
| |  GitHubで表示 GitHubで表示 | |
ゼロ値を多く含むテンソルを使用する場合は、スペースと時間の効率的な方法でテンソルを格納することが重要です。スパーステンソルは、多くのゼロ値を含むテンソルの効率的な保存と処理を可能にします。スパーステンサーは、NLPアプリケーションでのデータ前処理の一部としてTF-IDFなどのエンコード方式で、またコンピュータービジョンアプリケーションで多くの暗いピクセルを含む画像を前処理するために広く使用されています。
TensorFlowのスパーステンソル
TensorFlowは、 tf.SparseTensorオブジェクトを介してスパーステンソルを表します。現在、TensorFlowのスパーステンソルは、座標リスト(COO)形式を使用してエンコードされています。このエンコード形式は、埋め込みなどの超スパース行列用に最適化されています。
スパーステンソルのCOOエンコーディングは次のもので構成されます。
-
values:すべての非ゼロ値を含む形状[N]の1Dテンソル。 -
indices:非ゼロ値のインデックスを含む、形状[N, rank]の2Dテンソル。 -
dense_shape:形状[rank]の1Dテンソルで、テンソルの形状を指定します。
tf.SparseTensorのコンテキストでのゼロ以外の値は、明示的にエンコードされていない値です。 COOスパース行列のvaluesにゼロ値を明示的に含めることは可能ですが、スパーステンソルで非ゼロ値を参照する場合、これらの「明示的なゼロ」は通常含まれません。
tf.SparseTensorの作成
values 、 indices 、 dense_shapeを直接指定して、スパーステンソルを作成します。
import tensorflow as tf
st1 = tf.SparseTensor(indices=[[0, 3], [2, 4]],
values=[10, 20],
dense_shape=[3, 10])
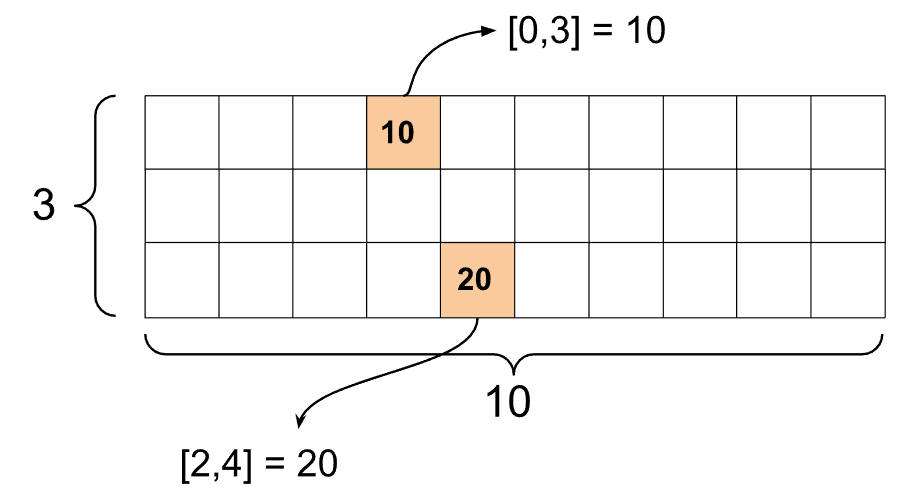
print()関数を使用してスパーステンソルを印刷すると、3つのコンポーネントテンソルの内容が表示されます。
print(st1)
SparseTensor(indices=tf.Tensor( [[0 3] [2 4]], shape=(2, 2), dtype=int64), values=tf.Tensor([10 20], shape=(2,), dtype=int32), dense_shape=tf.Tensor([ 3 10], shape=(2,), dtype=int64))
ゼロ以外のvaluesが対応するindicesと整列していると、スパーステンソルの内容を理解しやすくなります。ゼロ以外の各値が独自の行に表示されるように、スパーステンソルをきれいに印刷するヘルパー関数を定義します。
def pprint_sparse_tensor(st):
s = "<SparseTensor shape=%s \n values={" % (st.dense_shape.numpy().tolist(),)
for (index, value) in zip(st.indices, st.values):
s += f"\n %s: %s" % (index.numpy().tolist(), value.numpy().tolist())
return s + "}>"
print(pprint_sparse_tensor(st1))
<SparseTensor shape=[3, 10]
values={
[0, 3]: 10
[2, 4]: 20}>
tf.sparse.from_denseを使用して密テンソルからスパーステンソルを構築し、 tf.sparse.from_denseを使用してそれらを密テンソルに戻すこともtf.sparse.to_denseます。
st2 = tf.sparse.from_dense([[1, 0, 0, 8], [0, 0, 0, 0], [0, 0, 3, 0]])
print(pprint_sparse_tensor(st2))
<SparseTensor shape=[3, 4]
values={
[0, 0]: 1
[0, 3]: 8
[2, 2]: 3}>
st3 = tf.sparse.to_dense(st2)
print(st3)
tf.Tensor( [[1 0 0 8] [0 0 0 0] [0 0 3 0]], shape=(3, 4), dtype=int32)
スパーステンソルの操作
tf.sparseパッケージのユーティリティを使用して、スパーステンソルを操作します。密なテンソルの算術操作に使用できるtf.math.addのような演算は、疎なテンソルでは機能しません。
tf.sparse.addを使用して、同じ形状のスパーステンソルを追加します。
st_a = tf.SparseTensor(indices=[[0, 2], [3, 4]],
values=[31, 2],
dense_shape=[4, 10])
st_b = tf.SparseTensor(indices=[[0, 2], [7, 0]],
values=[56, 38],
dense_shape=[4, 10])
st_sum = tf.sparse.add(st_a, st_b)
print(pprint_sparse_tensor(st_sum))
<SparseTensor shape=[4, 10]
values={
[0, 2]: 87
[3, 4]: 2
[7, 0]: 38}>
tf.sparse.sparse_dense_matmulを使用して、スパーステンソルに密行列を乗算します。
st_c = tf.SparseTensor(indices=([0, 1], [1, 0], [1, 1]),
values=[13, 15, 17],
dense_shape=(2,2))
mb = tf.constant([[4], [6]])
product = tf.sparse.sparse_dense_matmul(st_c, mb)
print(product)
tf.Tensor( [[ 78] [162]], shape=(2, 1), dtype=int32)
tf.sparse.concatを使用してスパーステンソルをまとめ、 tf.sparse.concatを使用してそれらをtf.sparse.sliceします。
sparse_pattern_A = tf.SparseTensor(indices = [[2,4], [3,3], [3,4], [4,3], [4,4], [5,4]],
values = [1,1,1,1,1,1],
dense_shape = [8,5])
sparse_pattern_B = tf.SparseTensor(indices = [[0,2], [1,1], [1,3], [2,0], [2,4], [2,5], [3,5],
[4,5], [5,0], [5,4], [5,5], [6,1], [6,3], [7,2]],
values = [1,1,1,1,1,1,1,1,1,1,1,1,1,1],
dense_shape = [8,6])
sparse_pattern_C = tf.SparseTensor(indices = [[3,0], [4,0]],
values = [1,1],
dense_shape = [8,6])
sparse_patterns_list = [sparse_pattern_A, sparse_pattern_B, sparse_pattern_C]
sparse_pattern = tf.sparse.concat(axis=1, sp_inputs=sparse_patterns_list)
print(tf.sparse.to_dense(sparse_pattern))
tf.Tensor( [[0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0] [0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0] [0 0 0 1 1 0 0 0 0 0 1 1 0 0 0 0 0] [0 0 0 1 1 0 0 0 0 0 1 1 0 0 0 0 0] [0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0] [0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0]], shape=(8, 17), dtype=int32)
sparse_slice_A = tf.sparse.slice(sparse_pattern_A, start = [0,0], size = [8,5])
sparse_slice_B = tf.sparse.slice(sparse_pattern_B, start = [0,5], size = [8,6])
sparse_slice_C = tf.sparse.slice(sparse_pattern_C, start = [0,10], size = [8,6])
print(tf.sparse.to_dense(sparse_slice_A))
print(tf.sparse.to_dense(sparse_slice_B))
print(tf.sparse.to_dense(sparse_slice_C))
tf.Tensor( [[0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 1] [0 0 0 1 1] [0 0 0 1 1] [0 0 0 0 1] [0 0 0 0 0] [0 0 0 0 0]], shape=(8, 5), dtype=int32) tf.Tensor( [[0] [0] [1] [1] [1] [1] [0] [0]], shape=(8, 1), dtype=int32) tf.Tensor([], shape=(8, 0), dtype=int32)
TensorFlow 2.4以降を使用している場合は、スパーステンソルのゼロ以外の値に対する要素ごとの操作にtf.sparse.map_valuesを使用します。
st2_plus_5 = tf.sparse.map_values(tf.add, st2, 5)
print(tf.sparse.to_dense(st2_plus_5))
tf.Tensor( [[ 6 0 0 13] [ 0 0 0 0] [ 0 0 8 0]], shape=(3, 4), dtype=int32)
ゼロ以外の値のみが変更されたことに注意してください–ゼロ値はゼロのままです。
同様に、以前のバージョンのTensorFlowについては、以下のデザインパターンに従うことができます。
st2_plus_5 = tf.SparseTensor(
st2.indices,
st2.values + 5,
st2.dense_shape)
print(tf.sparse.to_dense(st2_plus_5))
tf.Tensor( [[ 6 0 0 13] [ 0 0 0 0] [ 0 0 8 0]], shape=(3, 4), dtype=int32)
tf.SparseTensorを他のTensorFlowAPIで使用する
スパーステンソルは、これらのTensorFlowAPIで透過的に機能します。
-
tf.keras -
tf.data -
tf.Train.Exampleprotobuf -
tf.function -
tf.while_loop -
tf.cond -
tf.identity -
tf.cast -
tf.print -
tf.saved_model -
tf.io.serialize_sparse -
tf.io.serialize_many_sparse -
tf.io.deserialize_many_sparse -
tf.math.abs -
tf.math.negative -
tf.math.sign -
tf.math.square -
tf.math.sqrt -
tf.math.erf -
tf.math.tanh -
tf.math.bessel_i0e -
tf.math.bessel_i1e
上記のAPIのいくつかの例を以下に示します。
tf.keras
tf.keras APIのサブセットは、高価なキャストや変換操作なしでスパーステンソルをサポートします。 Keras APIを使用すると、スパーステンソルをKerasモデルへの入力として渡すことができます。 tf.keras.Inputまたはtf.keras.layers.InputLayerを呼び出すときは、 sparse=Trueを設定します。 Kerasレイヤー間でスパーステンソルを渡すことができ、Kerasモデルにそれらを出力として返すようにすることもできます。モデルのtf.keras.layers.Denseレイヤーでスパーステンソルを使用すると、デンソルテンソルが出力されます。
以下の例は、スパース入力をサポートするレイヤーのみを使用する場合に、スパーステンソルをKerasモデルへの入力として渡す方法を示しています。
x = tf.keras.Input(shape=(4,), sparse=True)
y = tf.keras.layers.Dense(4)(x)
model = tf.keras.Model(x, y)
sparse_data = tf.SparseTensor(
indices = [(0,0),(0,1),(0,2),
(4,3),(5,0),(5,1)],
values = [1,1,1,1,1,1],
dense_shape = (6,4)
)
model(sparse_data)
model.predict(sparse_data)
array([[-1.3111044 , -1.7598825 , 0.07225233, -0.44544357],
[ 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ],
[ 0.8517609 , -0.16835624, 0.7307872 , -0.14531797],
[-0.8916302 , -0.9417639 , 0.24563438, -0.9029659 ]],
dtype=float32)
tf.data
tf.data APIを使用すると、単純で再利用可能な部分から複雑な入力パイプラインを構築できます。そのコアデータ構造はtf.data.Datasetであり、各要素が1つ以上のコンポーネントで構成される要素のシーケンスを表します。
スパーステンソルを使用したデータセットの構築
tf.TensorまたはNumPy配列( tf.data.Dataset.from_tensor_slicesなど)からデータセットを構築するために使用されるのと同じ方法を使用して、スパーステンソルからデータセットを構築します。この操作は、データのスパース性(またはスパース性)を保持します。
dataset = tf.data.Dataset.from_tensor_slices(sparse_data)
for element in dataset:
print(pprint_sparse_tensor(element))
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1
[2]: 1}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={
[3]: 1}>
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1}>
プレースホルダー27スパーステンソルを使用したデータセットのバッチ処理と非バッチ処理
Dataset.unbatch Dataset.batchをそれぞれ使用して、スパーステンソルでデータセットをバッチ処理(連続する要素を1つの要素に結合)およびバッチ解除できます。
batched_dataset = dataset.batch(2)
for element in batched_dataset:
print (pprint_sparse_tensor(element))
<SparseTensor shape=[2, 4]
values={
[0, 0]: 1
[0, 1]: 1
[0, 2]: 1}>
<SparseTensor shape=[2, 4]
values={}>
<SparseTensor shape=[2, 4]
values={
[0, 3]: 1
[1, 0]: 1
[1, 1]: 1}>
unbatched_dataset = batched_dataset.unbatch()
for element in unbatched_dataset:
print (pprint_sparse_tensor(element))
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1
[2]: 1}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={
[3]: 1}>
<SparseTensor shape=[4]
values={
[0]: 1
[1]: 1}>
tf.data.experimental.dense_to_sparse_batchを使用して、さまざまな形状のデータセット要素をスパーステンソルにバッチ処理することもできます。
スパーステンソルを使用したデータセットの変換
Dataset.mapを使用して、データセットにスパーステンソルを変換および作成します。
transform_dataset = dataset.map(lambda x: x*2)
for i in transform_dataset:
print(pprint_sparse_tensor(i))
<SparseTensor shape=[4]
values={
[0]: 2
[1]: 2
[2]: 2}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={}>
<SparseTensor shape=[4]
values={
[3]: 2}>
<SparseTensor shape=[4]
values={
[0]: 2
[1]: 2}>
tf.train.Example
tf.train.Exampleは、TensorFlowデータの標準のprotobufエンコーディングです。 tf.train.Exampleでスパーステンソルを使用する場合、次のことができます。
tf.SparseTensorを使用して、可変長データをtf.io.VarLenFeatureに読み込みます。ただし、代わりにtf.io.RaggedFeature使用を検討する必要があります。tf.SparseTensorを使用して任意のスパースデータをtf.io.SparseFeatureに読み込みます。これは、3つの個別の機能キーを使用して、indices、values、およびdense_shapeを格納します。
tf.function
tf.functionデコレータは、Python関数のTensorFlowグラフを事前に計算します。これにより、TensorFlowコードのパフォーマンスを大幅に向上させることができます。スパーステンソルは、 tf.function関数とconcrete関数の両方で透過的に機能します。
@tf.function
def f(x,y):
return tf.sparse.sparse_dense_matmul(x,y)
a = tf.SparseTensor(indices=[[0, 3], [2, 4]],
values=[15, 25],
dense_shape=[3, 10])
b = tf.sparse.to_dense(tf.sparse.transpose(a))
c = f(a,b)
print(c)
tf.Tensor( [[225 0 0] [ 0 0 0] [ 0 0 625]], shape=(3, 3), dtype=int32)
欠落している値とゼロの値を区別する
tf.SparseTensorのほとんどの操作は、欠落値と明示的なゼロ値を同じように扱います。これは仕様によるものですtf.SparseTensorは密なテンソルのように機能することになっています。
ただし、ゼロ値と欠落値を区別すると便利な場合がいくつかあります。特に、これにより、トレーニングデータ内の欠落/不明なデータをエンコードする1つの方法が可能になります。たとえば、スコアのテンソル(-Infから+ Infまでの任意の浮動小数点値を持つことができます)があり、いくつかのスコアが欠落しているユースケースを考えてみます。スパーステンソルを使用してこのテンソルをエンコードできます。ここで、明示的なゼロは既知のゼロスコアですが、暗黙的なゼロ値は実際には欠落データを表し、ゼロではありません。
tf.sparse.reduce_maxなどの一部の操作では、欠落している値がゼロであるかのように扱われないことに注意してください。たとえば、以下のコードブロックを実行すると、期待される出力は0になります。ただし、この例外のため、出力は-3です。
print(tf.sparse.reduce_max(tf.sparse.from_dense([-5, 0, -3])))
tf.Tensor(-3, shape=(), dtype=int32)
対照的に、 tf.math.reduce_maxを密なテンソルに適用すると、期待どおりに出力は0になります。
print(tf.math.reduce_max([-5, 0, -3]))
tf.Tensor(0, shape=(), dtype=int32)
さらなる読み物とリソース
- テンソルについては、テンソルガイドを参照してください。
- 不規則なデータを処理できるテンソルの一種である不規則なテンソルの操作方法については、不規則なテンソルガイドをお読みください。
-
tf.Exampleデータデコーダーでスパーステンソルを使用するTensorFlowモデルガーデンでこのオブジェクト検出モデルを確認してください。