
קוונטיזציה לאחר אימון היא טכניקת המרה שיכולה להקטין את גודל הדגם תוך שיפור זמן האחזור של המעבד והמאיץ החומרה, עם ירידה קטנה ברמת דיוק המודל. אתה יכול לכמת מודל TensorFlow צף שכבר מאומן כאשר אתה ממיר אותו לפורמט TensorFlow Lite באמצעות TensorFlow Lite Converter .
שיטות אופטימיזציה
ישנן מספר אפשרויות לכימות לאחר האימון לבחירה. להלן טבלת סיכום של הבחירות והיתרונות שהן מספקות:
| טֶכנִיקָה | יתרונות | חוּמרָה |
|---|---|---|
| קוונטיזציה של טווח דינמי | קטן פי 4, מהירות מוגברת פי 2-3 | מעבד |
| קוונטיזציה מלאה של מספרים | 4x קטן יותר, 3x+ מהירות | CPU, Edge TPU, מיקרו-בקרים |
| קוונטיזציה Float16 | קטן פי 2, האצת GPU | מעבד, GPU |
עץ ההחלטות הבא יכול לעזור לקבוע איזו שיטת קוונטיזציה לאחר אימון היא הטובה ביותר עבור מקרה השימוש שלך:
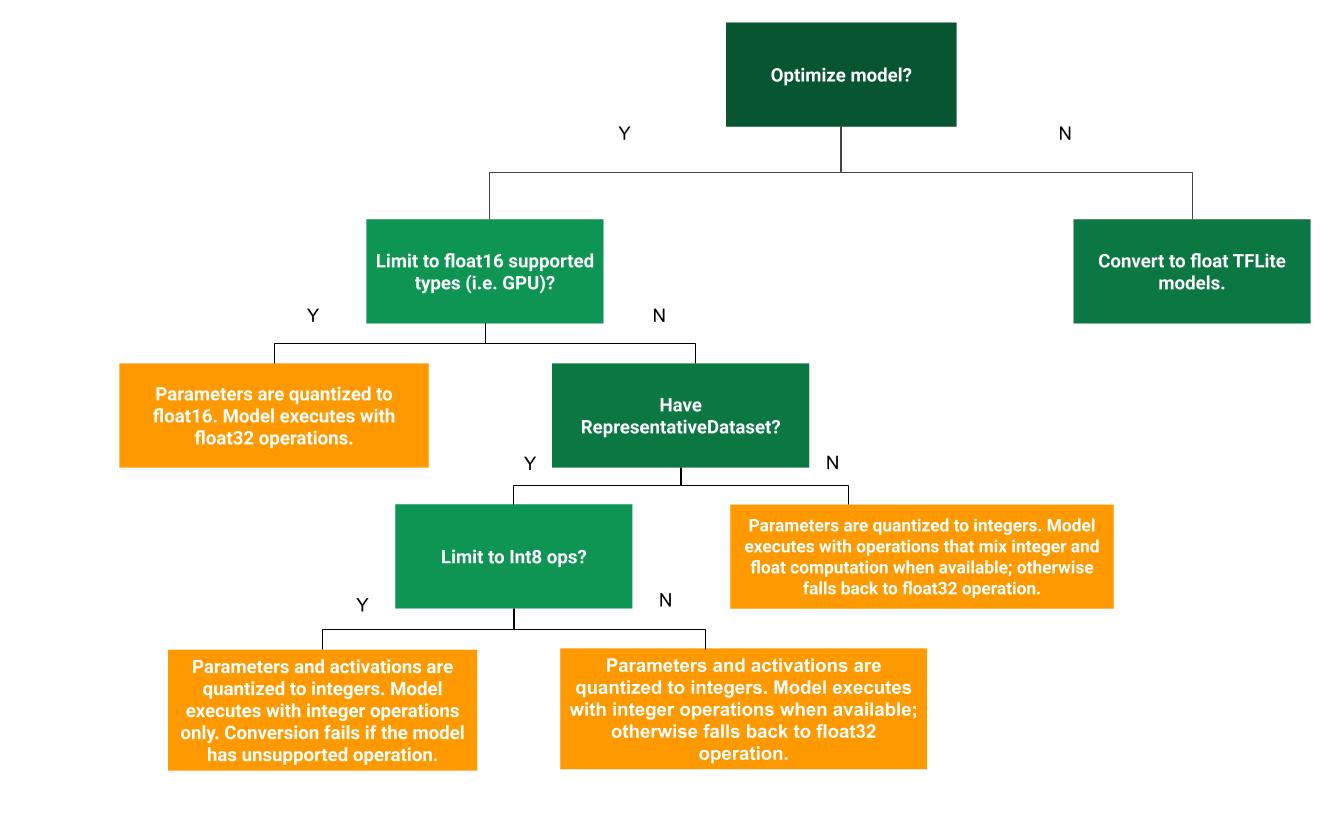
קוונטיזציה של טווח דינמי
קוונטיזציה של טווח דינמי היא נקודת התחלה מומלצת מכיוון שהיא מספקת שימוש מופחת בזיכרון וחישוב מהיר יותר מבלי שתצטרך לספק מערך נתונים מייצג לכיול. סוג זה של כימות, מכמת באופן סטטי רק את המשקולות מנקודה צפה למספר שלם בזמן ההמרה, מה שמספק 8 סיביות של דיוק:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
כדי לצמצם עוד יותר את ההשהיה במהלך ההסקה, אופרטורים "טווח דינמי" מכמתים באופן דינמי את הפעלות על סמך הטווח שלהם ל-8 סיביות ומבצעים חישובים עם משקלים והפעלות של 8 סיביות. אופטימיזציה זו מספקת זמן אחזור קרוב להסקת נקודות קבועות לחלוטין. עם זאת, הפלטים עדיין מאוחסנים באמצעות נקודה צפה כך שהמהירות המוגברת של פעולות בטווח דינמי היא פחות מחישוב נקודה קבועה מלאה.
קוונטיזציה מלאה של מספרים
אתה יכול לקבל שיפורי זמן אחזור נוספים, הפחתה בשימוש שיא בזיכרון ותאימות עם התקני חומרה או מאיצים של מספרים שלמים בלבד, על ידי הקפדה על כל מתמטיקה של המודלים בכימות שלמים.
לכימות מספר שלם מלא, עליך לכייל או להעריך את הטווח, כלומר (מינימום, מקסימום) של כל טנסור הנקודה הצפה במודל. שלא כמו טנסורים קבועים כמו משקלים והטיות, טנסורים משתנים כמו קלט מודל, הפעלה (פלטים של שכבות ביניים) ופלט מודל לא ניתנים לכייל אלא אם כן נריץ כמה מחזורי הסקה. כתוצאה מכך, הממיר דורש מערך נתונים מייצג כדי לכייל אותם. מערך נתונים זה יכול להיות תת-קבוצה קטנה (כ-100-500 דגימות) של נתוני ההדרכה או האימות. עיין בפונקציה representative_dataset() למטה.
מגרסת TensorFlow 2.7, אתה יכול לציין את מערך הנתונים המייצג באמצעות חתימה כדוגמה הבאה:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
אם יש יותר מחתימה אחת במודל TensorFlow הנתון, תוכל לציין את מערך הנתונים המרובים על ידי ציון מפתחות החתימה:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
אתה יכול ליצור את מערך הנתונים המייצג על ידי אספקת רשימת טנסור קלט:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
מאז גירסת TensorFlow 2.7, אנו ממליצים להשתמש בגישה מבוססת חתימות על פני הגישה מבוססת רשימת טנסור קלט מכיוון שניתן להפוך בקלות את סדר טנסור הקלט.
למטרות בדיקה, אתה יכול להשתמש במערך נתונים דמה באופן הבא:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
מספר שלם עם פלט צף (באמצעות קלט/פלט צף ברירת מחדל)
כדי לכמת מודל מלא של מספר שלם, אך השתמש באופרטורים צפים כאשר אין להם יישום של מספר שלם (כדי להבטיח שההמרה מתרחשת בצורה חלקה), השתמש בשלבים הבאים:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
מספר שלם בלבד
יצירת מודלים שלמים בלבד היא מקרה שימוש נפוץ עבור TensorFlow Lite עבור מיקרו-בקרים ו- Coral Edge TPUs .
בנוסף, כדי להבטיח תאימות עם התקנים שלמים בלבד (כגון מיקרו-בקרים של 8 סיביות) ומאיצים (כגון Coral Edge TPU), אתה יכול לאכוף קוונטיזציה מלאה של מספרים שלמים עבור כל הפעולות כולל הקלט והפלט, על ידי שימוש בשלבים הבאים:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
קוונטיזציה Float16
אתה יכול להקטין את הגודל של מודל נקודה צפה על ידי כימות המשקולות ל-float16, תקן IEEE למספרי נקודה צפה של 16 סיביות. כדי לאפשר קוונטיזציה של משקולות float16, השתמש בשלבים הבאים:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
היתרונות של quantization float16 הם כדלקמן:
- זה מקטין את גודל הדגם עד חצי (מאחר שכל המשקולות הופכות לחצי מהגודל המקורי שלהם).
- זה גורם לאובדן מינימלי של דיוק.
- הוא תומך בחלק מהנציגים (למשל נציג ה-GPU) שיכול לפעול ישירות על נתוני float16, וכתוצאה מכך ביצוע מהיר יותר מאשר חישובי float32.
החסרונות של קוונטיזציה float16 הם כדלקמן:
- זה לא מפחית את ההשהיה כמו קוונטיזציה למתמטיקה של נקודה קבועה.
- כברירת מחדל, מודל quantized float16 "תבטל" את ערכי המשקולות ל-float32 כאשר הוא רץ על ה-CPU. (שים לב שנציג ה-GPU לא יבצע ביטול קוונטיזציה זה, מכיוון שהוא יכול לפעול על נתוני float16.)
מספר שלם בלבד: הפעלות של 16 סיביות עם משקלים של 8 סיביות (ניסיוני)
זוהי ערכת קוונטיזציה ניסיונית. זה דומה לסכימת "מספר שלם בלבד", אבל הפעלות מכומתות על סמך הטווח שלהן ל-16 סיביות, משקלים מכומתים במספר שלם של 8 סיביות והטיה מקומתת למספר שלם של 64 סיביות. זה מכונה גם קוונטיזציה של 16x8.
היתרון העיקרי של קוונטיזציה זו הוא בכך שהוא יכול לשפר את הדיוק באופן משמעותי, אך רק להגדיל מעט את גודל הדגם.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
אם קוונטיזציה של 16x8 אינה נתמכת עבור אופרטורים מסוימים במודל, עדיין ניתן לכמת את המודל, אך אופרטורים לא נתמכים לשמור על ציפה. יש להוסיף את האפשרות הבאה ל-target_spec כדי לאפשר זאת.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
דוגמאות למקרי שימוש שבהם שיפורי הדיוק שסופקו על ידי תכנית כימות זו כוללים:
- רזולוציית על,
- עיבוד אותות שמע כגון ביטול רעשים ויצירת אלומה,
- ביטול רעשים של תמונה,
- שחזור HDR מתמונה אחת.
החיסרון של קוונטיזציה זו הוא:
- נכון לעכשיו ההסקה איטית יותר ממספר שלם מלא של 8 סיביות בשל היעדר יישום ליבה אופטימלי.
- נכון לעכשיו זה אינו תואם לנציגי TFLite המואצים בחומרה הקיימים.
מדריך עבור מצב קוונטיזציה זה ניתן למצוא כאן .
דיוק הדגם
מכיוון שמשקולות הן כמותיות לאחר אימון, יכול להיות אובדן דיוק, במיוחד עבור רשתות קטנות יותר. מודלים מוכשרים לחלוטין מסופקים עבור רשתות ספציפיות ב- TensorFlow Hub . חשוב לבדוק את הדיוק של המודל המקוונטי כדי לוודא שכל ירידה ברמת הדיוק נמצאת בגבולות המקובלים. ישנם כלים להערכת דיוק מודל TensorFlow Lite .
לחלופין, אם ירידת הדיוק גבוהה מדי, שקול להשתמש באימון מודע לכיוונטיזציה . עם זאת, פעולה זו דורשת שינויים במהלך אימון המודל כדי להוסיף צמתי קוונטיזציה מזויפים, בעוד שטכניקות הקוונטיזציה שלאחר האימון בדף זה משתמשות במודל קיים מיומן מראש.
ייצוג לטנזורים כמותיים
קוונטיזציה של 8 סיביות מקרבת ערכי נקודה צפה באמצעות הנוסחה הבאה.
\[real\_value = (int8\_value - zero\_point) \times scale\]
לייצוג שני חלקים עיקריים:
משקלי פר-ציר (המכונה פר-ערוץ) או משקלות לכל טנסור המיוצגים על ידי ערכי המשלים של int8 two בטווח [-127, 127] עם נקודת אפס שווה ל-0.
הפעלות/כניסות לכל טנסור המיוצגות על ידי ערכי המשלים של int8 two בטווח [-128, 127], עם נקודת אפס בטווח [-128, 127].
לתצוגה מפורטת של ערכת הכימות שלנו, עיין במפרט הכימות שלנו. ספקי חומרה שרוצים להתחבר לממשק הנציגים של TensorFlow Lite מוזמנים ליישם את סכימת הקוונטיזציה המתוארת שם.