
Pustaka TensorFlow Ranking membantu Anda membangun pembelajaran yang skalabel untuk menentukan peringkat model pembelajaran mesin menggunakan pendekatan dan teknik yang sudah mapan dari penelitian terbaru. Model pemeringkatan mengambil daftar item serupa, seperti halaman web, dan menghasilkan daftar item tersebut yang dioptimalkan, misalnya halaman yang paling relevan hingga halaman yang paling tidak relevan. Model pembelajaran memberi peringkat memiliki penerapan dalam pencarian, menjawab pertanyaan, sistem pemberi rekomendasi, dan sistem dialog. Anda dapat menggunakan perpustakaan ini untuk mempercepat pembuatan model peringkat untuk aplikasi Anda menggunakan Keras API . Pustaka Ranking juga menyediakan utilitas alur kerja untuk mempermudah peningkatan penerapan model Anda agar bekerja secara efektif dengan kumpulan data besar menggunakan strategi pemrosesan terdistribusi.
Ikhtisar ini memberikan ringkasan singkat tentang pengembangan pembelajaran untuk menentukan peringkat model dengan perpustakaan ini, memperkenalkan beberapa teknik lanjutan yang didukung oleh perpustakaan, dan membahas utilitas alur kerja yang disediakan untuk mendukung pemrosesan terdistribusi untuk aplikasi pemeringkatan.
Mengembangkan pembelajaran untuk menentukan peringkat model
Membangun model dengan pustaka TensorFlow Ranking mengikuti langkah-langkah umum berikut:
- Tentukan fungsi penilaian menggunakan lapisan Keras (
tf.keras.layers) - Tentukan metrik yang ingin Anda gunakan untuk evaluasi, seperti
tfr.keras.metrics.NDCGMetric - Tentukan fungsi kerugian, seperti
tfr.keras.losses.SoftmaxLoss - Kompilasi model dengan
tf.keras.Model.compile()dan latih dengan data Anda
Tutorial Rekomendasikan film memandu Anda mempelajari dasar-dasar pembuatan model pembelajaran untuk menentukan peringkat dengan perpustakaan ini. Lihat bagian Dukungan pemeringkatan terdistribusi untuk informasi lebih lanjut tentang cara membuat model pemeringkatan skala besar.
Teknik pemeringkatan tingkat lanjut
Pustaka Pemeringkatan TensorFlow memberikan dukungan untuk menerapkan teknik pemeringkatan lanjutan yang diteliti dan diterapkan oleh peneliti dan insinyur Google. Bagian berikut memberikan ikhtisar beberapa teknik ini dan cara mulai menggunakannya dalam aplikasi Anda.
Urutan masukan daftar BERT
Pustaka Ranking menyediakan implementasi TFR-BERT, arsitektur penilaian yang menggabungkan BERT dengan pemodelan LTR untuk mengoptimalkan pengurutan input daftar. Sebagai contoh penerapan pendekatan ini, pertimbangkan kueri dan daftar n dokumen yang ingin Anda rangking sebagai respons terhadap kueri ini. Daripada mempelajari representasi BERT yang diberi skor secara independen pada pasangan <query, document> , model LTR menerapkan kerugian peringkat untuk bersama-sama mempelajari representasi BERT yang memaksimalkan kegunaan seluruh daftar peringkat sehubungan dengan label kebenaran dasar. Gambar berikut mengilustrasikan teknik ini:
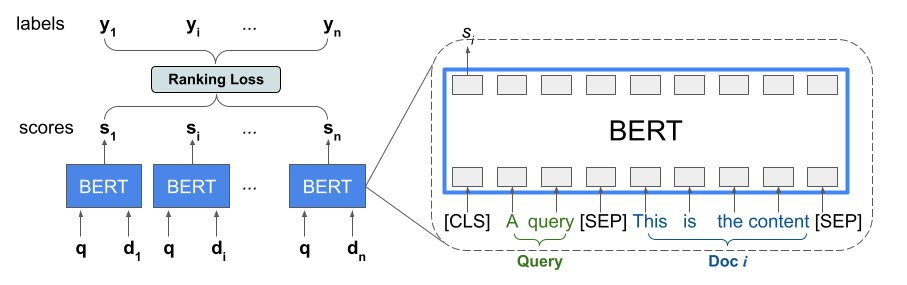
Pendekatan ini meratakan daftar dokumen untuk diberi peringkat sebagai respons terhadap kueri ke dalam daftar tupel <query, document> . Tupel ini kemudian dimasukkan ke dalam model bahasa terlatih BERT. Output BERT yang dikumpulkan untuk seluruh daftar dokumen kemudian disesuaikan dengan salah satu kerugian peringkat khusus yang tersedia di TensorFlow Ranking.
Arsitektur ini dapat memberikan peningkatan yang signifikan dalam performa model bahasa yang telah dilatih sebelumnya, menghasilkan performa canggih untuk beberapa tugas pemeringkatan populer, terutama ketika beberapa model bahasa yang telah dilatih sebelumnya digabungkan. Untuk informasi lebih lanjut tentang teknik ini, lihat penelitian terkait. Anda dapat memulai implementasi sederhana dalam kode contoh TensorFlow Ranking .
Model Aditif Umum Pemeringkatan Neural (GAM)
Untuk beberapa sistem pemeringkatan, seperti penilaian kelayakan pinjaman, penargetan iklan, atau panduan perawatan medis, transparansi dan penjelasan merupakan pertimbangan penting. Menerapkan model aditif umum (GAM) dengan faktor bobot yang dipahami dengan baik dapat membantu model peringkat Anda menjadi lebih mudah dijelaskan dan diinterpretasikan.
GAM telah dipelajari secara ekstensif dengan tugas regresi dan klasifikasi, namun masih kurang jelas bagaimana menerapkannya pada aplikasi pemeringkatan. Misalnya, meskipun GAM dapat dengan mudah diterapkan untuk memodelkan masing-masing item dalam daftar, memodelkan interaksi item dan konteks pemeringkatan item-item tersebut merupakan masalah yang lebih menantang. TensorFlow Ranking menyediakan implementasi peringkat neural GAM , perpanjangan dari model aditif umum yang dirancang untuk masalah peringkat. Implementasi TensorFlow Ranking pada GAM memungkinkan Anda menambahkan bobot spesifik pada fitur model Anda.
Ilustrasi sistem pemeringkatan hotel berikut ini menggunakan relevansi, harga, dan jarak sebagai fitur pemeringkatan utama. Model ini menerapkan teknik GAM untuk menimbang dimensi ini secara berbeda, berdasarkan konteks perangkat pengguna. Misalnya, jika kueri berasal dari ponsel, jarak akan lebih ditentukan, dengan asumsi pengguna mencari hotel terdekat.
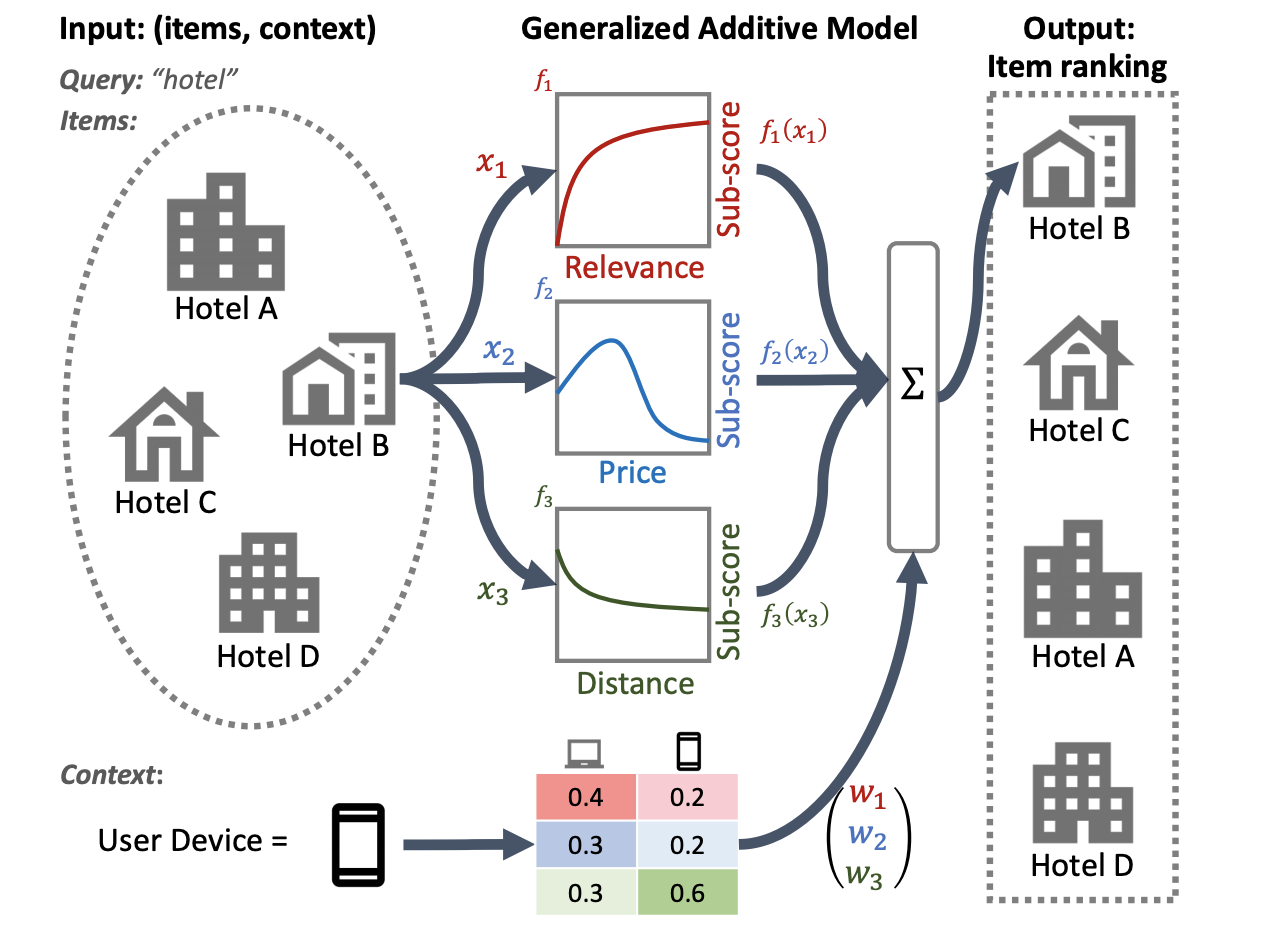
Untuk informasi lebih lanjut tentang penggunaan GAM dengan model pemeringkatan, lihat penelitian terkait. Anda dapat memulai dengan contoh implementasi teknik ini dalam kode contoh TensorFlow Ranking .
Dukungan peringkat terdistribusi
TensorFlow Ranking dirancang untuk membangun sistem pemeringkatan berskala besar secara menyeluruh: termasuk pemrosesan data, pembuatan model, evaluasi, dan penerapan produksi. Ini dapat menangani fitur-fitur heterogen yang padat dan jarang, meningkatkan skala hingga jutaan titik data, dan dirancang untuk mendukung pelatihan terdistribusi untuk aplikasi pemeringkatan skala besar.
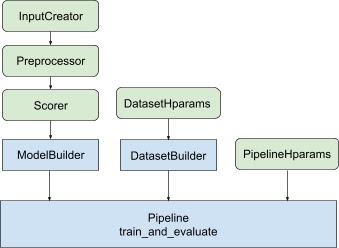
Pustaka ini menyediakan arsitektur saluran peringkat yang dioptimalkan, untuk menghindari kode boilerplate yang berulang dan membuat solusi terdistribusi yang dapat diterapkan mulai dari melatih model peringkat hingga menyajikannya. Pipeline pemeringkatan mendukung sebagian besar strategi terdistribusi TensorFlow, termasuk MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy , dan ParameterServerStrategy . Pipeline peringkat dapat mengekspor model peringkat terlatih dalam format tf.saved_model , yang mendukung beberapa tanda tangan input. Selain itu, pipeline Ranking menyediakan callback yang berguna, termasuk dukungan untuk visualisasi data TensorBoard dan BackupAndRestore untuk membantu pemulihan dari kegagalan dalam jangka panjang operasi pelatihan.
Pustaka pemeringkatan membantu membangun implementasi pelatihan terdistribusi dengan menyediakan serangkaian kelas tfr.keras.pipeline , yang menggunakan pembuat model, pembuat data, dan hyperparameter sebagai masukan. Kelas tfr.keras.ModelBuilder berbasis Keras memungkinkan Anda membuat model untuk pemrosesan terdistribusi, dan bekerja dengan kelas InputCreator, Preprocessor, dan Scorer yang dapat diperluas:
Kelas pipeline TensorFlow Ranking juga bekerja dengan DatasetBuilder untuk menyiapkan data pelatihan, yang dapat menggabungkan hyperparameter . Terakhir, pipeline itu sendiri dapat menyertakan sekumpulan hyperparameter sebagai objek PipelineHparams .
Mulailah membangun model pemeringkatan terdistribusi menggunakan tutorial pemeringkatan terdistribusi .