
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Dans cet exemple, vous explorerez le résultat de McClean, 2019 qui dit que n'importe quelle structure de réseau neuronal quantique fonctionnera bien en matière d'apprentissage. En particulier, vous verrez qu'une certaine grande famille de circuits quantiques aléatoires ne sert pas de bons réseaux de neurones quantiques, car ils ont des gradients qui disparaissent presque partout. Dans cet exemple, vous n'entraînerez aucun modèle pour un problème d'apprentissage spécifique, mais vous vous concentrerez plutôt sur le problème plus simple de la compréhension des comportements des gradients.
Installer
pip install tensorflow==2.7.0
Installez TensorFlow Quantum :
pip install tensorflow-quantum
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Importez maintenant TensorFlow et les dépendances du module :
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
np.random.seed(1234)
2022-02-04 12:15:43.355568: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. Résumé
Circuits quantiques aléatoires avec de nombreux blocs qui ressemblent à ceci (\(R_{P}(\theta)\) est une rotation de Pauli aléatoire) :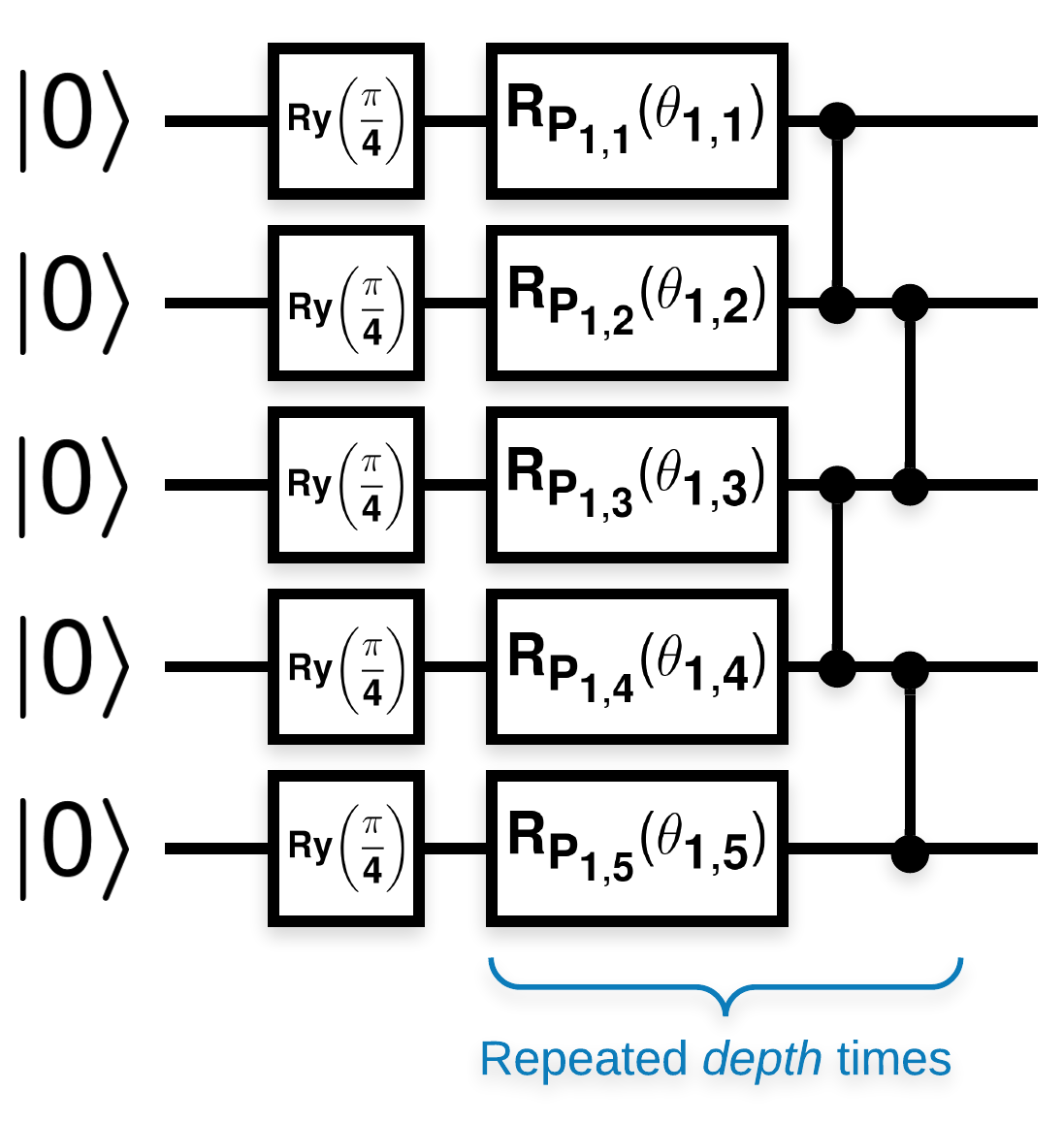
Où si \(f(x)\) est défini comme la valeur attendue par rapport \(Z_{a}Z_{b}\) pour tous les qubits \(a\) et \(b\), alors il y a un problème que \(f'(x)\) a une moyenne très proche de 0 et ne varie pas beaucoup. Vous verrez ceci ci-dessous :
2. Génération de circuits aléatoires
La construction de l'article est simple à suivre. Ce qui suit implémente une fonction simple qui génère un circuit quantique aléatoire - parfois appelé réseau de neurones quantiques (QNN) - avec la profondeur donnée sur un ensemble de qubits :
def generate_random_qnn(qubits, symbol, depth):
"""Generate random QNN's with the same structure from McClean et al."""
circuit = cirq.Circuit()
for qubit in qubits:
circuit += cirq.ry(np.pi / 4.0)(qubit)
for d in range(depth):
# Add a series of single qubit rotations.
for i, qubit in enumerate(qubits):
random_n = np.random.uniform()
random_rot = np.random.uniform(
) * 2.0 * np.pi if i != 0 or d != 0 else symbol
if random_n > 2. / 3.:
# Add a Z.
circuit += cirq.rz(random_rot)(qubit)
elif random_n > 1. / 3.:
# Add a Y.
circuit += cirq.ry(random_rot)(qubit)
else:
# Add a X.
circuit += cirq.rx(random_rot)(qubit)
# Add CZ ladder.
for src, dest in zip(qubits, qubits[1:]):
circuit += cirq.CZ(src, dest)
return circuit
generate_random_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2)
Les auteurs étudient le gradient d'un seul paramètre \(\theta_{1,1}\). Continuons en plaçant un sympy.Symbol dans le circuit où \(\theta_{1,1}\) . Étant donné que les auteurs n'analysent les statistiques d'aucun autre symbole du circuit, remplaçons-les par des valeurs aléatoires maintenant plutôt que plus tard.
3. Exécution des circuits
Générez quelques-uns de ces circuits avec un observable pour tester l'affirmation selon laquelle les gradients ne varient pas beaucoup. Tout d'abord, générez un lot de circuits aléatoires. Choisissez une observable ZZ aléatoire et calculez par lots les gradients et la variance à l'aide de TensorFlow Quantum.
3.1 Calcul de la variance par lot
Écrivons une fonction d'assistance qui calcule la variance du gradient d'un observable donné sur un lot de circuits :
def process_batch(circuits, symbol, op):
"""Compute the variance of a batch of expectations w.r.t. op on each circuit that
contains `symbol`. Note that this method sets up a new compute graph every time it is
called so it isn't as performant as possible."""
# Setup a simple layer to batch compute the expectation gradients.
expectation = tfq.layers.Expectation()
# Prep the inputs as tensors
circuit_tensor = tfq.convert_to_tensor(circuits)
values_tensor = tf.convert_to_tensor(
np.random.uniform(0, 2 * np.pi, (n_circuits, 1)).astype(np.float32))
# Use TensorFlow GradientTape to track gradients.
with tf.GradientTape() as g:
g.watch(values_tensor)
forward = expectation(circuit_tensor,
operators=op,
symbol_names=[symbol],
symbol_values=values_tensor)
# Return variance of gradients across all circuits.
grads = g.gradient(forward, values_tensor)
grad_var = tf.math.reduce_std(grads, axis=0)
return grad_var.numpy()[0]
3.1 Configurer et exécuter
Choisissez le nombre de circuits aléatoires à générer ainsi que leur profondeur et la quantité de qubits sur lesquels ils doivent agir. Tracez ensuite les résultats.
n_qubits = [2 * i for i in range(2, 7)
] # Ranges studied in paper are between 2 and 24.
depth = 50 # Ranges studied in paper are between 50 and 500.
n_circuits = 200
theta_var = []
for n in n_qubits:
# Generate the random circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_random_qnn(qubits, symbol, depth) for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.title('Gradient Variance in QNNs')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:5 out of the last 5 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
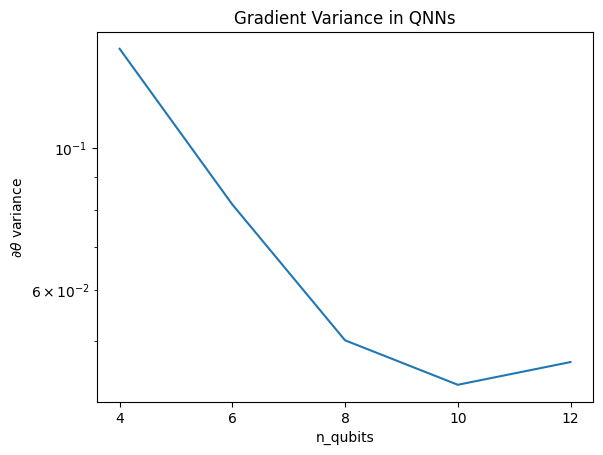
Ce graphique montre que pour les problèmes d'apprentissage automatique quantique, vous ne pouvez pas simplement deviner un ansatz QNN aléatoire et espérer le meilleur. Une certaine structure doit être présente dans le circuit modèle pour que les gradients varient au point où l'apprentissage peut se produire.
4. Heuristique
Une heuristique intéressante de Grant, 2019 permet de démarrer très proche du hasard, mais pas tout à fait. Utilisant les mêmes circuits que McClean et al., les auteurs proposent une technique d'initialisation différente pour les paramètres de contrôle classiques afin d'éviter les plateaux stériles. La technique d'initialisation démarre certaines couches avec des paramètres de contrôle totalement aléatoires, mais, dans les couches qui suivent immédiatement, choisissez des paramètres tels que la transformation initiale effectuée par les premières couches soit annulée. Les auteurs appellent cela un bloc d'identité .
L'avantage de cette heuristique est qu'en ne modifiant qu'un seul paramètre, tous les autres blocs en dehors du bloc actuel resteront l'identité - et le signal de gradient est beaucoup plus fort qu'auparavant. Cela permet à l'utilisateur de choisir les variables et les blocs à modifier pour obtenir un signal de gradient fort. Cette heuristique n'empêche pas l'utilisateur de tomber dans un plateau stérile pendant la phase d'entraînement (et restreint une mise à jour entièrement simultanée), elle garantit simplement que vous pouvez commencer en dehors d'un plateau.
4.1 Nouvelle construction QNN
Construisez maintenant une fonction pour générer des QNN de bloc d'identité. Cette implémentation est légèrement différente de celle du papier. Pour l'instant, regardez le comportement du gradient d'un seul paramètre afin qu'il soit cohérent avec McClean et al, afin que certaines simplifications puissent être apportées.
Pour générer un bloc d'identité et former le modèle, vous avez généralement besoin \(U1(\theta_{1a}) U1(\theta_{1b})^{\dagger}\) et non \(U1(\theta_1) U1(\theta_1)^{\dagger}\). Initialement \(\theta_{1a}\) et \(\theta_{1b}\) sont les mêmes angles mais ils sont appris indépendamment. Sinon, vous obtiendrez toujours l'identité même après la formation. Le choix du nombre de blocs d'identité est empirique. Plus le bloc est profond, plus la variance au milieu du bloc est petite. Mais au début et à la fin du bloc, la variance des gradients de paramètres doit être importante.
def generate_identity_qnn(qubits, symbol, block_depth, total_depth):
"""Generate random QNN's with the same structure from Grant et al."""
circuit = cirq.Circuit()
# Generate initial block with symbol.
prep_and_U = generate_random_qnn(qubits, symbol, block_depth)
circuit += prep_and_U
# Generate dagger of initial block without symbol.
U_dagger = (prep_and_U[1:])**-1
circuit += cirq.resolve_parameters(
U_dagger, param_resolver={symbol: np.random.uniform() * 2 * np.pi})
for d in range(total_depth - 1):
# Get a random QNN.
prep_and_U_circuit = generate_random_qnn(
qubits,
np.random.uniform() * 2 * np.pi, block_depth)
# Remove the state-prep component
U_circuit = prep_and_U_circuit[1:]
# Add U
circuit += U_circuit
# Add U^dagger
circuit += U_circuit**-1
return circuit
generate_identity_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2, 2)
4.2 Comparaison
Ici, vous pouvez voir que l'heuristique aide à empêcher la variance du gradient de disparaître aussi rapidement :
block_depth = 10
total_depth = 5
heuristic_theta_var = []
for n in n_qubits:
# Generate the identity block circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_identity_qnn(qubits, symbol, block_depth, total_depth)
for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
heuristic_theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.semilogy(n_qubits, heuristic_theta_var)
plt.title('Heuristic vs. Random')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:6 out of the last 6 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
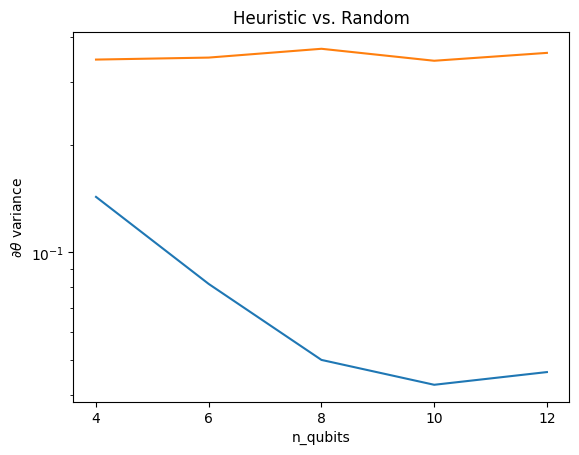
Il s'agit d'une grande amélioration pour obtenir des signaux de gradient plus forts à partir de QNN (quasi) aléatoires.