

مهمة تحديد ما يمثله الصوت تسمى تصنيف الصوت . يتم تدريب نموذج تصنيف الصوت للتعرف على الأحداث الصوتية المختلفة. على سبيل المثال، يمكنك تدريب نموذج للتعرف على الأحداث التي تمثل ثلاثة أحداث مختلفة: التصفيق، والتقاط الأصابع، والكتابة. يوفر TensorFlow Lite نماذج مُحسّنة مُدربة مسبقًا والتي يمكنك نشرها في تطبيقات الهاتف المحمول الخاصة بك. تعرف على المزيد حول تصنيف الصوت باستخدام TensorFlow هنا .
الصورة التالية توضح مخرجات نموذج تصنيف الصوت على نظام أندرويد.
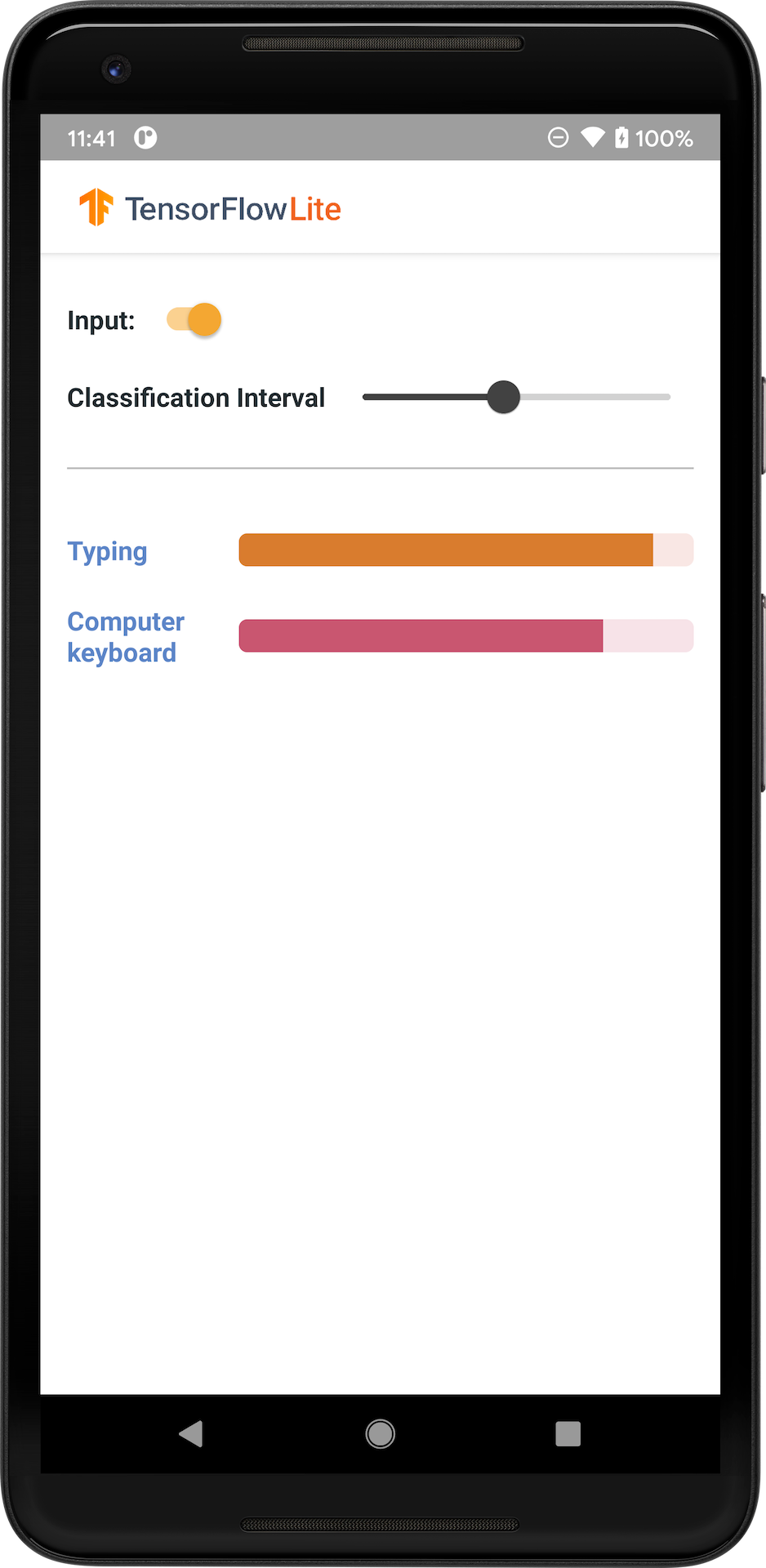
البدء
إذا كنت مستخدمًا جديدًا لـ TensorFlow Lite وتعمل مع Android، فنوصيك باستكشاف أمثلة التطبيقات التالية التي يمكن أن تساعدك على البدء.
يمكنك الاستفادة من واجهة برمجة التطبيقات الجاهزة من مكتبة المهام TensorFlow Lite لدمج نماذج تصنيف الصوت في بضعة أسطر فقط من التعليمات البرمجية. يمكنك أيضًا إنشاء مسار الاستدلال المخصص الخاص بك باستخدام مكتبة دعم TensorFlow Lite .
يوضح مثال Android أدناه التنفيذ باستخدام مكتبة مهام TFLite
إذا كنت تستخدم نظامًا أساسيًا غير Android/iOS، أو إذا كنت معتادًا بالفعل على واجهات برمجة التطبيقات TensorFlow Lite ، فقم بتنزيل النموذج المبدئي والملفات الداعمة (إن أمكن).
قم بتنزيل نموذج البداية من TensorFlow Hub
نموذج الوصف
YAMNet هو مصنف للأحداث الصوتية يأخذ الشكل الموجي الصوتي كمدخل ويقوم بعمل تنبؤات مستقلة لكل حدث من الأحداث الصوتية البالغ عددها 521 حدثًا من مجموعة AudioSet . يستخدم النموذج بنية MobileNet v1 وتم تدريبه باستخدام مجموعة AudioSet. تم إصدار هذا النموذج في الأصل في TensorFlow Model Garden، حيث يوجد الكود المصدري للنموذج ونقطة تفتيش النموذج الأصلية ووثائق أكثر تفصيلاً.
كيف تعمل
هناك نسختان من نموذج YAMNet تم تحويلهما إلى TFLite:
YAMNet هو نموذج تصنيف الصوت الأصلي، بحجم إدخال ديناميكي، مناسب لنقل التعلم ونشر الويب والهاتف المحمول. كما أن لديها مخرجات أكثر تعقيدًا.
YAMNet/classification هو إصدار كمي مع مدخلات إطارية أبسط ذات طول ثابت (15600 عينة) ويعيد متجهًا واحدًا للنتائج لـ 521 فئة من الأحداث الصوتية.
المدخلات
يقبل النموذج float32 Tensor أو NumPy أحادية الأبعاد بطول 15600 تحتوي على شكل موجة 0.975 ثانية ممثلة بعينات أحادية 16 كيلو هرتز في النطاق [-1.0, +1.0] .
النواتج
يقوم النموذج بإرجاع موتر float32 ثنائي الأبعاد للشكل (1، 521) يحتوي على الدرجات المتوقعة لكل فئة من الفئات الـ 521 في مجموعة AudioSet المدعومة بواسطة YAMNet. يتم تعيين فهرس العمود (0-520) لموتر الدرجات إلى اسم فئة AudioSet المقابل باستخدام YAMNet Class Map، والذي يتوفر كملف مرتبط yamnet_label_list.txt معبأ في ملف النموذج. انظر أدناه للاستخدام.
الاستخدامات المناسبة
يمكن استخدام يام نت
- كمصنف مستقل للأحداث الصوتية يوفر خط أساس معقول عبر مجموعة واسعة من الأحداث الصوتية.
- كمستخرج ميزات عالي المستوى: يمكن استخدام مخرجات التضمين 1024-D لـ YAMNet كميزات إدخال لنموذج آخر يمكن تدريبه بعد ذلك على كمية صغيرة من البيانات لمهمة معينة. يتيح ذلك إنشاء مصنفات صوتية متخصصة بسرعة دون الحاجة إلى الكثير من البيانات المصنفة ودون الحاجة إلى تدريب نموذج كبير من البداية إلى النهاية.
- كبداية دافئة: يمكن استخدام معلمات نموذج YAMNet لتهيئة جزء من نموذج أكبر يسمح بضبط دقيق واستكشاف النموذج بشكل أسرع.
محددات
- لم تتم معايرة مخرجات مصنف YAMNet عبر الفئات، لذلك لا يمكنك التعامل مباشرة مع المخرجات كاحتمالات. بالنسبة لأي مهمة معينة، من المحتمل جدًا أن تحتاج إلى إجراء معايرة باستخدام بيانات خاصة بالمهمة والتي تتيح لك تعيين حدود درجات مناسبة لكل فئة وقياسها.
- لقد تم تدريب YAMNet على الملايين من مقاطع فيديو YouTube، وعلى الرغم من تنوعها الشديد، إلا أنه لا يزال هناك عدم تطابق في النطاق بين متوسط فيديو YouTube ومدخلات الصوت المتوقعة لأي مهمة معينة. يجب أن تتوقع إجراء قدر من الضبط والمعايرة لجعل YAMNet قابلاً للاستخدام في أي نظام تقوم بإنشائه.
تخصيص النموذج
تم تدريب النماذج المدربة مسبقًا على اكتشاف 521 فئة صوتية مختلفة. للحصول على قائمة كاملة بالفئات، راجع ملف التصنيفات في مستودع النماذج .
يمكنك استخدام تقنية تُعرف باسم نقل التعلم لإعادة تدريب النموذج للتعرف على الفئات غير الموجودة في المجموعة الأصلية. على سبيل المثال، يمكنك إعادة تدريب النموذج لاكتشاف أغاني الطيور المتعددة. للقيام بذلك، ستحتاج إلى مجموعة من التسجيلات الصوتية التدريبية لكل من العلامات التجارية الجديدة التي ترغب في تدريبها. الطريقة الموصى بها هي استخدام مكتبة TensorFlow Lite Model Maker التي تبسط عملية تدريب نموذج TensorFlow Lite باستخدام مجموعة بيانات مخصصة، في بضعة أسطر من الرموز. يستخدم نقل التعلم لتقليل كمية بيانات التدريب المطلوبة والوقت. يمكنك أيضًا التعلم من نقل التعلم للتعرف على الصوت كمثال على نقل التعلم.
مزيد من القراءة والموارد
استخدم الموارد التالية لمعرفة المزيد حول المفاهيم المتعلقة بتصنيف الصوت: