
L'apprentissage structuré neuronal (NSL) se concentre sur la formation de réseaux neuronaux profonds en exploitant les signaux structurés (lorsqu'ils sont disponibles) ainsi que les entrées de fonctionnalités. Comme introduit par Bui et al. (WSDM'18) , ces signaux structurés sont utilisés pour régulariser l'entraînement d'un réseau neuronal, obligeant le modèle à apprendre des prédictions précises (en minimisant la perte supervisée), tout en maintenant la similarité structurelle d'entrée (en minimisant la perte de voisinage , voir la figure ci-dessous). Cette technique est générique et peut être appliquée sur des architectures neuronales arbitraires (telles que les NN Feed-forward, les NN convolutifs et les NN récurrents).
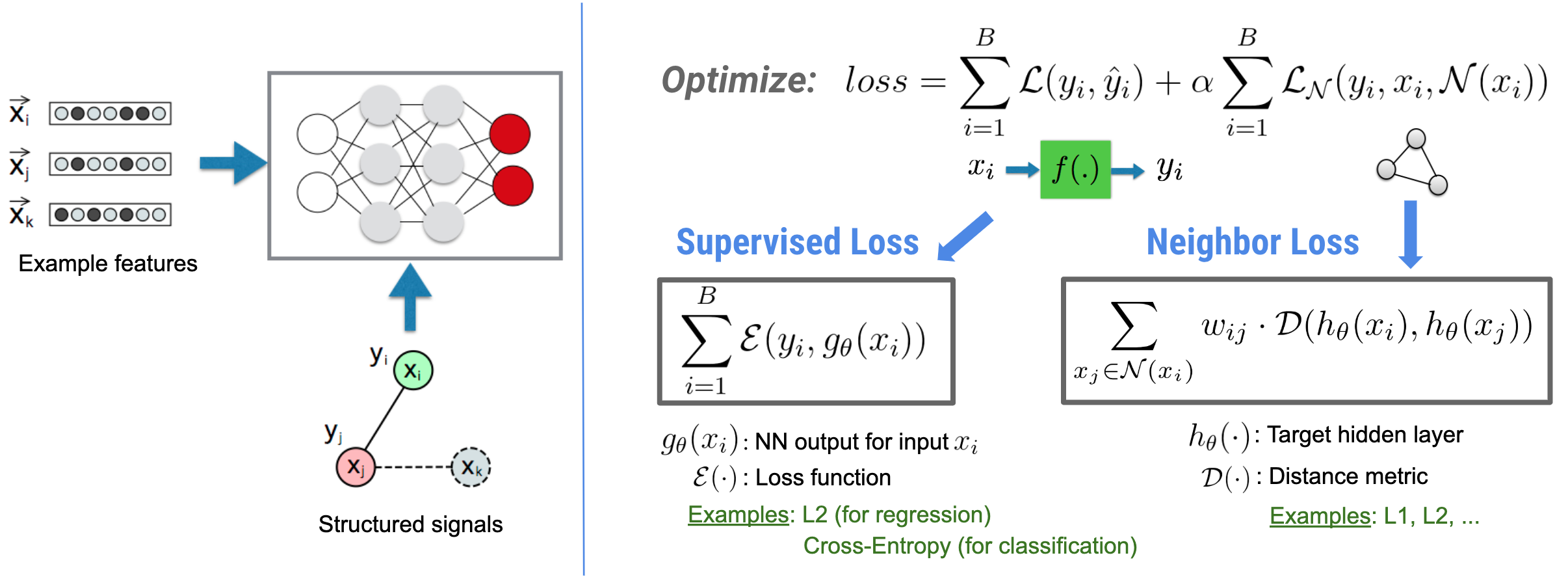
Notez que l'équation de perte de voisinage généralisée est flexible et peut avoir d'autres formes que celle illustrée ci-dessus. Par exemple, nous pouvons également sélectionner\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) être la perte du voisin, qui calcule la distance entre la vérité terrain \(y_i\)et la prédiction du voisin \(g_\theta(x_j)\). Ceci est couramment utilisé dans l'apprentissage contradictoire (Goodfellow et al., ICLR'15) . Par conséquent, NSL se généralise au Neural Graph Learning si les voisins sont explicitement représentés par un graphe, et à l’ Adversarial Learning si les voisins sont implicitement induits par une perturbation contradictoire.
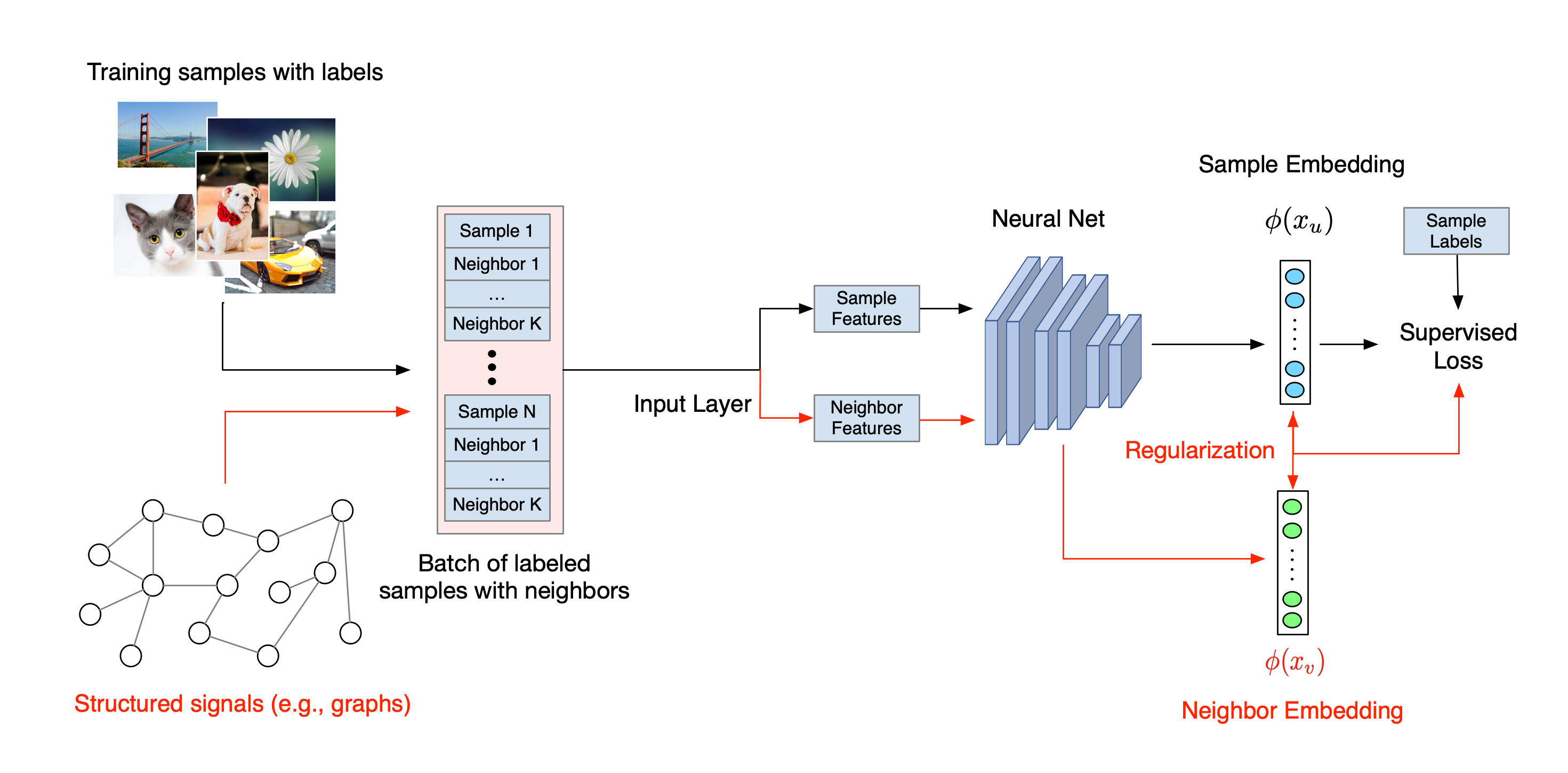
Le flux de travail global pour l’apprentissage structuré neuronal est illustré ci-dessous. Les flèches noires représentent le flux de travail de formation conventionnel et les flèches rouges représentent le nouveau flux de travail introduit par NSL pour exploiter les signaux structurés. Premièrement, les échantillons d’apprentissage sont augmentés pour inclure des signaux structurés. Lorsque les signaux structurés ne sont pas explicitement fournis, ils peuvent être soit construits, soit induits (cette dernière s’appliquant à l’apprentissage contradictoire). Ensuite, les échantillons d'entraînement augmentés (comprenant à la fois les échantillons d'origine et leurs voisins correspondants) sont transmis au réseau neuronal pour calculer leurs intégrations. La distance entre l'intégration d'un échantillon et celle de son voisin est calculée et utilisée comme perte de voisin, qui est traitée comme un terme de régularisation et ajoutée à la perte finale. Pour une régularisation explicite basée sur le voisin, nous calculons généralement la perte de voisin comme la distance entre l'intégration de l'échantillon et l'intégration du voisin. Cependant, n’importe quelle couche du réseau neuronal peut être utilisée pour calculer la perte de voisinage. D'autre part, pour la régularisation basée sur le voisin induit (adversaire), nous calculons la perte de voisin comme la distance entre la prédiction de sortie du voisin contradictoire induit et l'étiquette de vérité terrain.
Pourquoi utiliser NSL ?
NSL apporte les avantages suivants :
- Précision supérieure : le(s) signal(s) structuré(s) parmi les échantillons peuvent fournir des informations qui ne sont pas toujours disponibles dans les entrées de fonctionnalités ; par conséquent, il a été démontré que l'approche de formation conjointe (avec à la fois des signaux structurés et des fonctionnalités) surpasse de nombreuses méthodes existantes (qui reposent sur une formation avec des fonctionnalités uniquement) sur un large éventail de tâches, telles que la classification de documents et la classification d'intentions sémantiques ( Bui et al. ., WSDM'18 & Kipf et al., ICLR'17 ).
- Robustesse : les modèles entraînés avec des exemples contradictoires se sont révélés robustes face aux perturbations contradictoires conçues pour induire en erreur la prédiction ou la classification d'un modèle ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ). Lorsque le nombre d'échantillons d'entraînement est faible, l'entraînement avec des exemples contradictoires contribue également à améliorer la précision du modèle ( Tsipras et al., ICLR'19 ).
- Moins de données étiquetées requises : NSL permet aux réseaux de neurones d'exploiter à la fois des données étiquetées et non étiquetées, ce qui étend le paradigme d'apprentissage à l'apprentissage semi-supervisé . Plus précisément, NSL permet au réseau de s'entraîner à l'aide de données étiquetées comme dans un environnement supervisé, et en même temps amène le réseau à apprendre des représentations cachées similaires pour les « échantillons voisins » qui peuvent ou non avoir des étiquettes. Cette technique s'est révélée très prometteuse pour améliorer la précision du modèle lorsque la quantité de données étiquetées est relativement faible ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
Tutoriels étape par étape
Pour acquérir une expérience pratique de l'apprentissage structuré neuronal, nous proposons des didacticiels qui couvrent divers scénarios dans lesquels des signaux structurés peuvent être explicitement donnés, construits ou induits. En voici quelques-uns :
Régularisation de graphes pour la classification de documents à l'aide de graphes naturels . Dans ce didacticiel, nous explorons l'utilisation de la régularisation de graphe pour classer les documents qui forment un graphe naturel (organique).
Régularisation de graphiques pour la classification des sentiments à l'aide de graphiques synthétisés . Dans ce didacticiel, nous démontrons l'utilisation de la régularisation graphique pour classer les sentiments des critiques de films en construisant (synthétisant) des signaux structurés.
Apprentissage contradictoire pour la classification d'images . Dans ce didacticiel, nous explorons l'utilisation de l'apprentissage contradictoire (où des signaux structurés sont induits) pour classer les images contenant des chiffres numériques.
D'autres exemples et tutoriels peuvent être trouvés dans le répertoire d'exemples de notre référentiel GitHub.
,L'apprentissage structuré neuronal (NSL) se concentre sur la formation de réseaux neuronaux profonds en exploitant les signaux structurés (lorsqu'ils sont disponibles) ainsi que les entrées de fonctionnalités. Comme introduit par Bui et al. (WSDM'18) , ces signaux structurés sont utilisés pour régulariser l'entraînement d'un réseau neuronal, obligeant le modèle à apprendre des prédictions précises (en minimisant la perte supervisée), tout en maintenant la similarité structurelle d'entrée (en minimisant la perte de voisinage , voir la figure ci-dessous). Cette technique est générique et peut être appliquée sur des architectures neuronales arbitraires (telles que les NN Feed-forward, les NN convolutifs et les NN récurrents).
Notez que l’équation généralisée des pertes de voisinage est flexible et peut avoir d’autres formes que celle illustrée ci-dessus. Par exemple, nous pouvons également sélectionner\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) être la perte du voisin, qui calcule la distance entre la vérité terrain \(y_i\)et la prédiction du voisin \(g_\theta(x_j)\). Ceci est couramment utilisé dans l'apprentissage contradictoire (Goodfellow et al., ICLR'15) . Par conséquent, NSL se généralise au Neural Graph Learning si les voisins sont explicitement représentés par un graphe, et à l’ Adversarial Learning si les voisins sont implicitement induits par une perturbation contradictoire.
Le flux de travail global pour l’apprentissage structuré neuronal est illustré ci-dessous. Les flèches noires représentent le flux de travail de formation conventionnel et les flèches rouges représentent le nouveau flux de travail introduit par NSL pour exploiter les signaux structurés. Premièrement, les échantillons d’apprentissage sont augmentés pour inclure des signaux structurés. Lorsque les signaux structurés ne sont pas explicitement fournis, ils peuvent être soit construits, soit induits (cette dernière s’appliquant à l’apprentissage contradictoire). Ensuite, les échantillons d'entraînement augmentés (comprenant à la fois les échantillons d'origine et leurs voisins correspondants) sont transmis au réseau neuronal pour calculer leurs intégrations. La distance entre l'intégration d'un échantillon et celle de son voisin est calculée et utilisée comme perte de voisin, qui est traitée comme un terme de régularisation et ajoutée à la perte finale. Pour une régularisation explicite basée sur le voisin, nous calculons généralement la perte de voisin comme la distance entre l'intégration de l'échantillon et l'intégration du voisin. Cependant, n’importe quelle couche du réseau neuronal peut être utilisée pour calculer la perte de voisinage. D'autre part, pour la régularisation basée sur le voisin induit (adversaire), nous calculons la perte de voisin comme la distance entre la prédiction de sortie du voisin contradictoire induit et l'étiquette de vérité terrain.
Pourquoi utiliser NSL ?
NSL apporte les avantages suivants :
- Précision supérieure : le(s) signal(s) structuré(s) parmi les échantillons peuvent fournir des informations qui ne sont pas toujours disponibles dans les entrées de fonctionnalités ; par conséquent, il a été démontré que l'approche de formation conjointe (avec à la fois des signaux structurés et des fonctionnalités) surpasse de nombreuses méthodes existantes (qui reposent sur une formation avec des fonctionnalités uniquement) sur un large éventail de tâches, telles que la classification de documents et la classification d'intentions sémantiques ( Bui et al. ., WSDM'18 & Kipf et al., ICLR'17 ).
- Robustesse : les modèles entraînés avec des exemples contradictoires se sont révélés robustes face aux perturbations contradictoires conçues pour induire en erreur la prédiction ou la classification d'un modèle ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ). Lorsque le nombre d'échantillons d'entraînement est petit, l'entraînement avec des exemples contradictoires contribue également à améliorer la précision du modèle ( Tsipras et al., ICLR'19 ).
- Moins de données étiquetées requises : NSL permet aux réseaux de neurones d'exploiter à la fois des données étiquetées et non étiquetées, ce qui étend le paradigme d'apprentissage à l'apprentissage semi-supervisé . Plus précisément, NSL permet au réseau de s'entraîner à l'aide de données étiquetées comme dans un environnement supervisé, et en même temps amène le réseau à apprendre des représentations cachées similaires pour les « échantillons voisins » qui peuvent ou non avoir des étiquettes. Cette technique s'est révélée très prometteuse pour améliorer la précision du modèle lorsque la quantité de données étiquetées est relativement faible ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
Tutoriels étape par étape
Pour acquérir une expérience pratique de l'apprentissage structuré neuronal, nous proposons des didacticiels qui couvrent divers scénarios dans lesquels des signaux structurés peuvent être explicitement donnés, construits ou induits. En voici quelques-uns :
Régularisation de graphes pour la classification de documents à l'aide de graphes naturels . Dans ce didacticiel, nous explorons l'utilisation de la régularisation de graphe pour classer les documents qui forment un graphe naturel (organique).
Régularisation de graphiques pour la classification des sentiments à l'aide de graphiques synthétisés . Dans ce didacticiel, nous démontrons l'utilisation de la régularisation graphique pour classer les sentiments des critiques de films en construisant (synthétisant) des signaux structurés.
Apprentissage contradictoire pour la classification d'images . Dans ce didacticiel, nous explorons l'utilisation de l'apprentissage contradictoire (où des signaux structurés sont induits) pour classer les images contenant des chiffres numériques.
D'autres exemples et tutoriels peuvent être trouvés dans le répertoire d'exemples de notre référentiel GitHub.
,L'apprentissage structuré neuronal (NSL) se concentre sur la formation de réseaux neuronaux profonds en exploitant les signaux structurés (lorsqu'ils sont disponibles) ainsi que les entrées de fonctionnalités. Comme introduit par Bui et al. (WSDM'18) , ces signaux structurés sont utilisés pour régulariser l'entraînement d'un réseau neuronal, obligeant le modèle à apprendre des prédictions précises (en minimisant la perte supervisée), tout en maintenant la similarité structurelle d'entrée (en minimisant la perte de voisinage , voir la figure ci-dessous). Cette technique est générique et peut être appliquée sur des architectures neuronales arbitraires (telles que les NN Feed-forward, les NN convolutifs et les NN récurrents).
Notez que l’équation généralisée des pertes de voisinage est flexible et peut avoir d’autres formes que celle illustrée ci-dessus. Par exemple, nous pouvons également sélectionner\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) être la perte du voisin, qui calcule la distance entre la vérité terrain \(y_i\)et la prédiction du voisin \(g_\theta(x_j)\). Ceci est couramment utilisé dans l'apprentissage contradictoire (Goodfellow et al., ICLR'15) . Par conséquent, NSL se généralise au Neural Graph Learning si les voisins sont explicitement représentés par un graphe, et à l’ Adversarial Learning si les voisins sont implicitement induits par une perturbation contradictoire.
Le flux de travail global pour l’apprentissage structuré neuronal est illustré ci-dessous. Les flèches noires représentent le flux de travail de formation conventionnel et les flèches rouges représentent le nouveau flux de travail introduit par NSL pour exploiter les signaux structurés. Premièrement, les échantillons d’apprentissage sont augmentés pour inclure des signaux structurés. Lorsque les signaux structurés ne sont pas explicitement fournis, ils peuvent être soit construits, soit induits (cette dernière s’appliquant à l’apprentissage contradictoire). Ensuite, les échantillons d'entraînement augmentés (comprenant à la fois les échantillons d'origine et leurs voisins correspondants) sont transmis au réseau neuronal pour calculer leurs intégrations. La distance entre l'intégration d'un échantillon et celle de son voisin est calculée et utilisée comme perte de voisin, qui est traitée comme un terme de régularisation et ajoutée à la perte finale. Pour une régularisation explicite basée sur le voisin, nous calculons généralement la perte de voisin comme la distance entre l'intégration de l'échantillon et l'intégration du voisin. Cependant, n’importe quelle couche du réseau neuronal peut être utilisée pour calculer la perte de voisinage. D'autre part, pour la régularisation basée sur le voisin induit (adversaire), nous calculons la perte de voisin comme la distance entre la prédiction de sortie du voisin contradictoire induit et l'étiquette de vérité terrain.
Pourquoi utiliser NSL ?
NSL apporte les avantages suivants :
- Précision supérieure : le(s) signal(s) structuré(s) parmi les échantillons peuvent fournir des informations qui ne sont pas toujours disponibles dans les entrées de fonctionnalités ; par conséquent, il a été démontré que l'approche de formation conjointe (avec à la fois des signaux structurés et des fonctionnalités) surpasse de nombreuses méthodes existantes (qui reposent sur une formation avec des fonctionnalités uniquement) sur un large éventail de tâches, telles que la classification de documents et la classification d'intentions sémantiques ( Bui et al. ., WSDM'18 & Kipf et al., ICLR'17 ).
- Robustesse : les modèles entraînés avec des exemples contradictoires se sont révélés robustes face aux perturbations contradictoires conçues pour induire en erreur la prédiction ou la classification d'un modèle ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ). Lorsque le nombre d'échantillons d'entraînement est faible, l'entraînement avec des exemples contradictoires contribue également à améliorer la précision du modèle ( Tsipras et al., ICLR'19 ).
- Moins de données étiquetées requises : NSL permet aux réseaux de neurones d'exploiter à la fois des données étiquetées et non étiquetées, ce qui étend le paradigme d'apprentissage à l'apprentissage semi-supervisé . Plus précisément, NSL permet au réseau de s'entraîner à l'aide de données étiquetées comme dans un environnement supervisé, et en même temps amène le réseau à apprendre des représentations cachées similaires pour les « échantillons voisins » qui peuvent ou non avoir des étiquettes. Cette technique s'est révélée très prometteuse pour améliorer la précision du modèle lorsque la quantité de données étiquetées est relativement faible ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
Tutoriels étape par étape
Pour acquérir une expérience pratique de l'apprentissage structuré neuronal, nous proposons des didacticiels qui couvrent divers scénarios dans lesquels des signaux structurés peuvent être explicitement donnés, construits ou induits. En voici quelques-uns :
Régularisation de graphes pour la classification de documents à l'aide de graphes naturels . Dans ce didacticiel, nous explorons l'utilisation de la régularisation de graphe pour classer les documents qui forment un graphe naturel (organique).
Régularisation de graphiques pour la classification des sentiments à l'aide de graphiques synthétisés . Dans ce didacticiel, nous démontrons l'utilisation de la régularisation graphique pour classer les sentiments des critiques de films en construisant (synthétisant) des signaux structurés.
Apprentissage contradictoire pour la classification d'images . Dans ce didacticiel, nous explorons l'utilisation de l'apprentissage contradictoire (où des signaux structurés sont induits) pour classer les images contenant des chiffres numériques.
D'autres exemples et tutoriels peuvent être trouvés dans le répertoire d'exemples de notre référentiel GitHub.