
توفر البيانات التعريفية لـ TensorFlow Lite معيارًا لأوصاف النماذج. تعد البيانات التعريفية مصدرًا مهمًا للمعرفة حول ما يفعله النموذج ومعلومات الإدخال / الإخراج الخاصة به. تتكون البيانات الوصفية من كليهما
- الأجزاء القابلة للقراءة البشرية والتي تنقل أفضل الممارسات عند استخدام النموذج، و
- الأجزاء المقروءة آليًا والتي يمكن الاستفادة منها بواسطة مولدات الأكواد، مثل منشئ أكواد Android TensorFlow Lite وميزة Android Studio ML Binding .
تمت تعبئة جميع نماذج الصور المنشورة على TensorFlow Hub بالبيانات الوصفية.
نموذج مع تنسيق البيانات الوصفية
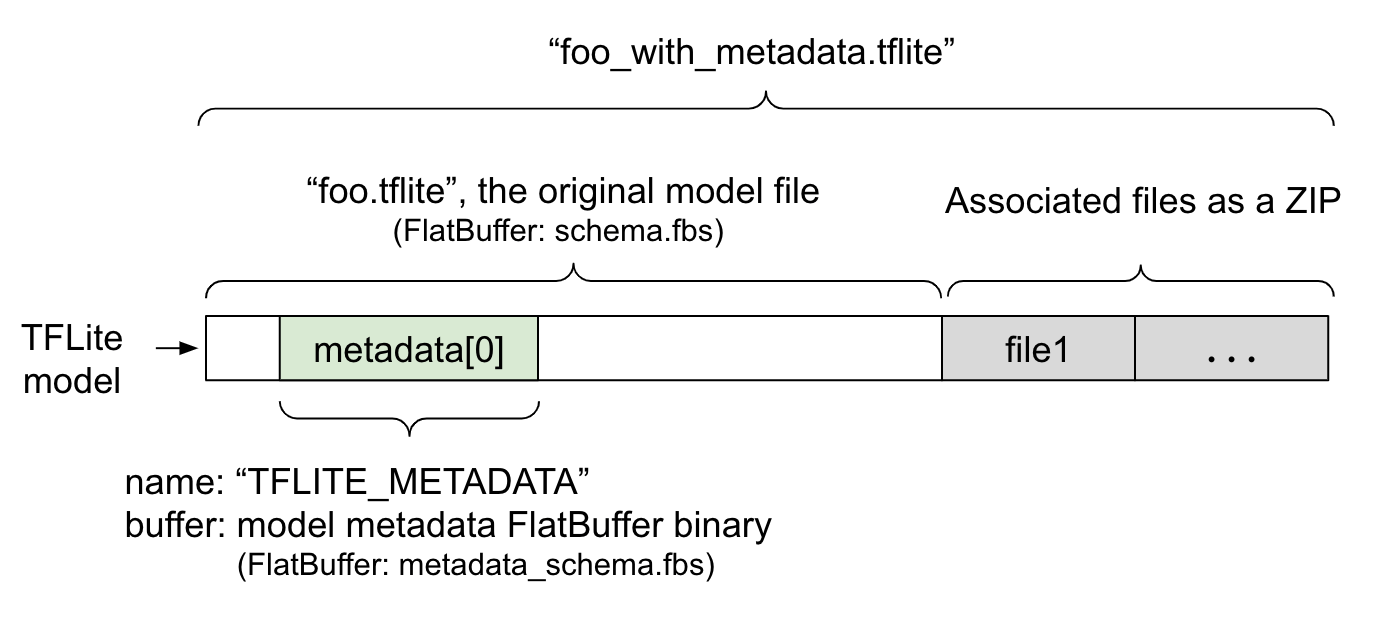
يتم تعريف بيانات تعريف النموذج في metadata_schema.fbs ، وهو ملف FlatBuffer . كما هو موضح في الشكل 1، يتم تخزينها في حقل البيانات الوصفية لمخطط نموذج TFLite ، تحت اسم "TFLITE_METADATA" . قد تأتي بعض النماذج مع الملفات المرتبطة، مثل ملفات تسمية التصنيف . يتم ربط هذه الملفات في نهاية ملف النموذج الأصلي كملف ZIP باستخدام وضع "إلحاق" ZipFile (الوضع 'a' ). يمكن لـ TFLite Interpreter استهلاك تنسيق الملف الجديد بنفس الطريقة السابقة. راجع حزم الملفات المرتبطة لمزيد من المعلومات.
راجع التعليمات الواردة أدناه حول كيفية تعبئة البيانات التعريفية وتصورها وقراءتها.
قم بإعداد أدوات البيانات الوصفية
قبل إضافة بيانات التعريف إلى النموذج الخاص بك، ستحتاج إلى إعداد بيئة برمجة Python لتشغيل TensorFlow. يوجد دليل مفصل حول كيفية إعداد هذا هنا .
بعد إعداد بيئة برمجة بايثون، ستحتاج إلى تثبيت أدوات إضافية:
pip install tflite-support
تدعم أدوات البيانات التعريفية TensorFlow Lite لغة Python 3.
إضافة البيانات الوصفية باستخدام Flatbuffers Python API
هناك ثلاثة أجزاء لبيانات تعريف النموذج في المخطط :
- معلومات النموذج - وصف عام للنموذج بالإضافة إلى عناصر مثل شروط الترخيص. راجع بيانات تعريف النموذج .
- معلومات الإدخال - وصف المدخلات والمعالجة المسبقة المطلوبة مثل التطبيع. راجع SubGraphMetadata.input_tensor_metadata .
- معلومات المخرجات - وصف المخرجات والمعالجة اللاحقة المطلوبة مثل التعيين على الملصقات. راجع SubGraphMetadata.output_tensor_metadata .
نظرًا لأن TensorFlow Lite يدعم فقط رسمًا بيانيًا فرعيًا واحدًا في هذه المرحلة، فإن منشئ أكواد TensorFlow Lite وميزة Android Studio ML Binding سيستخدمان ModelMetadata.name و ModelMetadata.description ، بدلاً من SubGraphMetadata.name و SubGraphMetadata.description ، عند عرض البيانات التعريفية وإنشاء التعليمات البرمجية.
أنواع الإدخال/الإخراج المدعومة
لم يتم تصميم بيانات تعريف TensorFlow Lite للإدخال والإخراج مع وضع أنواع نماذج محددة في الاعتبار، بل أنواع الإدخال والإخراج. لا يهم ما يفعله النموذج وظيفيًا، طالما أن أنواع الإدخال والإخراج تتكون مما يلي أو مجموعة مما يلي، فهي مدعومة ببيانات تعريف TensorFlow Lite:
- الميزة - الأرقام التي هي أعداد صحيحة غير موقعة أو float32.
- الصورة - تدعم البيانات التعريفية حاليًا صور RGB والصور ذات التدرج الرمادي.
- Bounding box - صناديق محيطة مستطيلة الشكل. يدعم المخطط مجموعة متنوعة من أنظمة الترقيم .
حزم الملفات المرتبطة
قد تأتي نماذج TensorFlow Lite مع ملفات مرتبطة مختلفة. على سبيل المثال، عادةً ما تحتوي نماذج اللغة الطبيعية على ملفات مفردات تقوم بتعيين أجزاء الكلمة إلى معرفات الكلمات؛ قد تحتوي نماذج التصنيف على ملفات تسمية تشير إلى فئات الكائنات. بدون الملفات المرتبطة (إن وجدت)، لن يعمل النموذج بشكل جيد.
يمكن الآن تجميع الملفات المرتبطة بالنموذج من خلال مكتبة Python للبيانات الوصفية. يصبح نموذج TensorFlow Lite الجديد ملفًا مضغوطًا يحتوي على النموذج والملفات المرتبطة به. يمكن تفريغها باستخدام أدوات مضغوطة شائعة. يستمر تنسيق النموذج الجديد هذا في استخدام نفس امتداد الملف، .tflite . وهو متوافق مع إطار عمل TFLite والمترجم الفوري. راجع تعبئة بيانات التعريف والملفات المرتبطة بها في النموذج لمزيد من التفاصيل.
يمكن تسجيل معلومات الملف المرتبطة في البيانات الوصفية. اعتمادًا على نوع الملف والمكان الذي تم إرفاق الملف به (أي ModelMetadata و SubGraphMetadata و TensorMetadata )، قد يقوم منشئ أكواد TensorFlow Lite Android بتطبيق المعالجة المسبقة/اللاحقة المقابلة تلقائيًا على الكائن. راجع قسم <Codegen use> لكل نوع ملف مرتبط في المخطط لمزيد من التفاصيل.
معلمات التطبيع والتكميم
التطبيع هو أسلوب شائع لمعالجة البيانات في التعلم الآلي. الهدف من التطبيع هو تغيير القيم إلى مقياس مشترك، دون تشويه الاختلافات في نطاقات القيم.
إن تكميم النموذج هو أسلوب يسمح بتمثيلات منخفضة الدقة للأوزان، واختياريًا، عمليات التنشيط لكل من التخزين والحساب.
فيما يتعلق بالمعالجة المسبقة والمعالجة اللاحقة، فإن التطبيع والتكميم هما خطوتان مستقلتان. التفاصيل هنا.
| تطبيع | توضيح | |
|---|---|---|
مثال على قيم المعلمات للصورة المدخلة في MobileNet للنماذج العائمة والكمية، على التوالي. | نموذج تعويم : - يعني: 127.5 - الأمراض المنقولة جنسيا: 127.5 النموذج الكمي : - يعني: 127.5 - الأمراض المنقولة جنسيا: 127.5 | نموذج تعويم : - نقطة الصفر: 0 - المقياس: 1.0 النموذج الكمي : - نقطة الصفر: 128.0 - المقياس: 0.0078125f |
متى الاستدعاء؟ | المدخلات : إذا تم تسوية بيانات الإدخال في التدريب، فيجب تسوية بيانات الإدخال الخاصة بالاستدلال وفقًا لذلك. المخرجات : لن يتم تسوية بيانات المخرجات بشكل عام. | النماذج العائمة لا تحتاج إلى التكميم. قد يحتاج النموذج الكمي أو لا يحتاج إلى التكميم في المعالجة المسبقة/اللاحقة. يعتمد ذلك على نوع بيانات موتر الإدخال/الإخراج. - الموترات العائمة: لا حاجة إلى التكميم في المعالجة المسبقة/اللاحقة. يتم دمج المرجع الكمي والمرجع المحدد في الرسم البياني النموذجي. - موترات int8/uint8: تحتاج إلى التكميم في المعالجة المسبقة/اللاحقة. |
معادلة | Normalized_input = (الإدخال - المتوسط) / الأمراض المنقولة جنسيا | القياس الكمي للمدخلات : ف = و / مقياس + نقطة صفر Dequantize للمخرجات : و = (ف - صفر نقطة) * مقياس |
أين المعلمات | يتم ملؤها بواسطة منشئ النموذج وتخزينها في بيانات تعريف النموذج، مثل NormalizationOptions | يتم تعبئته تلقائيًا بواسطة محول TFLite، ويتم تخزينه في ملف نموذج tflite. |
| كيفية الحصول على المعلمات؟ | من خلال واجهة برمجة تطبيقات MetadataExtractor [2] | من خلال TFLite Tensor API [1] أو من خلال MetadataExtractor API [2] |
| هل تشترك النماذج العائمة والكمية في نفس القيمة؟ | نعم، النماذج العائمة والكمية لها نفس معلمات التسوية | لا، النموذج العائم لا يحتاج إلى التكميم. |
| هل يقوم منشئ كود TFLite أو ربط Android Studio ML بإنشائه تلقائيًا في معالجة البيانات؟ | نعم | نعم |
[1] واجهة برمجة تطبيقات TensorFlow Lite Java وواجهة برمجة تطبيقات TensorFlow Lite C++ .
[2] مكتبة مستخرج البيانات الوصفية
عند معالجة بيانات الصورة لنماذج uint8، يتم أحيانًا تخطي التسوية والتكميم. من الجيد القيام بذلك عندما تكون قيم البكسل في النطاق [0، 255]. ولكن بشكل عام، يجب عليك دائمًا معالجة البيانات وفقًا لمعلمات التسوية والتكميم عند الاقتضاء.
يمكن لمكتبة المهام TensorFlow Lite التعامل مع التسوية نيابةً عنك إذا قمت بإعداد NormalizationOptions في البيانات التعريفية. يتم دائمًا تغليف معالجة التكميم والتكميم.
أمثلة
يمكنك العثور على أمثلة حول كيفية تعبئة البيانات التعريفية لأنواع مختلفة من النماذج هنا:
تصنيف الصور
قم بتنزيل البرنامج النصي هنا ، الذي يقوم بملء بيانات التعريف إلى mobilenet_v1_0.75_160_quantized.tflite . قم بتشغيل البرنامج النصي مثل هذا:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
لملء البيانات التعريفية لنماذج تصنيف الصور الأخرى، أضف مواصفات النموذج مثل هذه إلى البرنامج النصي. سيسلط باقي هذا الدليل الضوء على بعض الأقسام الرئيسية في مثال تصنيف الصور لتوضيح العناصر الأساسية.
تعمق في مثال تصنيف الصور
معلومات النموذج
تبدأ البيانات التعريفية بإنشاء معلومات نموذج جديدة:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
معلومات الإدخال / الإخراج
يوضح لك هذا القسم كيفية وصف توقيع الإدخال والإخراج الخاص بنموذجك. يمكن استخدام هذه البيانات التعريفية بواسطة مولدات الأكواد التلقائية لإنشاء تعليمات برمجية قبل وبعد المعالجة. لإنشاء معلومات الإدخال أو الإخراج حول الموتر:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
إدخال الصورة
الصورة هي نوع إدخال شائع للتعلم الآلي. تدعم البيانات التعريفية لـ TensorFlow Lite معلومات مثل مساحة الألوان ومعلومات المعالجة المسبقة مثل التطبيع. لا يتطلب بُعد الصورة مواصفات يدوية نظرًا لأنه يتم توفيره بالفعل من خلال شكل موتر الإدخال ويمكن استنتاجه تلقائيًا.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
إخراج التسمية
يمكن تعيين التسمية إلى موتر الإخراج عبر ملف مرتبط باستخدام TENSOR_AXIS_LABELS .
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
قم بإنشاء بيانات تعريف Flatbuffers
يجمع التعليمة البرمجية التالية معلومات النموذج مع معلومات الإدخال والإخراج:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
حزم البيانات الوصفية والملفات المرتبطة بها في النموذج
بمجرد إنشاء بيانات التعريف Flatbuffers، تتم كتابة البيانات التعريفية وملف التسمية في ملف TFLite عبر طريقة populate :
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
يمكنك حزم أي عدد تريده من الملفات المرتبطة في النموذج من خلال load_associated_files . ومع ذلك، من الضروري حزم تلك الملفات الموثقة في البيانات الوصفية على الأقل. في هذا المثال، يعد تعبئة ملف الملصق أمرًا إلزاميًا.
تصور البيانات التعريفية
يمكنك استخدام Netron لتصور بيانات التعريف الخاصة بك، أو يمكنك قراءة البيانات التعريفية من نموذج TensorFlow Lite إلى تنسيق json باستخدام MetadataDisplayer :
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
يدعم Android Studio أيضًا عرض البيانات الوصفية من خلال ميزة Android Studio ML Binding .
إصدار البيانات الوصفية
يتم إصدار مخطط البيانات التعريفية بواسطة رقم الإصدار الدلالي، الذي يتتبع تغييرات ملف المخطط، ومن خلال تعريف ملف Flatbuffers، الذي يشير إلى توافق الإصدار الحقيقي.
رقم الإصدار الدلالي
يتم إصدار مخطط بيانات التعريف بواسطة رقم الإصدار الدلالي ، مثل MAJOR.MINOR.PATCH. فهو يتتبع تغييرات المخطط وفقًا للقواعد الموجودة هنا . راجع تاريخ الحقول المضافة بعد الإصدار 1.0.0 .
تعريف ملف Flatbuffers
يضمن الإصدار الدلالي التوافق في حالة اتباع القواعد، لكنه لا يعني عدم التوافق الحقيقي. عند رفع الرقم الرئيسي، فهذا لا يعني بالضرورة أن التوافق مع الإصدارات السابقة قد تم كسره. لذلك، نستخدم تعريف ملف Flatbuffers ، file_identifier ، للإشارة إلى التوافق الحقيقي لمخطط البيانات الوصفية. معرف الملف هو بالضبط 4 أحرف. تم تثبيته على مخطط بيانات تعريف معين ولا يخضع للتغيير من قبل المستخدمين. إذا كان لا بد من كسر التوافق مع الإصدارات السابقة لمخطط البيانات التعريفية لسبب ما، فسيرتفع معرف الملف، على سبيل المثال، من "M001" إلى "M002". من المتوقع أن يتم تغيير File_identifier بشكل أقل تكرارًا من metadata_version.
الحد الأدنى الضروري لإصدار محلل البيانات الوصفية
الحد الأدنى الضروري لإصدار محلل البيانات التعريفية هو الحد الأدنى من إصدار محلل البيانات التعريفية (رمز Flatbuffers الذي تم إنشاؤه) والذي يمكنه قراءة بيانات تعريف Flatbuffers بالكامل. الإصدار هو في الواقع أكبر رقم إصدار بين إصدارات جميع الحقول المملوءة وأصغر إصدار متوافق يُشار إليه بواسطة معرف الملف. يتم ملء الحد الأدنى الضروري من إصدار محلل البيانات التعريفية تلقائيًا بواسطة MetadataPopulator عندما يتم ملء البيانات التعريفية في نموذج TFLite. راجع مستخرج البيانات التعريفية للحصول على مزيد من المعلومات حول كيفية استخدام الحد الأدنى الضروري من إصدار محلل البيانات التعريفية.
قراءة البيانات الوصفية من النماذج
تعد مكتبة Metadata Extractor أداة ملائمة لقراءة البيانات التعريفية والملفات المرتبطة بها من نماذج عبر منصات مختلفة (راجع إصدار Java وإصدار C++ ). يمكنك إنشاء أداة استخراج البيانات الوصفية الخاصة بك بلغات أخرى باستخدام مكتبة Flatbuffers.
قراءة البيانات الوصفية في جافا
لاستخدام مكتبة Metadata Extractor في تطبيق Android الخاص بك، نوصي باستخدام TensorFlow Lite Metadata AAR المستضاف في MavenCentral . يحتوي على فئة MetadataExtractor ، بالإضافة إلى روابط Java FlatBuffers لمخطط بيانات التعريف ومخطط النموذج .
يمكنك تحديد ذلك في تبعيات build.gradle الخاصة بك على النحو التالي:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
لاستخدام اللقطات الليلية، تأكد من إضافة مستودع لقطات Sonatype .
يمكنك تهيئة كائن MetadataExtractor باستخدام ByteBuffer الذي يشير إلى النموذج:
public MetadataExtractor(ByteBuffer buffer);
يجب أن يظل ByteBuffer دون تغيير طوال عمر كائن MetadataExtractor . قد تفشل التهيئة إذا كان معرف ملف Flatbuffers لبيانات تعريف النموذج لا يتطابق مع محلل بيانات التعريف. راجع إصدار بيانات التعريف لمزيد من المعلومات.
من خلال معرفات الملفات المطابقة، سيتمكن مستخرج البيانات التعريفية من قراءة البيانات التعريفية التي تم إنشاؤها من جميع المخططات السابقة والمستقبلية بنجاح بفضل آلية التوافق مع الأمام والخلف الخاصة بـ Flatbuffers. ومع ذلك، لا يمكن استخراج الحقول من المخططات المستقبلية بواسطة مستخرجي بيانات التعريف الأقدم. يشير الحد الأدنى الضروري من إصدار المحلل اللغوي للبيانات التعريفية إلى الحد الأدنى من إصدار محلل البيانات التعريفية الذي يمكنه قراءة البيانات التعريفية Flatbuffers بالكامل. يمكنك استخدام الطريقة التالية للتحقق من استيفاء الحد الأدنى الضروري لشرط إصدار المحلل اللغوي:
public final boolean isMinimumParserVersionSatisfied();
يُسمح بتمرير نموذج بدون بيانات وصفية. ومع ذلك، فإن استدعاء الأساليب التي تقرأ من البيانات التعريفية سيؤدي إلى حدوث أخطاء في وقت التشغيل. يمكنك التحقق مما إذا كان النموذج يحتوي على بيانات تعريفية عن طريق استدعاء التابع hasMetadata :
public boolean hasMetadata();
يوفر MetadataExtractor وظائف مناسبة لك للحصول على البيانات التعريفية لموترات الإدخال/الإخراج. على سبيل المثال،
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
على الرغم من أن مخطط نموذج TensorFlow Lite يدعم العديد من الرسوم البيانية الفرعية، إلا أن TFLite Interpreter يدعم حاليًا رسمًا بيانيًا فرعيًا واحدًا فقط. ولذلك، يحذف MetadataExtractor فهرس الرسم البياني الفرعي كوسيطة إدخال في أساليبه.
قراءة الملفات المرتبطة من النماذج
يعد نموذج TensorFlow Lite مع البيانات التعريفية والملفات المرتبطة به في الأساس ملفًا مضغوطًا يمكن فك ضغطه باستخدام أدوات مضغوطة شائعة للحصول على الملفات المرتبطة. على سبيل المثال، يمكنك فك ضغط mobilenet_v1_0.75_160_quantized واستخراج ملف التسمية في النموذج كما يلي:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
يمكنك أيضًا قراءة الملفات المرتبطة من خلال مكتبة Metadata Extractor.
في Java، قم بتمرير اسم الملف إلى طريقة MetadataExtractor.getAssociatedFile :
public InputStream getAssociatedFile(String fileName);
وبالمثل، في لغة C++، يمكن القيام بذلك باستخدام الطريقة ModelMetadataExtractor::GetAssociatedFile :
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;