| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
ملخص
يعد إعداد البيانات الصوتية وزيادتها أحد أكبر التحديات في التعرف التلقائي على الكلام. يمكن أن يكون تحليل البيانات الصوتية في نطاق الوقت أو التردد ، مما يضيف تعقيدًا إضافيًا مقارنة بمصادر البيانات الأخرى مثل الصور.
كجزء من النظام البيئي TensorFlow، tensorflow-io توفر حزمة عدد غير قليل من مفيدة واجهات برمجة التطبيقات ذات الصلة الصوت الذي يساعد على تخفيف إعداد وزيادة من البيانات الصوتية.
يثبت
قم بتثبيت الحزم المطلوبة ، وأعد تشغيل وقت التشغيل
pip install tensorflow-io
إستعمال
اقرأ ملف صوتي
في TensorFlow IO، والطبقة tfio.audio.AudioIOTensor يسمح لك لقراءة ملف صوتي إلى تحميل كسول- IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
في المثال أعلاه، وملف فلاك brooklyn.flac هو من مقطع صوتي متاحة للجمهور في جوجل السحابية .
وGCS عنوان gs://cloud-samples-tests/speech/brooklyn.flac تستخدم مباشرة لGCS هو نظام الملفات المعتمدة في TensorFlow. بالإضافة إلى Flac الشكل، WAV ، Ogg ، MP3 ، و MP4A معتمدة أيضا من قبل AudioIOTensor مع الكشف التلقائي تنسيق الملف.
AudioIOTensor هو كسول محملة بحيث تشكل فقط، dtype، وتظهر معدل عينة في البداية. شكل AudioIOTensor وممثلة على النحو [samples, channels] ، وهو ما يعني المقطع الصوتي الذي قمت بتحميله هو أحادي القناة مع 28979 العينات في int16 .
لن يتم قراءة محتوى مقطع الصوت حسب الحاجة، إما عن طريق تحويل AudioIOTensor إلى Tensor من خلال to_tensor() ، أو من خلال تشريح. يكون التقطيع مفيدًا بشكل خاص عند الحاجة إلى جزء صغير فقط من مقطع صوتي كبير:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
يمكن تشغيل الصوت من خلال:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
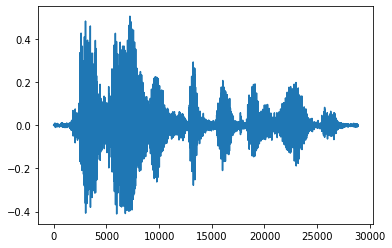
من الأنسب تحويل الموتر إلى أرقام عائمة وإظهار مقطع الصوت في الرسم البياني:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
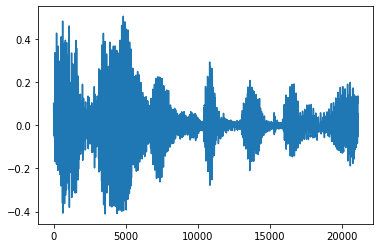
قلل الضوضاء
أحيانا فمن المنطقي لخفض الضجيج من الصوت، والتي يمكن أن يتم ذلك من خلال API tfio.audio.trim . عاد من API هو زوج من [start, stop] موقف segement:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
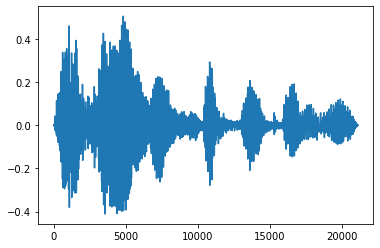
تتلاشى وتتلاشى
تتمثل إحدى تقنيات هندسة الصوت المفيدة في التلاشي ، الذي يزيد الإشارات الصوتية أو ينقصها تدريجيًا. ويمكن أن يتم ذلك من خلال tfio.audio.fade . tfio.audio.fade يدعم أشكال مختلفة من يتلاشى مثل linear ، logarithmic ، أو exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
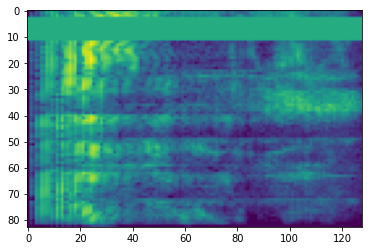
مخطط طيفي
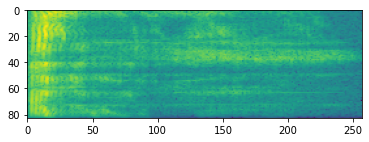
غالبًا ما تعمل المعالجة الصوتية المتقدمة على تغييرات التردد بمرور الوقت. في tensorflow-io الموجي يمكن تحويلها إلى الطيفية من خلال tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
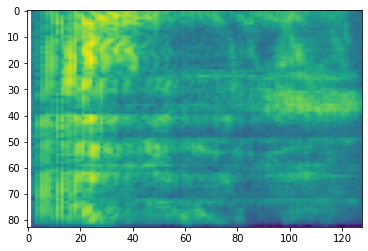
من الممكن أيضًا إجراء تحويل إضافي إلى مقاييس مختلفة:
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
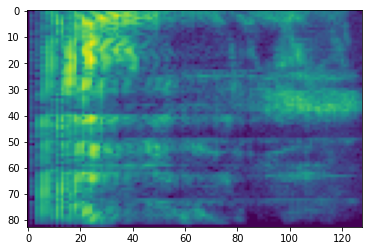
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
المواصفات
بالإضافة إلى ما سبق ذكره إعداد البيانات وزيادة واجهات برمجة التطبيقات، tensorflow-io يوفر حزمة أيضا تعزيزات الطيفية المتقدمة، وأبرزها التردد والوقت إخفاء مناقشتها في SpecAugment: (بارك وآخرون، 2019) A بسيطة طريقة تكبير بيانات التعرف على الكلام التلقائي .
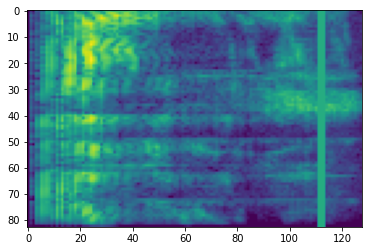
اخفاء التردد
في اخفاء تردد، تردد قنوات [f0, f0 + f) وملثمين حيث f يتم اختياره من توزيع الزي من 0 إلى قناع تردد المعلمة F ، و f0 يتم اختياره من (0, ν − f) حيث ν هو عدد تردد القنوات.
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
اخفاء الوقت
في الوقت اخفاء، t خطوات وقت متتالية [t0, t0 + t) وملثمين حيث t يتم اختياره من توزيع الزي من 0 إلى قناع وقت المعلمة T ، و t0 يتم اختياره من [0, τ − t) حيث τ هو خطوات الوقت.
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>