
एक उदाहरण के रूप में, विचार करें कि रैग्ड बनाम विरल टेंसर के लिए concat , stack और tile जैसे सरणी संचालन को कैसे परिभाषित किया जाता है। संयुक्त लंबाई के साथ एक पंक्ति बनाने के लिए रैग्ड टेन्सर को जोड़ना प्रत्येक पंक्ति में शामिल होता है:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
हालाँकि, विरल टेन्सर्स को संयोजित करना संबंधित घने टेंसरों को संयोजित करने के बराबर है, जैसा कि निम्नलिखित उदाहरण द्वारा दिखाया गया है (जहाँ Ø लापता मान इंगित करता है):
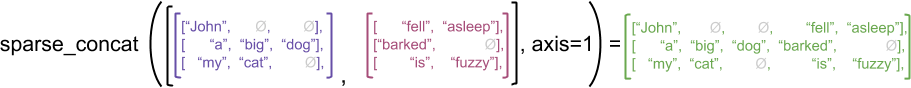
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
यह अंतर क्यों महत्वपूर्ण है, इसके एक अन्य उदाहरण के लिए, tf.reduce_mean जैसे ऑप के लिए "प्रत्येक पंक्ति का माध्य मान" की परिभाषा पर विचार करें। रैग्ड टेंसर के लिए, एक पंक्ति का माध्य मान पंक्ति की चौड़ाई से विभाजित पंक्ति के मानों का योग होता है। लेकिन एक विरल टेंसर के लिए, एक पंक्ति के लिए माध्य मान विरल टेंसर की समग्र चौड़ाई (जो सबसे लंबी पंक्ति की चौड़ाई से अधिक या उसके बराबर है) से विभाजित पंक्ति के मानों का योग है।
टेंसरफ्लो एपीआई
केरासो
tf.keras गहन शिक्षण मॉडल के निर्माण और प्रशिक्षण के लिए TensorFlow का उच्च-स्तरीय API है। रैग्ड टेंसर को केरस मॉडल के इनपुट के रूप में tf.keras.Input या tf.keras.layers.InputLayer पर ragged=True सेट करके पास किया जा सकता है। रैग्ड टेंसर को केरस परतों के बीच भी पारित किया जा सकता है, और केरस मॉडल द्वारा लौटाया जा सकता है। निम्न उदाहरण एक खिलौना LSTM मॉडल दिखाता है जिसे रैग्ड टेंसर का उपयोग करके प्रशिक्षित किया जाता है।
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.उदाहरण
tf.Example TensorFlow डेटा के लिए एक मानक प्रोटोबफ़ एन्कोडिंग है। tf.Example s के साथ एन्कोड किए गए डेटा में अक्सर चर-लंबाई की विशेषताएं शामिल होती हैं। उदाहरण के लिए, निम्न कोड चार tf.Example के बैच को परिभाषित करता है। विभिन्न फीचर लंबाई वाले उदाहरण संदेश:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
आप tf.io.parse_example का उपयोग करके इस एन्कोडेड डेटा को पार्स कर सकते हैं, जो क्रमबद्ध स्ट्रिंग्स का एक टेंसर और एक फीचर स्पेसिफिकेशन डिक्शनरी लेता है, और एक डिक्शनरी मैपिंग फीचर नाम को टेंसर में लौटाता है। रैग्ड टेंसर में वैरिएबल-लेंथ फीचर्स को पढ़ने के लिए, आप फीचर स्पेसिफिकेशन डिक्शनरी में बस tf.io.RaggedFeature का उपयोग करते हैं:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature का उपयोग कई रैग्ड आयामों वाली सुविधाओं को पढ़ने के लिए भी किया जा सकता है। विवरण के लिए, एपीआई दस्तावेज देखें।
डेटासेट
tf.data एक एपीआई है जो आपको सरल, पुन: प्रयोज्य टुकड़ों से जटिल इनपुट पाइपलाइन बनाने में सक्षम बनाता है। इसकी मूल डेटा संरचना tf.data.Dataset है, जो तत्वों के अनुक्रम का प्रतिनिधित्व करती है, जिसमें प्रत्येक तत्व में एक या अधिक घटक होते हैं।
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
रैग्ड टेंसर के साथ डेटासेट बनाना
डेटासेट को रैग्ड टेन्सर से उन्हीं विधियों का उपयोग करके बनाया जा सकता है जिनका उपयोग उन्हें tf.Tensor s या NumPy array s से बनाने के लिए किया जाता है, जैसे Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
रैग्ड टेंसर के साथ डेटासेट को बैचना और अनबैच करना
रैग्ड टेन्सर वाले डेटासेट को Dataset.batch विधि का उपयोग करके बैच किया जा सकता है (जो n लगातार तत्वों को एक तत्व में जोड़ता है)।
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
इसके विपरीत, एक बैच किए गए डेटासेट को Dataset.unbatch का उपयोग करके एक फ्लैट डेटासेट में बदला जा सकता है।
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
वेरिएबल-लेंथ नॉन-रैग्ड टेंसर के साथ बैचिंग डेटासेट
यदि आपके पास एक डेटासेट है जिसमें गैर-रैग्ड टेंसर शामिल हैं, और टेंसर की लंबाई सभी तत्वों में भिन्न होती है, तो आप उन गैर-रैग्ड टेंसर को dense_to_ragged_batch परिवर्तन को लागू करके रैग्ड टेंसर में बैच सकते हैं:
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
रैग्ड टेंसर के साथ डेटासेट बदलना
आप Dataset.map का उपयोग करके डेटासेट में Dataset.map टेंसर भी बना या बदल सकते हैं:
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
टीएफ.फंक्शन
tf.function एक डेकोरेटर है जो Python फ़ंक्शंस के लिए TensorFlow ग्राफ़ को प्रीकंप्यूट करता है, जो आपके TensorFlow कोड के प्रदर्शन में काफी सुधार कर सकता है। रैग्ड टेंसरों को @tf.function -decorated functions के साथ पारदर्शी रूप से उपयोग किया जा सकता है। उदाहरण के लिए, निम्न फ़ंक्शन रैग्ड और नॉन-रैग्ड टेंसर दोनों के साथ काम करता है:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
यदि आप tf.function के लिए input_signature स्पष्ट रूप से निर्दिष्ट करना चाहते हैं, तो आप tf.function का उपयोग tf.RaggedTensorSpec ऐसा कर सकते हैं।
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
ठोस कार्य
कंक्रीट फ़ंक्शन tf.function द्वारा बनाए गए व्यक्तिगत ट्रेस किए गए ग्राफ़ को इनकैप्सुलेट करते हैं। ठोस कार्यों के साथ रैग्ड टेंसर का पारदर्शी रूप से उपयोग किया जा सकता है।
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
सहेजे गए मॉडल
SavedModel एक क्रमबद्ध TensorFlow प्रोग्राम है, जिसमें वज़न और गणना दोनों शामिल हैं। इसे केरस मॉडल या कस्टम मॉडल से बनाया जा सकता है। किसी भी मामले में, रैग्ड टेन्सर्स को एक सहेजे गए मॉडल द्वारा परिभाषित कार्यों और विधियों के साथ पारदर्शी रूप से उपयोग किया जा सकता है।
उदाहरण: केरस मॉडल को सहेजना
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
उदाहरण: एक कस्टम मॉडल सहेजना
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
अतिभारित ऑपरेटरों
RaggedTensor वर्ग मानक पायथन अंकगणित और तुलना ऑपरेटरों को अधिभारित करता है, जिससे बुनियादी तत्व-वार गणित करना आसान हो जाता है:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
चूंकि अतिभारित ऑपरेटर तत्ववार गणना करते हैं, सभी बाइनरी परिचालनों के इनपुट में एक ही आकार होना चाहिए या एक ही आकार में प्रसारण योग्य होना चाहिए। सबसे सरल प्रसारण मामले में, एक एकल स्केलर को रैग्ड टेंसर में प्रत्येक मान के साथ तत्ववार जोड़ा जाता है:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
अधिक उन्नत मामलों की चर्चा के लिए, प्रसारण पर अनुभाग देखें।
रैग्ड टेंसर ऑपरेटरों के समान सेट को सामान्य Tensor के रूप में अधिभारित करते हैं: यूनरी ऑपरेटर्स - , ~ , और abs() ; और बाइनरी ऑपरेटरों + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > , और >= ।
इंडेक्सिंग
रैग्ड टेन्सर बहुआयामी अनुक्रमण और स्लाइसिंग सहित पायथन-शैली अनुक्रमण का समर्थन करते हैं। निम्नलिखित उदाहरण 2डी और 3डी रैग्ड टेंसर के साथ रैग्ड टेंसर इंडेक्सिंग को प्रदर्शित करते हैं।
अनुक्रमण उदाहरण: 2D रैग्ड टेंसर
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>88 l10n-
print(queries[:, :3]) # The first 3 words of each query
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
अनुक्रमण उदाहरण: 3D रैग्ड टेंसर
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor एक प्रतिबंध के साथ बहुआयामी अनुक्रमण और स्लाइसिंग का समर्थन करता है: रैग्ड आयाम में अनुक्रमण की अनुमति नहीं है। यह मामला समस्याग्रस्त है क्योंकि संकेतित मान कुछ पंक्तियों में मौजूद हो सकता है लेकिन अन्य में नहीं। ऐसे मामलों में, यह स्पष्ट नहीं है कि आपको (1) IndexError उठाना चाहिए या नहीं; (2) एक डिफ़ॉल्ट मान का उपयोग करें; या (3) उस मान को छोड़ दें और कम पंक्तियों वाला एक टेंसर लौटाएं, जिससे आपने शुरुआत की थी। पायथन के मार्गदर्शक सिद्धांतों के बाद ("अस्पष्टता के सामने, अनुमान लगाने के प्रलोभन से इंकार करें"), इस ऑपरेशन को वर्तमान में अस्वीकृत कर दिया गया है।
टेंसर प्रकार रूपांतरण
RaggedTensor वर्ग उन विधियों को परिभाषित करता है जिनका उपयोग RaggedTensor s और tf.Tensor s या tf.SparseTensors के बीच कनवर्ट करने के लिए किया जा सकता है:
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
रैग्ड टेंसर का मूल्यांकन
रैग्ड टेंसर में मानों तक पहुँचने के लिए, आप यह कर सकते हैं:
-
tf.RaggedTensor.to_listटेंसर को नेस्टेड पायथन सूची में बदलने के लिए tf.RaggedTensor.to_list का उपयोग करें। -
tf.RaggedTensor.numpyटेंसर को एक NumPy सरणी में बदलने के लिए tf.RaggedTensor.numpy का उपयोग करें, जिसका मान नेस्टेड NumPy सरणियाँ हैं। -
tf.RaggedTensor.valuesऔरtf.RaggedTensor.row_splitsगुणों, या पंक्ति-पैरिशनिंग विधियों जैसेtf.RaggedTensor.row_lengthsऔरtf.RaggedTensor.value_rowidsका उपयोग करके रैग्ड टेंसर को उसके घटकों में विघटित करें। - रैग्ड टेंसर से मूल्यों का चयन करने के लिए पायथन इंडेक्सिंग का उपयोग करें।
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
प्रसारण
प्रसारण अलग-अलग आकृतियों वाले टेंसर बनाने की प्रक्रिया है जिसमें तत्व के संचालन के लिए संगत आकार होते हैं। प्रसारण पर अधिक पृष्ठभूमि के लिए, देखें:
दो इनपुट x और y को संगत आकार देने के लिए प्रसारित करने के मूल चरण हैं:
यदि
xऔरyमें समान संख्या में आयाम नहीं हैं, तो बाहरी आयाम (आकार 1 के साथ) तब तक जोड़ें जब तक वे ऐसा न करें।प्रत्येक आयाम के लिए जहां
xऔरyके अलग-अलग आकार हैं:
- यदि
xयाyका आकारdआयाम में1है, तो अन्य इनपुट के आकार से मेल खाने के लिए आयामdमें इसके मानों को दोहराएं। - अन्यथा, एक अपवाद उठाएं (
xऔरyप्रसारण संगत नहीं हैं)।
जहां एक समान आयाम में एक टेंसर का आकार एक एकल संख्या है (उस आयाम में स्लाइस का आकार); और एक रैग्ड आयाम में एक टेंसर का आकार स्लाइस की लंबाई (उस आयाम के सभी स्लाइस के लिए) की एक सूची है।
प्रसारण उदाहरण
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
यहां आकृतियों के कुछ उदाहरण दिए गए हैं जो प्रसारित नहीं होते हैं:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
रैग्ड टेंसर एन्कोडिंग
रैग्ड टेंसर वर्ग का उपयोग करके RaggedTensor टेंसर को एन्कोड किया जाता है। आंतरिक रूप से, प्रत्येक RaggedTensor में निम्न शामिल हैं:
- एक
valuesटेंसर, जो चर-लंबाई वाली पंक्तियों को एक चपटी सूची में जोड़ता है। - एक
row_partition, जो इंगित करता है कि कैसे उन चपटे मानों को पंक्तियों में विभाजित किया जाता है।
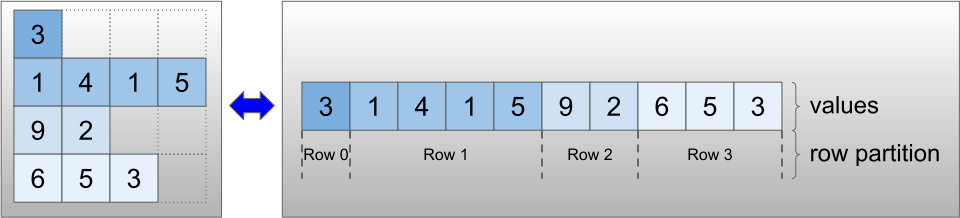
row_partition को चार अलग-अलग एन्कोडिंग का उपयोग करके संग्रहीत किया जा सकता है:
-
row_splitsएक पूर्णांक वेक्टर है जो पंक्तियों के बीच विभाजन बिंदुओं को निर्दिष्ट करता है। -
value_rowidsएक पूर्णांक वेक्टर है जो प्रत्येक मान के लिए पंक्ति अनुक्रमणिका निर्दिष्ट करता है। -
row_lengthsएक पूर्णांक वेक्टर है जो प्रत्येक पंक्ति की लंबाई निर्दिष्ट करता है। -
uniform_row_lengthएक पूर्णांक स्केलर है जो सभी पंक्तियों के लिए एक ही लंबाई निर्दिष्ट करता है।
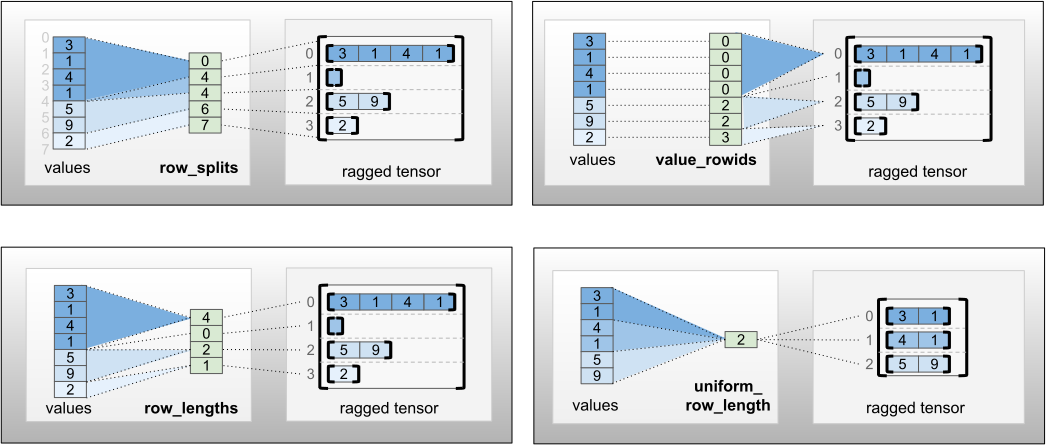
एक पूर्णांक स्केलर nrows को भी row_partition एन्कोडिंग में शामिल किया जा सकता है, जिसमें value_rowids वाली खाली अनुगामी पंक्तियों या value_rowids के साथ खाली पंक्तियों को शामिल किया जा uniform_row_length है।
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
पंक्ति विभाजन के लिए उपयोग की जाने वाली एन्कोडिंग का विकल्प कुछ संदर्भों में दक्षता में सुधार करने के लिए रैग्ड टेंसर द्वारा आंतरिक रूप से प्रबंधित किया जाता है। विशेष रूप से, विभिन्न पंक्ति-विभाजन योजनाओं के कुछ फायदे और नुकसान हैं:
- कुशल अनुक्रमण :
row_splitsएन्कोडिंग निरंतर-समय अनुक्रमण और रैग्ड टेंसर में स्लाइसिंग को सक्षम बनाता है। - कुशल संयोजन : रैग्ड टेंसरों को संयोजित करते समय
row_lengthsएन्कोडिंग अधिक कुशल होती है, क्योंकि दो टेंसरों को एक साथ जोड़ने पर पंक्ति की लंबाई नहीं बदलती है। - छोटे एन्कोडिंग आकार : रैग्ड टेंसरों को संग्रहीत करते समय
value_rowidsएन्कोडिंग अधिक कुशल होती है, जिसमें बड़ी संख्या में खाली पंक्तियाँ होती हैं, क्योंकि टेंसर का आकार केवल मानों की कुल संख्या पर निर्भर करता है। दूसरी ओर, लंबी पंक्तियों के साथ रैग्ड टेंसर को संग्रहीत करते समयrow_splitsऔरrow_lengthsएन्कोडिंग अधिक कुशल होते हैं, क्योंकि उन्हें प्रत्येक पंक्ति के लिए केवल एक स्केलर मान की आवश्यकता होती है। - संगतता :
value_rowidsयोजना संचालन द्वारा उपयोग किए जाने वाले विभाजन प्रारूप से मेल खाती है, जैसेtf.segment_sum।row_limitsयोजना ops द्वारा उपयोग किए जाने वाले प्रारूप जैसेtf.sequence_maskसे मेल खाती है। - समान आयाम : जैसा कि नीचे चर्चा की गई है, समान आयामों के साथ
uniform_row_lengthटेंसर को एन्कोड करने के लिए यूनिफ़ॉर्म_रो_लेंथ एन्कोडिंग का उपयोग किया जाता है।
एकाधिक रैग्ड आयाम
कई रैग्ड आयामों के साथ एक रैग्ड टेंसर को values टेंसर के लिए नेस्टेड RaggedTensor का उपयोग करके एन्कोड किया गया है। प्रत्येक नेस्टेड RaggedTensor एक रैग्ड आयाम जोड़ता है।
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
फ़ैक्टरी फ़ंक्शन tf.RaggedTensor.from_nested_row_splits का उपयोग कई रैग्ड आयामों के साथ RaggedTensor के निर्माण के लिए सीधे row_splits tensors की एक सूची प्रदान करके किया जा सकता है:
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
रैग्ड रैंक और फ्लैट वैल्यू
रैग्ड टेन्सर की रैग्ड रैंक उस समय की संख्या है जब अंतर्निहित values टेंसर को विभाजित किया गया है (अर्थात RaggedTensor ऑब्जेक्ट्स की नेस्टिंग डेप्थ)। अंतरतम values टेंसर को इसके flat_values के रूप में जाना जाता है। निम्नलिखित उदाहरण में, conversations में ragged_rank=3 है, और इसका flat_values 24 स्ट्रिंग्स वाला 1D Tensor है:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
समान आंतरिक आयाम
एकसमान आंतरिक आयामों वाले रैग्ड टेंसर को फ़्लैट_वैल्यूज़ (यानी, अंतरतम values ) के लिए एक बहुआयामी tf.Tensor का उपयोग करके एन्कोड किया गया है।
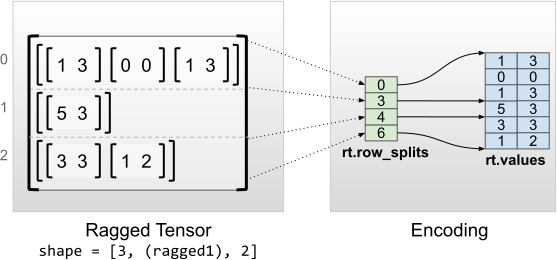
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
समान गैर-आंतरिक आयाम
समान गैर-आंतरिक आयामों वाले uniform_row_length टेंसर को यूनिफ़ॉर्म_रो_लेंथ के साथ पंक्तियों को विभाजित करके एन्कोड किया गया है।
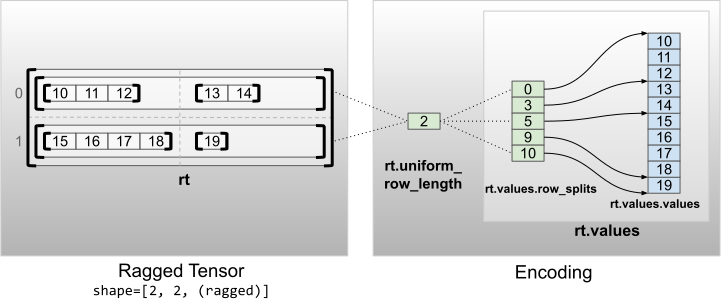
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2