
| | |  GitHub'da görüntüle GitHub'da görüntüle | | |
YAMNet , kahkaha, havlama veya siren gibi 521 sınıftan ses olaylarını tahmin edebilen önceden eğitilmiş bir derin sinir ağıdır.
Bu eğitimde şunları nasıl yapacağınızı öğreneceksiniz:
- Çıkarım için YAMNet modelini yükleyin ve kullanın.
- Kedi ve köpek seslerini sınıflandırmak için YAMNet yerleştirmelerini kullanarak yeni bir model oluşturun.
- Modelinizi değerlendirin ve dışa aktarın.
TensorFlow ve diğer kitaplıkları içe aktarın
Ses dosyalarını diskten yüklemenizi kolaylaştıracak olan TensorFlow I/O'yu yükleyerek başlayın.
pip install tensorflow_io
tutucu1 l10n-yerimport os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
YAMNet Hakkında
YAMNet , MobileNetV1 derinlemesine ayrılabilir evrişim mimarisini kullanan önceden eğitilmiş bir sinir ağıdır. Giriş olarak bir ses dalga biçimi kullanabilir ve AudioSet korpusundan 521 ses olayının her biri için bağımsız tahminler yapabilir.
Model, dahili olarak, ses sinyalinden "kareler" çıkarır ve bu karelerin toplu işlemlerini işler. Modelin bu sürümü 0,96 saniye uzunluğundaki kareleri kullanır ve her 0,48 saniyede bir kare çıkarır.
Model, [-1.0, +1.0] aralığında tek kanallı (mono) 16 kHz örnekler olarak temsil edilen, isteğe bağlı uzunlukta bir dalga biçimi içeren 1-D float32 Tensör veya NumPy dizisini kabul eder. Bu öğretici, WAV dosyalarını desteklenen biçime dönüştürmenize yardımcı olacak kod içerir.
Model, sınıf puanları, yerleştirmeler (aktarım öğrenimi için kullanacağınız) ve log mel spektrogramı dahil olmak üzere 3 çıktı döndürür. Daha fazla ayrıntıyı burada bulabilirsiniz.
YAMNet'in özel bir kullanımı, üst düzey bir özellik çıkarıcıdır - 1.024 boyutlu gömme çıktısı. Temel (YAMNet) modelin girdi özelliklerini kullanacak ve bunları bir gizli tf.keras.layers.Dense katmanından oluşan daha sığ modelinize besleyeceksiniz. Ardından, çok sayıda etiketli veriye ve uçtan uca eğitime ihtiyaç duymadan , ses sınıflandırması için ağı az miktarda veri üzerinde eğiteceksiniz. (Bu, daha fazla bilgi için TensorFlow Hub ile görüntü sınıflandırması için transfer öğrenimine benzer.)
İlk olarak, modeli test edecek ve sesi sınıflandırmanın sonuçlarını göreceksiniz. Daha sonra veri ön işleme hattını oluşturacaksınız.
YAMNet'i TensorFlow Hub'dan yükleme
Ses dosyalarından yerleştirmeleri çıkarmak için Tensorflow Hub'dan önceden eğitilmiş bir YAMNet kullanacaksınız.
TensorFlow Hub'dan bir model yüklemek basittir: modeli seçin, URL'sini kopyalayın ve load işlevini kullanın.
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
Model yüklendiğinde, YAMNet temel kullanım eğitimini takip edebilir ve çıkarımı çalıştırmak için örnek bir WAV dosyası indirebilirsiniz.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
Daha sonra eğitim verileriyle çalışırken de kullanılacak olan ses dosyalarını yüklemek için bir işleve ihtiyacınız olacak. ( Basit ses tanıma bölümünde ses dosyalarını ve etiketlerini okuma hakkında daha fazla bilgi edinin.
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

Sınıf eşlemesini yükle
YAMNet'in tanıyabileceği sınıf adlarını yüklemek önemlidir. Eşleme dosyası yamnet_model.class_map_path() içinde CSV formatında bulunur.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
çıkarımı çalıştır
YAMNet, çerçeve düzeyinde sınıf puanları sağlar (yani, her çerçeve için 521 puan). Klip düzeyinde tahminleri belirlemek için, puanlar çerçeveler arasında sınıf başına toplanabilir (örneğin, ortalama veya maksimum toplama kullanılarak). Bu, aşağıda scores_np.mean(axis=0) tarafından yapılır. Son olarak, klip düzeyinde en yüksek puanı alan sınıfı bulmak için toplam 521 puanın maksimumunu alırsınız.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
ESC-50 veri seti
ESC-50 veri seti ( Piczak, 2015 ), 2.000 adet beş saniyelik uzun çevresel ses kaydının etiketlenmiş bir koleksiyonudur. Veri seti, sınıf başına 40 örnek olmak üzere 50 sınıftan oluşmaktadır.
Veri kümesini indirin ve çıkarın.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
Verileri keşfedin
Her dosyanın meta verileri, ./datasets/ESC-50-master/meta/esc50.csv adresindeki csv dosyasında belirtilir.
ve tüm ses dosyaları ./datasets/ESC-50-master/audio/ .
Eşleme ile bir panda DataFrame oluşturacak ve verileri daha net bir şekilde görmek için bunu kullanacaksınız.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
Verileri filtrele
Artık veriler DataFrame içinde depolandığına göre, bazı dönüşümler uygulayın:
- Satırları filtreleyin ve yalnızca seçili sınıfları kullanın -
dogvecat. Başka sınıfları kullanmak istiyorsanız, onları seçebileceğiniz yer burasıdır. - Tam yola sahip olmak için dosya adını değiştirin. Bu, daha sonra yüklemeyi kolaylaştıracaktır.
- Hedefleri belirli bir aralıkta olacak şekilde değiştirin. Bu örnekte,
dog0kalacak, ancakcatorijinal değeri olan5yerine1olacak.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
Ses dosyalarını yükleyin ve yerleştirmeleri alın
Burada load_wav_16k_mono uygulayacak ve model için WAV verilerini hazırlayacaksınız.
WAV verilerinden yerleştirmeleri çıkarırken, bir şekil dizisi (N, 1024) elde edersiniz; burada N , YAMNet'in bulduğu kare sayısıdır (her 0,48 saniyelik ses için bir tane).
Modeliniz her kareyi bir girdi olarak kullanacaktır. Bu nedenle, her satırda bir çerçeve olan yeni bir sütun oluşturmanız gerekir. Bu yeni satırları uygun şekilde yansıtmak için etiketleri ve fold sütununu da genişletmeniz gerekir.
Genişletilmiş fold sütunu, orijinal değerleri korur. Çerçeveleri karıştıramazsınız çünkü bölmeleri gerçekleştirirken, farklı bölmelerde aynı sesin parçalarına sahip olabilirsiniz, bu da doğrulama ve test adımlarınızı daha az etkili hale getirir.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
verileri böl
Veri kümesini tren, doğrulama ve test kümelerine bölmek için fold sütununu kullanacaksınız.
ESC-50, aynı orijinal kaynaktan gelen klipler her zaman aynı fold içinde olacak şekilde, beş tekdüze boyutlu çapraz doğrulama fold s halinde düzenlenmiştir - ESC: Çevresel Ses Sınıflandırması için Veri Kümesi belgesinde daha fazlasını öğrenin.
Son adım, eğitim sırasında kullanmayacağınız için fold sütununu veri kümesinden çıkarmaktır.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
Modelinizi oluşturun
İşin çoğunu sen yaptın! Ardından, kedileri ve köpekleri seslerden tanımak için bir gizli katmana ve iki çıktıya sahip çok basit bir Sıralı model tanımlayın.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
Fazla uydurma olmadığından emin olmak için test verileri üzerinde evaluate yöntemini çalıştıralım.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
Sen yaptın!
Modelinizi test edin
Ardından, modelinizi yalnızca YAMNet kullanarak önceki testteki gömme üzerinde deneyin.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
Doğrudan bir WAV dosyasını girdi olarak alabilen bir modeli kaydedin
Modeliniz, girdi olarak yerleştirmeleri verdiğinizde çalışır.
Gerçek dünya senaryosunda, ses verilerini doğrudan girdi olarak kullanmak isteyeceksiniz.
Bunu yapmak için, YAMNet'i modeliniz ile diğer uygulamalar için dışa aktarabileceğiniz tek bir modelde birleştireceksiniz.
Modelin sonucunu kullanmayı kolaylaştırmak için son katman bir reduce_mean işlemi olacaktır. Bu modeli servis için kullanırken (ki bunu öğreticide daha sonra öğreneceksiniz), son katmanın adına ihtiyacınız olacak. Birini tanımlamazsanız, TensorFlow, modeli her eğittiğinizde değişmeye devam edeceğinden, test etmeyi zorlaştıran artımlı bir otomatik tanımlayacaktır. Ham TensorFlow işlemi kullanırken buna bir ad atayamazsınız. Bu sorunu çözmek için, reduce_mean ve buna 'classifier' adını veren özel bir katman oluşturacaksınız.
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
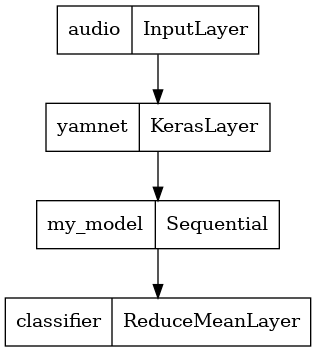
Beklendiği gibi çalıştığını doğrulamak için kayıtlı modelinizi yükleyin.
reloaded_model = tf.saved_model.load(saved_model_path)
Ve son test için: Bazı sağlam veriler verildiğinde, modeliniz doğru sonucu veriyor mu?
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
Yeni modelinizi bir sunum kurulumunda denemek istiyorsanız, 'serving_default' imzasını kullanabilirsiniz.
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(İsteğe bağlı) Biraz daha test
Model hazır.
Test veri setindeki YAMNet ile karşılaştıralım.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
Sonraki adımlar
Köpeklerden veya kedilerden gelen sesleri sınıflandırabilen bir model oluşturdunuz. Aynı fikir ve farklı bir veri seti ile, örneğin kuşların ötüşlerine göre akustik bir tanımlayıcı oluşturmayı deneyebilirsiniz.
Projenizi sosyal medyada TensorFlow ekibiyle paylaşın!