
| | |  عرض المصدر على جيثب عرض المصدر على جيثب |
وثائق API: tf.RaggedTensor tf.ragged
يثبت
import math
import tensorflow as tf
ملخص
تأتي بياناتك في أشكال عديدة ؛ يجب أن تكون الموترات الخاصة بك أيضًا. الموترات الخشنة هي مكافئ TensorFlow لقوائم متغيرة الطول متداخلة. إنها تجعل من السهل تخزين البيانات ومعالجتها بأشكال غير موحدة ، بما في ذلك:
- ميزات متغيرة الطول ، مثل مجموعة الممثلين في الفيلم.
- دفعات من المدخلات المتسلسلة متغيرة الطول ، مثل الجمل أو مقاطع الفيديو.
- المدخلات الهرمية ، مثل المستندات النصية المقسمة إلى أقسام وفقرات وجمل وكلمات.
- الحقول الفردية في المدخلات المنظمة ، مثل المخازن المؤقتة للبروتوكول.
ما يمكنك القيام به مع موتر ممزق
يتم دعم الموترات الخشنة بأكثر من مائة عملية TensorFlow ، بما في ذلك العمليات الحسابية (مثل tf.add و tf.reduce_mean ) ، عمليات المصفوفة (مثل tf.concat و tf.tile ) ، عمليات التلاعب بالسلسلة (مثل tf.substr ) وعمليات التحكم في التدفق (مثل tf. tf.while_loop و tf.map_fn ) والعديد من العمليات الأخرى:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
هناك أيضًا عدد من الأساليب والعمليات الخاصة بالموترات الممزقة ، بما في ذلك طرق المصنع وطرق التحويل وعمليات تخطيط القيمة. للحصول على قائمة العمليات المدعومة ، راجع وثائق الحزمة tf.ragged .
يتم دعم الموترات الخشنة بواسطة العديد من واجهات برمجة تطبيقات TensorFlow ، بما في ذلك Keras و Datasets و tf.function و SavedModels و tf . لمزيد من المعلومات ، راجع قسم TensorFlow APIs أدناه.
كما هو الحال مع الموترات العادية ، يمكنك استخدام فهرسة بنمط Python للوصول إلى شرائح معينة من موتر خشن. لمزيد من المعلومات ، راجع القسم الخاص بالفهرسة أدناه.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
ومثل الموترات العادية ، يمكنك استخدام عوامل حسابية ومقارنة في بايثون لإجراء عمليات عنصرية. لمزيد من المعلومات ، راجع القسم الخاص بالعاملين المحملين أدناه.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
إذا كنت بحاجة إلى إجراء تحويل عنصري إلى قيم RaggedTensor ، فيمكنك استخدام tf.ragged.map_flat_values ، التي تأخذ دالة بالإضافة إلى وسيطة واحدة أو أكثر ، وتطبق الوظيفة لتحويل قيم RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
يمكن تحويل الموترات الخشنة إلى list Python و array متداخلة:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
بناء موتر ممزق
إن أبسط طريقة لبناء موتر خشن هي استخدام tf.ragged.constant ، الذي يبني RaggedTensor المطابق list Python المتداخلة أو array NumPy:
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
يمكن أيضًا إنشاء الموترات الخشنة عن طريق إقران موترات القيم المسطحة مع موترات تقسيم الصفوف التي تشير إلى كيفية تقسيم هذه القيم إلى صفوف ، باستخدام طرق تصنيف المصنع مثل tf.RaggedTensor.from_value_rowids و tf.RaggedTensor.from_row_lengths و tf.RaggedTensor.from_row_splits .
tf.RaggedTensor.from_value_rowids
إذا كنت تعرف الصف الذي تنتمي إليه كل قيمة ، فيمكنك بناء RaggedTensor باستخدام موتر تقسيم الصفوف value_rowids :
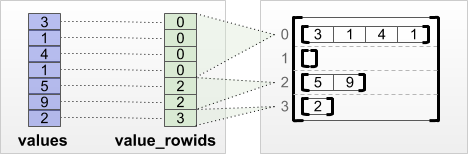
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
إذا كنت تعرف طول كل صف ، فيمكنك استخدام row_lengths تقسيم الصفوف:
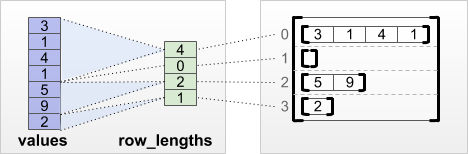
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
إذا كنت تعرف الفهرس حيث يبدأ كل صف وينتهي ، فيمكنك استخدام row_splits تقسيم الصفوف:
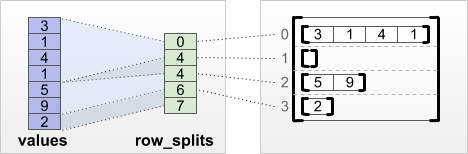
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
راجع وثائق فئة tf.RaggedTensor للحصول على قائمة كاملة بأساليب المصنع.
ما يمكنك تخزينه في موتر خشن
كما هو الحال مع Tensor العادي ، يجب أن تحتوي جميع القيم في RaggedTensor على نفس النوع ؛ ويجب أن تكون جميع القيم في نفس عمق التداخل ( رتبة الموتر):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
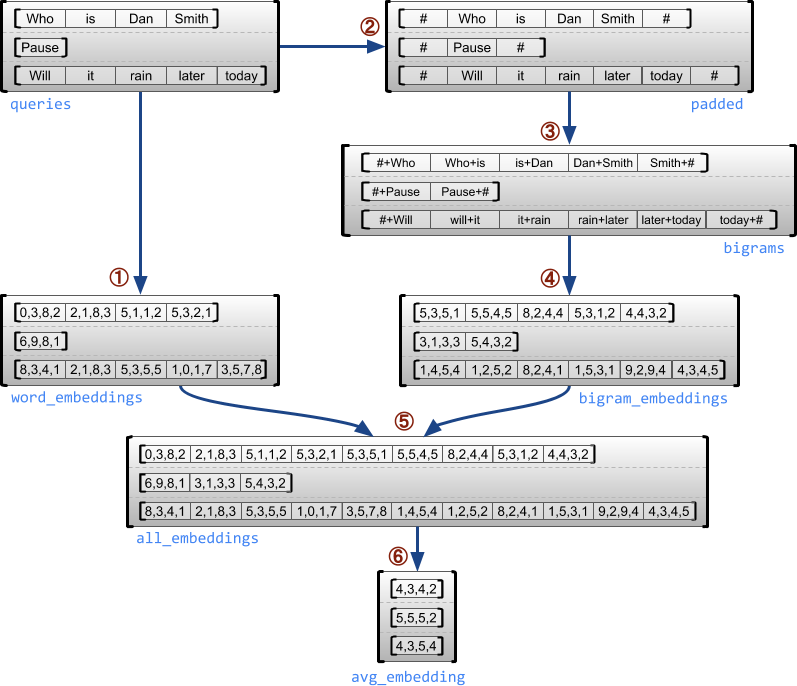
مثال على حالة الاستخدام
يوضح المثال التالي كيف يمكن استخدام RaggedTensor s لبناء ودمج عمليات دمج أحادي الطبقة و Bigram لمجموعة من الاستعلامات متغيرة الطول ، باستخدام علامات خاصة لبداية ونهاية كل جملة. لمزيد من التفاصيل حول العمليات المستخدمة في هذا المثال ، تحقق من وثائق الحزمة tf.ragged .
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
أبعاد خشنة وموحدة
البعد الممزق هو بعد قد يكون لشرائحه أطوال مختلفة. على سبيل المثال ، البعد الداخلي (العمود) لـ rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] ممزق ، لأن شرائح العمود ( rt[0, :] ، ...، rt[4, :] ) لها أطوال مختلفة. تسمى الأبعاد التي تحتوي جميع شرائحها بنفس الطول أبعاد موحدة .
دائمًا ما يكون البعد الخارجي للموتر الممزق منتظمًا ، لأنه يتكون من شريحة واحدة (وبالتالي ، لا توجد إمكانية لاختلاف أطوال الشرائح). قد تكون الأبعاد المتبقية إما ممزقة أو موحدة. على سبيل المثال ، يمكنك تخزين كلمة embeddings لكل كلمة في مجموعة من الجمل باستخدام موتر خشن مع الشكل [num_sentences, (num_words), embedding_size] ، حيث تشير الأقواس حول (num_words) إلى أن البعد ممزق.
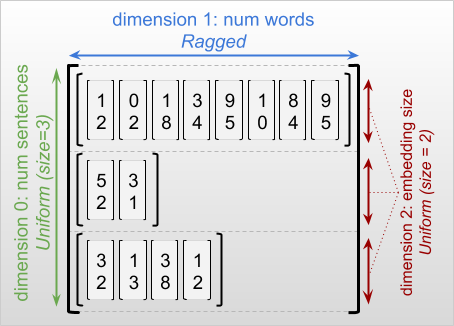
قد يكون للموترات الخشنة أبعاد متعددة ممزقة. على سبيل المثال ، يمكنك تخزين مجموعة من المستندات النصية المهيكلة باستخدام موتر مع الشكل [num_documents, (num_paragraphs), (num_sentences), (num_words)] (حيث يتم استخدام الأقواس مرة أخرى للإشارة إلى أبعاد ممزقة).
كما هو الحال مع tf.Tensor ، فإن رتبة الموتر الممزق هي العدد الإجمالي للأبعاد (بما في ذلك الأبعاد الخشنة والموحدة). الموتر الذي يحتمل أن يكون ممزق هو القيمة التي قد تكون إما tf.Tensor أو tf.RaggedTensor .
عند وصف شكل RaggedTensor ، تتم الإشارة إلى الأبعاد الخشنة بشكل تقليدي من خلال وضعها بين قوسين. على سبيل المثال ، كما رأيت أعلاه ، يمكن كتابة شكل RaggedTensor ثلاثي الأبعاد الذي يخزن تضمين الكلمات لكل كلمة في مجموعة من الجمل كـ [num_sentences, (num_words), embedding_size] .
تقوم السمة RaggedTensor.shape بإرجاع tf.TensorShape خشن حيث يكون للأبعاد الممزقة حجم None :
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
يمكن استخدام الطريقة tf.RaggedTensor.bounding_shape للعثور على شكل إحاطة ضيق RaggedTensor معين:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
خشن مقابل متفرق
لا ينبغي اعتبار الموتر الممزق نوعًا من الموتر المتناثر. على وجه الخصوص ، الموترات المتناثرة هي ترميز فعال لـ tf.Tensor الذي يصمم نفس البيانات بتنسيق مضغوط ؛ لكن الموتر الممزق هو امتداد لـ tf.Tensor الذي يصمم فئة موسعة من البيانات. هذا الاختلاف مهم عند تحديد العمليات:
- تطبيق op على موتر متفرق أو كثيف يجب أن يعطي نفس النتيجة دائمًا.
- قد يؤدي تطبيق عملية على موتر ممزق أو متفرق إلى نتائج مختلفة.
كمثال توضيحي ، ضع في اعتبارك كيف يتم تعريف عمليات الصفيف مثل concat و stack و tile لموترات خشنة مقابل موترات متفرقة. الموترات المتسلسلة الممزقة تنضم إلى كل صف لتشكيل صف واحد بطول مجمع:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
ومع ذلك ، فإن سلاسل الموترات المتناثرة المتسلسلة تعادل تسلسل الموترات الكثيفة المقابلة ، كما هو موضح في المثال التالي (حيث يشير Ø إلى القيم المفقودة):
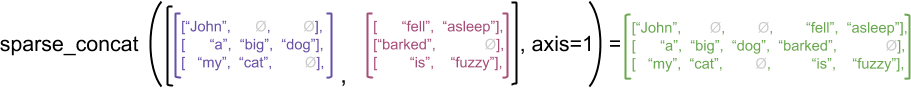
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
للحصول على مثال آخر عن سبب أهمية هذا التمييز ، ضع في اعتبارك تعريف "القيمة المتوسطة لكل صف" لمرجع مثل tf.reduce_mean . بالنسبة للموتر الممزق ، تكون القيمة المتوسطة للصف هي مجموع قيم الصف مقسومة على عرض الصف. ولكن بالنسبة للموتر المتفرق ، فإن القيمة المتوسطة للصف هي مجموع قيم الصف مقسومة على العرض الإجمالي للموتر المتناثر (أكبر من أو يساوي عرض الصف الأطول).
واجهات برمجة تطبيقات TensorFlow
كيراس
tf.keras هي واجهة برمجة تطبيقات عالية المستوى من TensorFlow لبناء وتدريب نماذج التعلم العميق. يمكن تمرير الموترات الخشنة كمدخلات لنموذج Keras عن طريق ضبط ragged ragged=True على tf.keras.Input أو tf.keras.layers.InputLayer . يمكن أيضًا تمرير الموترات الخشنة بين طبقات Keras ، وإعادتها بواسطة نماذج Keras. يوضح المثال التالي نموذج لعبة LSTM تم تدريبه باستخدام موترات خشنة.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf مثال
مثال هو تشفير protobuf القياسي لبيانات TensorFlow. غالبًا ما تشتمل البيانات المشفرة باستخدام tf.Example s على ميزات متغيرة الطول. على سبيل المثال ، يُعرّف الكود التالي مجموعة من أربعة رسائل tf.Example ، أمثلة بأطوال ميزات مختلفة:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
يمكنك تحليل هذه البيانات المشفرة باستخدام tf.io.parse_example ، والذي يأخذ موترًا من السلاسل المتسلسلة وقاموس مواصفات الميزة ، ويعيد تعيين أسماء ميزات القاموس إلى الموترات. لقراءة الميزات متغيرة الطول في موترات خشنة ، يمكنك ببساطة استخدام tf.io.RaggedFeature في قاموس مواصفات الميزة:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
يمكن أيضًا استخدام tf.io.RaggedFeature لقراءة الميزات ذات الأبعاد الخشنة المتعددة. للحصول على التفاصيل ، راجع وثائق API .
مجموعات البيانات
tf.data هي واجهة برمجة تطبيقات تمكّنك من إنشاء خطوط إدخال معقدة من أجزاء بسيطة قابلة لإعادة الاستخدام. هيكل البيانات الأساسي الخاص به هو tf.data.Dataset ، والذي يمثل سلسلة من العناصر ، حيث يتكون كل عنصر من مكون واحد أو أكثر.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
بناء مجموعات البيانات باستخدام الموترات الممزقة
يمكن بناء مجموعات البيانات من الموترات الخشنة باستخدام نفس الأساليب المستخدمة في بنائها من tf.Tensor s أو NumPy array s ، مثل Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
تجميع مجموعات البيانات وفكها باستخدام موترات خشنة
يمكن تجميع مجموعات البيانات ذات الموترات الممزقة (التي تجمع عددًا من العناصر المتتالية في عنصر واحد) باستخدام طريقة Dataset.batch .
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
على العكس من ذلك ، يمكن تحويل مجموعة البيانات المجمعة إلى مجموعة بيانات مسطحة باستخدام Dataset.unbatch .
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
مجموعات البيانات المجمعة مع موتر متغير الطول غير ممزق
إذا كانت لديك مجموعة بيانات تحتوي على موترات غير خشنة ، وتختلف أطوال الموتر عبر العناصر ، فيمكنك حينئذٍ تجميع تلك الموترات غير الخشنة في dense_to_ragged_batch خشنة عن طريق تطبيق تحويل الدفعة الكثيفة:
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
تحويل مجموعات البيانات باستخدام موترات خشنة
يمكنك أيضًا إنشاء موترات ممزقة أو تحويلها في مجموعات البيانات باستخدام Dataset.map :
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
وظيفة tf
tf.function هو مصمم يحسب مسبقًا الرسوم البيانية TensorFlow لوظائف Python ، والتي يمكن أن تحسن بشكل كبير من أداء كود TensorFlow الخاص بك. يمكن استخدام الموترات الخشنة بشفافية مع وظائف @tf.function . على سبيل المثال ، تعمل الوظيفة التالية مع كل من موترات ممزقة وغير ممزقة:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
إذا كنت ترغب في تحديد input_signature tf.function ، فيمكنك القيام بذلك باستخدام tf.RaggedTensorSpec .
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
وظائف ملموسة
تغلف الوظائف الملموسة الرسوم البيانية الفردية المتعقبة التي تم إنشاؤها بواسطة tf.function . يمكن استخدام الموترات الخشنة بشفافية مع وظائف الخرسانة.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
النماذج المحفوظة
يعد SavedModel برنامج TensorFlow متسلسل ، بما في ذلك كل من الأوزان والحسابات. يمكن بناؤه من طراز Keras أو من نموذج مخصص. في كلتا الحالتين ، يمكن استخدام الموترات الخشنة بشفافية مع الوظائف والطرق المحددة بواسطة SavedModel.
مثال: حفظ نموذج Keras
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
مثال: حفظ نموذج مخصص
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
مشغلين محملين فوق طاقتهم
تعمل فئة RaggedTensor على زيادة التحميل على عوامل التشغيل الحسابية والمقارنة في Python القياسية ، مما يجعل من السهل إجراء العمليات الحسابية الأساسية للعنصر:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
نظرًا لأن المشغلين المحملين يقومون بحسابات عنصرية ، يجب أن يكون للمدخلات في جميع العمليات الثنائية نفس الشكل أو تكون قابلة للبث إلى نفس الشكل. في أبسط حالة إذاعية ، يتم دمج عددي واحد بطريقة عنصرية مع كل قيمة في موتر خشن:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
لمناقشة الحالات الأكثر تقدمًا ، راجع قسم البث .
الموترات الخشنة تفرط في تحميل نفس مجموعة المشغلات مثل Tensor s العادية: العوامل الأحادية - ، ~ ، و abs() ؛ والعوامل الثنائية + ، - ، * ، / ، // ، % ، ** ، & ، | و ^ و == و < و <= و > و >= .
الفهرسة
تدعم الموترات الخشنة الفهرسة بأسلوب Python ، بما في ذلك الفهرسة متعددة الأبعاد والتقطيع. توضح الأمثلة التالية فهرسة موتر ممزقة باستخدام موتر خشن ثنائي الأبعاد وثلاثي الأبعاد.
أمثلة على الفهرسة: موتر خشن ثنائي الأبعاد
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
أمثلة على الفهرسة: موتر ثلاثي الأبعاد ممزق
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor s الفهرسة والتقطيع متعدد الأبعاد بقيد واحد: لا يُسمح بالفهرسة في بُعد ممزق. هذه الحالة إشكالية لأن القيمة المشار إليها قد تكون موجودة في بعض الصفوف دون غيرها. في مثل هذه الحالات ، ليس من الواضح ما إذا كان عليك (1) رفع خطأ في IndexError ؛ (2) استخدام قيمة افتراضية ؛ أو (3) تخطي هذه القيمة وإرجاع موتر بعدد صفوف أقل مما بدأت به. باتباع المبادئ التوجيهية لبايثون ("في مواجهة الغموض ، ارفض إغراء التخمين") ، هذه العملية غير مسموح بها حاليًا.
تحويل نوع الموتر
تحدد فئة RaggedTensor الطرق التي يمكن استخدامها للتحويل بين RaggedTensor s و tf.Tensor s أو tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
تقييم الموترات الممزقة
للوصول إلى القيم في موتر خشن ، يمكنك:
- استخدم
tf.RaggedTensor.to_listلتحويل الموتر الممزق إلى قائمة Python المتداخلة. - استخدم
tf.RaggedTensor.numpyلتحويل الموتر الممزق إلى مصفوفة NumPy تكون قيمها عبارة عن مصفوفات NumPy المتداخلة. - حلل الموتر الممزق إلى مكوناته ، باستخدام
tf.RaggedTensor.valuesوخصائصtf.RaggedTensor.row_splits، أو طرق تقسيم الصفوف مثلtf.RaggedTensor.row_lengthsوtf.RaggedTensor.value_rowids. - استخدم فهرسة Python لتحديد القيم من الموتر الممزق.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
البث
البث هو عملية جعل الموترات ذات الأشكال المختلفة لها أشكال متوافقة للعمليات الأولية. لمزيد من المعلومات الأساسية عن البث ، يرجى الرجوع إلى:
الخطوات الأساسية لبث مدخلين x و y للحصول على أشكال متوافقة هي:
إذا لم يكن لكل من
xوyنفس عدد الأبعاد ، فقم بإضافة الأبعاد الخارجية (بالحجم 1) حتى يكون لها نفس العدد.لكل بُعد حيث يكون لكل من
xوyأحجام مختلفة:
- إذا كان حجم
xأوy1في البعدd، فكرر قيمه عبر البعدdلتتناسب مع حجم المدخلات الأخرى. - خلاف ذلك ، قم بإثارة استثناء (لا تتوافق
xوyمع البث).
حيث يكون حجم الموتر في بُعد موحد رقمًا واحدًا (حجم الشرائح عبر هذا البعد) ؛ وحجم الموتر في بُعد خشن هو قائمة بأطوال الشرائح (لجميع الشرائح عبر هذا البعد).
أمثلة البث
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
فيما يلي بعض الأمثلة على الأشكال التي لا يتم بثها:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
ترميز RaggedTensor
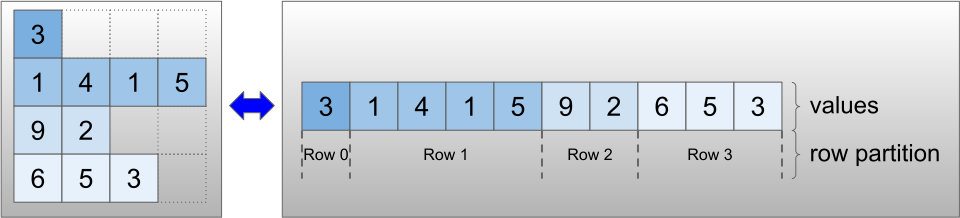
يتم ترميز الموترات الخشنة باستخدام فئة RaggedTensor . داخليًا ، يتكون كل RaggedTensor من:
- موتر
values، الذي يربط الصفوف متغيرة الطول في قائمة مسطحة. -
row_partition، والذي يشير إلى كيفية تقسيم هذه القيم المسطحة إلى صفوف.
يمكن تخزين row_partition باستخدام أربعة ترميزات مختلفة:
-
row_splitsهو متجه عدد صحيح يحدد نقاط الانقسام بين الصفوف. -
value_rowidsعبارة عن متجه عدد صحيح يحدد فهرس الصف لكل قيمة. -
row_lengthsهو متجه عدد صحيح يحدد طول كل صف. - يعتبر
uniform_row_lengthعددًا عددًا صحيحًا يحدد طولًا واحدًا لجميع الصفوف.
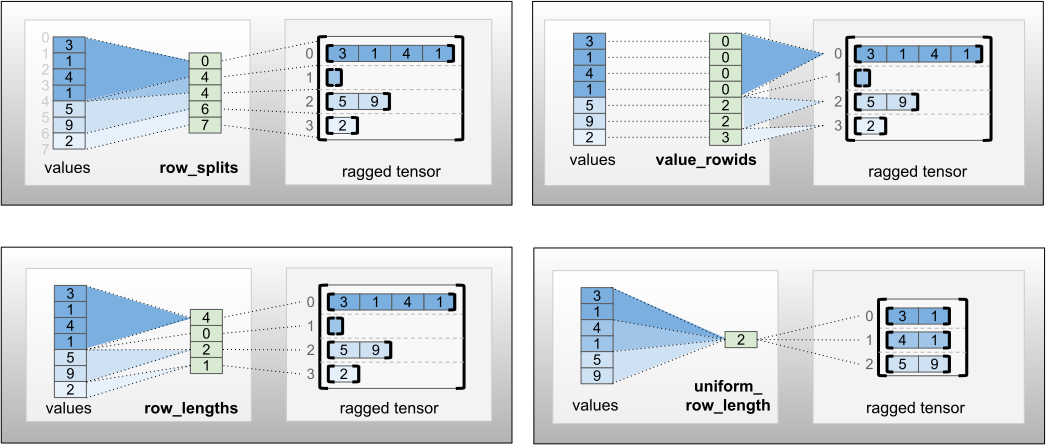
يمكن أيضًا تضمين عدد صحيح nrows في ترميز row_partition لحساب الصفوف الزائدة الفارغة ذات value_rowids أو الصفوف الفارغة ذات uniform_row_length .
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
يتم إدارة اختيار الترميز المراد استخدامه لأقسام الصف داخليًا بواسطة موترات خشنة لتحسين الكفاءة في بعض السياقات. على وجه الخصوص ، بعض مزايا وعيوب أنظمة تقسيم الصف المختلفة هي:
- الفهرسة الفعالة : يتيح ترميز
row_splitsفهرسة الوقت الثابت والتقطيع إلى موترات خشنة. - التسلسل الفعال : يكون ترميز
row_lengthsأكثر كفاءة عند تسلسل الموترات الخشنة ، حيث لا تتغير أطوال الصفوف عندما يتم ربط اثنين من الموترات معًا. - حجم ترميز صغير : يكون ترميز
value_rowidsأكثر كفاءة عند تخزين الموترات الممزقة التي تحتوي على عدد كبير من الصفوف الفارغة ، نظرًا لأن حجم الموتر يعتمد فقط على العدد الإجمالي للقيم. من ناحية أخرى ، تكون ترميزاتrow_splitsوrow_lengthsأكثر كفاءة عند تخزين الموترات الممزقة بصفوف أطول ، لأنها تتطلب قيمة عددية واحدة فقط لكل صف. - التوافق : يطابق مخطط
value_rowidsتنسيق التجزئة الذي تستخدمه العمليات ، مثلtf.segment_sum. يتطابق مخططrow_limitsمع التنسيق المستخدم بواسطة عمليات مثلtf.sequence_mask. - الأبعاد الموحدة : كما نوقش أدناه ، يتم استخدام ترميز موحد الطول لتشفير
uniform_row_lengthبأبعاد موحدة.
أبعاد متعددة ممزقة
يتم ترميز الموتر الخشن مع أبعاد خشن متعددة باستخدام RaggedTensor متداخلة values موتر. يضيف كل RaggedTensor متداخلة بُعدًا خشنًا واحدًا.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
يمكن استخدام وظيفة المصنع tf.RaggedTensor.from_nested_row_splits لإنشاء RaggedTensor بأبعاد خشنة متعددة مباشرةً من خلال توفير قائمة من row_splits :
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
الرتبة الخشنة والقيم المسطحة
رتبة الموتر الخشنة هي عدد المرات التي تم فيها تقسيم موتر values الأساسية (أي عمق تداخل كائنات RaggedTensor ). يُعرف موتر values الأعمق بقيمه المسطحة . في المثال التالي ، يكون conversations Tensor = 3 ، flat_values هي موتر 1D مع 24 سلسلة:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
أبعاد داخلية موحدة
يتم ترميز الموترات الخشنة ذات الأبعاد الداخلية الموحدة باستخدام tf.Tensor متعدد الأبعاد للقيم المسطحة (أي values الأعمق).
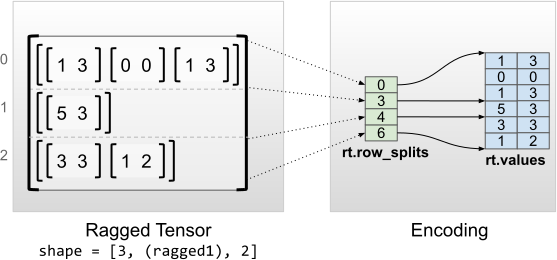
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
أبعاد موحدة غير داخلية
يتم ترميز uniform_row_length ذات الأبعاد غير الداخلية المنتظمة عن طريق تقسيم الصفوف ذات الطول المنتظم.
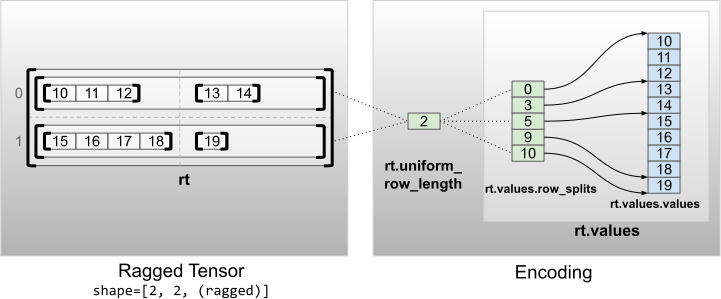
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2