
O Neural Structured Learning (NSL) se concentra no treinamento de redes neurais profundas, aproveitando sinais estruturados (quando disponíveis) junto com entradas de recursos. Conforme introduzido por Bui et al. (WSDM'18) , esses sinais estruturados são usados para regularizar o treinamento de uma rede neural, forçando o modelo a aprender previsões precisas (minimizando a perda supervisionada), enquanto ao mesmo tempo mantém a similaridade estrutural de entrada (minimizando a perda do vizinho). , veja a figura abaixo). Essa técnica é genérica e pode ser aplicada em arquiteturas neurais arbitrárias (como NNs Feed-forward, NNs Convolucionais e NNs Recorrentes).
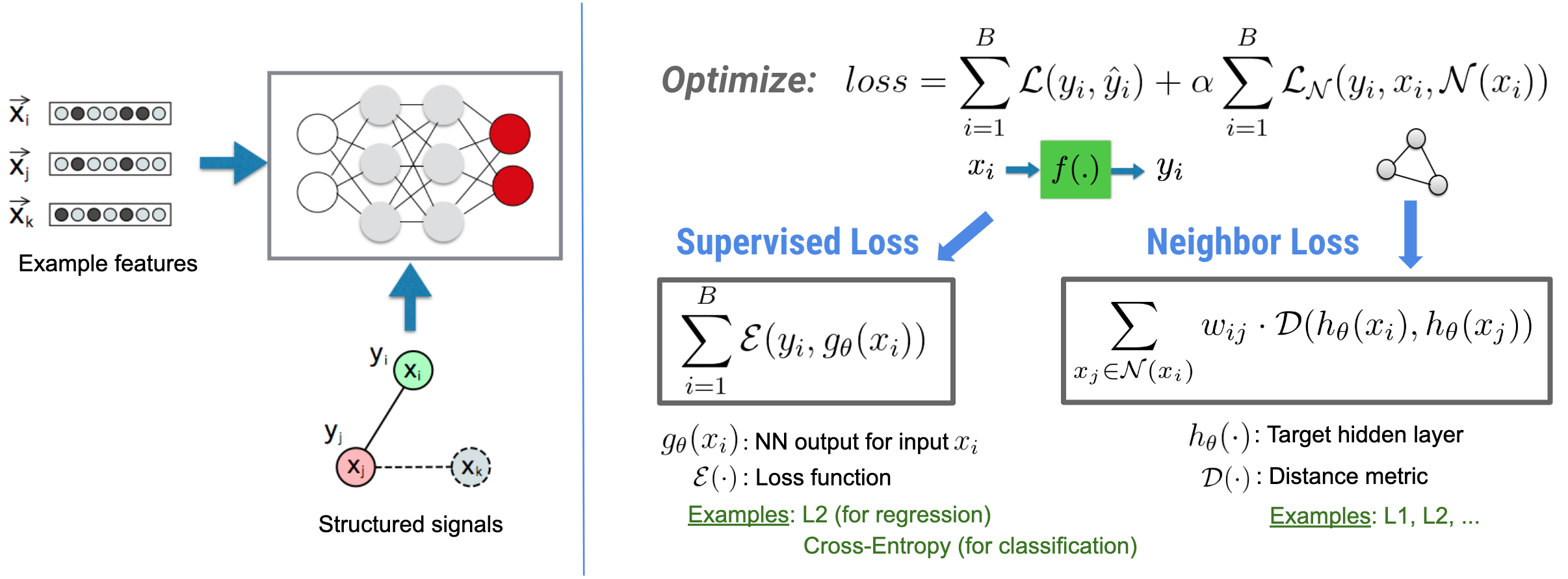
Observe que a equação de perda generalizada de vizinhos é flexível e pode ter outras formas além da ilustrada acima. Por exemplo, também podemos selecionar\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) para ser a perda do vizinho, que calcula a distância entre a verdade do terreno \(y_i\)e a previsão do vizinho \(g_\theta(x_j)\). Isso é comumente usado na aprendizagem adversária (Goodfellow et al., ICLR'15) . Portanto, NSL generaliza para Aprendizagem de Grafo Neural se os vizinhos são explicitamente representados por um grafo, e para Aprendizagem Adversarial se vizinhos são implicitamente induzidos por perturbação adversarial.
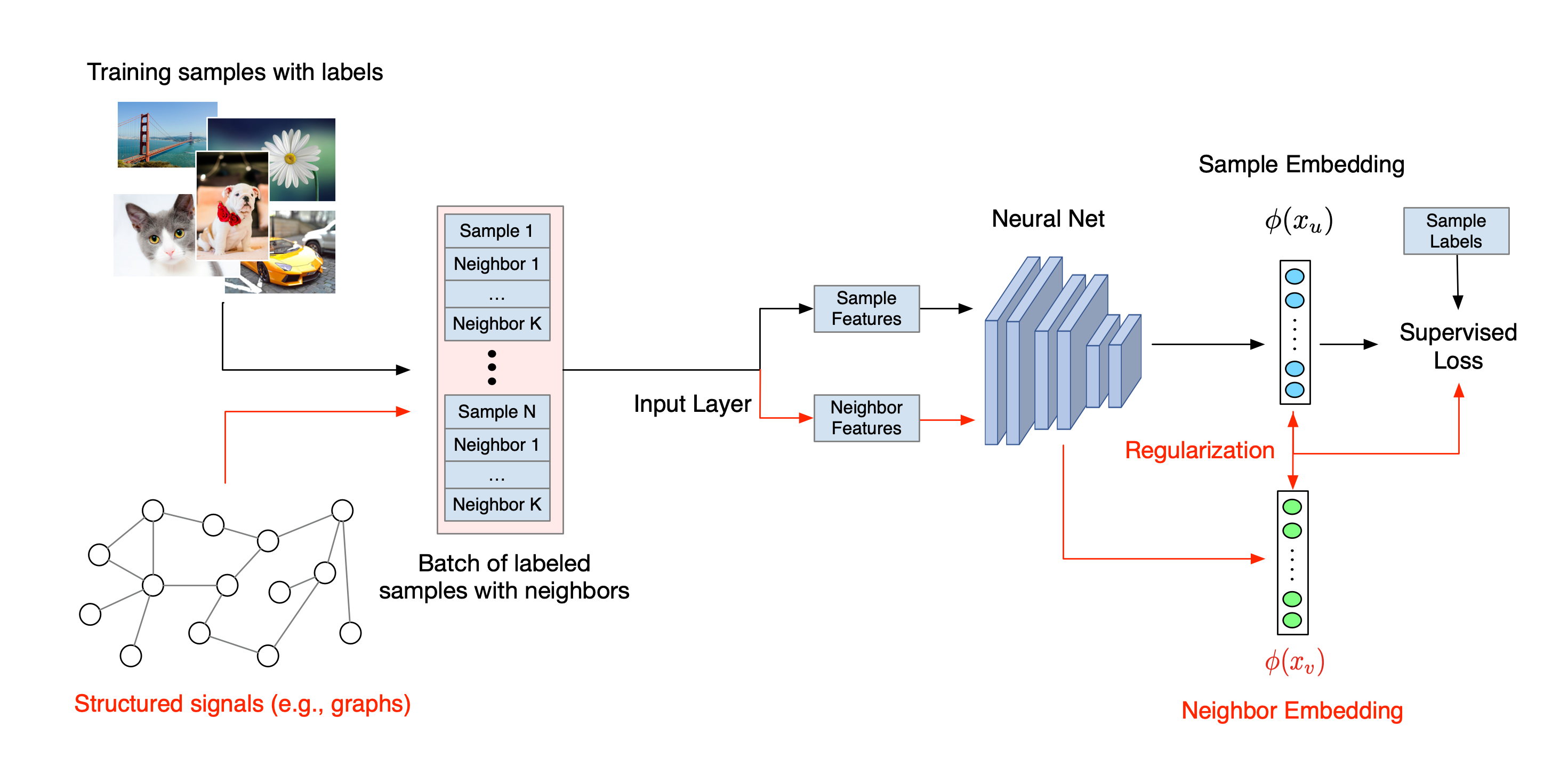
O fluxo de trabalho geral para o Aprendizado Estruturado Neural é ilustrado abaixo. As setas pretas representam o fluxo de trabalho de treinamento convencional e as setas vermelhas representam o novo fluxo de trabalho introduzido pela NSL para alavancar sinais estruturados. Primeiro, as amostras de treinamento são aumentadas para incluir sinais estruturados. Quando os sinais estruturados não são fornecidos explicitamente, eles podem ser construídos ou induzidos (o último se aplica ao aprendizado adversário). Em seguida, as amostras de treinamento aumentadas (incluindo as amostras originais e seus vizinhos correspondentes) são alimentadas à rede neural para calcular seus embeddings. A distância entre a incorporação de uma amostra e a incorporação de seu vizinho é calculada e utilizada como a perda do vizinho, que é tratada como um termo de regularização e adicionada à perda final. Para regularização baseada em vizinho explícito, normalmente calculamos a perda de vizinho como a distância entre a incorporação da amostra e a incorporação do vizinho. No entanto, qualquer camada da rede neural pode ser usada para calcular a perda do vizinho. Por outro lado, para regularização baseada no vizinho induzido (adversarial), calculamos a perda do vizinho como a distância entre a previsão de saída do vizinho adversário induzido e o rótulo de verdade.
Por que usar o NSL?
A NSL traz as seguintes vantagens:
- Maior precisão : os sinais estruturados entre as amostras podem fornecer informações que nem sempre estão disponíveis nas entradas de recursos; Portanto, a abordagem de treinamento conjunto (com sinais estruturados e recursos) demonstrou superar muitos métodos existentes (que dependem de treinamento apenas com recursos) em uma ampla gama de tarefas, como classificação de documentos e classificação de intenção semântica ( Bui et al. ., WSDM'18 & Kipf et al., ICLR'17 ).
- Robustez : modelos treinados com exemplos adversários demonstraram ser robustos contra perturbações adversárias projetadas para enganar a previsão ou classificação de um modelo ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ). Quando o número de amostras de treinamento é pequeno, o treinamento com exemplos adversários também ajuda a melhorar a precisão do modelo ( Tsipras et al., ICLR'19 ).
- Dados menos rotulados necessários : o NSL permite que as redes neurais aproveitem dados rotulados e não rotulados, o que estende o paradigma de aprendizado para aprendizado semissupervisionado . Especificamente, o NSL permite que a rede treine usando dados rotulados como na configuração supervisionada e, ao mesmo tempo, leva a rede a aprender representações ocultas semelhantes para as "amostras vizinhas" que podem ou não ter rótulos. Esta técnica mostrou uma grande promessa para melhorar a precisão do modelo quando a quantidade de dados rotulados é relativamente pequena ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
Tutoriais passo a passo
Para obter experiência prática com Aprendizado Estruturado Neural, temos tutoriais que cobrem vários cenários em que sinais estruturados podem ser dados, construídos ou induzidos explicitamente. Aqui estão alguns:
Regularização de grafos para classificação de documentos usando grafos naturais . Neste tutorial, exploramos o uso da regularização de grafos para classificar documentos que formam um grafo natural (orgânico).
Regularização de grafos para classificação de sentimentos utilizando grafos sintetizados . Neste tutorial, demonstramos o uso da regularização de grafos para classificar os sentimentos de resenhas de filmes construindo (sintetizando) sinais estruturados.
Aprendizagem adversarial para classificação de imagens . Neste tutorial, exploramos o uso de aprendizagem adversarial (onde sinais estruturados são induzidos) para classificar imagens contendo dígitos numéricos.
Mais exemplos e tutoriais podem ser encontrados no diretório de exemplos do nosso repositório GitHub.