
| | |  Ver fonte no GitHub Ver fonte no GitHub | | |
Visão geral
Este filme classifica notebook opiniões como positivo ou negativo usando o texto da revisão. Este é um exemplo de classificação binária, um tipo importante e amplamente aplicáveis de problema de aprendizagem de máquina.
Demonstraremos o uso de regularização de gráfico neste bloco de notas construindo um gráfico a partir da entrada fornecida. A receita geral para construir um modelo regularizado por gráfico usando o framework Neural Structured Learning (NSL) quando a entrada não contém um gráfico explícito é a seguinte:
- Crie embeddings para cada amostra de texto na entrada. Isso pode ser feito usando modelos pré-treinados como word2vec , Swivel , BERT etc.
- Construa um gráfico com base nesses embeddings usando uma métrica de similaridade, como a distância 'L2', distância 'cosseno', etc. Os nós no gráfico correspondem a amostras e as bordas no gráfico correspondem à similaridade entre pares de amostras.
- Gere dados de treinamento a partir do gráfico sintetizado acima e dos recursos de amostra. Os dados de treinamento resultantes conterão recursos vizinhos, além dos recursos do nó original.
- Crie uma rede neural como modelo básico usando a API sequencial, funcional ou de subclasse de Keras.
- Envolva o modelo básico com a classe wrapper GraphRegularization, que é fornecida pela estrutura NSL, para criar um novo modelo Keras de gráfico. Este novo modelo incluirá uma perda de regularização de gráfico como termo de regularização em seu objetivo de treinamento.
- Treine e avalie o modelo gráfico de Keras.
Requisitos
- Instale o pacote Neural Structured Learning.
- Instale o tensorflow-hub.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
Dependências e importações
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Conjunto de dados IMDB
O conjunto de dados IMDB contém o texto de 50.000 revisões de filme da Internet Movie Database . Elas são divididas em 25.000 análises para treinamento e 25.000 análises para teste. Os conjuntos de treinamento e teste são equilibradas, o que significa que contêm o mesmo número de comentários positivos e negativos.
Neste tutorial, usaremos uma versão pré-processada do conjunto de dados IMDB.
Baixe o conjunto de dados IMDB pré-processado
O conjunto de dados IMDB vem empacotado com TensorFlow. Já foi pré-processado de forma que as resenhas (sequências de palavras) foram convertidas em sequências de inteiros, onde cada inteiro representa uma palavra específica em um dicionário.
O código a seguir baixa o conjunto de dados IMDB (ou usa uma cópia em cache se já tiver sido baixado):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
O argumento num_words=10000 mantém os principais 10.000 palavras que ocorrem mais frequentemente nos dados de treinamento. As palavras raras são descartadas para manter o tamanho do vocabulário gerenciável.
Explore os dados
Vamos dedicar um momento para entender o formato dos dados. O conjunto de dados vem pré-processado: cada exemplo é um array de inteiros que representam as palavras da crítica do filme. Cada rótulo é um valor inteiro de 0 ou 1, onde 0 é uma revisão negativa e 1 é uma revisão positiva.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
O texto das resenhas foi convertido em inteiros, onde cada inteiro representa uma palavra específica em um dicionário. Esta é a aparência da primeira revisão:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
As resenhas de filmes podem ter durações diferentes. O código a seguir mostra o número de palavras na primeira e na segunda revisões. Como as entradas de uma rede neural devem ter o mesmo comprimento, precisaremos resolver isso mais tarde.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
Converta os inteiros de volta em palavras
Pode ser útil saber como converter números inteiros de volta ao texto correspondente. Aqui, criaremos uma função auxiliar para consultar um objeto de dicionário que contém o inteiro para mapeamento de string:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
Agora podemos usar o decode_review função para exibir o texto para a primeira revisão:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
Construção de gráfico
A construção do gráfico envolve a criação de embeddings para amostras de texto e, em seguida, o uso de uma função de similaridade para comparar os embeddings.
Antes de prosseguir, primeiro criamos um diretório para armazenar artefatos criados por este tutorial.
mkdir -p /tmp/imdb
Crie exemplos de embeddings
Usaremos embeddings giro pré-treinado para criar embeddings na tf.train.Example formato para cada amostra na entrada. Nós iremos guardar as incorporações resultantes no TFRecord formato juntamente com um recurso adicional que representa o ID de cada amostra. Isso é importante e nos permitirá combinar os embeddings de amostra com os nós correspondentes no gráfico posteriormente.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
Construir um gráfico
Agora que temos os embeddings de amostra, iremos usá-los para construir um grafo de similaridade, ou seja, os nós neste grafo corresponderão às amostras e as arestas neste grafo corresponderão à similaridade entre pares de nós.
O Neural Structured Learning fornece uma biblioteca de construção de gráficos para construir um gráfico com base em exemplos de embeddings. Ele usa similaridade do cosseno como a medida de similaridade para comparar embeddings e bordas construção entre eles. Também nos permite especificar um limite de similaridade, que pode ser usado para descartar arestas diferentes do gráfico final. Neste exemplo, usando 0,99 como o limite de similaridade e 12345 como a semente aleatória, terminamos com um gráfico que tem 429.415 arestas bidirecionais. Aqui nós estamos usando o suporte do construtor gráfico para sensíveis à localidade hashing (LSH) para acelerar a construção de gráfico. Para mais detalhes sobre o uso do suporte LSH do construtor gráfico, veja o build_graph_from_config documentação da API.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
Cada borda bidirecional é representada por duas bordas direcionadas no arquivo TSV de saída, de modo que o arquivo contenha 429.415 * 2 = 858.830 linhas no total:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
Recursos de amostra
Nós criar recursos de exemplo para o nosso problema usando o tf.train.Example formato e persistem-los no TFRecord formato. Cada amostra incluirá os três recursos a seguir:
- ID: O ID do nó da amostra.
- palavras: Uma lista int64 contendo IDs de palavra.
- etiqueta: Um singleton int64 identificar a classe de destino da revisão.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
Aumente os dados de treinamento com os vizinhos do gráfico
Como temos os recursos de amostra e o gráfico sintetizado, podemos gerar os dados de treinamento aumentados para o Aprendizado Neural Estruturado. A estrutura NSL fornece uma biblioteca para combinar o gráfico e os recursos de amostra para produzir os dados de treinamento finais para a regularização do gráfico. Os dados de treinamento resultantes incluirão recursos de amostra originais, bem como recursos de seus vizinhos correspondentes.
Neste tutorial, consideramos bordas não direcionadas e usamos no máximo 3 vizinhos por amostra para aumentar os dados de treinamento com os vizinhos do gráfico.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
Modelo básico
Agora estamos prontos para construir um modelo básico sem regularização de gráfico. Para construir este modelo, podemos usar embeddings que foram usados na construção do gráfico ou podemos aprender novos embeddings juntamente com a tarefa de classificação. Para o propósito deste bloco de notas, faremos o último.
Variáveis globais
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
Hiperparâmetros
Vamos usar um exemplo de HParams para inclue vários hiperparâmetros e constantes utilizadas para treinamento e avaliação. Descrevemos resumidamente cada um deles abaixo:
num_classes: Há 2 classes - positivo e negativo.
max_seq_length: Este é o número máximo de palavras consideradas de cada resenha do filme neste exemplo.
vocab_size: Este é o tamanho do vocabulário considerado para este exemplo.
distance_type: Esta é a distância métrica utilizada para regularizar a amostra com seus vizinhos.
graph_regularization_multiplier: Este controla o peso relativo do termo gráfico regularização na função global de perda.
num_neighbors: O número de vizinhos utilizados para regularização gráfico. Este valor tem de ser inferior ou igual ao
max_nbrsargumento usado acima ao invocarnsl.tools.pack_nbrs.num_fc_units: O número de unidades na camada completamente ligada da rede neural.
train_epochs: O número de épocas de treinamento.
Tamanho do lote usado para treinamento e avaliação: batch_size.
eval_steps: O número de lotes para processo antes julgando avaliação for concluída. Se definido para
None, todas as instâncias do conjunto de teste são avaliados.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
Prepare os dados
As revisões - as matrizes de inteiros - devem ser convertidas em tensores antes de serem alimentadas na rede neural. Essa conversão pode ser feita de duas maneiras:
Converter as matrizes em vectores de
0s e1s, indicando a ocorrência da palavra, semelhante a um de uma codificação quente. Por exemplo, a sequência de[3, 5]se tornaria um10000vector -dimensional que é todos os zeros excepto para os índices3e5, que são aqueles. Então, faça esta a primeira camada em nossa rede de umaDensecamada que pode lidar com dados de ponto flutuante do vetor. Esta abordagem é intensivo de memória, no entanto, a necessidade de umnum_words * num_reviewsmatriz de tamanho.Alternativamente, podemos almofada as matrizes, de forma que todos têm o mesmo comprimento, então, criar um tensor número inteiro de forma
max_length * num_reviews. Podemos usar uma camada de incorporação capaz de lidar com essa forma como a primeira camada em nossa rede.
Neste tutorial, usaremos a segunda abordagem.
Desde as críticas de filmes devem ter o mesmo comprimento, vamos usar o pad_sequence função definida abaixo para padronizar os comprimentos.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
Construir o modelo
Uma rede neural é criada empilhando camadas - isso requer duas decisões arquitetônicas principais:
- Quantas camadas usar no modelo?
- Quantas unidades escondido para usar para cada camada?
Neste exemplo, os dados de entrada consistem em uma matriz de índices de palavras. Os rótulos a prever são 0 ou 1.
Usaremos um LSTM bidirecional como nosso modelo base neste tutorial.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
As camadas são efetivamente empilhadas sequencialmente para construir o classificador:
- A primeira camada é uma
Inputcamada que toma o vocabulário codificado por inteiro. - A camada seguinte é uma
Embeddingcamada, a qual leva o vocabulário e aparência codificado-inteiro-se o vector de incorporação para cada palavra-índice. Esses vetores são aprendidos à medida que o modelo treina. Os vetores adicionam uma dimensão ao array de saída. As dimensões resultantes são:(batch, sequence, embedding). - Em seguida, uma camada LSTM bidirecional retorna um vetor de saída de comprimento fixo para cada exemplo.
- Este vector de saída de comprimento fixo é canalizada através de uma totalmente ligado (
Densecamada) com 64 unidades escondidos. - A última camada está densamente conectada a um único nó de saída. Usando o
sigmoidfunção de activação, este valor é um flutuador entre 0 e 1, que representa uma probabilidade, ou nível de confiança.
Unidades ocultas
O modelo acima tem dois ou camadas intermédias "ocultas", entre a entrada ea saída, e excluindo a Embedding camada. O número de saídas (unidades, nós ou neurônios) é a dimensão do espaço representacional para a camada. Em outras palavras, a quantidade de liberdade que a rede tem ao aprender uma representação interna.
Se um modelo tiver mais unidades ocultas (um espaço de representação de dimensão superior) e / ou mais camadas, a rede pode aprender representações mais complexas. No entanto, torna a rede mais cara computacionalmente e pode levar ao aprendizado de padrões indesejados - padrões que melhoram o desempenho nos dados de treinamento, mas não nos dados de teste. Isso é chamado overfitting.
Função de perda e otimizador
Um modelo precisa de uma função de perda e um otimizador para treinamento. Uma vez que este é um problema de classificação binária eo modelo de saídas uma probabilidade (a camada única unidade com um ativação sigmóide), usaremos o binary_crossentropy função de perda.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Crie um conjunto de validação
Ao treinar, queremos verificar a precisão do modelo em dados que não vimos antes. Criar um conjunto de validação, definindo além uma fração dos dados de treinamento originais. (Por que não usar o conjunto de teste agora? Nosso objetivo é desenvolver e ajustar nosso modelo usando apenas os dados de treinamento e, em seguida, usar os dados de teste apenas uma vez para avaliar nossa precisão).
Neste tutorial, pegamos cerca de 10% das amostras de treinamento inicial (10% de 25.000) como dados rotulados para treinamento e o restante como dados de validação. Uma vez que a divisão de treinamento / teste inicial foi 50/50 (25.000 amostras cada), a divisão de treinamento / validação / teste efetiva que temos agora é 5/45/50.
Observe que 'train_dataset' já foi agrupado e embaralhado.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
Treine o modelo
Treine o modelo em minilotes. Durante o treinamento, monitore a perda e a precisão do modelo no conjunto de validação:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
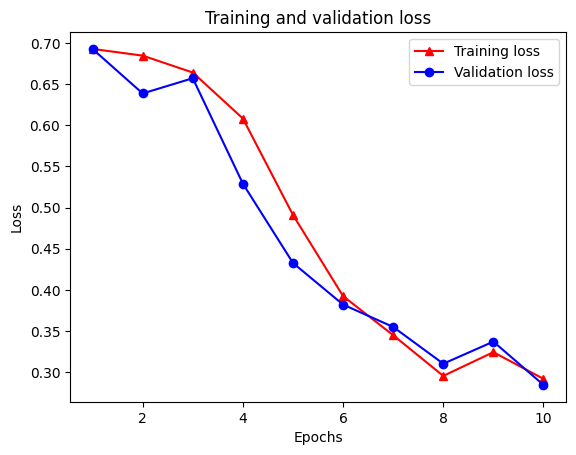
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
Avalie o modelo
Agora, vamos ver como o modelo funciona. Dois valores serão retornados. Perda (um número que representa nosso erro, valores mais baixos são melhores) e precisão.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
Crie um gráfico de precisão / perda ao longo do tempo
model.fit() retorna uma History objeto que contém um dicionário com tudo o que aconteceu durante o treinamento:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Existem quatro entradas: uma para cada métrica monitorada durante o treinamento e a validação. Podemos usá-los para traçar a perda de treinamento e validação para comparação, bem como a precisão do treinamento e da validação:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
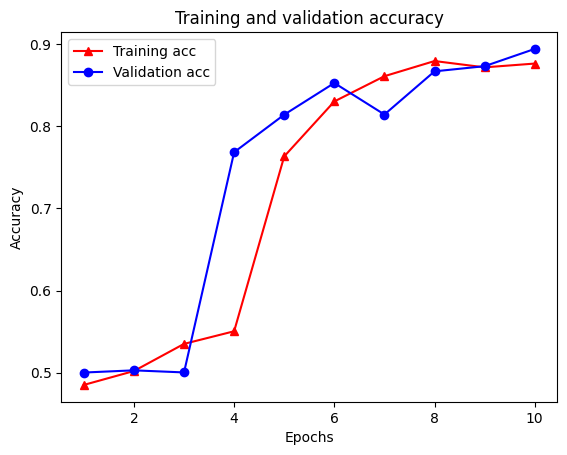
Observe a perda de formação diminui com cada época ea precisão de treinamento aumenta com cada época. Isso é esperado ao usar uma otimização de gradiente descendente - deve minimizar a quantidade desejada em cada iteração.
Regularização de grafos
Agora estamos prontos para tentar a regularização de gráfico usando o modelo básico que construímos acima. Nós vamos usar o GraphRegularization classe wrapper fornecido pela estrutura de aprendizagem estruturado Neural para embrulhar o modelo base (bi-LSTM) para incluir o gráfico de regularização. O restante das etapas para treinar e avaliar o modelo regularizado por gráfico são semelhantes às do modelo básico.
Crie um modelo regularizado por gráfico
Para avaliar o benefício incremental da regularização do gráfico, criaremos uma nova instância do modelo base. Isto é porque model já foi treinado por algumas iterações, e reutilizar este modelo treinados para criar um modelo regularizado-gráfico não será uma comparação justa para model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Treine o modelo
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
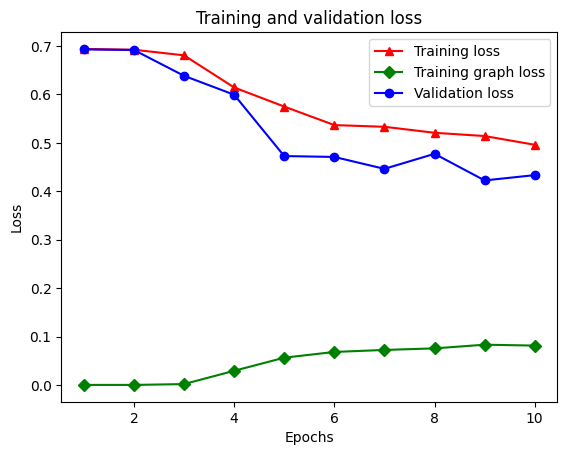
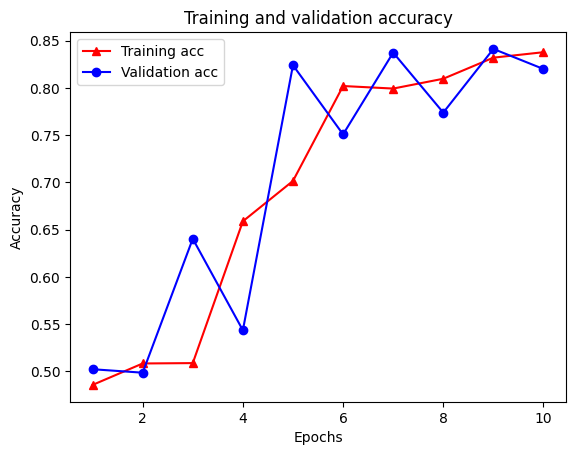
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
Avalie o modelo
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
Crie um gráfico de precisão / perda ao longo do tempo
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
Há cinco entradas no total no dicionário: perda de treinamento, precisão de treinamento, perda de gráfico de treinamento, perda de validação e precisão de validação. Podemos representá-los todos juntos para comparação. Observe que a perda do gráfico só é calculada durante o treinamento.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
O poder da aprendizagem semissupervisionada
O aprendizado semissupervisionado e, mais especificamente, a regularização de gráfico no contexto deste tutorial, pode ser muito poderoso quando a quantidade de dados de treinamento é pequena. A falta de dados de treinamento é compensada pelo aproveitamento da similaridade entre as amostras de treinamento, o que não é possível no aprendizado supervisionado tradicional.
Nós definimos proporção controlo, tal como a proporção de formação de amostras para o número total de amostras que inclui a formação, a validação, e amostras de teste. Neste notebook, usamos uma taxa de supervisão de 0,05 (ou seja, 5% dos dados rotulados) para treinar tanto o modelo básico quanto o modelo regularizado por gráfico. Ilustramos o impacto da taxa de supervisão na precisão do modelo na célula abaixo.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
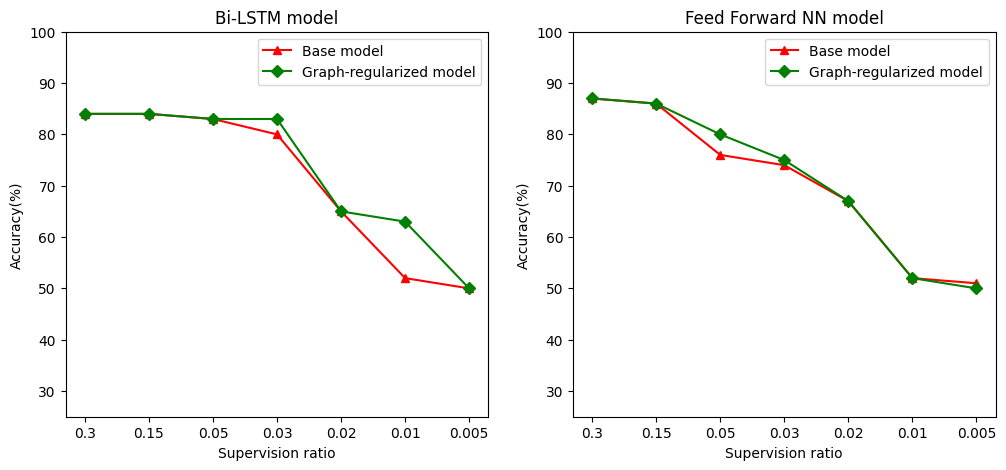
Pode-se observar que conforme a razão de superivisão diminui, a precisão do modelo também diminui. Isso é verdadeiro para o modelo básico e para o modelo regularizado por gráfico, independentemente da arquitetura do modelo usada. No entanto, observe que o modelo regularizado por gráfico tem um desempenho melhor do que o modelo básico para ambas as arquiteturas. Em particular, para o modelo de Bi-LSTM, quando a relação de supervisão é 0,01, a precisão do modelo regularizado-gráfico é ~ 20% mais elevada do que a do modelo de base. Isso se deve principalmente ao aprendizado semissupervisionado para o modelo regularizado por gráfico, em que a similaridade estrutural entre as amostras de treinamento é usada além das próprias amostras de treinamento.
Conclusão
Demonstramos o uso de regularização de gráfico usando o framework Neural Structured Learning (NSL), mesmo quando a entrada não contém um gráfico explícito. Consideramos a tarefa de classificação de sentimento das resenhas de filmes do IMDB para as quais sintetizamos um gráfico de similaridade baseado em embeddings de resenhas. Incentivamos os usuários a experimentar mais, variando os hiperparâmetros, a quantidade de supervisão e usando diferentes arquiteturas de modelo.