
La quantizzazione post-training è una tecnica di conversione che può ridurre le dimensioni del modello migliorando al tempo stesso la latenza della CPU e dell'acceleratore hardware, con un degrado minimo nella precisione del modello. Puoi quantizzare un modello TensorFlow float già addestrato quando lo converti nel formato TensorFlow Lite utilizzando TensorFlow Lite Converter .
Metodi di ottimizzazione
Sono disponibili diverse opzioni di quantizzazione post-allenamento tra cui scegliere. Ecco una tabella riepilogativa delle scelte e dei vantaggi che offrono:
| Tecnica | Benefici | Hardware |
|---|---|---|
| Quantizzazione della gamma dinamica | 4x più piccolo, 2x-3x più veloce | processore |
| Quantizzazione intera intera | 4 volte più piccolo, 3 volte più veloce | CPU, Edge TPU, microcontrollori |
| Quantizzazione Float16 | 2 volte più piccolo, accelerazione GPU | Processore, GPU |
Il seguente albero decisionale può aiutare a determinare quale metodo di quantizzazione post-training è migliore per il tuo caso d'uso:
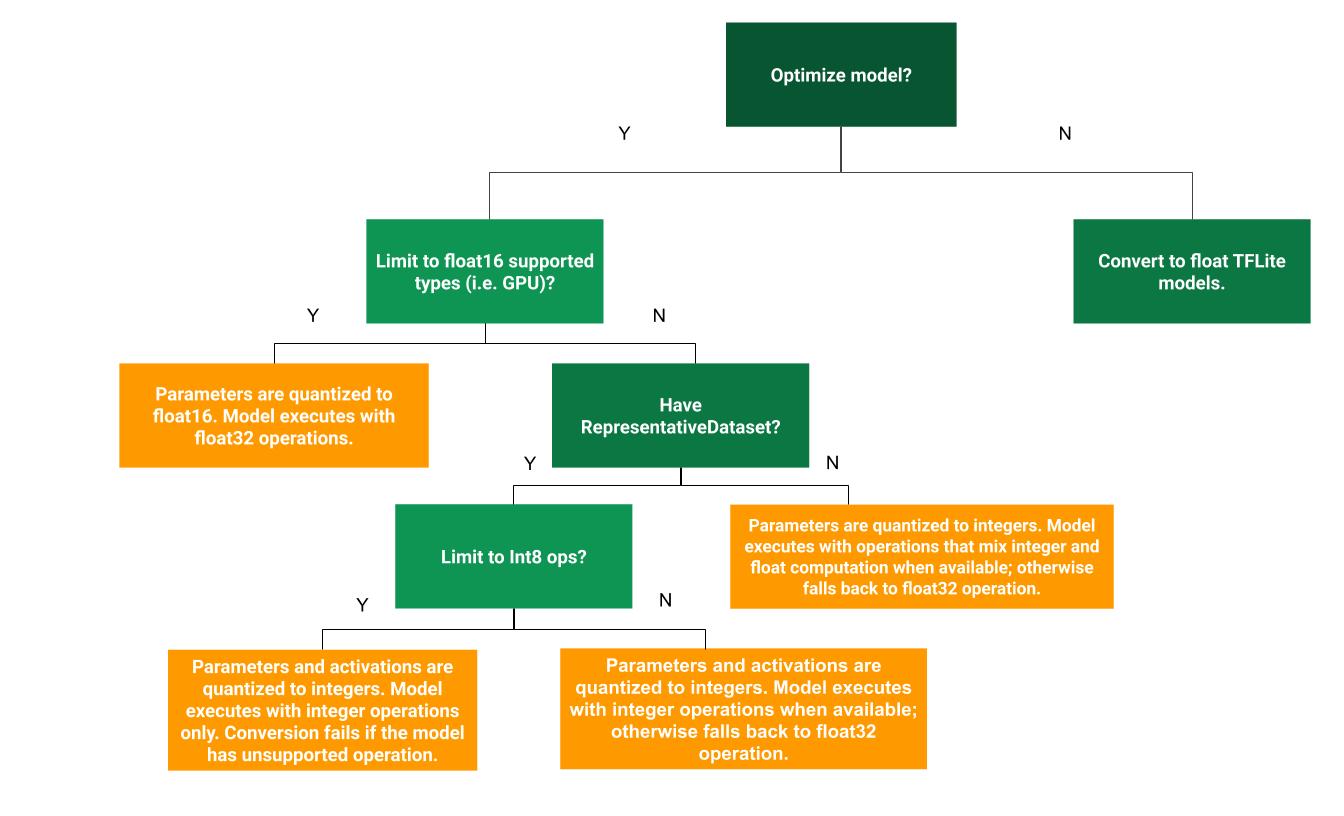
Quantizzazione della gamma dinamica
La quantizzazione della gamma dinamica è un punto di partenza consigliato perché fornisce un utilizzo ridotto della memoria e calcoli più rapidi senza dover fornire un set di dati rappresentativo per la calibrazione. Questo tipo di quantizzazione quantizza staticamente solo i pesi da virgola mobile a intero al momento della conversione, fornendo 8 bit di precisione:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Per ridurre ulteriormente la latenza durante l'inferenza, gli operatori "a gamma dinamica" quantizzano dinamicamente le attivazioni in base al loro intervallo a 8 bit ed eseguono calcoli con pesi e attivazioni a 8 bit. Questa ottimizzazione fornisce latenze vicine alle inferenze completamente a virgola fissa. Tuttavia, gli output vengono ancora archiviati utilizzando la virgola mobile, quindi la maggiore velocità delle operazioni a intervallo dinamico è inferiore a un calcolo completo a virgola fissa.
Quantizzazione intera intera
Puoi ottenere ulteriori miglioramenti della latenza, riduzioni dei picchi di utilizzo della memoria e compatibilità con dispositivi hardware o acceleratori solo interi assicurandoti che tutta la matematica del modello sia quantizzata con numeri interi.
Per la quantizzazione intera completa, è necessario calibrare o stimare l'intervallo, ovvero (min, max) di tutti i tensori a virgola mobile nel modello. A differenza dei tensori costanti come pesi e bias, i tensori variabili come l'input del modello, le attivazioni (output degli strati intermedi) e l'output del modello non possono essere calibrati a meno che non si eseguano alcuni cicli di inferenza. Di conseguenza, il convertitore richiede un set di dati rappresentativo per calibrarli. Questo set di dati può essere un piccolo sottoinsieme (circa 100-500 campioni) dei dati di addestramento o convalida. Fare riferimento alla funzione representative_dataset() di seguito.
Dalla versione TensorFlow 2.7, è possibile specificare il set di dati rappresentativo tramite una firma come nel seguente esempio:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Se è presente più di una firma nel modello TensorFlow specificato, è possibile specificare più set di dati specificando le chiavi della firma:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
È possibile generare il set di dati rappresentativo fornendo un elenco di tensori di input:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
A partire dalla versione TensorFlow 2.7, consigliamo di utilizzare l'approccio basato sulla firma rispetto all'approccio basato sull'elenco dei tensori di input perché l'ordinamento dei tensori di input può essere facilmente invertito.
A scopo di test, è possibile utilizzare un set di dati fittizio come segue:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Intero con fallback float (utilizzando input/output float predefinito)
Per quantizzare completamente un modello intero, ma utilizzare gli operatori float quando non hanno un'implementazione intera (per garantire che la conversione avvenga senza intoppi), utilizzare i seguenti passaggi:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Solo numero intero
La creazione di modelli solo interi è un caso d'uso comune per TensorFlow Lite per microcontrollori e TPU Coral Edge .
Inoltre, per garantire la compatibilità con dispositivi solo interi (come i microcontrollori a 8 bit) e acceleratori (come il Coral Edge TPU), puoi applicare la quantizzazione intera intera per tutte le operazioni, inclusi input e output, utilizzando i seguenti passaggi:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Quantizzazione Float16
È possibile ridurre la dimensione di un modello a virgola mobile quantizzando i pesi su float16, lo standard IEEE per i numeri a virgola mobile a 16 bit. Per abilitare la quantizzazione float16 dei pesi, utilizzare i seguenti passaggi:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
I vantaggi della quantizzazione float16 sono i seguenti:
- Riduce le dimensioni del modello fino alla metà (poiché tutti i pesi diventano la metà delle dimensioni originali).
- Causa una perdita minima di precisione.
- Supporta alcuni delegati (ad esempio il delegato GPU) che possono operare direttamente sui dati float16, con conseguente esecuzione più rapida rispetto ai calcoli float32.
Gli svantaggi della quantizzazione float16 sono i seguenti:
- Non riduce la latenza tanto quanto una quantizzazione su calcoli a virgola fissa.
- Per impostazione predefinita, un modello quantizzato float16 "dequantizzerà" i valori dei pesi in float32 quando viene eseguito sulla CPU. (Si noti che il delegato GPU non eseguirà questa dequantizzazione, poiché può operare su dati float16.)
Solo numeri interi: attivazioni a 16 bit con pesi a 8 bit (sperimentale)
Questo è uno schema di quantizzazione sperimentale. È simile allo schema "solo intero", ma le attivazioni sono quantizzate in base al loro intervallo fino a 16 bit, i pesi sono quantizzati in numeri interi a 8 bit e il bias è quantizzato in numeri interi a 64 bit. Questa viene chiamata ulteriormente quantizzazione 16x8.
Il vantaggio principale di questa quantizzazione è che può migliorare significativamente la precisione, ma aumentare solo leggermente le dimensioni del modello.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Se la quantizzazione 16x8 non è supportata per alcuni operatori nel modello, è comunque possibile quantizzare il modello, ma gli operatori non supportati possono essere mantenuti mobili. La seguente opzione dovrebbe essere aggiunta a target_spec per consentire ciò.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Esempi di casi d'uso in cui i miglioramenti di precisione forniti da questo schema di quantizzazione includono:
- super-risoluzione,
- elaborazione del segnale audio come cancellazione del rumore e beamforming,
- riduzione del rumore dell'immagine,
- Ricostruzione HDR da una singola immagine.
Lo svantaggio di questa quantizzazione è:
- Attualmente l'inferenza è notevolmente più lenta dell'intero intero a 8 bit a causa della mancanza di un'implementazione ottimizzata del kernel.
- Attualmente non è compatibile con i delegati TFLite con accelerazione hardware esistenti.
Un tutorial per questa modalità di quantizzazione può essere trovato qui .
Precisione del modello
Poiché i pesi vengono quantizzati dopo l'addestramento, potrebbe verificarsi una perdita di precisione, in particolare per le reti più piccole. Su TensorFlow Hub vengono forniti modelli completamente quantizzati pre-addestrati per reti specifiche. È importante controllare l'accuratezza del modello quantizzato per verificare che qualsiasi degrado dell'accuratezza rientri entro limiti accettabili. Sono disponibili strumenti per valutare l'accuratezza del modello TensorFlow Lite .
In alternativa, se il calo di precisione è troppo elevato, valuta la possibilità di utilizzare un addestramento basato sulla quantizzazione . Tuttavia, ciò richiede modifiche durante l'addestramento del modello per aggiungere falsi nodi di quantizzazione, mentre le tecniche di quantizzazione post-addestramento in questa pagina utilizzano un modello pre-addestrato esistente.
Rappresentazione dei tensori quantizzati
La quantizzazione a 8 bit si avvicina ai valori in virgola mobile utilizzando la seguente formula.
\[real\_value = (int8\_value - zero\_point) \times scale\]
La rappresentazione ha due parti principali:
Pesi per asse (ovvero per canale) o per tensore rappresentati da int8 valori di complemento a due nell'intervallo [-127, 127] con punto zero uguale a 0.
Attivazioni/input per tensore rappresentati da valori di complemento a due int8 nell'intervallo [-128, 127], con un punto zero nell'intervallo [-128, 127].
Per una visione dettagliata del nostro schema di quantizzazione, consulta le nostre specifiche di quantizzazione . I fornitori di hardware che desiderano collegarsi all'interfaccia delegato di TensorFlow Lite sono incoraggiati a implementare lo schema di quantizzazione ivi descritto.