
| | |  Voir la source sur GitHub Voir la source sur GitHub | | |
Aperçu
Ce bloc - notes classifie critiques de films comme positifs ou négatifs en utilisant le texte de l'examen. Ceci est un exemple de classification binaire, une sorte importante et largement applicable problème d'apprentissage de la machine.
Nous allons démontrer l'utilisation de la régularisation de graphe dans ce cahier en construisant un graphe à partir de l'entrée donnée. La recette générale pour construire un modèle de graphe régularisé à l'aide du framework Neural Structured Learning (NSL) lorsque l'entrée ne contient pas de graphe explicite est la suivante :
- Créez des incorporations pour chaque échantillon de texte dans l'entrée. Cela peut être fait en utilisant des modèles pré-formés tels que word2vec , pivotant , BERT etc.
- Construisez un graphique basé sur ces plongements en utilisant une métrique de similarité telle que la distance « L2 », la distance « cosinus », etc. Les nœuds du graphique correspondent aux échantillons et les arêtes du graphique correspondent à la similarité entre les paires d'échantillons.
- Générez des données d'entraînement à partir du graphique synthétisé ci-dessus et des exemples de caractéristiques. Les données d'apprentissage résultantes contiendront des caractéristiques voisines en plus des caractéristiques de nœud d'origine.
- Créez un réseau de neurones comme modèle de base à l'aide de l'API Keras séquentielle, fonctionnelle ou de sous-classe.
- Enveloppez le modèle de base avec la classe wrapper GraphRegularization, qui est fournie par le framework NSL, pour créer un nouveau modèle de graphe Keras. Ce nouveau modèle inclura une perte de régularisation de graphe comme terme de régularisation dans son objectif d'entraînement.
- Former et évaluer le modèle graphique Keras.
Exigences
- Installez le package d'apprentissage structuré neuronal.
- Installez tensorflow-hub.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
Dépendances et importations
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Jeu de données IMDB
Le jeu de données IMDB contient le texte de 50.000 critiques de films de la Internet Movie Database . Ceux-ci sont divisés en 25 000 avis pour la formation et 25 000 avis pour les tests. Les ensembles de formation et d' essai sont équilibrés, ce qui signifie qu'ils contiennent un nombre égal de commentaires positifs et négatifs.
Dans ce didacticiel, nous utiliserons une version prétraitée du jeu de données IMDB.
Télécharger le jeu de données IMDB prétraité
L'ensemble de données IMDB est fourni avec TensorFlow. Il a déjà été prétraité de telle sorte que les revues (séquences de mots) ont été converties en séquences d'entiers, où chaque entier représente un mot spécifique dans un dictionnaire.
Le code suivant télécharge l'ensemble de données IMDB (ou utilise une copie en cache s'il a déjà été téléchargé) :
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
L'argument num_words=10000 maintient les 10.000 premiers mots qui se produisent le plus souvent dans les données de formation. Les mots rares sont supprimés pour garder la taille du vocabulaire gérable.
Explorer les données
Prenons un moment pour comprendre le format des données. L'ensemble de données est prétraité : chaque exemple est un tableau d'entiers représentant les mots de la critique du film. Chaque étiquette est une valeur entière de 0 ou 1, où 0 est un avis négatif et 1 est un avis positif.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
Le texte des critiques a été converti en nombres entiers, où chaque entier représente un mot spécifique dans un dictionnaire. Voici à quoi ressemble le premier avis :
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
Les critiques de films peuvent être de durées différentes. Le code ci-dessous indique le nombre de mots dans les premier et deuxième avis. Étant donné que les entrées d'un réseau de neurones doivent avoir la même longueur, nous devrons résoudre ce problème plus tard.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
Convertir les nombres entiers en mots
Il peut être utile de savoir comment reconvertir les entiers en texte correspondant. Ici, nous allons créer une fonction d'assistance pour interroger un objet de dictionnaire qui contient le mappage entier vers chaîne :
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
Maintenant , nous pouvons utiliser la decode_review fonction pour afficher le texte pour la première évaluation:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
Construction graphique
La construction d'un graphique implique la création d'incorporations pour des échantillons de texte, puis l'utilisation d'une fonction de similarité pour comparer les incorporations.
Avant d'aller plus loin, nous créons d'abord un répertoire pour stocker les artefacts créés par ce didacticiel.
mkdir -p /tmp/imdb
Créer des exemples d'incorporations
Nous utiliserons incorporations pour créer Swivel incorporations pré - entraîné dans le tf.train.Example format pour chaque échantillon dans l'entrée. Nous conserverons les incorporations résultant du TFRecord le format long avec une fonctionnalité supplémentaire qui représente l'ID de chaque échantillon. Ceci est important et nous permettra de faire correspondre des exemples de plongements avec les nœuds correspondants dans le graphe plus tard.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
Construire un graphique
Maintenant que nous avons les exemples de plongements, nous allons les utiliser pour construire un graphe de similarité, c'est-à-dire que les nœuds de ce graphe correspondront aux échantillons et les arêtes de ce graphe correspondront à la similarité entre les paires de nœuds.
Neural Structured Learning fournit une bibliothèque de création de graphiques pour créer un graphique basé sur des exemples d'intégration. Il utilise la similarité cosinus comme la mesure de similarité pour comparer les incorporations et les bords de construction entre eux. Cela nous permet également de spécifier un seuil de similarité, qui peut être utilisé pour éliminer les arêtes dissemblables du graphe final. Dans cet exemple, en utilisant 0,99 comme seuil de similarité et 12345 comme graine aléatoire, nous nous retrouvons avec un graphique qui a 429 415 arêtes bidirectionnelles. Ici nous utilisons le soutien du constructeur graphique pour hachage sensible localité (LSH) pour accélérer la construction graphique. Pour plus de détails sur l' utilisation du support LSH du constructeur graphique, consultez la build_graph_from_config documentation de l' API.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
Chaque arête bidirectionnelle est représentée par deux arêtes dirigées dans le fichier TSV de sortie, de sorte que ce fichier contient 429 415 * 2 = 858 830 lignes au total :
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
Exemples de fonctionnalités
Nous créons des fonctionnalités exemples pour notre problème en utilisant le tf.train.Example le format et les persistons dans le TFRecord format. Chaque échantillon comprendra les trois caractéristiques suivantes :
- id: l'ID de noeud de l'échantillon.
- mots: Une liste de int64 contenant les identifiants de mots.
- Label: singleton int64 identifiant la classe cible de l'examen.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
Augmenter les données d'entraînement avec des voisins de graphe
Puisque nous avons les exemples de caractéristiques et le graphique synthétisé, nous pouvons générer les données d'entraînement augmentées pour l'apprentissage structuré neuronal. Le cadre NSL fournit une bibliothèque pour combiner le graphique et les exemples de caractéristiques afin de produire les données d'apprentissage finales pour la régularisation du graphique. Les données d'apprentissage résultantes incluront les caractéristiques d'échantillon d'origine ainsi que les caractéristiques de leurs voisins correspondants.
Dans ce didacticiel, nous considérons les arêtes non dirigées et utilisons un maximum de 3 voisins par échantillon pour augmenter les données d'apprentissage avec des voisins de graphe.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
Modèle de base
Nous sommes maintenant prêts à construire un modèle de base sans régularisation de graphe. Afin de construire ce modèle, nous pouvons soit utiliser les plongements qui ont été utilisés dans la construction du graphe, soit apprendre de nouveaux plongements conjointement avec la tâche de classification. Pour les besoins de ce cahier, nous allons faire ce dernier.
Variables globales
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
Hyperparamètres
Nous utiliserons une instance de HParams à diverses hyperparam'etres et inclue constantes utilisées pour la formation et l' évaluation. Nous les décrivons brièvement ci-dessous :
num_classes: Il y a 2 classes - positives et négatives.
max_seq_length: Ceci est le nombre maximum de mots considérés lors de chaque examen de film dans cet exemple.
vocab_size: Ceci est la taille du vocabulaire considéré pour cet exemple.
distance_type: Ceci est la distance métrique utilisée pour régulariser l'échantillon avec ses voisins.
graph_regularization_multiplier: Ce contrôle le poids relatif du terme de régularisation graphique dans la fonction globale de perte.
num_neighbors: Le nombre de voisins utilisés pour la régularisation du graphique. Cette valeur doit être inférieure ou égale à l'
max_nbrsargument utilisé ci - dessus lors de l' appelnsl.tools.pack_nbrs.num_fc_units: Le nombre d'unités dans la couche entièrement relié du réseau de neurones.
train_epochs: Le nombre d'époques de formation.
batch_size: Taille du lot utilisé pour la formation et l' évaluation.
eval_steps: Le nombre de lots à traiter avant de considérer l' évaluation est terminée. Si la valeur
None, toutes les instances du jeu de test sont évalués.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
Préparer les données
Les revues - les tableaux d'entiers - doivent être convertis en tenseurs avant d'être introduits dans le réseau de neurones. Cette conversion peut être effectuée de plusieurs manières :
Convertir les matrices dans des vecteurs de
0s et1s indiquant l' apparition de mots, semblable à un codage d'un chaud. Par exemple, la séquence[3, 5]deviendrait un10000vecteur qui est tous -dimensionnelle zéros à l' exception des indices3et5, qui sont ceux. Ensuite, faire de cette première couche dans notre réseau uneDensecouche qui peut gérer des données flottantes point de vecteur. Cette approche utilise beaucoup de mémoire, bien que, nécessitant unenum_words * num_reviewsmatrice de taille.Sinon, nous pouvons rembourrer les tableaux de sorte qu'ils ont tous la même longueur, puis créer un tenseur entier de forme
max_length * num_reviews. Nous pouvons utiliser une couche d'intégration capable de gérer cette forme en tant que première couche de notre réseau.
Dans ce tutoriel, nous utiliserons la deuxième approche.
Depuis les critiques de films doivent être de la même longueur, nous utiliserons la pad_sequence fonction définie ci - dessous pour normaliser les longueurs.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
Construire le modèle
Un réseau de neurones est créé en empilant des couches, ce qui nécessite deux décisions architecturales principales :
- Combien de couches utiliser dans le modèle ?
- Combien d'unités cachées à utiliser pour chaque couche?
Dans cet exemple, les données d'entrée consistent en un tableau d'indices de mots. Les étiquettes à prédire sont soit 0, soit 1.
Nous utiliserons un LSTM bidirectionnel comme modèle de base dans ce tutoriel.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
Les couches sont effectivement empilées séquentiellement pour construire le classificateur :
- La première couche est une
Inputcouche qui tire le vocabulaire codé entier. - La couche suivante est une
Embeddingcouche, qui prend le vocabulaire codé entier et recherche le vecteur enrobage pour chaque mot-index. Ces vecteurs sont appris en tant que trains miniatures. Les vecteurs ajoutent une dimension au tableau de sortie. Les dimensions résultantes sont les suivantes :(batch, sequence, embedding). - Ensuite, une couche LSTM bidirectionnelle renvoie un vecteur de sortie de longueur fixe pour chaque exemple.
- Ce vecteur de sortie de longueur fixe est canalisé à travers un (entièrement connecté
Densecouche) avec 64 unités cachées. - La dernière couche est densément connectée à un seul nœud de sortie. Utilisation de la
sigmoidfonction d'activation, cette valeur est un flotteur entre 0 et 1, ce qui représente une probabilité, ou le niveau de confiance.
Unités cachées
Le modèle ci - dessus a deux couches intermédiaires ou « cachée », entre l'entrée et la sortie, et ne contenant pas la Embedding couche. Le nombre de sorties (unités, nœuds ou neurones) est la dimension de l'espace de représentation pour la couche. En d'autres termes, la quantité de liberté que le réseau est autorisé lors de l'apprentissage d'une représentation interne.
Si un modèle a plus d'unités cachées (un espace de représentation de plus haute dimension) et/ou plus de couches, alors le réseau peut apprendre des représentations plus complexes. Cependant, cela rend le réseau plus coûteux en calcul et peut conduire à l'apprentissage de modèles indésirables, des modèles qui améliorent les performances sur les données d'entraînement mais pas sur les données de test. On appelle cela overfitting.
Fonction de perte et optimiseur
Un modèle a besoin d'une fonction de perte et d'un optimiseur pour l'entraînement. Comme il s'agit d' un problème de classification binaire et le modèle délivre une probabilité (une seule couche unité avec une activation sigmoïde), nous allons utiliser la binary_crossentropy fonction de perte.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Créer un ensemble de validation
Lors de l'entraînement, nous voulons vérifier l'exactitude du modèle sur des données qu'il n'a jamais vues auparavant. Créer un ensemble de validation en mettant à part une fraction des données de formation d' origine. (Pourquoi ne pas utiliser l'ensemble de test maintenant ? Notre objectif est de développer et de régler notre modèle en utilisant uniquement les données d'entraînement, puis d'utiliser les données de test une seule fois pour évaluer notre précision).
Dans ce didacticiel, nous prenons environ 10 % des échantillons d'entraînement initiaux (10 % de 2500) comme données étiquetées pour la formation et le reste comme données de validation. Étant donné que la répartition initiale du train/test était de 50/50 (25 000 échantillons chacun), la répartition effective du train/validation/test que nous avons maintenant est de 5/45/50.
Notez que 'train_dataset' a déjà été groupé et mélangé.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
Former le modèle
Entraînez le modèle en mini-lots. Pendant l'entraînement, surveillez la perte et la précision du modèle sur l'ensemble de validation :
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
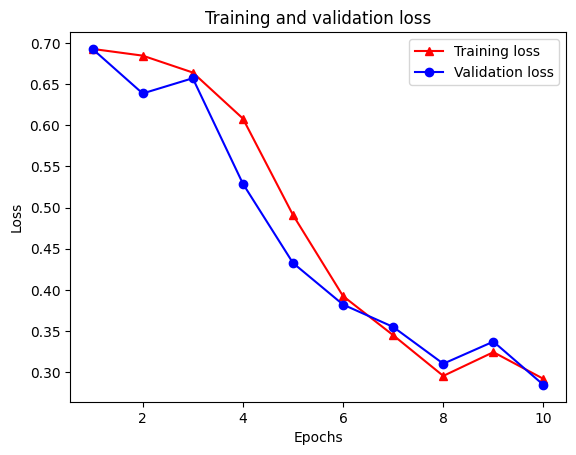
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
Évaluer le modèle
Voyons maintenant comment le modèle fonctionne. Deux valeurs seront renvoyées. Perte (un nombre qui représente notre erreur, les valeurs inférieures sont meilleures) et précision.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
Créer un graphique de précision/perte au fil du temps
model.fit() retourne une History objet qui contient un dictionnaire avec tout ce qui est arrivé lors de la formation:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Il y a quatre entrées : une pour chaque métrique surveillée pendant la formation et la validation. Nous pouvons les utiliser pour tracer la perte de formation et de validation à des fins de comparaison, ainsi que la précision de la formation et de la validation :
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
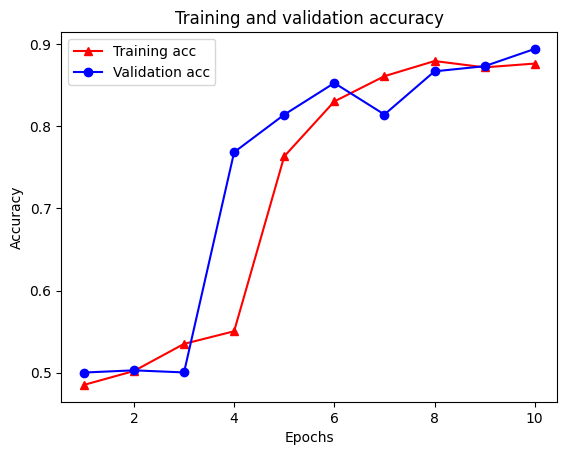
Notez que la perte de la formation diminue avec chaque époque et la précision formation augmente avec chaque époque. Ceci est attendu lors de l'utilisation d'une optimisation de descente de gradient - elle devrait minimiser la quantité souhaitée à chaque itération.
Régularisation des graphes
Nous sommes maintenant prêts à essayer la régularisation de graphe en utilisant le modèle de base que nous avons construit ci-dessus. Nous utiliserons la GraphRegularization classe enveloppe fournie par le cadre d' apprentissage structuré Neural pour envelopper le modèle de base (bi-LSTM) pour inclure la régularisation graphique. Les autres étapes d'apprentissage et d'évaluation du modèle à graphe régulier sont similaires à celles du modèle de base.
Créer un modèle à régularisation graphique
Pour évaluer l'avantage supplémentaire de la régularisation des graphes, nous allons créer une nouvelle instance de modèle de base. En effet , le model a déjà été formé pour quelques itérations, et réutiliser ce modèle formé pour créer un modèle régularisé graphique-ne sera pas une comparaison équitable pour model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Former le modèle
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
Évaluer le modèle
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
Créer un graphique de précision/perte au fil du temps
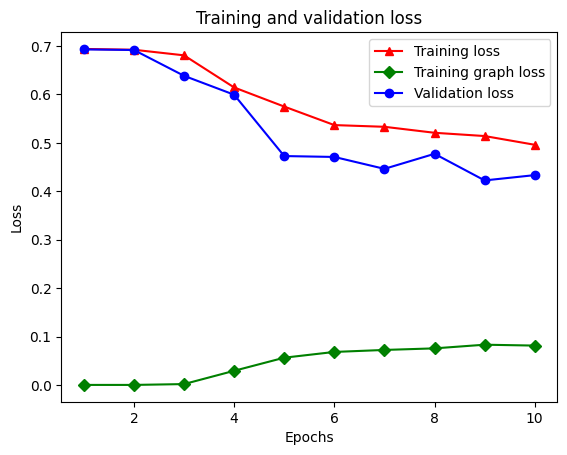
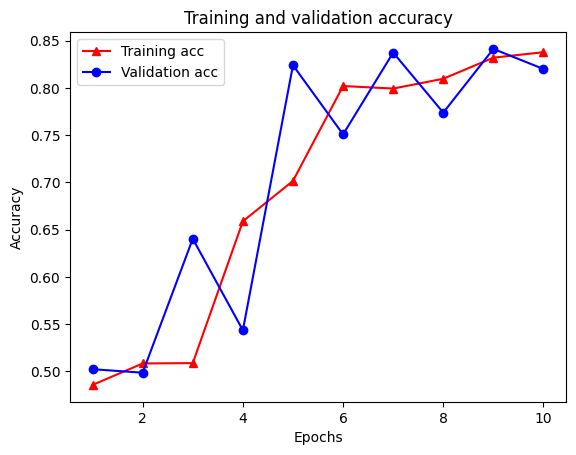
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
Il y a cinq entrées au total dans le dictionnaire : perte d'entraînement, précision d'entraînement, perte de graphique d'entraînement, perte de validation et précision de validation. Nous pouvons les tracer tous ensemble à des fins de comparaison. Notez que la perte de graphique n'est calculée que pendant l'apprentissage.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
La puissance de l'apprentissage semi-supervisé
L'apprentissage semi-supervisé et plus précisément, la régularisation de graphes dans le cadre de ce tutoriel, peut être vraiment puissant lorsque la quantité de données d'entraînement est faible. Le manque de données d'apprentissage est compensé en tirant parti de la similitude entre les échantillons d'apprentissage, ce qui n'est pas possible dans l'apprentissage supervisé traditionnel.
Nous définissons le rapport de surveillance comme le rapport des échantillons de formation au nombre total d'échantillons qui comprend la formation, la validation et des échantillons de test. Dans ce cahier, nous avons utilisé un ratio de supervision de 0,05 (c'est-à-dire 5 % des données étiquetées) pour entraîner à la fois le modèle de base et le modèle à graphe régularisé. Nous illustrons l'impact du ratio de supervision sur la précision du modèle dans la cellule ci-dessous.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
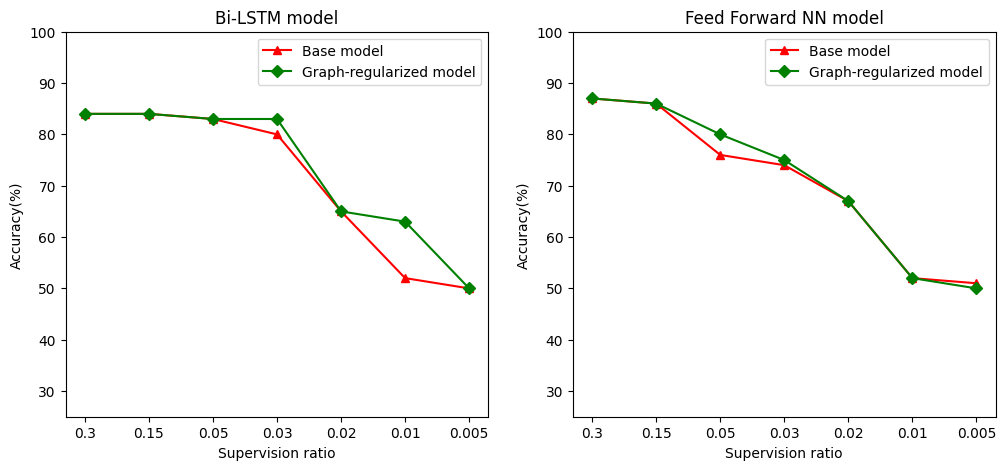
On peut observer que lorsque le taux de supervision diminue, la précision du modèle diminue également. Ceci est vrai à la fois pour le modèle de base et pour le modèle à graphe régularisé, quelle que soit l'architecture de modèle utilisée. Cependant, notez que le modèle graphe-régularisé fonctionne mieux que le modèle de base pour les deux architectures. En particulier, pour le modèle Bi-LSTM, lorsque le rapport de supervision est de 0,01, la précision du modèle régularisé graph-est de ~ 20% supérieure à celle du modèle de base. Ceci est principalement dû à l'apprentissage semi-supervisé pour le modèle à graphe régulier, où la similarité structurelle entre les échantillons d'apprentissage est utilisée en plus des échantillons d'apprentissage eux-mêmes.
Conclusion
Nous avons démontré l'utilisation de la régularisation de graphe à l'aide du framework Neural Structured Learning (NSL) même lorsque l'entrée ne contient pas de graphe explicite. Nous avons considéré la tâche de classification des sentiments des critiques de films IMDB pour laquelle nous avons synthétisé un graphique de similarité basé sur les intégrations de critiques. Nous encourageons les utilisateurs à expérimenter davantage en faisant varier les hyperparamètres, la quantité de supervision et en utilisant différentes architectures de modèles.