
এজ ডিভাইসে প্রায়ই সীমিত মেমরি বা গণনা শক্তি থাকে। মডেলগুলিতে বিভিন্ন অপ্টিমাইজেশন প্রয়োগ করা যেতে পারে যাতে সেগুলি এই সীমাবদ্ধতার মধ্যে চালানো যায়। উপরন্তু, কিছু অপ্টিমাইজেশন ত্বরিত অনুমানের জন্য বিশেষ হার্ডওয়্যার ব্যবহারের অনুমতি দেয়।
TensorFlow Lite এবং TensorFlow মডেল অপ্টিমাইজেশান টুলকিট অপ্টিমাইজ করা অনুমানের জটিলতা কমানোর জন্য টুল প্রদান করে।
এটি সুপারিশ করা হয় যে আপনি আপনার অ্যাপ্লিকেশন বিকাশ প্রক্রিয়া চলাকালীন মডেল অপ্টিমাইজেশান বিবেচনা করুন৷ এই নথিটি প্রান্ত হার্ডওয়্যারে স্থাপনার জন্য TensorFlow মডেলগুলিকে অপ্টিমাইজ করার জন্য কিছু সেরা অনুশীলনের রূপরেখা দেয়৷
কেন মডেল অপ্টিমাইজ করা উচিত
মডেল অপ্টিমাইজেশন অ্যাপ্লিকেশন বিকাশে সাহায্য করতে পারে এমন কয়েকটি প্রধান উপায় রয়েছে।
আকার হ্রাস
অপ্টিমাইজেশনের কিছু ফর্ম একটি মডেলের আকার কমাতে ব্যবহার করা যেতে পারে। ছোট মডেলের নিম্নলিখিত সুবিধা রয়েছে:
- ছোট সঞ্চয়স্থানের আকার: ছোট মডেলগুলি আপনার ব্যবহারকারীদের ডিভাইসে কম সঞ্চয়স্থান দখল করে। উদাহরণস্বরূপ, একটি ছোট মডেল ব্যবহার করে একটি অ্যান্ড্রয়েড অ্যাপ ব্যবহারকারীর মোবাইল ডিভাইসে কম স্টোরেজ স্পেস নেবে।
- ডাউনলোডের আকার ছোট: ছোট মডেলের ব্যবহারকারীদের ডিভাইসে ডাউনলোড করতে কম সময় এবং ব্যান্ডউইথের প্রয়োজন হয়।
- কম মেমরি ব্যবহার: ছোট মডেলগুলি চালানোর সময় কম RAM ব্যবহার করে, যা আপনার অ্যাপ্লিকেশনের অন্যান্য অংশগুলি ব্যবহারের জন্য মেমরিকে মুক্ত করে এবং আরও ভাল কার্যক্ষমতা এবং স্থিতিশীলতার জন্য অনুবাদ করতে পারে।
কোয়ান্টাইজেশন এই সমস্ত ক্ষেত্রে একটি মডেলের আকার কমাতে পারে, সম্ভাব্য কিছু নির্ভুলতার খরচে। ছাঁটাই এবং ক্লাস্টারিং এটিকে আরও সহজে সংকোচনযোগ্য করে ডাউনলোডের জন্য একটি মডেলের আকার কমাতে পারে।
বিলম্বতা হ্রাস
লেটেন্সি হল প্রদত্ত মডেলের সাথে একটি একক অনুমান চালাতে যে পরিমাণ সময় লাগে। অপ্টিমাইজেশনের কিছু ফর্ম একটি মডেল ব্যবহার করে অনুমান চালানোর জন্য প্রয়োজনীয় গণনার পরিমাণ কমাতে পারে, যার ফলে কম বিলম্ব হয়। লেটেন্সি পাওয়ার খরচের উপরও প্রভাব ফেলতে পারে।
বর্তমানে, কিছু নির্ভুলতার খরচে সম্ভাব্যভাবে অনুমানের সময় ঘটে যাওয়া গণনাগুলিকে সরলীকরণ করে স্থিরতা কমাতে কোয়ান্টাইজেশন ব্যবহার করা যেতে পারে।
অ্যাক্সিলারেটর সামঞ্জস্য
কিছু হার্ডওয়্যার এক্সিলারেটর, যেমন এজ TPU , সঠিকভাবে অপ্টিমাইজ করা মডেলগুলির সাথে অনুমান অত্যন্ত দ্রুত চালাতে পারে।
সাধারণত, এই ধরনের ডিভাইসগুলির জন্য মডেলগুলিকে একটি নির্দিষ্ট উপায়ে পরিমাপ করা প্রয়োজন। তাদের প্রয়োজনীয়তা সম্পর্কে আরও জানতে প্রতিটি হার্ডওয়্যার অ্যাক্সিলারেটরের ডকুমেন্টেশন দেখুন।
ট্রেড-অফ
অপ্টিমাইজেশনের ফলে মডেলের নির্ভুলতার পরিবর্তন হতে পারে, যা অ্যাপ্লিকেশন বিকাশ প্রক্রিয়ার সময় অবশ্যই বিবেচনা করা উচিত।
নির্ভুলতা পরিবর্তনগুলি অপ্টিমাইজ করা পৃথক মডেলের উপর নির্ভর করে এবং সময়ের আগে ভবিষ্যদ্বাণী করা কঠিন। সাধারণত, আকার বা বিলম্বের জন্য অপ্টিমাইজ করা মডেলগুলি অল্প পরিমাণ নির্ভুলতা হারাবে। আপনার আবেদনের উপর নির্ভর করে, এটি আপনার ব্যবহারকারীদের অভিজ্ঞতাকে প্রভাবিত করতে পারে বা নাও করতে পারে। বিরল ক্ষেত্রে, কিছু মডেল অপ্টিমাইজেশন প্রক্রিয়ার ফলে কিছু নির্ভুলতা অর্জন করতে পারে।
অপ্টিমাইজেশনের ধরন
TensorFlow Lite বর্তমানে কোয়ান্টাইজেশন, ছাঁটাই এবং ক্লাস্টারিংয়ের মাধ্যমে অপ্টিমাইজেশন সমর্থন করে।
এগুলি TensorFlow মডেল অপ্টিমাইজেশান টুলকিটের অংশ, যা টেনসরফ্লো লাইটের সাথে সামঞ্জস্যপূর্ণ মডেল অপ্টিমাইজেশান কৌশলগুলির জন্য সংস্থান সরবরাহ করে৷
কোয়ান্টাইজেশন
কোয়ান্টাইজেশন একটি মডেলের পরামিতিগুলিকে উপস্থাপন করতে ব্যবহৃত সংখ্যাগুলির নির্ভুলতা হ্রাস করে কাজ করে, যা ডিফল্টভাবে 32-বিট ফ্লোটিং পয়েন্ট সংখ্যা। এটি একটি ছোট মডেল আকার এবং দ্রুত গণনা ফলাফল.
TensorFlow Lite-এ নিম্নলিখিত ধরনের কোয়ান্টাইজেশন পাওয়া যায়:
| প্রযুক্তি | ডেটা প্রয়োজনীয়তা | আকার হ্রাস | সঠিকতা | সমর্থিত হার্ডওয়্যার |
|---|---|---|---|---|
| পোস্ট-ট্রেনিং float16 কোয়ান্টাইজেশন | কোন তথ্য নেই | 50 পর্যন্ত% | নগণ্য নির্ভুলতা ক্ষতি | সিপিইউ, জিপিইউ |
| প্রশিক্ষণ পরবর্তী গতিশীল পরিসীমা পরিমাপ | কোন তথ্য নেই | 75% পর্যন্ত | ক্ষুদ্রতম নির্ভুলতা ক্ষতি | CPU, GPU (Android) |
| প্রশিক্ষণ-পরবর্তী পূর্ণসংখ্যা পরিমাপ | লেবেলবিহীন প্রতিনিধি নমুনা | 75% পর্যন্ত | ছোট নির্ভুলতা ক্ষতি | CPU, GPU (Android), EdgeTPU, Hexagon DSP |
| পরিমাপ-সচেতন প্রশিক্ষণ | লেবেলযুক্ত প্রশিক্ষণ ডেটা | 75% পর্যন্ত | ক্ষুদ্রতম নির্ভুলতা ক্ষতি | CPU, GPU (Android), EdgeTPU, Hexagon DSP |
নিম্নলিখিত সিদ্ধান্ত ট্রি আপনাকে আপনার মডেলের জন্য ব্যবহার করতে চান এমন কোয়ান্টাইজেশন স্কিমগুলি নির্বাচন করতে সাহায্য করে, শুধুমাত্র প্রত্যাশিত মডেলের আকার এবং নির্ভুলতার উপর ভিত্তি করে।
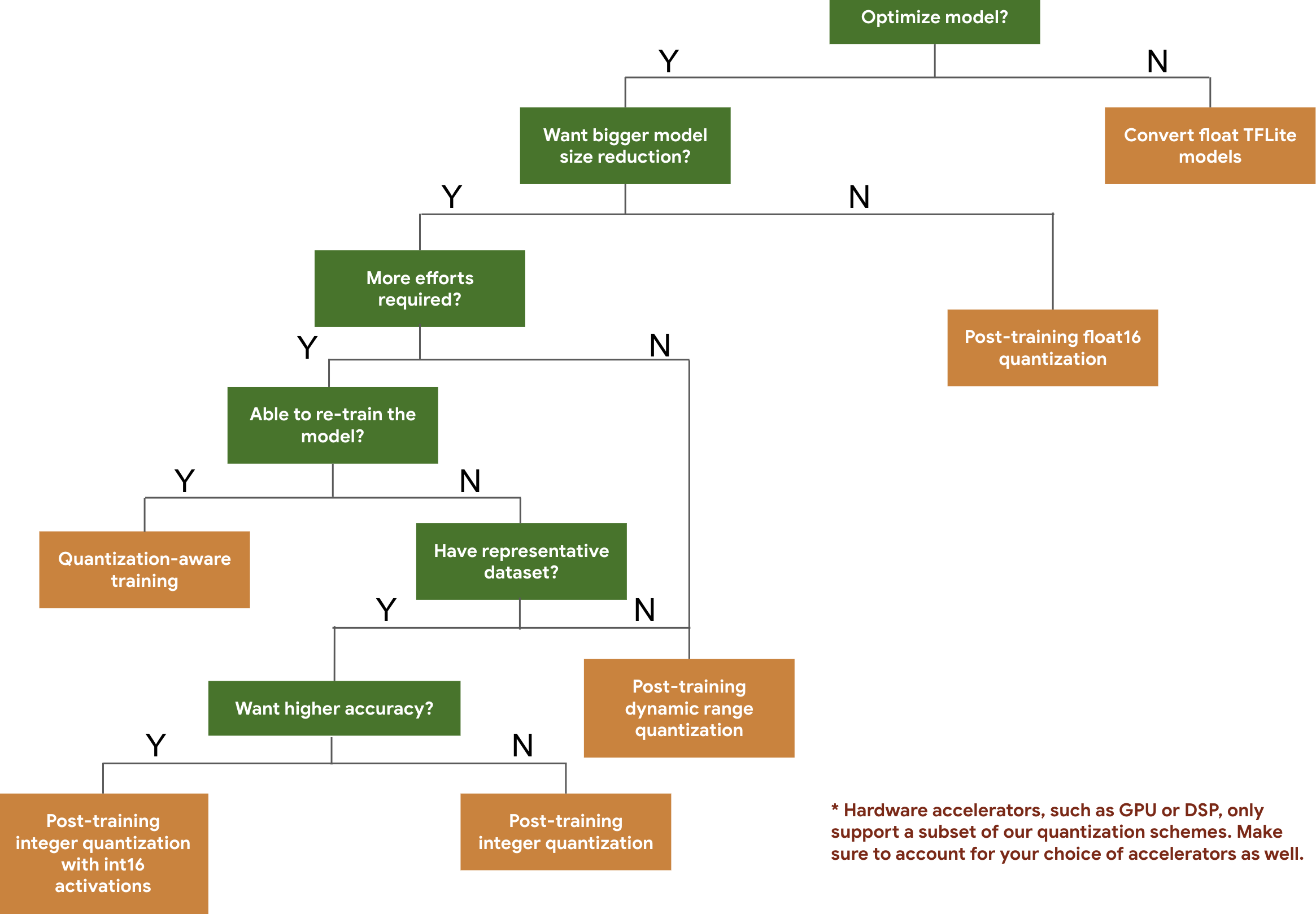
নীচে কয়েকটি মডেলের প্রশিক্ষণ-পরবর্তী কোয়ান্টাইজেশন এবং কোয়ান্টাইজেশন-সচেতন প্রশিক্ষণের জন্য বিলম্বিততা এবং নির্ভুলতার ফলাফল রয়েছে। সমস্ত লেটেন্সি নম্বর একটি একক বড় কোর CPU ব্যবহার করে Pixel 2 ডিভাইসে পরিমাপ করা হয়। টুলকিট উন্নত হওয়ার সাথে সাথে এখানে সংখ্যাগুলিও হবে:
| মডেল | শীর্ষ-১ নির্ভুলতা (মূল) | টপ-১ নির্ভুলতা (প্রশিক্ষণের পরে কোয়ান্টাইজড) | শীর্ষ-১ নির্ভুলতা (কোয়ান্টাইজেশন সচেতন প্রশিক্ষণ) | লেটেন্সি (আসল) (মিসে) | লেটেন্সি (পোস্ট ট্রেনিং কোয়ান্টাইজড) (মিসে) | লেটেন্সি (কোয়ান্টাইজেশন সচেতন প্রশিক্ষণ) (মিসে) | আকার (মূল) (MB) | আকার (অপ্টিমাইজ করা) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | ৮৯ | 98 | 54 | 14 | 3.6 |
| ইনসেপশন_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | N/A | 3973 | 2868 | N/A | 178.3 | 44.9 |
int16 অ্যাক্টিভেশন এবং int8 ওজন সহ সম্পূর্ণ পূর্ণসংখ্যার পরিমাপ
int16 অ্যাক্টিভেশন সহ কোয়ান্টাইজেশন হল int16-এ অ্যাক্টিভেশন এবং int8-এ ওজন সহ একটি সম্পূর্ণ পূর্ণসংখ্যার কোয়ান্টাইজেশন স্কিম। এই মোডটি একই মডেলের আকার রেখে int8-এ সক্রিয়করণ এবং ওজন উভয়ের সাথে সম্পূর্ণ পূর্ণসংখ্যা পরিমাপকরণ স্কিমের তুলনায় কোয়ান্টাইজড মডেলের নির্ভুলতা উন্নত করতে পারে। যখন অ্যাক্টিভেশনগুলি পরিমাপের প্রতি সংবেদনশীল হয় তখন এটি সুপারিশ করা হয়।
দ্রষ্টব্য: বর্তমানে শুধুমাত্র অ-অপ্টিমাইজ করা রেফারেন্স কার্নেল বাস্তবায়ন এই কোয়ান্টাইজেশন স্কিমের জন্য TFLite-এ উপলব্ধ, তাই ডিফল্টরূপে কর্মক্ষমতা int8 কার্নেলের তুলনায় ধীর হবে। এই মোডের সম্পূর্ণ সুবিধাগুলি বর্তমানে বিশেষ হার্ডওয়্যার বা কাস্টম সফ্টওয়্যারের মাধ্যমে অ্যাক্সেস করা যেতে পারে।
নীচে এই মোড থেকে উপকৃত কিছু মডেলের নির্ভুলতা ফলাফল রয়েছে৷ মডেল নির্ভুলতা মেট্রিক প্রকার নির্ভুলতা (float32 সক্রিয়করণ) নির্ভুলতা (int8 সক্রিয়করণ) নির্ভুলতা (int16 সক্রিয়করণ) Wav2letter আমরা 6.7% 7.7% 7.2% ডিপ স্পিচ 0.5.1 (আনরোল করা) সিইআর 6.13% 43.67% 6.52% YoloV3 mAP(IOU=0.5) 0.577 0.563 0.574 MobileNetV1 শীর্ষ-1 যথার্থতা 0.7062 0.694 0.6936 MobileNetV2 শীর্ষ-1 যথার্থতা 0.718 0.7126 0.7137 মোবাইলবার্ট F1 (সঠিক মিল) 88.81(81.23) 2.08(0) 88.73(81.15)
ছাঁটাই
ছাঁটাই একটি মডেলের মধ্যে পরামিতিগুলিকে সরিয়ে দিয়ে কাজ করে যার ভবিষ্যদ্বাণীতে সামান্য প্রভাব পড়ে। ছাঁটাই করা মডেলগুলি ডিস্কে একই আকারের হয় এবং একই রানটাইম লেটেন্সি থাকে, তবে আরও কার্যকরভাবে সংকুচিত করা যায়। এটি মডেল ডাউনলোডের আকার হ্রাস করার জন্য ছাঁটাইকে একটি দরকারী কৌশল করে তোলে।
ভবিষ্যতে, TensorFlow Lite ছাঁটাই করা মডেলগুলির জন্য লেটেন্সি হ্রাস প্রদান করবে।
ক্লাস্টারিং
ক্লাস্টারিং একটি মডেলের প্রতিটি স্তরের ওজনকে একটি পূর্বনির্ধারিত সংখ্যক ক্লাস্টারে গোষ্ঠীবদ্ধ করে কাজ করে, তারপর প্রতিটি পৃথক ক্লাস্টারের অন্তর্গত ওজনের জন্য সেন্ট্রোয়েড মানগুলি ভাগ করে। এটি একটি মডেলে অনন্য ওজনের মানের সংখ্যা হ্রাস করে, এইভাবে এর জটিলতা হ্রাস করে।
ফলস্বরূপ, ক্লাস্টারযুক্ত মডেলগুলিকে আরও কার্যকরভাবে সংকুচিত করা যেতে পারে, ছাঁটাইয়ের মতো স্থাপনার সুবিধা প্রদান করে।
উন্নয়ন কর্মপ্রবাহ
একটি প্রারম্ভিক বিন্দু হিসাবে, হোস্ট করা মডেলগুলির মডেলগুলি আপনার অ্যাপ্লিকেশনের জন্য কাজ করতে পারে কিনা তা পরীক্ষা করুন৷ যদি তা না হয়, আমরা সুপারিশ করি যে ব্যবহারকারীরা প্রশিক্ষণ-পরবর্তী কোয়ান্টাইজেশন টুল দিয়ে শুরু করুন কারণ এটি ব্যাপকভাবে প্রযোজ্য এবং প্রশিক্ষণের ডেটার প্রয়োজন নেই।
যে ক্ষেত্রে নির্ভুলতা এবং লেটেন্সি লক্ষ্য পূরণ হয় না, বা হার্ডওয়্যার অ্যাক্সিলারেটর সমর্থন গুরুত্বপূর্ণ, কোয়ান্টাইজেশন-সচেতন প্রশিক্ষণ হল ভাল বিকল্প। TensorFlow মডেল অপ্টিমাইজেশান টুলকিটের অধীনে অতিরিক্ত অপ্টিমাইজেশান কৌশল দেখুন।
আপনি যদি আপনার মডেলের আকার আরও কমাতে চান, আপনি আপনার মডেলের পরিমাণ নির্ধারণ করার আগে ছাঁটাই এবং/অথবা ক্লাস্টার করার চেষ্টা করতে পারেন।