

Bir sesin neyi temsil ettiğini belirleme görevine ses sınıflandırması denir. Bir ses sınıflandırma modeli, çeşitli ses olaylarını tanıyacak şekilde eğitilir. Örneğin, bir modeli üç farklı olayı temsil eden olayları tanıyacak şekilde eğitebilirsiniz: alkışlama, parmak şıklatma ve yazma. TensorFlow Lite, mobil uygulamalarınızda kullanabileceğiniz optimize edilmiş önceden eğitilmiş modeller sunar. TensorFlow'u kullanarak ses sınıflandırması hakkında daha fazla bilgiyi burada bulabilirsiniz.
Aşağıdaki resim Android'deki ses sınıflandırma modelinin çıktısını göstermektedir.
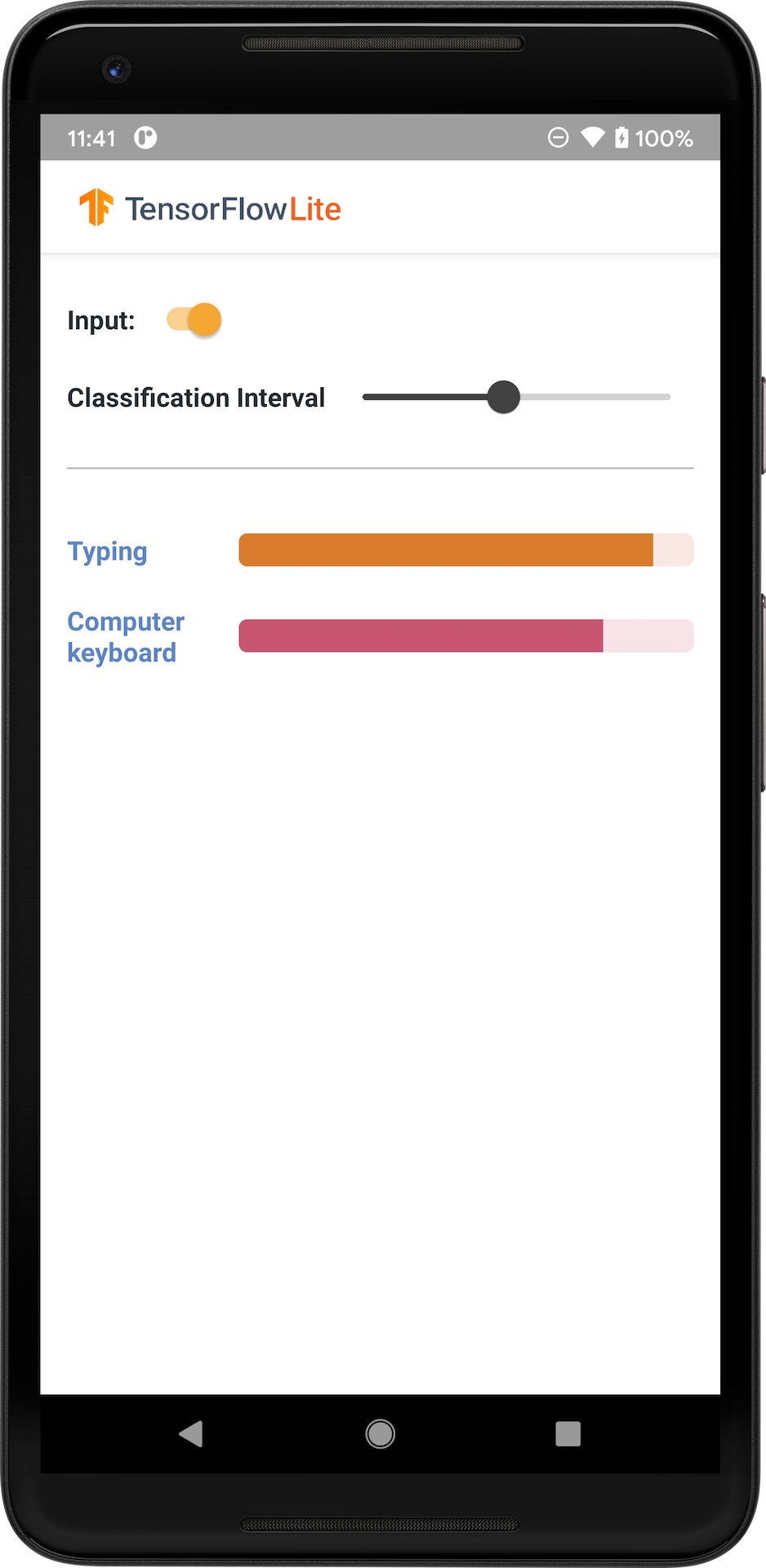
Başlamak
TensorFlow Lite'ta yeniyseniz ve Android ile çalışıyorsanız, başlamanıza yardımcı olabilecek aşağıdaki örnek uygulamaları incelemenizi öneririz.
Ses sınıflandırma modellerini yalnızca birkaç satır kodla entegre etmek için TensorFlow Lite Görev Kitaplığı'ndaki kullanıma hazır API'den yararlanabilirsiniz. TensorFlow Lite Destek Kitaplığını kullanarak kendi özel çıkarım işlem hattınızı da oluşturabilirsiniz.
Aşağıdaki Android örneği, TFLite Görev Kitaplığı kullanılarak uygulamayı göstermektedir
Android/iOS dışında bir platform kullanıyorsanız veya TensorFlow Lite API'lerine zaten aşina iseniz başlangıç modelini ve destek dosyalarını (varsa) indirin.
Başlangıç modelini TensorFlow Hub'dan indirin
Model Açıklaması
YAMNet, ses dalga biçimini girdi olarak alan ve AudioSet ontolojisinden 521 ses olayının her biri için bağımsız tahminler yapan bir ses olayı sınıflandırıcısıdır. Model, MobileNet v1 mimarisini kullanıyor ve AudioSet külliyatı kullanılarak eğitildi. Bu model ilk olarak model kaynak kodunun, orijinal model kontrol noktasının ve daha ayrıntılı belgelerin bulunduğu TensorFlow Model Garden'da piyasaya sürüldü.
Nasıl çalışır
YAMNet modelinin TFLite'a dönüştürülmüş iki versiyonu vardır:
YAMNet , Transfer Öğrenme, Web ve Mobil dağıtımına uygun, dinamik giriş boyutuna sahip orijinal ses sınıflandırma modelidir. Aynı zamanda daha karmaşık bir çıktıya sahiptir.
YAMNet/sınıflandırma, daha basit bir sabit uzunluklu çerçeve girişine (15600 örnek) sahip ve 521 ses olayı sınıfı için tek bir puan vektörü döndüren nicelenmiş bir versiyondur.
Girişler
Model [-1.0, +1.0] aralığında mono 16 kHz örnekler olarak temsil edilen 0,975 saniyelik bir dalga biçimini içeren 15600 uzunluğunda bir 1-D float32 Tensor veya NumPy dizisini kabul eder.
çıktılar
Model, YAMNet tarafından desteklenen AudioSet ontolojisindeki 521 sınıfın her biri için öngörülen puanları içeren 2 boyutlu bir float32 Tensör şekli (1, 521) döndürür. Puan tensörünün sütun dizini (0-520), model dosyasında paketlenmiş ilişkili bir yamnet_label_list.txt dosyası olarak bulunan YAMNet Sınıf Haritası kullanılarak karşılık gelen AudioSet sınıf adıyla eşlenir. Kullanım için aşağıya bakın.
Uygun kullanımlar
YAMNet kullanılabilir
- çok çeşitli ses olayları için makul bir temel sağlayan bağımsız bir ses olayı sınıflandırıcısı olarak.
- üst düzey bir özellik çıkarıcı olarak: YAMNet'in 1024-D yerleştirme çıktısı, daha sonra belirli bir görev için küçük miktarda veri üzerinde eğitilebilecek başka bir modelin giriş özellikleri olarak kullanılabilir. Bu, çok fazla etiketli veri gerektirmeden ve büyük bir modeli uçtan uca eğitmek zorunda kalmadan, özel ses sınıflandırıcılarının hızlı bir şekilde oluşturulmasına olanak tanır.
- Sıcak bir başlangıç olarak: YAMNet model parametreleri daha büyük bir modelin bir kısmını başlatmak için kullanılabilir, bu da daha hızlı ince ayar ve model keşfine olanak tanır.
Sınırlamalar
- YAMNet'in sınıflandırıcı çıktıları sınıflar arasında kalibre edilmediğinden, çıktıları doğrudan olasılık olarak ele alamazsınız. Herhangi bir görev için, büyük olasılıkla, sınıf başına uygun puan eşikleri ve ölçeklendirme atamanıza olanak tanıyan, göreve özgü verilerle bir kalibrasyon yapmanız gerekecektir.
- YAMNet, milyonlarca YouTube videosu üzerinde eğitilmiştir ve bunlar çok çeşitli olmasına rağmen, ortalama YouTube videosu ile herhangi bir görev için beklenen ses girişleri arasında yine de alan adı uyumsuzluğu olabilir. YAMNet'i oluşturduğunuz herhangi bir sistemde kullanılabilir hale getirmek için bir miktar ince ayar ve kalibrasyon yapmayı beklemelisiniz.
Modeli özelleştirme
Sağlanan önceden eğitilmiş modeller, 521 farklı ses sınıfını tespit edecek şekilde eğitilmiştir. Sınıfların tam listesi için model deposundaki etiketler dosyasına bakın.
Orijinal sette olmayan sınıfları tanıyacak şekilde bir modeli yeniden eğitmek için transfer öğrenme olarak bilinen bir tekniği kullanabilirsiniz. Örneğin, birden fazla kuş şarkısını tespit etmek için modeli yeniden eğitebilirsiniz. Bunu yapmak için, eğitmek istediğiniz her yeni plak şirketi için bir dizi eğitim sesine ihtiyacınız olacak. Önerilen yol, özel veri kümesini kullanarak bir TensorFlow Lite modelinin birkaç satır kodla eğitilme sürecini basitleştiren TensorFlow Lite Model Maker kitaplığının kullanılmasıdır. Gerekli eğitim verisi miktarını ve süresini azaltmak için transfer öğrenmeyi kullanır. Transfer öğreniminin bir örneği olarak ses tanıma için Transfer öğreniminden de öğrenebilirsiniz.
Daha fazla okuma ve kaynaklar
Ses sınıflandırmasıyla ilgili kavramlar hakkında daha fazla bilgi edinmek için aşağıdaki kaynakları kullanın: