
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
import tensorflow as tf
import numpy as np
تانسورها آرایه های چند بعدی با نوع یکنواخت هستند (به نام dtype ). میتوانید همه dtypes پشتیبانیشده را در tf.dtypes.DType .
اگر با NumPy آشنا هستید، تانسورها (نوعی) مانند np.arrays هستند.
همه تانسورها مانند اعداد و رشته های پایتون تغییر ناپذیر هستند: شما هرگز نمی توانید محتوای یک تانسور را به روز کنید، فقط یک تانسور جدید ایجاد کنید.
مبانی
بیایید چند تانسور اصلی ایجاد کنیم.
در اینجا یک تانسور "اسکالر" یا "رتبه-0" وجود دارد. یک اسکالر حاوی یک مقدار واحد و بدون "محور" است.
# This will be an int32 tensor by default; see "dtypes" below.
rank_0_tensor = tf.constant(4)
print(rank_0_tensor)
tf.Tensor(4, shape=(), dtype=int32)
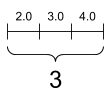
تانسور "بردار" یا "رتبه-1" مانند لیستی از مقادیر است. یک بردار یک محور دارد:
# Let's make this a float tensor.
rank_1_tensor = tf.constant([2.0, 3.0, 4.0])
print(rank_1_tensor)
tf.Tensor([2. 3. 4.], shape=(3,), dtype=float32)
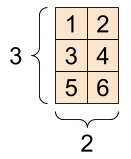
یک تانسور "ماتریس" یا "رتبه-2" دو محور دارد:
# If you want to be specific, you can set the dtype (see below) at creation time
rank_2_tensor = tf.constant([[1, 2],
[3, 4],
[5, 6]], dtype=tf.float16)
print(rank_2_tensor)
tf.Tensor( [[1. 2.] [3. 4.] [5. 6.]], shape=(3, 2), dtype=float16)
اسکالر، شکل: [] | یک بردار، شکل: [3] | یک ماتریس، شکل: [3, 2] |
|---|---|---|
 |  |  |
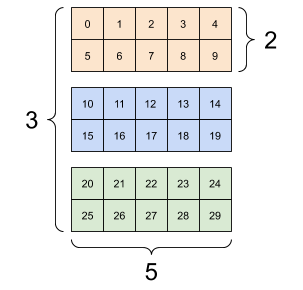
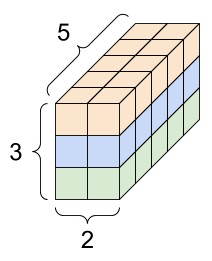
تانسورها ممکن است محورهای بیشتری داشته باشند. در اینجا یک تانسور با سه محور وجود دارد:
# There can be an arbitrary number of
# axes (sometimes called "dimensions")
rank_3_tensor = tf.constant([
[[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]],
[[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]],
[[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]],])
print(rank_3_tensor)
tf.Tensor( [[[ 0 1 2 3 4] [ 5 6 7 8 9]] [[10 11 12 13 14] [15 16 17 18 19]] [[20 21 22 23 24] [25 26 27 28 29]]], shape=(3, 2, 5), dtype=int32)
راه های زیادی وجود دارد که می توانید یک تانسور را با بیش از دو محور تجسم کنید.
تانسور 3 محوری، شکل: [3, 2, 5] | ||
|---|---|---|
 | 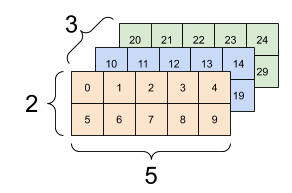 |  |
شما می توانید یک تانسور را با استفاده از روش np.array یا tensor.numpy به آرایه NumPy تبدیل کنید:
np.array(rank_2_tensor)
array([[1., 2.],
[3., 4.],
[5., 6.]], dtype=float16)
rank_2_tensor.numpy()
array([[1., 2.],
[3., 4.],
[5., 6.]], dtype=float16)
تانسورها اغلب حاوی شناورها و int ها هستند، اما انواع دیگری نیز دارند، از جمله:
- اعداد مختلط
- رشته های
کلاس پایه tf.Tensor نیاز دارد که تانسورها "مستطیلی" باشند --- یعنی در امتداد هر محور، هر عنصر یک اندازه باشد. با این حال، انواع خاصی از تانسورها وجود دارد که می توانند اشکال مختلف را مدیریت کنند:
- تانسورهای Ragged (به RaggedTensor زیر مراجعه کنید)
- تانسورهای پراکنده (به SparseTensor زیر مراجعه کنید)
شما می توانید ریاضیات پایه را روی تانسورها انجام دهید، از جمله جمع، ضرب بر اساس عنصر و ضرب ماتریس.
a = tf.constant([[1, 2],
[3, 4]])
b = tf.constant([[1, 1],
[1, 1]]) # Could have also said `tf.ones([2,2])`
print(tf.add(a, b), "\n")
print(tf.multiply(a, b), "\n")
print(tf.matmul(a, b), "\n")
tf.Tensor( [[2 3] [4 5]], shape=(2, 2), dtype=int32) tf.Tensor( [[1 2] [3 4]], shape=(2, 2), dtype=int32) tf.Tensor( [[3 3] [7 7]], shape=(2, 2), dtype=int32)
print(a + b, "\n") # element-wise addition
print(a * b, "\n") # element-wise multiplication
print(a @ b, "\n") # matrix multiplication
tf.Tensor( [[2 3] [4 5]], shape=(2, 2), dtype=int32) tf.Tensor( [[1 2] [3 4]], shape=(2, 2), dtype=int32) tf.Tensor( [[3 3] [7 7]], shape=(2, 2), dtype=int32)
تانسورها در انواع عملیات (ops) استفاده می شوند.
c = tf.constant([[4.0, 5.0], [10.0, 1.0]])
# Find the largest value
print(tf.reduce_max(c))
# Find the index of the largest value
print(tf.argmax(c))
# Compute the softmax
print(tf.nn.softmax(c))
tf.Tensor(10.0, shape=(), dtype=float32) tf.Tensor([1 0], shape=(2,), dtype=int64) tf.Tensor( [[2.6894143e-01 7.3105854e-01] [9.9987662e-01 1.2339458e-04]], shape=(2, 2), dtype=float32)
در مورد اشکال
تانسورها اشکال دارند. برخی از واژگان:
- شکل : طول (تعداد عناصر) هر یک از محورهای یک تانسور.
- رتبه : تعداد محورهای تانسور. یک اسکالر دارای رتبه 0، یک بردار دارای رتبه 1، یک ماتریس دارای رتبه 2 است.
- محور یا بعد : بعد خاصی از یک تانسور.
- اندازه : تعداد کل موارد در تانسور، بردار شکل محصول.
تانسورها و اشیاء tf.TensorShape ویژگی های مناسبی برای دسترسی به این موارد دارند:
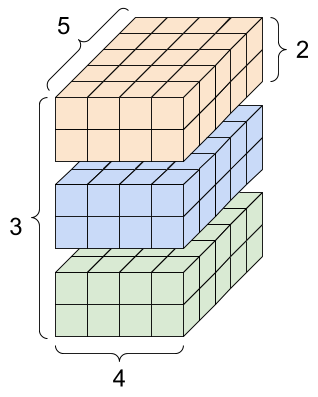
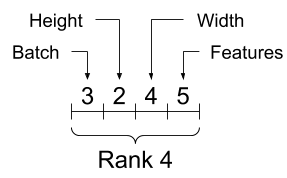
rank_4_tensor = tf.zeros([3, 2, 4, 5])
تانسور رتبه-4، شکل: [3, 2, 4, 5] | |
|---|---|
 |  |
print("Type of every element:", rank_4_tensor.dtype)
print("Number of axes:", rank_4_tensor.ndim)
print("Shape of tensor:", rank_4_tensor.shape)
print("Elements along axis 0 of tensor:", rank_4_tensor.shape[0])
print("Elements along the last axis of tensor:", rank_4_tensor.shape[-1])
print("Total number of elements (3*2*4*5): ", tf.size(rank_4_tensor).numpy())
Type of every element: <dtype: 'float32'> Number of axes: 4 Shape of tensor: (3, 2, 4, 5) Elements along axis 0 of tensor: 3 Elements along the last axis of tensor: 5 Total number of elements (3*2*4*5): 120
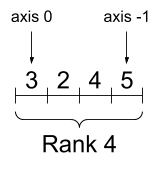
در حالی که محورها اغلب با شاخصهایشان مورد اشاره قرار میگیرند، همیشه باید معنای هر کدام را دنبال کنید. غالباً محورها از جهانی به محلی مرتب می شوند: ابتدا محور دسته ای و سپس ابعاد فضایی و ویژگی های هر مکان پایان می یابد. به این ترتیب بردارهای ویژگی، مناطق به هم پیوسته حافظه هستند.
| ترتیب محورهای معمولی |
|---|
 |
نمایه سازی
نمایه سازی تک محوری
TensorFlow از قوانین نمایه سازی استاندارد پایتون، مشابه فهرست کردن یک لیست یا یک رشته در پایتون ، و قوانین اساسی برای نمایه سازی NumPy پیروی می کند.
- شاخص ها از
0شروع می شوند - شاخص های منفی از انتها معکوس می شمارند
- دو نقطه،
:، برای برش ها استفاده می شود:start:stop:step
rank_1_tensor = tf.constant([0, 1, 1, 2, 3, 5, 8, 13, 21, 34])
print(rank_1_tensor.numpy())
[ 0 1 1 2 3 5 8 13 21 34]
نمایه سازی با اسکالر محور را حذف می کند:
print("First:", rank_1_tensor[0].numpy())
print("Second:", rank_1_tensor[1].numpy())
print("Last:", rank_1_tensor[-1].numpy())
First: 0 Second: 1 Last: 34
نمایه سازی با : slice محور را حفظ می کند:
print("Everything:", rank_1_tensor[:].numpy())
print("Before 4:", rank_1_tensor[:4].numpy())
print("From 4 to the end:", rank_1_tensor[4:].numpy())
print("From 2, before 7:", rank_1_tensor[2:7].numpy())
print("Every other item:", rank_1_tensor[::2].numpy())
print("Reversed:", rank_1_tensor[::-1].numpy())
Everything: [ 0 1 1 2 3 5 8 13 21 34] Before 4: [0 1 1 2] From 4 to the end: [ 3 5 8 13 21 34] From 2, before 7: [1 2 3 5 8] Every other item: [ 0 1 3 8 21] Reversed: [34 21 13 8 5 3 2 1 1 0]
نمایه سازی چند محوری
تانسورهای رتبه بالاتر با عبور از چند شاخص نمایه می شوند.
دقیقاً همان قوانینی که در مورد تک محوری وجود دارد برای هر محور به طور مستقل اعمال می شود.
print(rank_2_tensor.numpy())
[[1. 2.] [3. 4.] [5. 6.]]
با ارسال یک عدد صحیح برای هر شاخص، نتیجه یک عدد اسکالر است.
# Pull out a single value from a 2-rank tensor
print(rank_2_tensor[1, 1].numpy())
4.0
می توانید با استفاده از هر ترکیبی از اعداد صحیح و برش ها ایندکس کنید:
# Get row and column tensors
print("Second row:", rank_2_tensor[1, :].numpy())
print("Second column:", rank_2_tensor[:, 1].numpy())
print("Last row:", rank_2_tensor[-1, :].numpy())
print("First item in last column:", rank_2_tensor[0, -1].numpy())
print("Skip the first row:")
print(rank_2_tensor[1:, :].numpy(), "\n")
Second row: [3. 4.] Second column: [2. 4. 6.] Last row: [5. 6.] First item in last column: 2.0 Skip the first row: [[3. 4.] [5. 6.]]
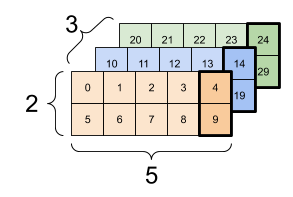
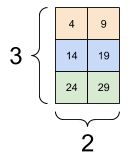
در اینجا یک مثال با یک تانسور 3 محور است:
print(rank_3_tensor[:, :, 4])
tf.Tensor( [[ 4 9] [14 19] [24 29]], shape=(3, 2), dtype=int32)
| انتخاب آخرین ویژگی در همه مکانها در هر نمونه در دسته | |
|---|---|
 |  |
راهنمای برش تانسور را بخوانید تا بیاموزید چگونه میتوانید نمایهسازی را برای دستکاری عناصر جداگانه در تانسورها اعمال کنید.
دستکاری اشکال
تغییر شکل یک تانسور بسیار مفید است.
# Shape returns a `TensorShape` object that shows the size along each axis
x = tf.constant([[1], [2], [3]])
print(x.shape)
(3, 1)
# You can convert this object into a Python list, too
print(x.shape.as_list())
[3, 1]
می توانید یک تانسور را به شکل جدیدی تغییر شکل دهید. عملیات tf.reshape سریع و ارزان است زیرا دادههای زیربنایی نیازی به تکرار ندارند.
# You can reshape a tensor to a new shape.
# Note that you're passing in a list
reshaped = tf.reshape(x, [1, 3])
print(x.shape)
print(reshaped.shape)
(3, 1) (1, 3)
داده ها طرح خود را در حافظه حفظ می کنند و یک تانسور جدید با شکل درخواستی ایجاد می شود که به همان داده اشاره می کند. TensorFlow از ترتیب حافظه "ردیف اصلی" به سبک C استفاده می کند، جایی که افزایش شاخص سمت راست با یک مرحله در حافظه مطابقت دارد.
print(rank_3_tensor)
tf.Tensor( [[[ 0 1 2 3 4] [ 5 6 7 8 9]] [[10 11 12 13 14] [15 16 17 18 19]] [[20 21 22 23 24] [25 26 27 28 29]]], shape=(3, 2, 5), dtype=int32)
اگر یک تانسور را صاف کنید، می توانید ببینید که چه ترتیبی در حافظه گذاشته شده است.
# A `-1` passed in the `shape` argument says "Whatever fits".
print(tf.reshape(rank_3_tensor, [-1]))
tf.Tensor( [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29], shape=(30,), dtype=int32)
معمولاً تنها استفاده معقول از tf.reshape ترکیب یا تقسیم محورهای مجاور (یا افزودن/حذف 1 ثانیه) است.
برای این تانسور 3x2x5، تغییر شکل به (3x2)x5 یا 3x(2x5) هر دو کار منطقی هستند، زیرا برش ها با هم مخلوط نمی شوند:
print(tf.reshape(rank_3_tensor, [3*2, 5]), "\n")
print(tf.reshape(rank_3_tensor, [3, -1]))
tf.Tensor( [[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14] [15 16 17 18 19] [20 21 22 23 24] [25 26 27 28 29]], shape=(6, 5), dtype=int32) tf.Tensor( [[ 0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29]], shape=(3, 10), dtype=int32)
| چند تغییر شکل خوب | ||
|---|---|---|
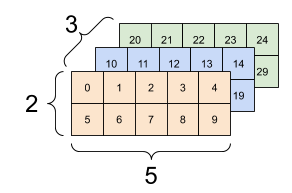 |  | 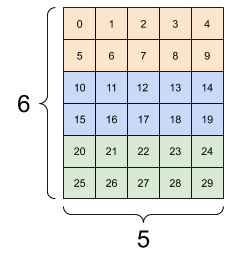 |
تغییر شکل برای هر شکل جدید با تعداد کل عناصر یکسان "کار می کند"، اما اگر ترتیب محورها را رعایت نکنید، کار مفیدی نخواهد داشت.
تعویض محورها در tf.reshape کار نمی کند. برای آن به tf.transpose نیاز دارید.
# Bad examples: don't do this
# You can't reorder axes with reshape.
print(tf.reshape(rank_3_tensor, [2, 3, 5]), "\n")
# This is a mess
print(tf.reshape(rank_3_tensor, [5, 6]), "\n")
# This doesn't work at all
try:
tf.reshape(rank_3_tensor, [7, -1])
except Exception as e:
print(f"{type(e).__name__}: {e}")
tf.Tensor( [[[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14]] [[15 16 17 18 19] [20 21 22 23 24] [25 26 27 28 29]]], shape=(2, 3, 5), dtype=int32) tf.Tensor( [[ 0 1 2 3 4 5] [ 6 7 8 9 10 11] [12 13 14 15 16 17] [18 19 20 21 22 23] [24 25 26 27 28 29]], shape=(5, 6), dtype=int32) InvalidArgumentError: Input to reshape is a tensor with 30 values, but the requested shape requires a multiple of 7 [Op:Reshape]
| چند تغییر شکل بد | ||
|---|---|---|
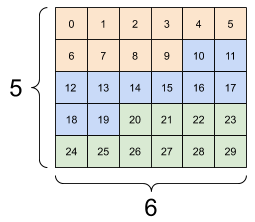 | 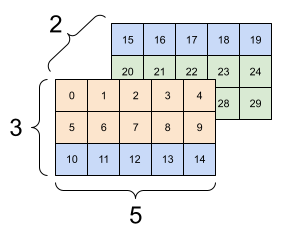 |  |
ممکن است در اشکال کاملاً مشخص نشده اجرا شوید. یا شکل حاوی یک None است (طول محور ناشناخته است) یا کل شکل None است (رتبه تانسور ناشناخته است).
به جز tf.RaggedTensor ، چنین اشکالی فقط در زمینه APIهای نمادین و گراف ساز TensorFlow رخ می دهند:
اطلاعات بیشتر در مورد DTypes
برای بررسی نوع داده tf.Tensor از ویژگی Tensor.dtype استفاده کنید.
هنگام ایجاد یک tf.Tensor از یک شی پایتون، می توانید به صورت اختیاری نوع داده را مشخص کنید.
اگر این کار را نکنید، TensorFlow یک نوع داده را انتخاب می کند که می تواند داده های شما را نشان دهد. TensorFlow اعداد صحیح پایتون را به tf.int32 و اعداد ممیز شناور پایتون را به tf.float32 می کند. در غیر این صورت TensorFlow از همان قوانینی استفاده می کند که NumPy هنگام تبدیل به آرایه ها استفاده می کند.
شما می توانید از نوع به نوع دیگر ارسال کنید.
the_f64_tensor = tf.constant([2.2, 3.3, 4.4], dtype=tf.float64)
the_f16_tensor = tf.cast(the_f64_tensor, dtype=tf.float16)
# Now, cast to an uint8 and lose the decimal precision
the_u8_tensor = tf.cast(the_f16_tensor, dtype=tf.uint8)
print(the_u8_tensor)
tf.Tensor([2 3 4], shape=(3,), dtype=uint8)
صدا و سیما
پخش مفهومی است که از ویژگی معادل در NumPy به عاریت گرفته شده است. به طور خلاصه، تحت شرایط خاص، تانسورهای کوچکتر به طور خودکار "کشیده" می شوند تا در هنگام اجرای عملیات ترکیبی بر روی تانسورهای بزرگتر قرار بگیرند.
ساده ترین و رایج ترین مورد زمانی است که شما سعی می کنید یک تانسور را به یک اسکالر ضرب یا اضافه کنید. در آن صورت، اسکالر به همان شکل آرگومان دیگر پخش میشود.
x = tf.constant([1, 2, 3])
y = tf.constant(2)
z = tf.constant([2, 2, 2])
# All of these are the same computation
print(tf.multiply(x, 2))
print(x * y)
print(x * z)
tf.Tensor([2 4 6], shape=(3,), dtype=int32) tf.Tensor([2 4 6], shape=(3,), dtype=int32) tf.Tensor([2 4 6], shape=(3,), dtype=int32)
به همین ترتیب، محورهای با طول 1 را می توان برای مطابقت با آرگومان های دیگر گسترش داد. هر دو آرگومان می توانند در یک محاسبات کشیده شوند.
در این مورد یک ماتریس 3x1 از نظر عنصر در یک ماتریس 1x4 ضرب می شود تا یک ماتریس 3x4 تولید شود. توجه داشته باشید که چگونه 1 پیشرو اختیاری است: شکل y [4] است.
# These are the same computations
x = tf.reshape(x,[3,1])
y = tf.range(1, 5)
print(x, "\n")
print(y, "\n")
print(tf.multiply(x, y))
tf.Tensor( [[1] [2] [3]], shape=(3, 1), dtype=int32) tf.Tensor([1 2 3 4], shape=(4,), dtype=int32) tf.Tensor( [[ 1 2 3 4] [ 2 4 6 8] [ 3 6 9 12]], shape=(3, 4), dtype=int32)
یک اضافه پخش شده: a [3, 1] بار [1, 4] یک [3,4] می دهد. |
|---|
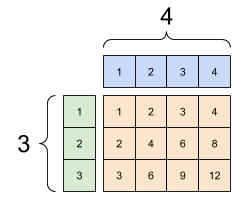 |
در اینجا همان عملیات بدون پخش است:
x_stretch = tf.constant([[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]])
y_stretch = tf.constant([[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]])
print(x_stretch * y_stretch) # Again, operator overloading
tf.Tensor( [[ 1 2 3 4] [ 2 4 6 8] [ 3 6 9 12]], shape=(3, 4), dtype=int32)
در بیشتر مواقع، پخش هم زمان و هم در مکان کارآمد است، زیرا عملیات پخش هرگز تانسورهای منبسط شده در حافظه را تحقق نمیبخشد.
می بینید که پخش با استفاده از tf.broadcast_to به نظر می رسد.
print(tf.broadcast_to(tf.constant([1, 2, 3]), [3, 3]))
tf.Tensor( [[1 2 3] [1 2 3] [1 2 3]], shape=(3, 3), dtype=int32)
بر خلاف یک عملیات ریاضی، برای مثال، broadcast_to هیچ کار خاصی برای صرفه جویی در حافظه انجام نمی دهد. در اینجا، شما تانسور را مادی می کنید.
می تواند حتی پیچیده تر شود. این بخش از کتاب Jake VanderPlas کتاب Python Data Science Handbook ترفندهای پخش بیشتری را نشان می دهد (دوباره در NumPy).
tf.convert_to_tensor
اکثر عملیاتها مانند tf.matmul و tf.reshape آرگومانهای کلاس tf.Tensor را میگیرند. با این حال، متوجه خواهید شد که در مورد بالا، اشیاء پایتون به شکل تانسور پذیرفته می شوند.
بیشتر، اما نه همه، عملیات ها convert_to_tensor را روی آرگومان های غیر تانسور فراخوانی می کنند. یک رجیستری از تبدیل ها وجود دارد و اکثر کلاس های شی مانند ndarray NumPy، TensorShape ، لیست های Python و tf.Variable همگی به طور خودکار تبدیل می شوند.
برای جزئیات بیشتر به tf.register_tensor_conversion_function مراجعه کنید، و اگر نوع خود را دارید میخواهید به طور خودکار به تانسور تبدیل کنید.
تانسورهای پاره پاره
یک تانسور با تعداد متغیر عناصر در امتداد برخی از محورها "راگ" نامیده می شود. برای داده های ناهموار از tf.ragged.RaggedTensor استفاده کنید.
به عنوان مثال، این را نمی توان به عنوان یک تانسور منظم نشان داد:
یک tf.RaggedTensor ، شکل: [4, None] |
|---|
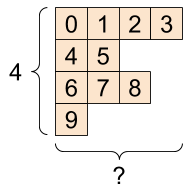 |
ragged_list = [
[0, 1, 2, 3],
[4, 5],
[6, 7, 8],
[9]]
try:
tensor = tf.constant(ragged_list)
except Exception as e:
print(f"{type(e).__name__}: {e}")
ValueError: Can't convert non-rectangular Python sequence to Tensor.
به جای آن یک tf.RaggedTensor با استفاده از tf.ragged.constant ایجاد کنید:
ragged_tensor = tf.ragged.constant(ragged_list)
print(ragged_tensor)
<tf.RaggedTensor [[0, 1, 2, 3], [4, 5], [6, 7, 8], [9]]>
شکل یک tf.RaggedTensor شامل چند محور با طول ناشناخته است:
print(ragged_tensor.shape)
(4, None)
تانسورهای رشته ای
tf.string یک نوع dtype است، یعنی میتوانید دادهها را به صورت رشتهها (آرایههای بایت با طول متغیر) در تانسورها نشان دهید.
رشته ها اتمی هستند و نمی توان مانند رشته های پایتون ایندکس کرد. طول رشته یکی از محورهای تانسور نیست. برای دستکاری توابع به tf.strings مراجعه کنید.
در اینجا یک تانسور رشته اسکالر وجود دارد:
# Tensors can be strings, too here is a scalar string.
scalar_string_tensor = tf.constant("Gray wolf")
print(scalar_string_tensor)
tf.Tensor(b'Gray wolf', shape=(), dtype=string)
و بردار رشته ها:
بردار رشته ها، شکل: [3,] |
|---|
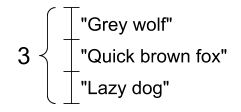 |
# If you have three string tensors of different lengths, this is OK.
tensor_of_strings = tf.constant(["Gray wolf",
"Quick brown fox",
"Lazy dog"])
# Note that the shape is (3,). The string length is not included.
print(tensor_of_strings)
tf.Tensor([b'Gray wolf' b'Quick brown fox' b'Lazy dog'], shape=(3,), dtype=string)
در چاپ بالا، پیشوند b نشان می دهد که tf.string dtype یک رشته یونیکد نیست، بلکه یک رشته بایت است. برای اطلاعات بیشتر در مورد کار با متن یونیکد در TensorFlow به آموزش یونیکد مراجعه کنید.
اگر کاراکترهای یونیکد را پاس کنید، utf-8 کدگذاری شده اند.
tf.constant("🥳👍")
<tf.Tensor: shape=(), dtype=string, numpy=b'\xf0\x9f\xa5\xb3\xf0\x9f\x91\x8d'>
برخی از توابع اساسی با رشته ها را می توان در tf.strings یافت، از جمله tf.strings.split .
# You can use split to split a string into a set of tensors
print(tf.strings.split(scalar_string_tensor, sep=" "))
tf.Tensor([b'Gray' b'wolf'], shape=(2,), dtype=string)
# ...but it turns into a `RaggedTensor` if you split up a tensor of strings,
# as each string might be split into a different number of parts.
print(tf.strings.split(tensor_of_strings))
<tf.RaggedTensor [[b'Gray', b'wolf'], [b'Quick', b'brown', b'fox'], [b'Lazy', b'dog']]>
سه رشته تقسیم شده، شکل: [3, None] |
|---|
 |
و tf.string.to_number :
text = tf.constant("1 10 100")
print(tf.strings.to_number(tf.strings.split(text, " ")))
tf.Tensor([ 1. 10. 100.], shape=(3,), dtype=float32)
اگرچه نمیتوانید از tf.cast برای تبدیل تانسور رشتهای به عدد استفاده کنید، میتوانید آن را به بایت و سپس به عدد تبدیل کنید.
byte_strings = tf.strings.bytes_split(tf.constant("Duck"))
byte_ints = tf.io.decode_raw(tf.constant("Duck"), tf.uint8)
print("Byte strings:", byte_strings)
print("Bytes:", byte_ints)
Byte strings: tf.Tensor([b'D' b'u' b'c' b'k'], shape=(4,), dtype=string) Bytes: tf.Tensor([ 68 117 99 107], shape=(4,), dtype=uint8)
# Or split it up as unicode and then decode it
unicode_bytes = tf.constant("アヒル 🦆")
unicode_char_bytes = tf.strings.unicode_split(unicode_bytes, "UTF-8")
unicode_values = tf.strings.unicode_decode(unicode_bytes, "UTF-8")
print("\nUnicode bytes:", unicode_bytes)
print("\nUnicode chars:", unicode_char_bytes)
print("\nUnicode values:", unicode_values)
Unicode bytes: tf.Tensor(b'\xe3\x82\xa2\xe3\x83\x92\xe3\x83\xab \xf0\x9f\xa6\x86', shape=(), dtype=string) Unicode chars: tf.Tensor([b'\xe3\x82\xa2' b'\xe3\x83\x92' b'\xe3\x83\xab' b' ' b'\xf0\x9f\xa6\x86'], shape=(5,), dtype=string) Unicode values: tf.Tensor([ 12450 12498 12523 32 129414], shape=(5,), dtype=int32)
tf.string dtype برای تمام داده های بایت خام در TensorFlow استفاده می شود. ماژول tf.io شامل توابعی برای تبدیل داده به بایت و از بایت است، از جمله رمزگشایی تصاویر و تجزیه csv.
تانسورهای پراکنده
گاهی اوقات، داده های شما پراکنده هستند، مانند یک فضای جاسازی بسیار گسترده. TensorFlow از tf.sparse.SparseTensor و عملیات مربوطه برای ذخیره کارآمد داده های پراکنده پشتیبانی می کند.
A tf.SparseTensor ، شکل: [3, 4] |
|---|
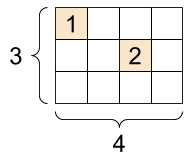 |
# Sparse tensors store values by index in a memory-efficient manner
sparse_tensor = tf.sparse.SparseTensor(indices=[[0, 0], [1, 2]],
values=[1, 2],
dense_shape=[3, 4])
print(sparse_tensor, "\n")
# You can convert sparse tensors to dense
print(tf.sparse.to_dense(sparse_tensor))
SparseTensor(indices=tf.Tensor( [[0 0] [1 2]], shape=(2, 2), dtype=int64), values=tf.Tensor([1 2], shape=(2,), dtype=int32), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64)) tf.Tensor( [[1 0 0 0] [0 0 2 0] [0 0 0 0]], shape=(3, 4), dtype=int32)