
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Aperçu
Les modèles sont Premade moyens rapides et faciles à construire TFL tf.keras.model cas pour les cas typiques d'utilisation. Ce guide décrit les étapes nécessaires pour construire un modèle TFL Premade et l'entraîner/tester.
Installer
Installation du package TF Lattice :
pip install tensorflow-lattice pydot
Importation des packages requis :
import tensorflow as tf
import copy
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Définition des valeurs par défaut utilisées pour la formation dans ce guide :
LEARNING_RATE = 0.01
BATCH_SIZE = 128
NUM_EPOCHS = 500
PREFITTING_NUM_EPOCHS = 10
Téléchargement du jeu de données UCI Statlog (Heart) :
heart_csv_file = tf.keras.utils.get_file(
'heart.csv',
'http://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
heart_df = pd.read_csv(heart_csv_file)
thal_vocab_list = ['normal', 'fixed', 'reversible']
heart_df['thal'] = heart_df['thal'].map(
{v: i for i, v in enumerate(thal_vocab_list)})
heart_df = heart_df.astype(float)
heart_train_size = int(len(heart_df) * 0.8)
heart_train_dict = dict(heart_df[:heart_train_size])
heart_test_dict = dict(heart_df[heart_train_size:])
# This ordering of input features should match the feature configs. If no
# feature config relies explicitly on the data (i.e. all are 'quantiles'),
# then you can construct the feature_names list by simply iterating over each
# feature config and extracting it's name.
feature_names = [
'age', 'sex', 'cp', 'chol', 'fbs', 'trestbps', 'thalach', 'restecg',
'exang', 'oldpeak', 'slope', 'ca', 'thal'
]
# Since we have some features that manually construct their input keypoints,
# we need an index mapping of the feature names.
feature_name_indices = {name: index for index, name in enumerate(feature_names)}
label_name = 'target'
heart_train_xs = [
heart_train_dict[feature_name] for feature_name in feature_names
]
heart_test_xs = [heart_test_dict[feature_name] for feature_name in feature_names]
heart_train_ys = heart_train_dict[label_name]
heart_test_ys = heart_test_dict[label_name]
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/heart.csv 16384/13273 [=====================================] - 0s 0us/step 24576/13273 [=======================================================] - 0s 0us/step
Configurations de fonctionnalités
Étalonnage des fonctionnalités et configurations par-fonction sont définies à l' aide tfl.configs.FeatureConfig . Configurations de fonction comprennent les contraintes de régularisation, par monotonicité-fonction (voir tfl.configs.RegularizerConfig ) et tailles treillis pour les modèles treillis.
Notez que nous devons spécifier complètement la configuration de la fonctionnalité pour toute fonctionnalité que nous voulons que notre modèle reconnaisse. Sinon, le modèle n'aura aucun moyen de savoir qu'une telle caractéristique existe.
Définir nos configurations de fonctionnalités
Maintenant que nous pouvons calculer nos quantiles, nous définissons une configuration de caractéristiques pour chaque caractéristique que nous voulons que notre modèle prenne en entrée.
# Features:
# - age
# - sex
# - cp chest pain type (4 values)
# - trestbps resting blood pressure
# - chol serum cholestoral in mg/dl
# - fbs fasting blood sugar > 120 mg/dl
# - restecg resting electrocardiographic results (values 0,1,2)
# - thalach maximum heart rate achieved
# - exang exercise induced angina
# - oldpeak ST depression induced by exercise relative to rest
# - slope the slope of the peak exercise ST segment
# - ca number of major vessels (0-3) colored by flourosopy
# - thal normal; fixed defect; reversable defect
#
# Feature configs are used to specify how each feature is calibrated and used.
heart_feature_configs = [
tfl.configs.FeatureConfig(
name='age',
lattice_size=3,
monotonicity='increasing',
# We must set the keypoints manually.
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
pwl_calibration_clip_max=100,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_wrinkle', l2=0.1),
],
),
tfl.configs.FeatureConfig(
name='sex',
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='cp',
monotonicity='increasing',
# Keypoints that are uniformly spaced.
pwl_calibration_num_keypoints=4,
pwl_calibration_input_keypoints=np.linspace(
np.min(heart_train_xs[feature_name_indices['cp']]),
np.max(heart_train_xs[feature_name_indices['cp']]),
num=4),
),
tfl.configs.FeatureConfig(
name='chol',
monotonicity='increasing',
# Explicit input keypoints initialization.
pwl_calibration_input_keypoints=[126.0, 210.0, 247.0, 286.0, 564.0],
# Calibration can be forced to span the full output range by clamping.
pwl_calibration_clamp_min=True,
pwl_calibration_clamp_max=True,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
],
),
tfl.configs.FeatureConfig(
name='fbs',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='trestbps',
monotonicity='decreasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='thalach',
monotonicity='decreasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='restecg',
# Partial monotonicity: output(0) <= output(1), output(0) <= output(2)
monotonicity=[(0, 1), (0, 2)],
num_buckets=3,
),
tfl.configs.FeatureConfig(
name='exang',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='oldpeak',
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='slope',
# Partial monotonicity: output(0) <= output(1), output(1) <= output(2)
monotonicity=[(0, 1), (1, 2)],
num_buckets=3,
),
tfl.configs.FeatureConfig(
name='ca',
monotonicity='increasing',
pwl_calibration_num_keypoints=4,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='thal',
# Partial monotonicity:
# output(normal) <= output(fixed)
# output(normal) <= output(reversible)
monotonicity=[('normal', 'fixed'), ('normal', 'reversible')],
num_buckets=3,
# We must specify the vocabulary list in order to later set the
# monotonicities since we used names and not indices.
vocabulary_list=thal_vocab_list,
),
]
Définir les monotonicités et les points clés
Ensuite, nous devons nous assurer de définir correctement les monotonicités pour les fonctionnalités pour lesquelles nous avons utilisé un vocabulaire personnalisé (tel que « thal » ci-dessus).
tfl.premade_lib.set_categorical_monotonicities(heart_feature_configs)
Enfin, nous pouvons compléter nos configurations de fonctionnalités en calculant et en définissant les points clés.
feature_keypoints = tfl.premade_lib.compute_feature_keypoints(
feature_configs=heart_feature_configs, features=heart_train_dict)
tfl.premade_lib.set_feature_keypoints(
feature_configs=heart_feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False)
Modèle linéaire calibré
Pour construire un modèle de premade TFL, d' abord construire une configuration de modèle à partir tfl.configs . Un modèle linéaire calibrée est construit en utilisant le tfl.configs.CalibratedLinearConfig . Il applique un étalonnage linéaire par morceaux et catégoriel sur les caractéristiques d'entrée, suivi d'une combinaison linéaire et d'un étalonnage linéaire par morceaux de sortie en option. Lors de l'utilisation de l'étalonnage de sortie ou lorsque des limites de sortie sont spécifiées, la couche linéaire applique une moyenne pondérée sur les entrées calibrées.
Cet exemple crée un modèle linéaire calibré sur les 5 premières entités.
# Model config defines the model structure for the premade model.
linear_model_config = tfl.configs.CalibratedLinearConfig(
feature_configs=heart_feature_configs[:5],
use_bias=True,
output_calibration=True,
output_calibration_num_keypoints=10,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=np.linspace(-2.0, 2.0, num=10),
regularizer_configs=[
# Regularizer for the output calibrator.
tfl.configs.RegularizerConfig(name='output_calib_hessian', l2=1e-4),
])
# A CalibratedLinear premade model constructed from the given model config.
linear_model = tfl.premade.CalibratedLinear(linear_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(linear_model, show_layer_names=False, rankdir='LR')
2022-01-14 12:36:31.295751: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
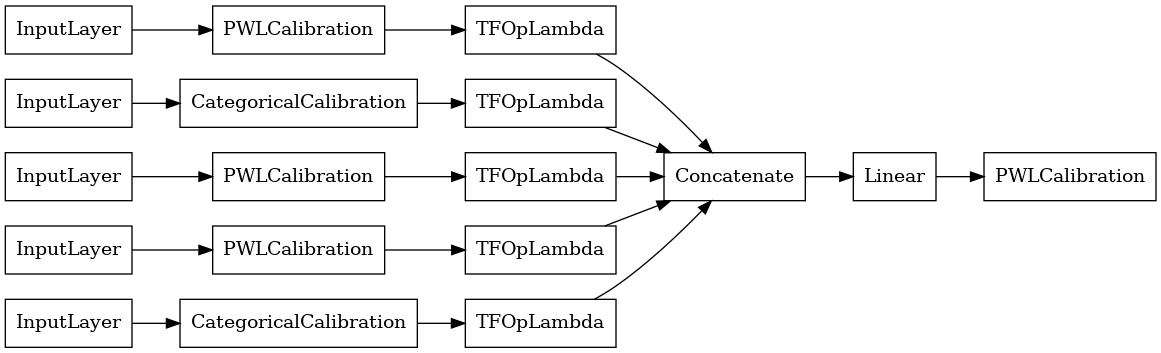
Maintenant, comme avec tout autre tf.keras.Model , nous compilons et ajuster le modèle à nos données.
linear_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
linear_model.fit(
heart_train_xs[:5],
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
<keras.callbacks.History at 0x7fe4385f0290>
Après avoir entraîné notre modèle, nous pouvons l'évaluer sur notre ensemble de test.
print('Test Set Evaluation...')
print(linear_model.evaluate(heart_test_xs[:5], heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 0s 3ms/step - loss: 0.4728 - auc: 0.8252 [0.47278329730033875, 0.8251879215240479]
Modèle de treillis calibré
Un modèle calibré treillis est construit en utilisant tfl.configs.CalibratedLatticeConfig . Un modèle de réseau calibré applique un étalonnage linéaire par morceaux et catégoriel sur les entités en entrée, suivi d'un modèle de réseau et d'un étalonnage linéaire par morceaux de sortie en option.
Cet exemple crée un modèle de réseau calibré sur les 5 premières entités.
# This is a calibrated lattice model: inputs are calibrated, then combined
# non-linearly using a lattice layer.
lattice_model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=heart_feature_configs[:5],
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
regularizer_configs=[
# Torsion regularizer applied to the lattice to make it more linear.
tfl.configs.RegularizerConfig(name='torsion', l2=1e-2),
# Globally defined calibration regularizer is applied to all features.
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-2),
])
# A CalibratedLattice premade model constructed from the given model config.
lattice_model = tfl.premade.CalibratedLattice(lattice_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(lattice_model, show_layer_names=False, rankdir='LR')

Comme précédemment, nous compilons, ajustons et évaluons notre modèle.
lattice_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
lattice_model.fit(
heart_train_xs[:5],
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(lattice_model.evaluate(heart_test_xs[:5], heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 3ms/step - loss: 0.4709 - auc_1: 0.8302 [0.4709009826183319, 0.8302004933357239]
Modèle d'ensemble de treillis calibré
Lorsque le nombre d'entités est important, vous pouvez utiliser un modèle d'ensemble, qui crée plusieurs réseaux plus petits pour des sous-ensembles d'entités et fait la moyenne de leur sortie au lieu de créer un seul grand réseau. Modèles de treillis Ensemble sont construits à l' aide tfl.configs.CalibratedLatticeEnsembleConfig . Un modèle d'ensemble de réseau calibré applique un étalonnage linéaire par morceaux et catégoriel sur l'entité en entrée, suivi d'un ensemble de modèles de réseau et d'un étalonnage linéaire par morceaux de sortie en option.
Initialisation d'ensemble de réseau explicite
Si vous savez déjà quels sous-ensembles de fonctionnalités vous souhaitez intégrer à vos réseaux, vous pouvez définir explicitement les réseaux à l'aide des noms de fonctionnalités. Cet exemple crée un modèle d'ensemble de réseau calibré avec 5 réseaux et 3 entités par réseau.
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combined non-linearly and averaged using multiple lattice layers.
explicit_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=heart_feature_configs,
lattices=[['trestbps', 'chol', 'ca'], ['fbs', 'restecg', 'thal'],
['fbs', 'cp', 'oldpeak'], ['exang', 'slope', 'thalach'],
['restecg', 'age', 'sex']],
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0])
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config.
explicit_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
explicit_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
explicit_ensemble_model, show_layer_names=False, rankdir='LR')
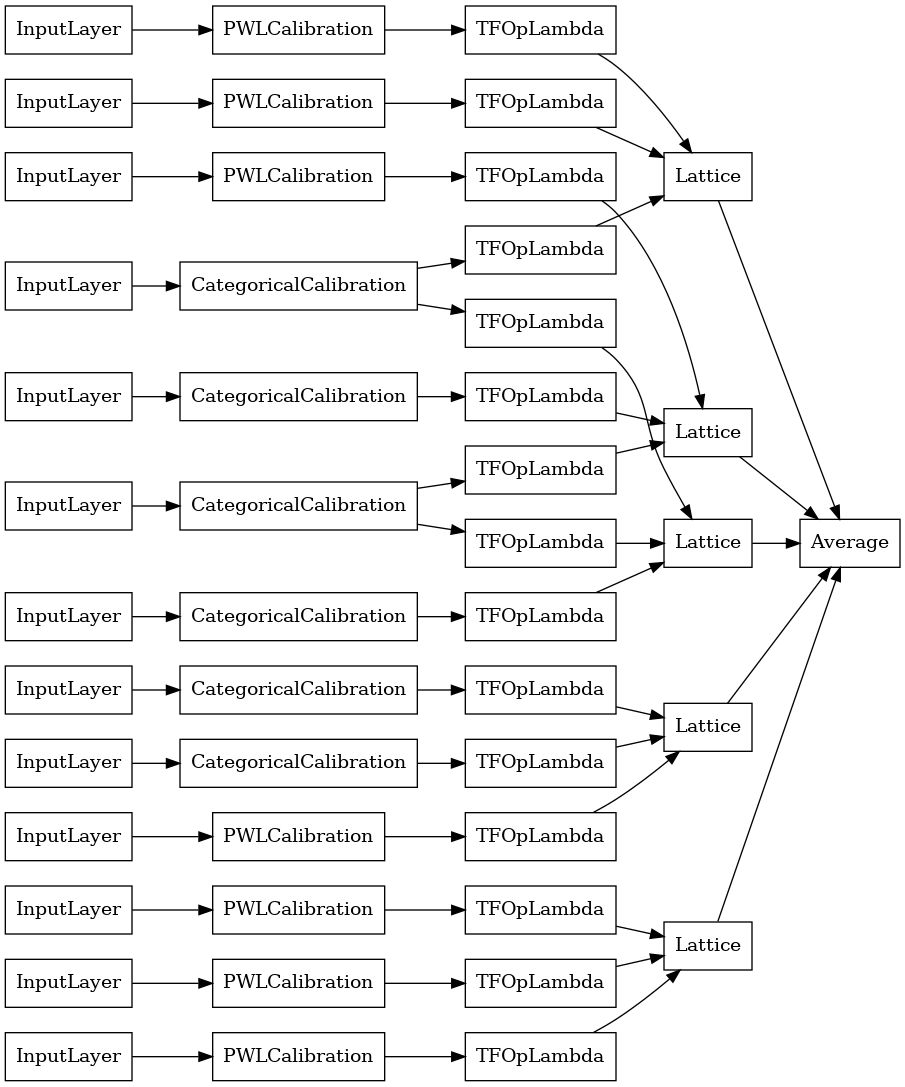
Comme précédemment, nous compilons, ajustons et évaluons notre modèle.
explicit_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
explicit_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(explicit_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 4ms/step - loss: 0.3768 - auc_2: 0.8954 [0.3768467903137207, 0.895363450050354]
Ensemble de treillis aléatoire
Si vous n'êtes pas sûr des sous-ensembles d'entités à alimenter dans vos réseaux, une autre option consiste à utiliser des sous-ensembles aléatoires d'entités pour chaque réseau. Cet exemple crée un modèle d'ensemble de réseau calibré avec 5 réseaux et 3 entités par réseau.
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combined non-linearly and averaged using multiple lattice layers.
random_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=heart_feature_configs,
lattices='random',
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
random_seed=42)
# Now we must set the random lattice structure and construct the model.
tfl.premade_lib.set_random_lattice_ensemble(random_ensemble_model_config)
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config.
random_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
random_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
random_ensemble_model, show_layer_names=False, rankdir='LR')
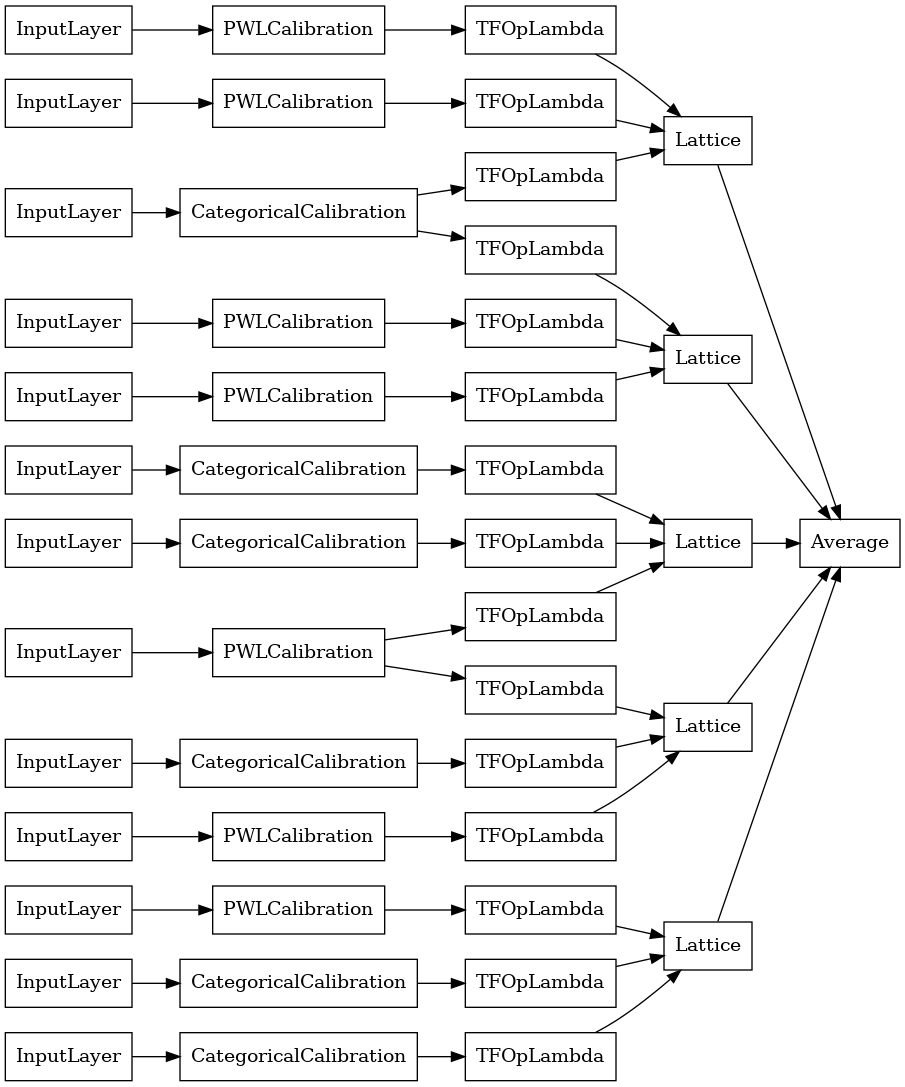
Comme précédemment, nous compilons, ajustons et évaluons notre modèle.
random_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
random_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(random_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 4ms/step - loss: 0.3739 - auc_3: 0.8997 [0.3739270567893982, 0.8997493982315063]
Ensemble RTL Layer Random Lattice
Lors de l' utilisation d' un ensemble réseau aléatoire, vous pouvez spécifier que le modèle utilise une seule tfl.layers.RTL couche. Nous notons que tfl.layers.RTL ne supporte que les contraintes et doit avoir monotonicité la même taille de réseau pour toutes les fonctions et aucune régularisation par-fonction. Notez que l' utilisation d' une tfl.layers.RTL couche vous permet d' évoluer à des ensembles beaucoup plus que d' utiliser différents tfl.layers.Lattice cas.
Cet exemple crée un modèle d'ensemble de réseau calibré avec 5 réseaux et 3 entités par réseau.
# Make sure our feature configs have the same lattice size, no per-feature
# regularization, and only monotonicity constraints.
rtl_layer_feature_configs = copy.deepcopy(heart_feature_configs)
for feature_config in rtl_layer_feature_configs:
feature_config.lattice_size = 2
feature_config.unimodality = 'none'
feature_config.reflects_trust_in = None
feature_config.dominates = None
feature_config.regularizer_configs = None
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combined non-linearly and averaged using multiple lattice layers.
rtl_layer_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=rtl_layer_feature_configs,
lattices='rtl_layer',
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
random_seed=42)
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config. Note that we do not have to specify the lattices by calling
# a helper function (like before with random) because the RTL Layer will take
# care of that for us.
rtl_layer_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
rtl_layer_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
rtl_layer_ensemble_model, show_layer_names=False, rankdir='LR')
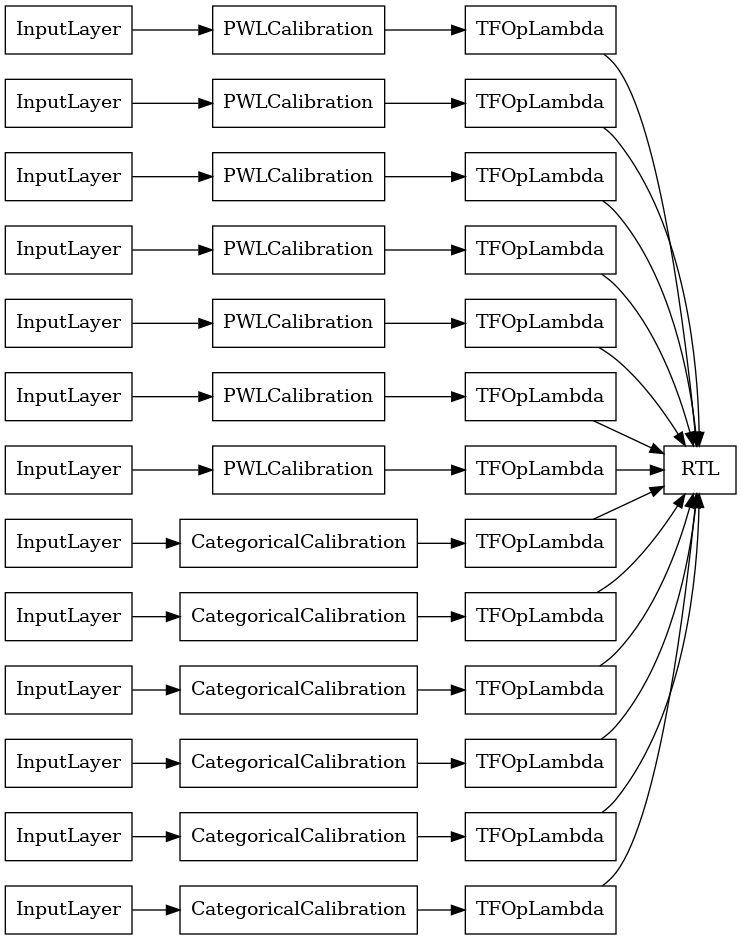
Comme précédemment, nous compilons, ajustons et évaluons notre modèle.
rtl_layer_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
rtl_layer_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(rtl_layer_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 0s 3ms/step - loss: 0.3614 - auc_4: 0.9079 [0.36142951250076294, 0.9078947305679321]
Ensemble de treillis de cristaux
Premade fournit également un algorithme d'arrangement de fonction heuristique, appelée cristaux . Pour utiliser l'algorithme Crystals, nous formons d'abord un modèle de pré-ajustement qui estime les interactions de caractéristiques par paires. Nous organisons ensuite l'ensemble final de telle sorte que les entités avec plus d'interactions non linéaires soient dans les mêmes réseaux.
la bibliothèque Premade offre des fonctions d'aide pour construire la configuration du modèle de pré-ajustement et extraire la structure des cristaux. Notez que le modèle de pré-ajustement n'a pas besoin d'être entièrement formé, donc quelques époques devraient suffire.
Cet exemple crée un modèle d'ensemble de réseau calibré avec 5 réseaux et 3 entités par réseau.
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combines non-linearly and averaged using multiple lattice layers.
crystals_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=heart_feature_configs,
lattices='crystals',
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
random_seed=42)
# Now that we have our model config, we can construct a prefitting model config.
prefitting_model_config = tfl.premade_lib.construct_prefitting_model_config(
crystals_ensemble_model_config)
# A CalibratedLatticeEnsemble premade model constructed from the given
# prefitting model config.
prefitting_model = tfl.premade.CalibratedLatticeEnsemble(
prefitting_model_config)
# We can compile and train our prefitting model as we like.
prefitting_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
prefitting_model.fit(
heart_train_xs,
heart_train_ys,
epochs=PREFITTING_NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
# Now that we have our trained prefitting model, we can extract the crystals.
tfl.premade_lib.set_crystals_lattice_ensemble(crystals_ensemble_model_config,
prefitting_model_config,
prefitting_model)
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config.
crystals_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
crystals_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
crystals_ensemble_model, show_layer_names=False, rankdir='LR')
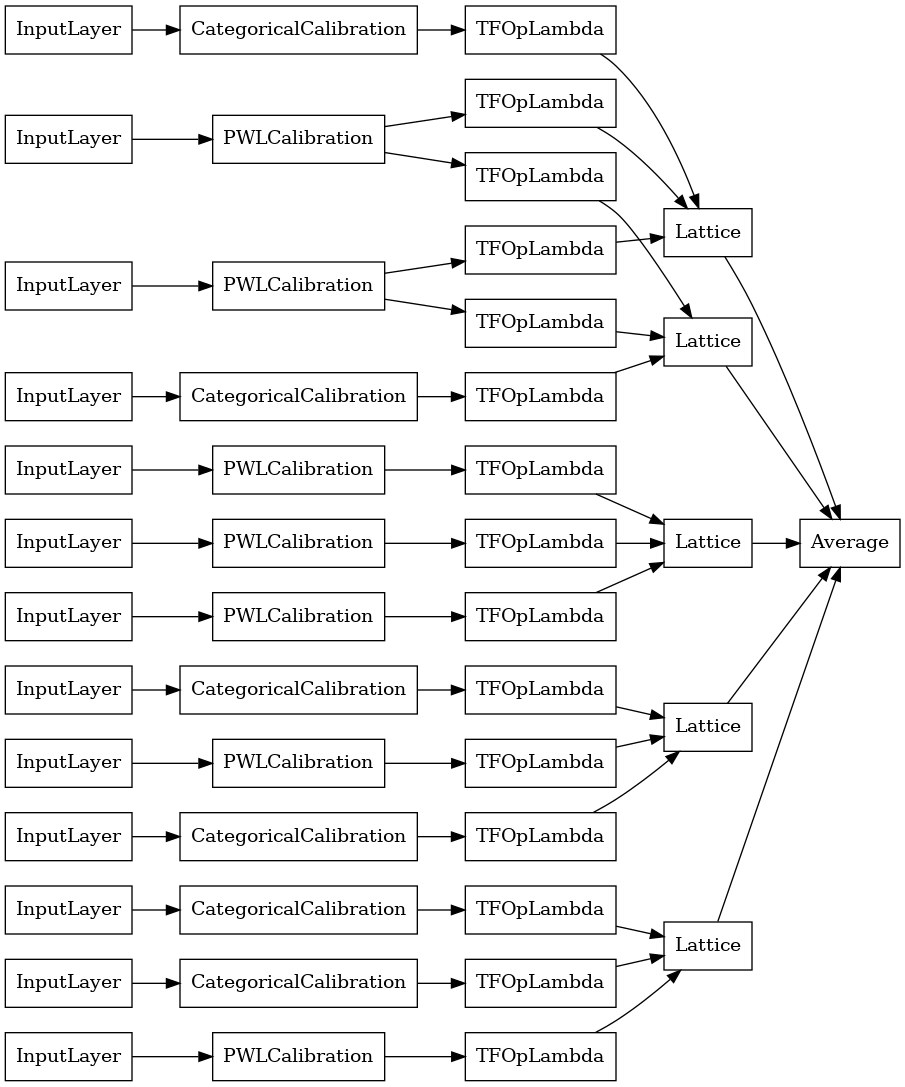
Comme précédemment, nous compilons, ajustons et évaluons notre modèle.
crystals_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
crystals_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(crystals_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 3ms/step - loss: 0.3404 - auc_5: 0.9179 [0.34039050340652466, 0.9179198145866394]