
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Aperçu
Les estimateurs prédéfinis sont des moyens rapides et faciles de former des modèles TFL pour des cas d'utilisation typiques. Ce guide décrit les étapes nécessaires pour créer un estimateur TFL en conserve.
Installer
Installation du package TF Lattice :
pip install tensorflow-lattice
Importation des packages requis :
import tensorflow as tf
import copy
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
from tensorflow import feature_column as fc
logging.disable(sys.maxsize)
Téléchargement du jeu de données UCI Statlog (Heart) :
csv_file = tf.keras.utils.get_file(
'heart.csv', 'http://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
df = pd.read_csv(csv_file)
target = df.pop('target')
train_size = int(len(df) * 0.8)
train_x = df[:train_size]
train_y = target[:train_size]
test_x = df[train_size:]
test_y = target[train_size:]
df.head()
Définition des valeurs par défaut utilisées pour la formation dans ce guide :
LEARNING_RATE = 0.01
BATCH_SIZE = 128
NUM_EPOCHS = 500
PREFITTING_NUM_EPOCHS = 10
Colonnes de fonction
Comme pour tout autre estimateur de TF, les données doivent être transmises à l'estimateur, qui est typiquement via un input_fn et analysés en utilisant FeatureColumns .
# Feature columns.
# - age
# - sex
# - cp chest pain type (4 values)
# - trestbps resting blood pressure
# - chol serum cholestoral in mg/dl
# - fbs fasting blood sugar > 120 mg/dl
# - restecg resting electrocardiographic results (values 0,1,2)
# - thalach maximum heart rate achieved
# - exang exercise induced angina
# - oldpeak ST depression induced by exercise relative to rest
# - slope the slope of the peak exercise ST segment
# - ca number of major vessels (0-3) colored by flourosopy
# - thal 3 = normal; 6 = fixed defect; 7 = reversable defect
feature_columns = [
fc.numeric_column('age', default_value=-1),
fc.categorical_column_with_vocabulary_list('sex', [0, 1]),
fc.numeric_column('cp'),
fc.numeric_column('trestbps', default_value=-1),
fc.numeric_column('chol'),
fc.categorical_column_with_vocabulary_list('fbs', [0, 1]),
fc.categorical_column_with_vocabulary_list('restecg', [0, 1, 2]),
fc.numeric_column('thalach'),
fc.categorical_column_with_vocabulary_list('exang', [0, 1]),
fc.numeric_column('oldpeak'),
fc.categorical_column_with_vocabulary_list('slope', [0, 1, 2]),
fc.numeric_column('ca'),
fc.categorical_column_with_vocabulary_list(
'thal', ['normal', 'fixed', 'reversible']),
]
Les estimateurs prédéfinis TFL utilisent le type de colonne d'entités pour décider du type de couche d'étalonnage à utiliser. Nous utilisons une tfl.layers.PWLCalibration couche pour les colonnes de caractéristiques numériques et une tfl.layers.CategoricalCalibration couche pour les colonnes de caractéristiques catégoriques.
Notez que les colonnes de caractéristiques catégorielles ne sont pas enveloppées par une colonne de caractéristiques d'incorporation. Ils sont directement introduits dans l'estimateur.
Création de input_fn
Comme pour tout autre estimateur, vous pouvez utiliser un input_fn pour alimenter le modèle en données pour l'apprentissage et l'évaluation. Les estimateurs TFL peuvent calculer automatiquement les quantiles des entités et les utiliser comme points clés d'entrée pour la couche d'étalonnage PWL. Pour ce faire, ils exigent le passage d' un feature_analysis_input_fn , qui est similaire à la formation input_fn mais avec une seule époque ou d' un sous - échantillon des données.
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
num_threads=1)
# feature_analysis_input_fn is used to collect statistics about the input.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
# Note that we only need one pass over the data.
num_epochs=1,
num_threads=1)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=test_x,
y=test_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=1,
num_threads=1)
# Serving input fn is used to create saved models.
serving_input_fn = (
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=fc.make_parse_example_spec(feature_columns)))
Configurations de fonctionnalités
Étalonnage des fonctionnalités et configurations par-fonction sont définies à l' aide tfl.configs.FeatureConfig . Configurations de fonction comprennent les contraintes de régularisation, par monotonicité-fonction (voir tfl.configs.RegularizerConfig ) et tailles treillis pour les modèles treillis.
Si aucune configuration est définie pour une fonction d'entrée, la configuration par défaut dans tfl.config.FeatureConfig est utilisé.
# Feature configs are used to specify how each feature is calibrated and used.
feature_configs = [
tfl.configs.FeatureConfig(
name='age',
lattice_size=3,
# By default, input keypoints of pwl are quantiles of the feature.
pwl_calibration_num_keypoints=5,
monotonicity='increasing',
pwl_calibration_clip_max=100,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_wrinkle', l2=0.1),
],
),
tfl.configs.FeatureConfig(
name='cp',
pwl_calibration_num_keypoints=4,
# Keypoints can be uniformly spaced.
pwl_calibration_input_keypoints='uniform',
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='chol',
# Explicit input keypoint initialization.
pwl_calibration_input_keypoints=[126.0, 210.0, 247.0, 286.0, 564.0],
monotonicity='increasing',
# Calibration can be forced to span the full output range by clamping.
pwl_calibration_clamp_min=True,
pwl_calibration_clamp_max=True,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
],
),
tfl.configs.FeatureConfig(
name='fbs',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
),
tfl.configs.FeatureConfig(
name='trestbps',
pwl_calibration_num_keypoints=5,
monotonicity='decreasing',
),
tfl.configs.FeatureConfig(
name='thalach',
pwl_calibration_num_keypoints=5,
monotonicity='decreasing',
),
tfl.configs.FeatureConfig(
name='restecg',
# Partial monotonicity: output(0) <= output(1), output(0) <= output(2)
monotonicity=[(0, 1), (0, 2)],
),
tfl.configs.FeatureConfig(
name='exang',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
),
tfl.configs.FeatureConfig(
name='oldpeak',
pwl_calibration_num_keypoints=5,
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='slope',
# Partial monotonicity: output(0) <= output(1), output(1) <= output(2)
monotonicity=[(0, 1), (1, 2)],
),
tfl.configs.FeatureConfig(
name='ca',
pwl_calibration_num_keypoints=4,
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='thal',
# Partial monotonicity:
# output(normal) <= output(fixed)
# output(normal) <= output(reversible)
monotonicity=[('normal', 'fixed'), ('normal', 'reversible')],
),
]
Modèle linéaire calibré
Pour construire un estimateur mis en conserve TFL, construire une configuration de modèle à partir tfl.configs . Un modèle linéaire calibrée est construit en utilisant tfl.configs.CalibratedLinearConfig . Il applique un étalonnage linéaire par morceaux et catégoriel sur les caractéristiques d'entrée, suivi d'une combinaison linéaire et d'un étalonnage linéaire par morceaux de sortie en option. Lors de l'utilisation de l'étalonnage de sortie ou lorsque des limites de sortie sont spécifiées, la couche linéaire applique une moyenne pondérée sur les entrées calibrées.
Cet exemple crée un modèle linéaire calibré sur les 5 premières entités. Nous utilisons tfl.visualization pour tracer le graphique du modèle avec les parcelles calibrateur.
# Model config defines the model structure for the estimator.
model_config = tfl.configs.CalibratedLinearConfig(
feature_configs=feature_configs,
use_bias=True,
output_calibration=True,
regularizer_configs=[
# Regularizer for the output calibrator.
tfl.configs.RegularizerConfig(name='output_calib_hessian', l2=1e-4),
])
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns[:5],
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Calibrated linear test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph)
2021-09-30 20:54:06.660239: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected Calibrated linear test AUC: 0.834586501121521
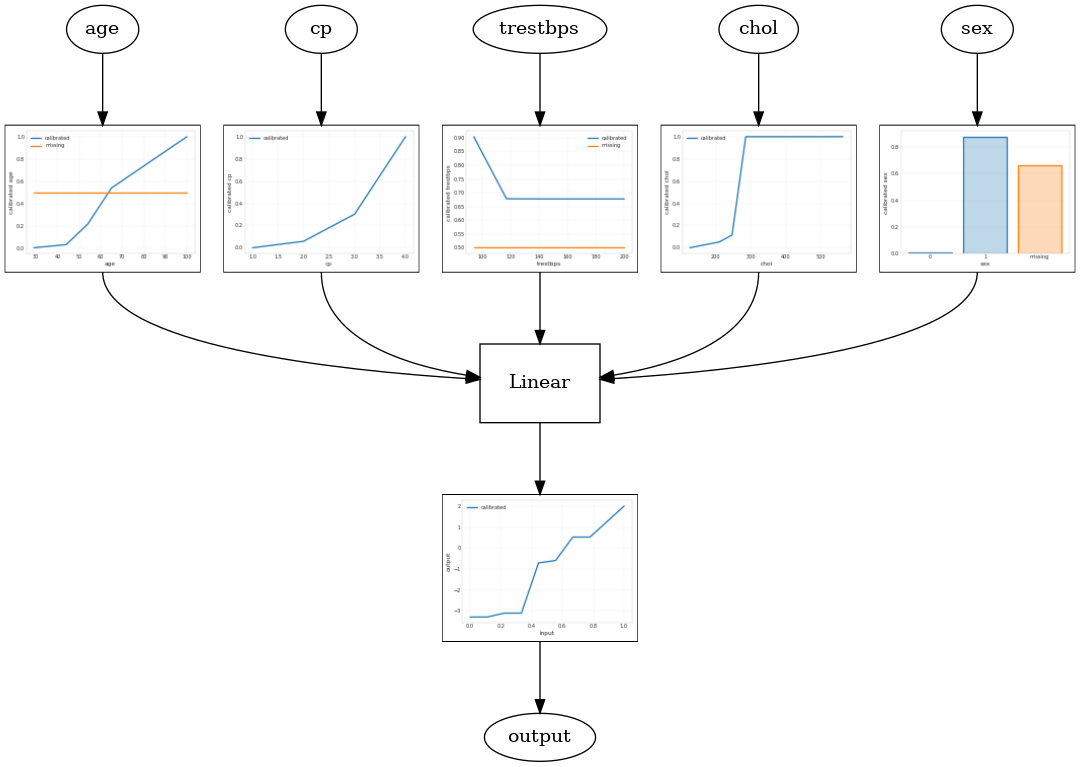
Modèle de treillis calibré
Un modèle calibré treillis est construit en utilisant tfl.configs.CalibratedLatticeConfig . Un modèle de réseau calibré applique un étalonnage linéaire par morceaux et catégoriel sur les entités en entrée, suivi d'un modèle de réseau et d'un étalonnage linéaire par morceaux de sortie en option.
Cet exemple crée un modèle de réseau calibré sur les 5 premières entités.
# This is calibrated lattice model: Inputs are calibrated, then combined
# non-linearly using a lattice layer.
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=feature_configs,
regularizer_configs=[
# Torsion regularizer applied to the lattice to make it more linear.
tfl.configs.RegularizerConfig(name='torsion', l2=1e-4),
# Globally defined calibration regularizer is applied to all features.
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
])
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns[:5],
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Calibrated lattice test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph)
Calibrated lattice test AUC: 0.8427318930625916
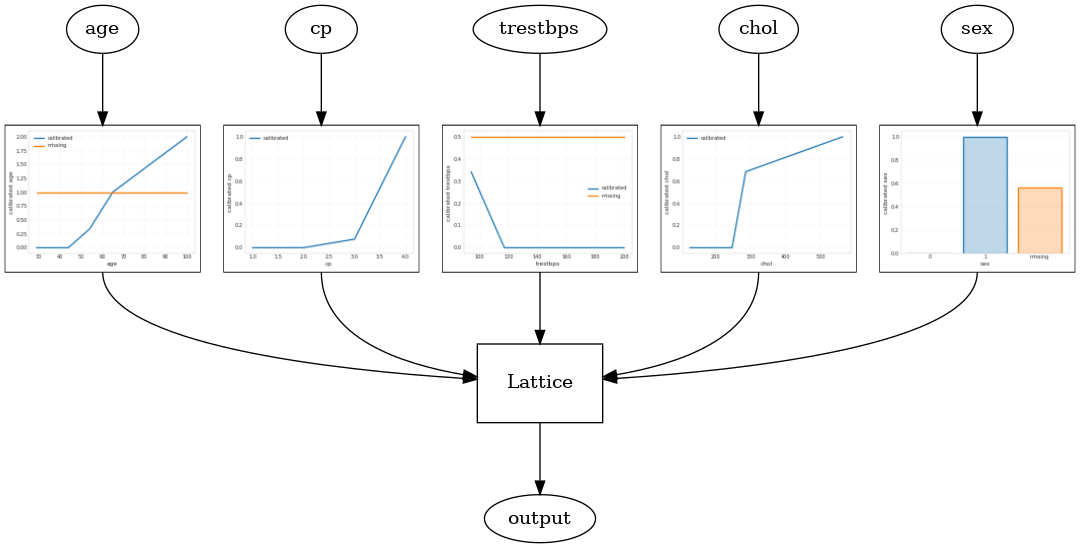
Ensemble de treillis calibré
Lorsque le nombre d'entités est important, vous pouvez utiliser un modèle d'ensemble, qui crée plusieurs réseaux plus petits pour des sous-ensembles d'entités et fait la moyenne de leur sortie au lieu de créer un seul grand réseau. Modèles de treillis Ensemble sont construits à l' aide tfl.configs.CalibratedLatticeEnsembleConfig . Un modèle d'ensemble de réseau calibré applique un étalonnage linéaire par morceaux et catégoriel sur l'entité en entrée, suivi d'un ensemble de modèles de réseau et d'un étalonnage linéaire par morceaux de sortie en option.
Ensemble de treillis aléatoire
La configuration de modèle suivante utilise un sous-ensemble aléatoire de fonctionnalités pour chaque réseau.
# This is random lattice ensemble model with separate calibration:
# model output is the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=feature_configs,
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Random ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
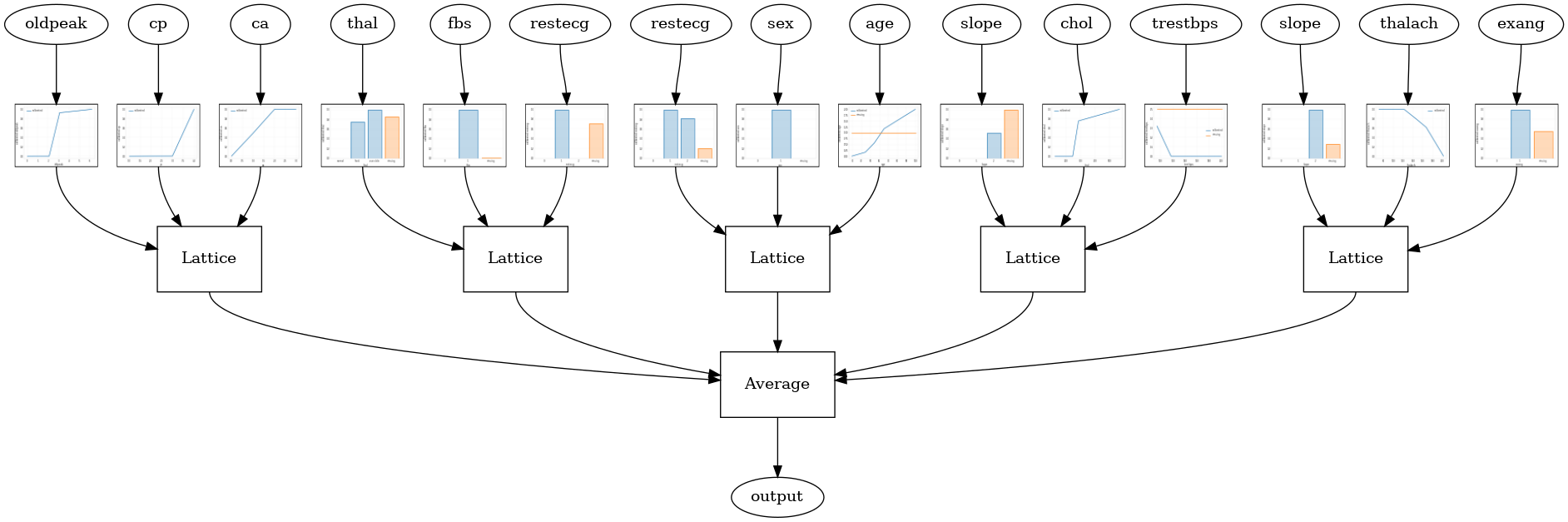
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Random ensemble test AUC: 0.9003759026527405
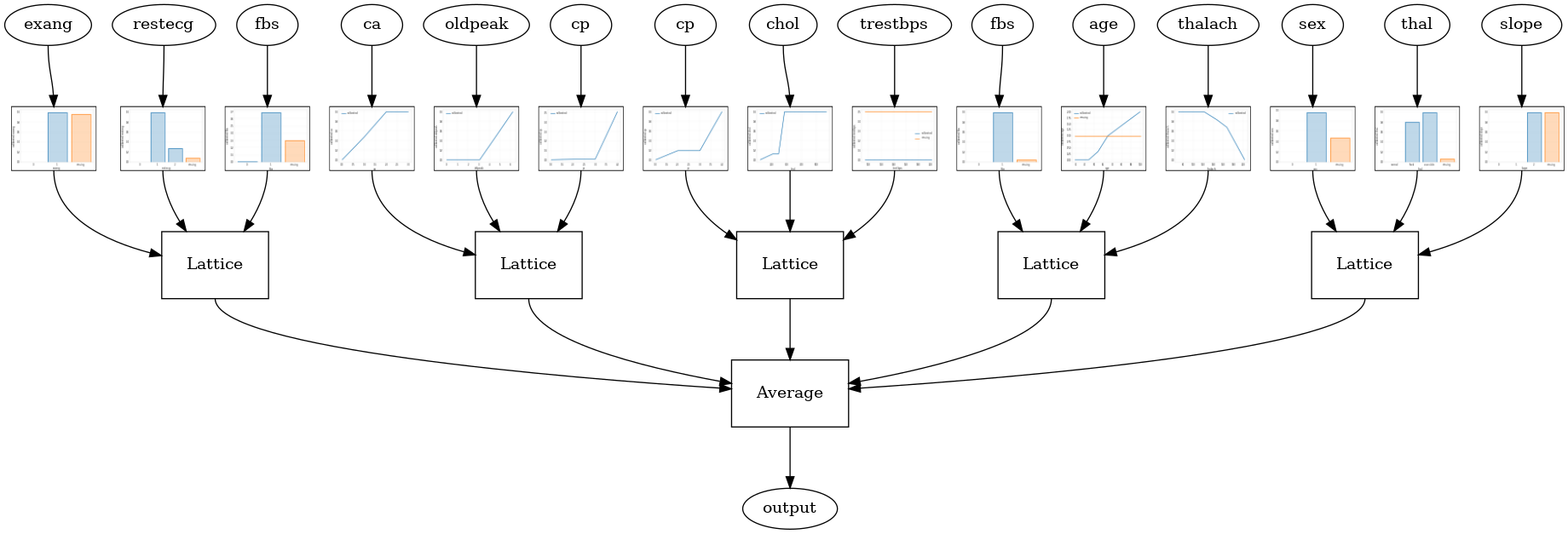
Ensemble RTL Layer Random Lattice
La configuration du modèle suivant utilise une tfl.layers.RTL couche qui utilise un sous - ensemble aléatoire de caractéristiques pour chaque treillis. Nous notons que tfl.layers.RTL ne supporte que les contraintes et doit avoir monotonicité la même taille de réseau pour toutes les fonctions et aucune régularisation par-fonction. Notez que l' utilisation d' une tfl.layers.RTL couche vous permet d' évoluer à des ensembles beaucoup plus que d' utiliser différents tfl.layers.Lattice cas.
# Make sure our feature configs have the same lattice size, no per-feature
# regularization, and only monotonicity constraints.
rtl_layer_feature_configs = copy.deepcopy(feature_configs)
for feature_config in rtl_layer_feature_configs:
feature_config.lattice_size = 2
feature_config.unimodality = 'none'
feature_config.reflects_trust_in = None
feature_config.dominates = None
feature_config.regularizer_configs = None
# This is RTL layer ensemble model with separate calibration:
# model output is the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
lattices='rtl_layer',
feature_configs=rtl_layer_feature_configs,
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Random ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Random ensemble test AUC: 0.8903509378433228
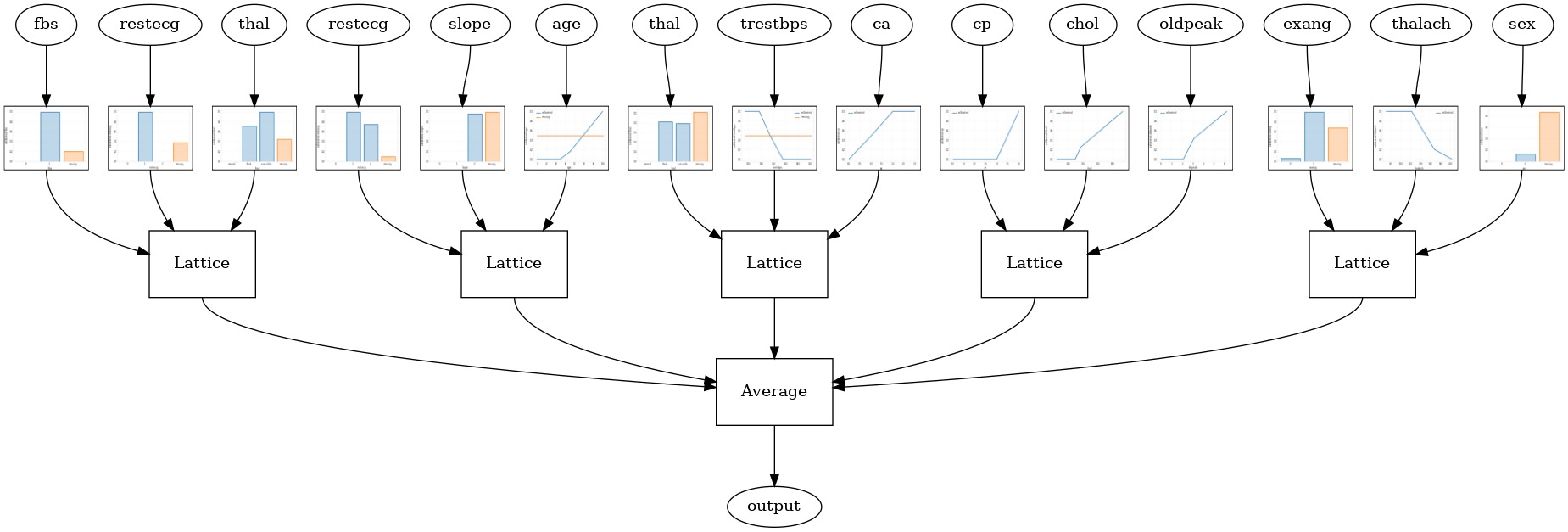
Ensemble de treillis de cristaux
TFL fournit également un algorithme d'arrangement de fonction heuristique, appelée cristaux . Les cristaux algorithme premiers trains un modèle que les estimations autoradio prémonté interactions caractéristique deux à deux. Il organise ensuite l'ensemble final de telle sorte que les entités avec plus d'interactions non linéaires se trouvent dans les mêmes réseaux.
Pour les modèles de cristaux, vous aurez également besoin de fournir un prefitting_input_fn qui est utilisé pour former le modèle autoradio prémonté, comme décrit ci - dessus. Le modèle de pré-ajustement n'a pas besoin d'être entièrement formé, donc quelques époques devraient suffire.
prefitting_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=PREFITTING_NUM_EPOCHS,
num_threads=1)
Vous pouvez ensuite créer un modèle de cristal en définissant lattice='crystals' dans la configuration du modèle.
# This is Crystals ensemble model with separate calibration: model output is
# the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=feature_configs,
lattices='crystals',
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
# prefitting_input_fn is required to train the prefitting model.
prefitting_input_fn=prefitting_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
prefitting_optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Crystals ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Crystals ensemble test AUC: 0.8840851783752441
Vous pouvez tracer des calibrateurs de fonctionnalités avec plus de détails à l' aide du tfl.visualization module.
_ = tfl.visualization.plot_feature_calibrator(model_graph, "age")
_ = tfl.visualization.plot_feature_calibrator(model_graph, "restecg")

