
غالبًا ما تتمتع الأجهزة المتطورة بذاكرة أو قوة حسابية محدودة. يمكن تطبيق تحسينات مختلفة على النماذج بحيث يمكن تشغيلها ضمن هذه القيود. بالإضافة إلى ذلك، تسمح بعض التحسينات باستخدام أجهزة متخصصة للاستدلال السريع.
يوفر TensorFlow Lite ومجموعة أدوات تحسين نموذج TensorFlow أدوات لتقليل تعقيد تحسين الاستدلال.
من المستحسن أن تفكر في تحسين النموذج أثناء عملية تطوير التطبيق الخاص بك. يوضح هذا المستند بعض أفضل الممارسات لتحسين نماذج TensorFlow للنشر على أجهزة الحافة.
لماذا يجب تحسين النماذج
هناك عدة طرق رئيسية يمكن أن يساعد بها تحسين النموذج في تطوير التطبيقات.
تخفيض حجم
يمكن استخدام بعض أشكال التحسين لتقليل حجم النموذج. تتمتع النماذج الأصغر بالمزايا التالية:
- حجم تخزين أصغر: تشغل النماذج الأصغر مساحة تخزين أقل على أجهزة المستخدمين. على سبيل المثال، سيشغل تطبيق Android الذي يستخدم نموذجًا أصغر مساحة تخزين أقل على الجهاز المحمول الخاص بالمستخدم.
- حجم تنزيل أصغر: تتطلب النماذج الأصغر وقتًا ونطاقًا تردديًا أقل للتنزيل على أجهزة المستخدمين.
- استخدام أقل للذاكرة: تستخدم الطرز الأصغر حجمًا ذاكرة وصول عشوائي (RAM) أقل عند تشغيلها، مما يحرر الذاكرة لاستخدام أجزاء أخرى من تطبيقك، ويمكن أن يترجم إلى أداء واستقرار أفضل.
يمكن أن يؤدي التكميم إلى تقليل حجم النموذج في جميع هذه الحالات، وربما على حساب بعض الدقة. يمكن أن يؤدي التقليم والتجميع إلى تقليل حجم النموذج المطلوب تنزيله عن طريق جعله قابلاً للضغط بسهولة أكبر.
تقليل الكمون
الكمون هو مقدار الوقت المستغرق لتشغيل استدلال واحد باستخدام نموذج معين. يمكن لبعض أشكال التحسين أن تقلل من مقدار العمليات الحسابية المطلوبة لتشغيل الاستدلال باستخدام نموذج، مما يؤدي إلى تقليل زمن الوصول. يمكن أن يكون لزمن الوصول أيضًا تأثير على استهلاك الطاقة.
حاليًا، يمكن استخدام التكميم لتقليل زمن الوصول عن طريق تبسيط الحسابات التي تحدث أثناء الاستدلال، وربما على حساب بعض الدقة.
توافق المسرع
يمكن لبعض مسرعات الأجهزة، مثل Edge TPU ، تشغيل الاستدلال بسرعة كبيرة مع النماذج التي تم تحسينها بشكل صحيح.
بشكل عام، تتطلب هذه الأنواع من الأجهزة قياس النماذج بطريقة محددة. راجع وثائق كل مسرع أجهزة لمعرفة المزيد حول متطلباته.
المقايضات
من المحتمل أن تؤدي التحسينات إلى تغييرات في دقة النموذج، والتي يجب أخذها في الاعتبار أثناء عملية تطوير التطبيق.
تعتمد تغييرات الدقة على النموذج الفردي الذي يتم تحسينه، ويصعب التنبؤ به مسبقًا. بشكل عام، ستفقد النماذج التي تم تحسينها من حيث الحجم أو زمن الاستجابة قدرًا صغيرًا من الدقة. اعتمادًا على تطبيقك، قد يؤثر هذا أو لا يؤثر على تجربة المستخدمين. في حالات نادرة، قد تكتسب بعض النماذج بعض الدقة نتيجة لعملية التحسين.
أنواع التحسين
يدعم TensorFlow Lite حاليًا التحسين من خلال التكميم والتشذيب والتجميع.
هذه جزء من مجموعة أدوات تحسين نموذج TensorFlow ، والتي توفر موارد لتقنيات تحسين النموذج المتوافقة مع TensorFlow Lite.
توضيح
يعمل التكميم عن طريق تقليل دقة الأرقام المستخدمة لتمثيل معلمات النموذج، والتي تكون بشكل افتراضي أرقام الفاصلة العائمة 32 بت. وينتج عن هذا حجم نموذج أصغر وحساب أسرع.
تتوفر الأنواع التالية من القياس الكمي في TensorFlow Lite:
| تقنية | متطلبات البيانات | تخفيض حجم | دقة | الأجهزة المدعومة |
|---|---|---|---|---|
| تعويم ما بعد التدريب16 التكميم | لايوجد بيانات | ما يصل إلى 50% | فقدان دقة ضئيلة | وحدة المعالجة المركزية، وحدة معالجة الرسومات |
| تكميم النطاق الديناميكي بعد التدريب | لايوجد بيانات | ما يصل إلى 75% | أصغر فقدان الدقة | وحدة المعالجة المركزية، وحدة معالجة الرسومات (أندرويد) |
| التكميم الصحيح بعد التدريب | عينة تمثيلية غير مسماة | ما يصل إلى 75% | فقدان دقة صغيرة | وحدة المعالجة المركزية، ووحدة معالجة الرسومات (Android)، وEdgeTPU، وHexagon DSP |
| التدريب المدرك للكمية | بيانات التدريب المسمى | ما يصل إلى 75% | أصغر فقدان الدقة | وحدة المعالجة المركزية، ووحدة معالجة الرسومات (Android)، وEdgeTPU، وHexagon DSP |
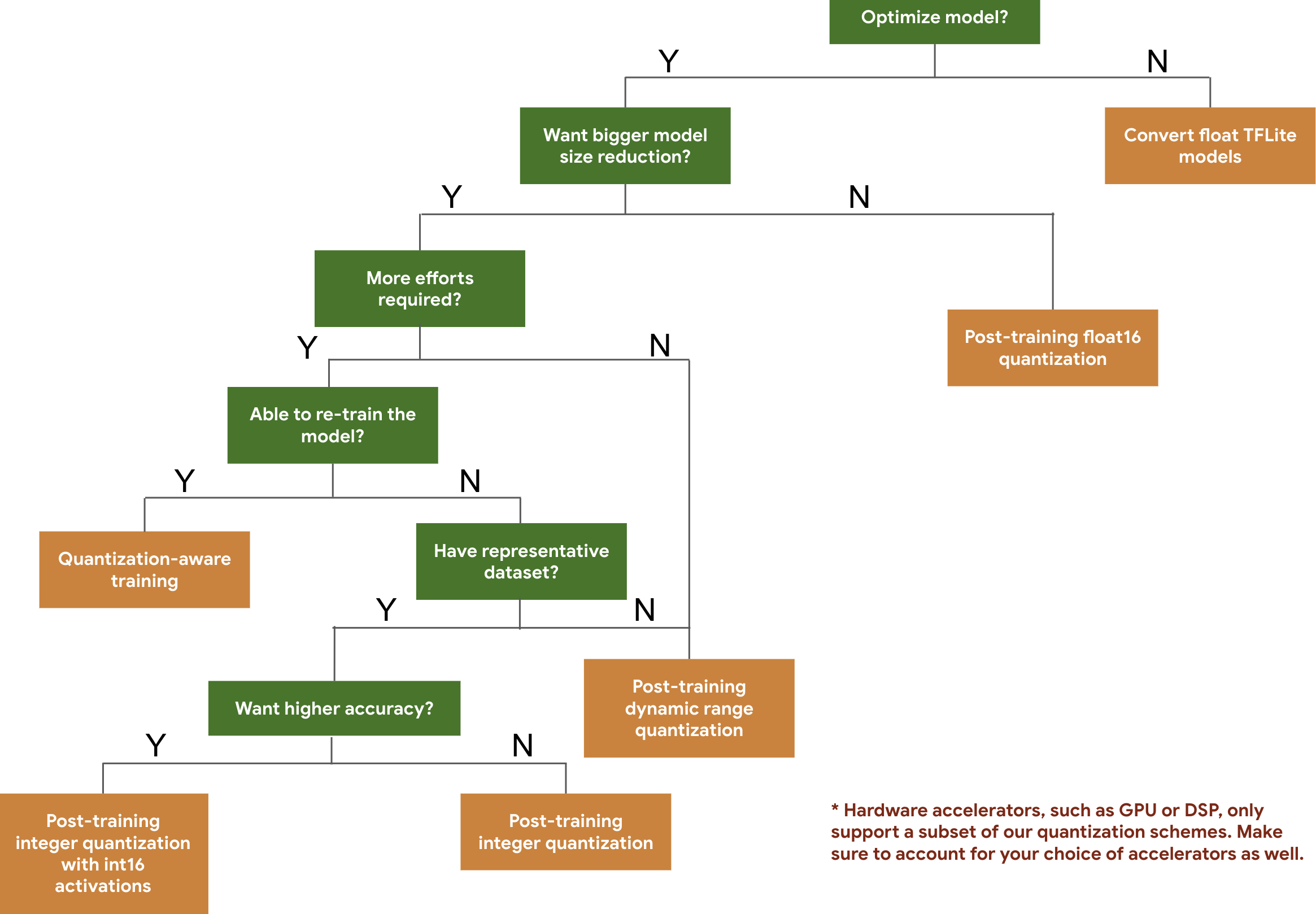
تساعدك شجرة القرار التالية في تحديد مخططات القياس الكمي التي قد ترغب في استخدامها لنموذجك، وذلك استنادًا ببساطة إلى حجم النموذج المتوقع ودقته.
فيما يلي نتائج زمن الاستجابة والدقة الخاصة بالتكميم بعد التدريب والتدريب المدرك للتكميم على بعض النماذج. يتم قياس جميع أرقام زمن الوصول على أجهزة Pixel 2 باستخدام وحدة معالجة مركزية واحدة كبيرة الحجم. ومع تحسن مجموعة الأدوات، ستتحسن الأرقام هنا أيضًا:
| نموذج | دقة أعلى 1 (أصلية) | أعلى 1 دقة (بعد التدريب الكمي) | الدقة الأولى (التدريب المدرك للتكميم) | زمن الوصول (الأصل) (ملي ثانية) | زمن الوصول (بعد التدريب الكمي) (ملي ثانية) | زمن الوصول (التدريب المدرك للتكميم) (ملي ثانية) | الحجم (الأصلي) (ميجابايت) | الحجم (الأمثل) (ميجابايت) |
|---|---|---|---|---|---|---|---|---|
| موبايل نت-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| موبايل نت-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | لا يوجد | 3973 | 2868 | لا يوجد | 178.3 | 44.9 |
تكميم عدد صحيح كامل مع عمليات التنشيط int16 والأوزان int8
التكميم باستخدام عمليات التنشيط int16 هو نظام تكميم كامل للأعداد الصحيحة مع عمليات التنشيط في int16 والأوزان في int8. يمكن لهذا الوضع تحسين دقة النموذج الكمي بالمقارنة مع نظام تكميم الأعداد الصحيحة الكاملة مع كل من عمليات التنشيط والأوزان في int8 مع الحفاظ على حجم نموذج مماثل. يوصى به عندما تكون عمليات التنشيط حساسة للتكميم.
ملاحظة: تتوفر حاليًا فقط تطبيقات kernel المرجعية غير المحسنة في TFLite لنظام التكميم هذا، لذا سيكون الأداء بطيئًا بشكل افتراضي مقارنة بنواة int8. يمكن حاليًا الوصول إلى المزايا الكاملة لهذا الوضع عبر أجهزة متخصصة أو برامج مخصصة.
فيما يلي نتائج الدقة لبعض النماذج التي تستفيد من هذا الوضع. نموذج نوع مقياس الدقة الدقة (تنشيط float32) الدقة (تنشيط int8) الدقة (تنشيط int16) Wav2letter ور 6.7% 7.7% 7.2% DeepSpeech 0.5.1 (غير منشور) خفض الانبعاثات المعتمدة 6.13% 43.67% 6.52% يولوV3 خريطة (IOU=0.5) 0.577 0.563 0.574 موبايل نتV1 أعلى 1 دقة 0.7062 0.694 0.6936 موبايل نتV2 أعلى 1 دقة 0.718 0.7126 0.7137 موبايل بيرت F1 (تطابق تام) 88.81(81.23) 2.08(0) 88.73(81.15)
تشذيب
يعمل التقليم عن طريق إزالة المعلمات الموجودة داخل النموذج والتي لها تأثير بسيط فقط على تنبؤاته. النماذج المقطوعة لها نفس الحجم على القرص، ولها نفس زمن الوصول في وقت التشغيل، ولكن يمكن ضغطها بشكل أكثر فعالية. وهذا يجعل التقليم أسلوبًا مفيدًا لتقليل حجم تنزيل النموذج.
في المستقبل، سيوفر TensorFlow Lite تقليل زمن الوصول للنماذج المقطوعة.
تجمع
يعمل التجميع عن طريق تجميع أوزان كل طبقة في النموذج في عدد محدد مسبقًا من المجموعات، ثم مشاركة قيم النقطه الوسطى للأوزان التي تنتمي إلى كل مجموعة على حدة. وهذا يقلل من عدد قيم الوزن الفريدة في النموذج، وبالتالي يقلل من تعقيده.
ونتيجة لذلك، يمكن ضغط النماذج المجمعة بشكل أكثر فعالية، مما يوفر فوائد النشر المشابهة للتقليم.
سير العمل التطويري
كنقطة بداية، تحقق مما إذا كانت النماذج الموجودة في النماذج المستضافة يمكن أن تعمل مع تطبيقك. إذا لم يكن الأمر كذلك، فإننا نوصي بأن يبدأ المستخدمون باستخدام أداة القياس الكمي بعد التدريب لأن هذا قابل للتطبيق على نطاق واسع ولا يتطلب بيانات التدريب.
بالنسبة للحالات التي لا يتم فيها تحقيق أهداف الدقة وزمن الوصول، أو عندما يكون دعم مسرع الأجهزة مهمًا، فإن التدريب المدرك للكمية هو الخيار الأفضل. راجع تقنيات التحسين الإضافية ضمن مجموعة أدوات تحسين نموذج TensorFlow .
إذا كنت ترغب في تقليل حجم النموذج الخاص بك بشكل أكبر، يمكنك تجربة التقليم و/أو التجميع قبل تحديد كمية النماذج الخاصة بك.