ML flexible, contrôlé et interprétable avec des modèles basés sur des réseaux
import numpy as np import tensorflow as tf import tensorflow_lattice as tfl model = tf.keras.models.Sequential() model.add( tfl.layers.ParallelCombination([ # Monotonic piece-wise linear calibration with bounded output tfl.layers.PWLCalibration( monotonicity='increasing', input_keypoints=np.linspace(1., 5., num=20), output_min=0.0, output_max=1.0), # Diminishing returns tfl.layers.PWLCalibration( monotonicity='increasing', convexity='concave', input_keypoints=np.linspace(0., 200., num=20), output_min=0.0, output_max=2.0), # Partially monotonic categorical calibration: calib(0) <= calib(1) tfl.layers.CategoricalCalibration( num_buckets=4, output_min=0.0, output_max=1.0, monotonicities=[(0, 1)]), ])) model.add( tfl.layers.Lattice( lattice_sizes=[2, 3, 2], monotonicities=['increasing', 'increasing', 'increasing'], # Trust: model is more responsive to input 0 if input 1 increases edgeworth_trusts=(0, 1, 'positive'))) model.compile(...)
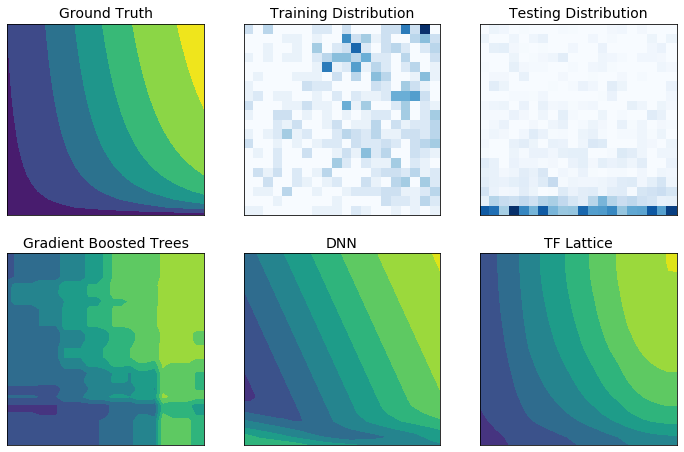
TensorFlow Lattice est une bibliothèque qui implémente des modèles contraints et interprétables basés sur des réseaux. Cette bibliothèque vous permet d'injecter la connaissance du domaine dans le processus d'apprentissage par l'intermédiaire de contraintes de forme basées sur le bon sens ou sur des règles. Cela passe par l'utilisation d'un ensemble de couches Keras qui peuvent satisfaire des contraintes telles que la monotonie, la convexité et les interactions entre les caractéristiques. La bibliothèque fournit également des modèles prédéfinis et des Estimators standardisés faciles à configurer.
TF Lattice vous permet d'utiliser la connaissance du domaine pour mieux extrapoler les parties de l'espace d'entrée non couvertes par l'ensemble de données d'entraînement. Cela permet d'éviter un comportement inattendu du modèle lorsque la distribution d'inférence est différente de la distribution d'entraînement.