
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Neste exemplo, você explorará o resultado de McClean, 2019, que diz que não apenas qualquer estrutura de rede neural quântica se sairá bem quando se trata de aprendizado. Em particular, você verá que uma certa grande família de circuitos quânticos aleatórios não serve como boas redes neurais quânticas, porque possuem gradientes que desaparecem em quase todos os lugares. Neste exemplo, você não treinará nenhum modelo para um problema de aprendizado específico, mas sim focará no problema mais simples de entender os comportamentos dos gradientes.
Configurar
pip install tensorflow==2.7.0
Instale o TensorFlow Quantum:
pip install tensorflow-quantum
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Agora importe o TensorFlow e as dependências do módulo:
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
np.random.seed(1234)
2022-02-04 12:15:43.355568: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. Resumo
Circuitos quânticos aleatórios com muitos blocos que se parecem com isso (\(R_{P}(\theta)\) é uma rotação aleatória de Pauli):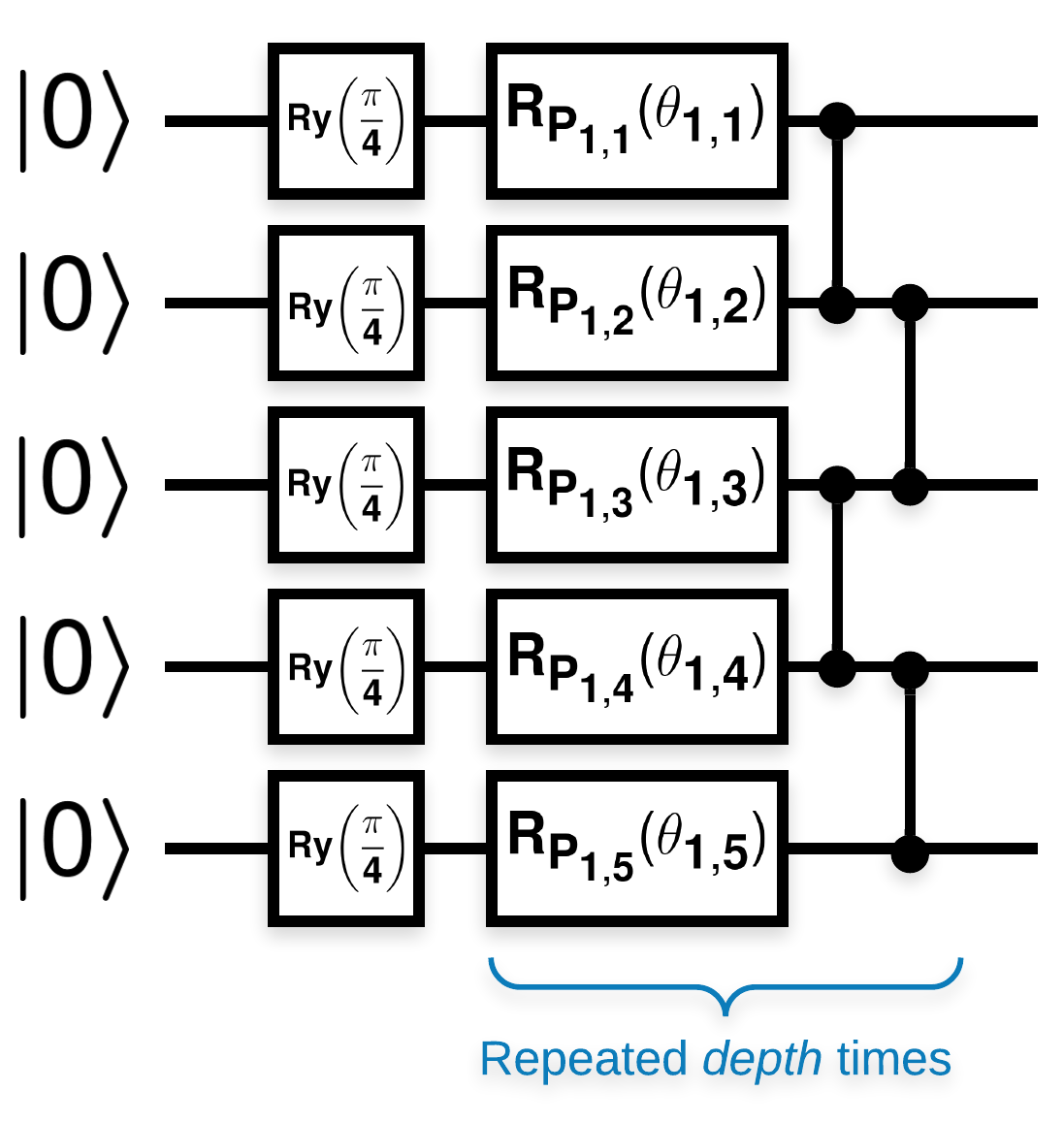
Onde se \(f(x)\) é definido como o valor esperado wrt \(Z_{a}Z_{b}\) para quaisquer qubits \(a\) e \(b\), então há um problema que \(f'(x)\) tem uma média muito próxima de 0 e não varia muito. Você verá isso abaixo:
2. Gerando circuitos aleatórios
A construção do papel é simples de seguir. O seguinte implementa uma função simples que gera um circuito quântico aleatório - às vezes chamado de rede neural quântica (QNN) - com a profundidade fornecida em um conjunto de qubits:
def generate_random_qnn(qubits, symbol, depth):
"""Generate random QNN's with the same structure from McClean et al."""
circuit = cirq.Circuit()
for qubit in qubits:
circuit += cirq.ry(np.pi / 4.0)(qubit)
for d in range(depth):
# Add a series of single qubit rotations.
for i, qubit in enumerate(qubits):
random_n = np.random.uniform()
random_rot = np.random.uniform(
) * 2.0 * np.pi if i != 0 or d != 0 else symbol
if random_n > 2. / 3.:
# Add a Z.
circuit += cirq.rz(random_rot)(qubit)
elif random_n > 1. / 3.:
# Add a Y.
circuit += cirq.ry(random_rot)(qubit)
else:
# Add a X.
circuit += cirq.rx(random_rot)(qubit)
# Add CZ ladder.
for src, dest in zip(qubits, qubits[1:]):
circuit += cirq.CZ(src, dest)
return circuit
generate_random_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2)
Os autores investigam o gradiente de um único parâmetro \(\theta_{1,1}\). Vamos continuar colocando um sympy.Symbol no circuito onde \(\theta_{1,1}\) estaria. Como os autores não analisam as estatísticas de nenhum outro símbolo no circuito, vamos substituí-los por valores aleatórios agora em vez de mais tarde.
3. Executando os circuitos
Gere alguns desses circuitos junto com um observável para testar a afirmação de que os gradientes não variam muito. Primeiro, gere um lote de circuitos aleatórios. Escolha um observável ZZ aleatório e calcule em lote os gradientes e a variação usando o TensorFlow Quantum.
3.1 Cálculo da variação do lote
Vamos escrever uma função auxiliar que calcula a variância do gradiente de um dado observável em um lote de circuitos:
def process_batch(circuits, symbol, op):
"""Compute the variance of a batch of expectations w.r.t. op on each circuit that
contains `symbol`. Note that this method sets up a new compute graph every time it is
called so it isn't as performant as possible."""
# Setup a simple layer to batch compute the expectation gradients.
expectation = tfq.layers.Expectation()
# Prep the inputs as tensors
circuit_tensor = tfq.convert_to_tensor(circuits)
values_tensor = tf.convert_to_tensor(
np.random.uniform(0, 2 * np.pi, (n_circuits, 1)).astype(np.float32))
# Use TensorFlow GradientTape to track gradients.
with tf.GradientTape() as g:
g.watch(values_tensor)
forward = expectation(circuit_tensor,
operators=op,
symbol_names=[symbol],
symbol_values=values_tensor)
# Return variance of gradients across all circuits.
grads = g.gradient(forward, values_tensor)
grad_var = tf.math.reduce_std(grads, axis=0)
return grad_var.numpy()[0]
3.1 Configurar e executar
Escolha o número de circuitos aleatórios a serem gerados junto com sua profundidade e a quantidade de qubits em que eles devem agir. Em seguida, plote os resultados.
n_qubits = [2 * i for i in range(2, 7)
] # Ranges studied in paper are between 2 and 24.
depth = 50 # Ranges studied in paper are between 50 and 500.
n_circuits = 200
theta_var = []
for n in n_qubits:
# Generate the random circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_random_qnn(qubits, symbol, depth) for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.title('Gradient Variance in QNNs')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:5 out of the last 5 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
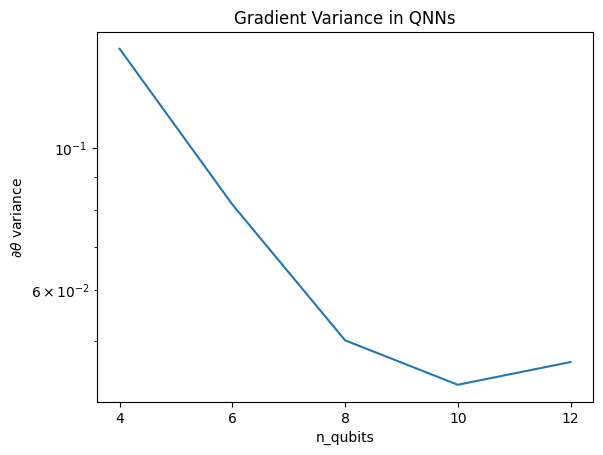
Este gráfico mostra que, para problemas de aprendizado de máquina quântico, você não pode simplesmente adivinhar um ansatz QNN aleatório e esperar o melhor. Alguma estrutura deve estar presente no circuito modelo para que os gradientes variem até o ponto em que o aprendizado possa acontecer.
4. Heurística
Uma heurística interessante de Grant, 2019 permite começar muito perto do aleatório, mas não exatamente. Usando os mesmos circuitos de McClean et al., os autores propõem uma técnica de inicialização diferente para os parâmetros de controle clássicos para evitar platôs estéreis. A técnica de inicialização inicia algumas camadas com parâmetros de controle totalmente aleatórios - mas, nas camadas imediatamente seguintes, escolha parâmetros de forma que a transformação inicial feita pelas primeiras camadas seja desfeita. Os autores chamam isso de bloco de identidade .
A vantagem dessa heurística é que, alterando apenas um único parâmetro, todos os outros blocos fora do bloco atual permanecerão a identidade - e o sinal de gradiente passa muito mais forte do que antes. Isso permite que o usuário escolha quais variáveis e blocos modificar para obter um sinal de gradiente forte. Essa heurística não impede que o usuário caia em um platô estéril durante a fase de treinamento (e restringe uma atualização totalmente simultânea), apenas garante que você possa começar fora de um platô.
4.1 Nova construção do QNN
Agora construa uma função para gerar QNNs de bloco de identidade. Esta implementação é ligeiramente diferente da do papel. Por enquanto, observe o comportamento do gradiente de um único parâmetro para que seja consistente com McClean et al, para que algumas simplificações possam ser feitas.
Para gerar um bloco de identidade e treinar o modelo, geralmente você precisa \(U1(\theta_{1a}) U1(\theta_{1b})^{\dagger}\) e não \(U1(\theta_1) U1(\theta_1)^{\dagger}\). Inicialmente \(\theta_{1a}\) e \(\theta_{1b}\) são os mesmos ângulos, mas são aprendidos independentemente. Caso contrário, você sempre obterá a identidade mesmo após o treinamento. A escolha do número de blocos de identidade é empírica. Quanto mais profundo o bloco, menor a variação no meio do bloco. Mas no início e no final do bloco, a variação dos gradientes dos parâmetros deve ser grande.
def generate_identity_qnn(qubits, symbol, block_depth, total_depth):
"""Generate random QNN's with the same structure from Grant et al."""
circuit = cirq.Circuit()
# Generate initial block with symbol.
prep_and_U = generate_random_qnn(qubits, symbol, block_depth)
circuit += prep_and_U
# Generate dagger of initial block without symbol.
U_dagger = (prep_and_U[1:])**-1
circuit += cirq.resolve_parameters(
U_dagger, param_resolver={symbol: np.random.uniform() * 2 * np.pi})
for d in range(total_depth - 1):
# Get a random QNN.
prep_and_U_circuit = generate_random_qnn(
qubits,
np.random.uniform() * 2 * np.pi, block_depth)
# Remove the state-prep component
U_circuit = prep_and_U_circuit[1:]
# Add U
circuit += U_circuit
# Add U^dagger
circuit += U_circuit**-1
return circuit
generate_identity_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2, 2)
4.2 Comparação
Aqui você pode ver que a heurística ajuda a evitar que a variação do gradiente desapareça tão rapidamente:
block_depth = 10
total_depth = 5
heuristic_theta_var = []
for n in n_qubits:
# Generate the identity block circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_identity_qnn(qubits, symbol, block_depth, total_depth)
for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
heuristic_theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.semilogy(n_qubits, heuristic_theta_var)
plt.title('Heuristic vs. Random')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:6 out of the last 6 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
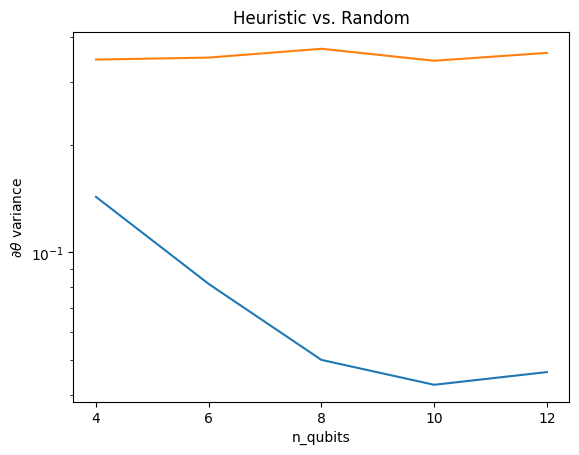
Esta é uma grande melhoria na obtenção de sinais de gradiente mais fortes de (quase) QNNs aleatórios.