
Библиотека ранжирования TensorFlow помогает построить масштабируемое обучение для ранжирования моделей машинного обучения, используя хорошо зарекомендовавшие себя подходы и методы, полученные из недавних исследований. Модель ранжирования берет список похожих элементов, таких как веб-страницы, и генерирует оптимизированный список этих элементов, например, наиболее релевантные и наименее релевантные страницы. Модели обучения ранжированию применяются в поиске, ответах на вопросы, рекомендательных системах и диалоговых системах. Вы можете использовать эту библиотеку для ускорения построения модели ранжирования вашего приложения с помощью Keras API . Библиотека ранжирования также предоставляет утилиты рабочего процесса, упрощающие масштабирование реализации вашей модели для эффективной работы с большими наборами данных с использованием стратегий распределенной обработки.
В этом обзоре представлен краткий обзор разработки обучения ранжированию моделей с помощью этой библиотеки, представлены некоторые расширенные методы, поддерживаемые библиотекой, и обсуждаются утилиты рабочего процесса, предоставляемые для поддержки распределенной обработки для ранжирования приложений.
Развитие обучения ранжированию моделей
Построение модели с помощью библиотеки TensorFlow Ranking выполняется следующим образом:
- Укажите функцию оценки, используя слои Keras (
tf.keras.layers). - Определите метрики, которые вы хотите использовать для оценки, например
tfr.keras.metrics.NDCGMetric. - Укажите функцию потерь, например
tfr.keras.losses.SoftmaxLoss. - Скомпилируйте модель с помощью
tf.keras.Model.compile()и обучите ее своим данным.
Учебное пособие «Рекомендовать фильмы» знакомит вас с основами построения модели обучения для ранжирования с помощью этой библиотеки. Дополнительную информацию о построении крупномасштабных моделей ранжирования можно найти в разделе «Поддержка распределенного ранжирования» .
Продвинутые методы ранжирования
Библиотека ранжирования TensorFlow обеспечивает поддержку применения передовых методов ранжирования, разработанных и реализованных исследователями и инженерами Google. В следующих разделах представлен обзор некоторых из этих методов и того, как начать использовать их в своем приложении.
Порядок ввода списка BERT
Библиотека ранжирования предоставляет реализацию TFR-BERT, архитектуру оценки, которая объединяет BERT с моделированием LTR для оптимизации порядка входных данных списка. В качестве примера применения этого подхода рассмотрим запрос и список из n документов, которые вы хотите ранжировать в ответ на этот запрос. Вместо изучения представления BERT, оцениваемого независимо по парам <query, document> , модели LTR применяют потерю ранжирования для совместного изучения представления BERT, которое максимизирует полезность всего ранжированного списка по отношению к меткам основной истины. Следующий рисунок иллюстрирует эту технику:
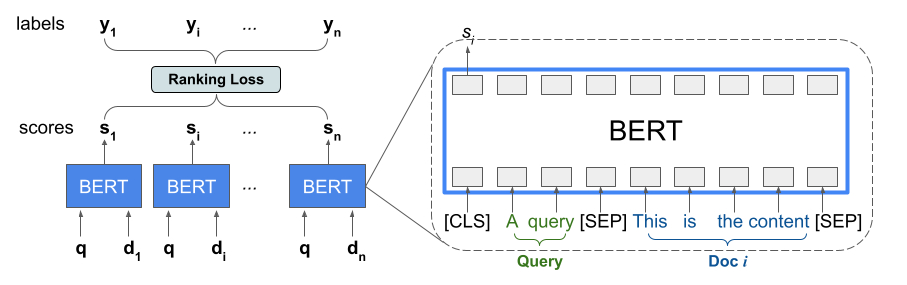
Этот подход объединяет список документов, которые необходимо ранжировать в ответ на запрос, в список кортежей <query, document> . Эти кортежи затем передаются в предварительно обученную языковую модель BERT. Объединенные выходные данные BERT для всего списка документов затем совместно настраиваются с помощью одной из специализированных потерь ранжирования , доступных в TensorFlow Ranking.
Эта архитектура может обеспечить значительные улучшения производительности предварительно обученных языковых моделей, обеспечивая высочайшую производительность для нескольких популярных задач ранжирования, особенно при объединении нескольких предварительно обученных языковых моделей. Для получения дополнительной информации об этой методике см. соответствующее исследование . Начать работу можно с простой реализации в примере кода TensorFlow Ranking.
Обобщенные аддитивные модели нейронного ранжирования (GAM)
Для некоторых систем ранжирования, таких как оценка права на получение кредита, таргетинг рекламы или рекомендации по лечению, прозрачность и объяснимость являются критически важными факторами. Применение обобщенных аддитивных моделей (GAM) с хорошо понятными весовыми коэффициентами может помочь вашей модели ранжирования стать более объяснимой и интерпретируемой.
GAM широко изучались с задачами регрессии и классификации, но менее ясно, как их применять в приложениях для ранжирования. Например, хотя GAM можно просто применить для моделирования каждого отдельного элемента в списке, моделирование как взаимодействия элементов, так и контекста, в котором эти элементы ранжируются, является более сложной проблемой. TensorFlow Ranking обеспечивает реализацию нейронного ранжирования GAM — расширения обобщенных аддитивных моделей, предназначенных для решения задач ранжирования. Реализация GAM TensorFlow Ranking позволяет вам добавлять определенный вес к функциям вашей модели.
На следующей иллюстрации системы ранжирования отелей в качестве основных характеристик ранжирования используются релевантность, цена и расстояние. В этой модели применяется метод GAM для различного взвешивания этих измерений в зависимости от контекста устройства пользователя. Например, если запрос поступил с телефона, расстояние имеет большее значение, если предположить, что пользователи ищут ближайший отель.
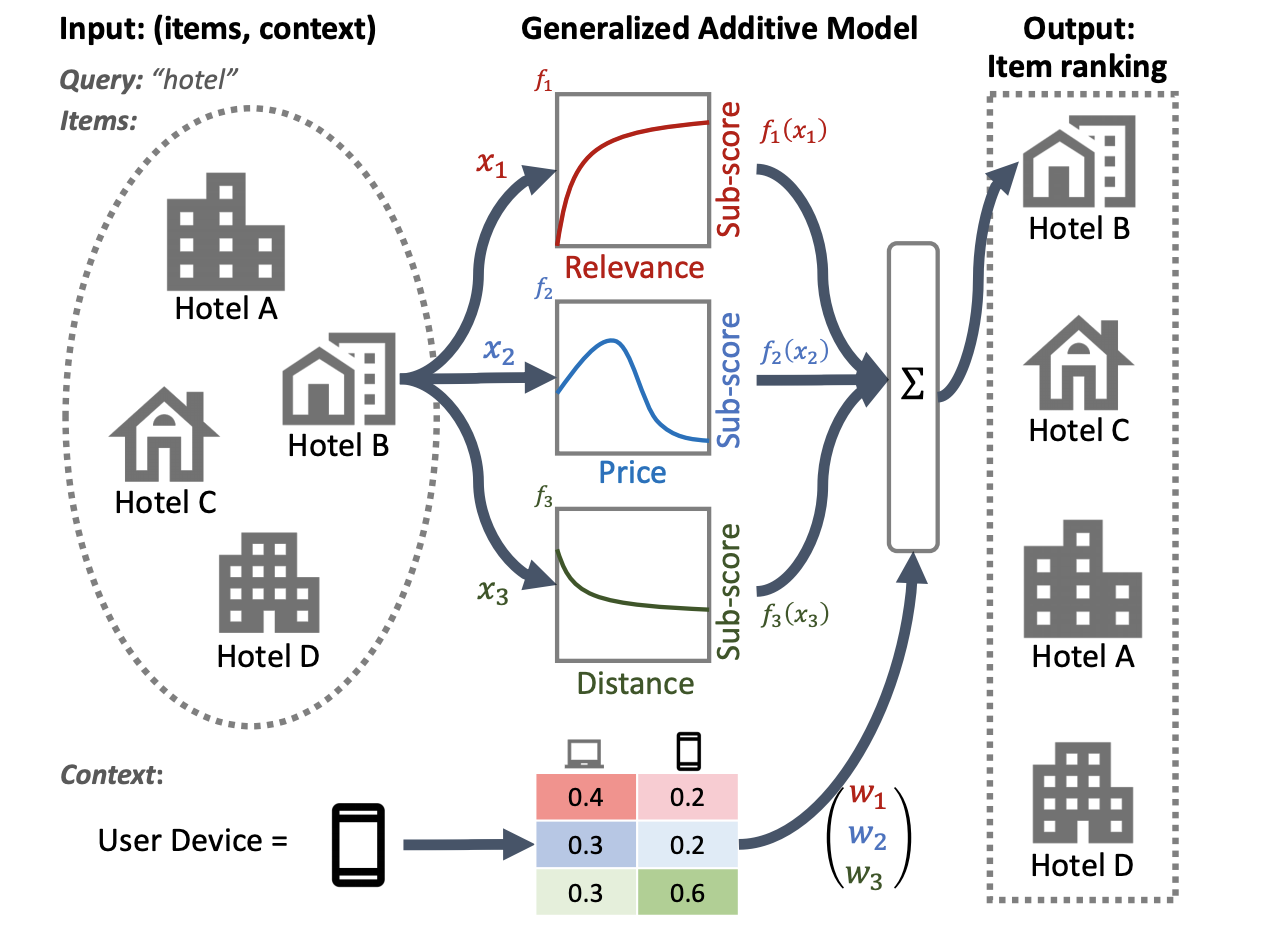
Дополнительную информацию об использовании GAM с моделями ранжирования см. в соответствующем исследовании . Вы можете начать работу с примера реализации этой техники в примере кода TensorFlow Ranking.
Распределенная поддержка ранжирования
TensorFlow Ranking предназначен для построения крупномасштабных комплексных систем ранжирования: включая обработку данных, построение моделей, оценку и развертывание производства. Он может обрабатывать гетерогенные плотные и разреженные функции, масштабироваться до миллионов точек данных и предназначен для поддержки распределенного обучения для крупномасштабных приложений ранжирования.
Библиотека обеспечивает оптимизированную архитектуру конвейера ранжирования, позволяющую избежать повторяющегося шаблонного кода и создавать распределенные решения, которые можно применять от обучения вашей модели ранжирования до ее обслуживания. Конвейер ранжирования поддерживает большинство распределенных стратегий TensorFlow, включая MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy и ParameterServerStrategy . Конвейер ранжирования может экспортировать обученную модель ранжирования в формате tf.saved_model , который поддерживает несколько входных сигнатур . Кроме того, конвейер ранжирования предоставляет полезные обратные вызовы, включая поддержку визуализации данных TensorBoard и BackupAndRestore , помогающих восстанавливаться после сбоев в длительных работах. тренировочные операции.
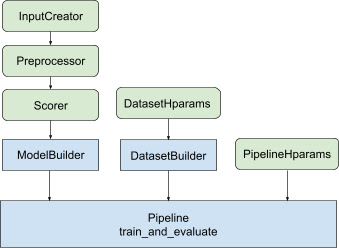
Библиотека ранжирования помогает создать реализацию распределенного обучения, предоставляя набор классов tfr.keras.pipeline , которые принимают в качестве входных данных построитель моделей, построитель данных и гиперпараметры. Класс tfr.keras.ModelBuilder на основе Keras позволяет создавать модель для распределенной обработки и работает с расширяемыми классами InputCreator, Preprocessor и Scorer:
Классы конвейера TensorFlow Ranking также работают с DatasetBuilder для настройки обучающих данных, которые могут включать гиперпараметры . Наконец, сам конвейер может включать набор гиперпараметров в виде объекта PipelineHparams .
Начните создавать модели распределенного ранжирования с помощью руководства по распределенному ранжированию .