
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מדריך זה מדגים כיצד להשתמש ב-Deep & Cross Network (DCN) כדי ללמוד ביעילות הצלבות תכונות.
רקע כללי
מהם צלבי תכונה ומדוע הם חשובים? תארו לעצמכם שאנחנו בונים מערכת ממליצים למכירת בלנדר ללקוחות. ואז, היסטורית רכישת העבר של לקוח כגון purchased_bananas ו purchased_cooking_books , או תכונות גיאוגרפיות, הן תכונות יחידות. אם אחד רכש שני בננות ספרי בישול, ואז לקוח זה יהיה סביר יותר לחץ על הבלנדר המומלץ. השילוב של purchased_bananas ו purchased_cooking_books נקרא צלב תכונה, אשר מספק מידע אינטראקציות נוסף מעבר לתכונות הבודדות.
מהם האתגרים בהצלבי תכונות למידה? ביישומים בקנה מידה אינטרנט, הנתונים הם לרוב קטגוריים, מה שמוביל לשטח תכונות גדול ודליל. זיהוי הצלבות תכונות אפקטיביות בהגדרה זו דורש לעתים קרובות הנדסת תכונות ידנית או חיפוש ממצה. מודלים מסורתיים להזנה קדימה מרובה שכבתיים (MLP) הם מקרוב פונקציות אוניברסלי; עם זאת, הם לא יכולים להתקרב ביעילות אפילו צלבי תכונה 2 או 3-מנת [ 1 , 2 ].
מהי Deep & Cross Network (DCN)? DCN תוכנן ללמוד תכונות צולבות מפורשות ומוגבלות בדרגות בצורה יעילה יותר. זה מתחיל עם שכבת קלט (בדרך כלל שכבת הטבעה), ואחריו רשת צלב המכילה שכבות צלב מרובות כי מודלי אינטראקציות תכונה מפורשות, ולאחר מכן משלב עם רשת עמוקה כי מודלי אינטראקציות תכונה מרומזות.
- חוצה רשת. זה הליבה של DCN. זה מחיל במפורש חציית תכונה בכל שכבה, והדרגה הפולינומית הגבוהה ביותר גדלה עם עומק השכבה. התרשים מראה בעקבות \((i+1)\)ה- יצא שכבת צלב.
- רשת עמוקה. זהו פרצפטרון רב-שכבתי מסורתי להזנה קדימה (MLP).
הרשת העמוקה רשת צלב מצורפים יחד כדי ליצור DCN [ 1 ]. בדרך כלל, נוכל לערום רשת עמוקה על גבי הרשת הצולבת (מבנה מוערם); נוכל גם למקם אותם במקביל (מבנה מקביל).
בהמשך, נציג תחילה את היתרון של DCN עם דוגמה לצעצוע, ולאחר מכן נדריך אותך בכמה דרכים נפוצות לשימוש ב- DCN באמצעות מערך הנתונים של MovieLen-1M.
תחילה נתקין ולייבא את החבילות הדרושות עבור colab זה.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
דוגמה לצעצוע
כדי להמחיש את היתרונות של DCN, הבה נעבור על דוגמה פשוטה. נניח שיש לנו מערך נתונים שבו אנחנו מנסים לדמות את הסבירות שלקוח ילחץ על מודעת בלנדר, עם התכונות והתווית שלה מתוארים כדלקמן.
| תכונות / תווית | תיאור | סוג/טווח ערך |
|---|---|---|
| \(x_1\) = בארץ | המדינה שבה חי הלקוח הזה | Int ב-[0, 199] |
| \(x_2\) = בננות | # בננות שהלקוח רכש | Int ב-[0, 23] |
| \(x_3\) = ספרי בישול | # ספרי בישול שהלקוח רכש | Int ב-[0, 5] |
| \(y\) | הסבירות של לחיצה על מודעת בלנדר | -- |
לאחר מכן, אנו נותנים לנתונים לעקוב אחר ההתפלגות הבסיסית הבאה:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
איפה את הסבירות \(y\) תלויה לינארית הן תכונות \(x_i\)של, אלא גם על אינטראקציות בין כפלי \(x_i\)של. במקרה שלנו, היינו אומרים כי הסבירות של רכישת בבלנדר (\(y\)) תלוי לא רק על רכישת בננות (\(x_2\)) או ספרי בישול (\(x_3\)), אלא גם על רכישת בננות ספרי בישול ביחד (\(x_2x_3\)).
אנו יכולים להפיק את הנתונים לכך באופן הבא:
הפקת נתונים סינתטיים
אנחנו הראשונים להגדיר \(f(x_1, x_2, x_3)\) כמתואר לעיל.
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
בואו נפיק את הנתונים שאחרי ההתפלגות, ונחלק את הנתונים ל-90% לאימון ו-10% לבדיקות.
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
בניית דגם
אנחנו הולכים לנסות גם רשתות חוצה וגם רשתות עמוקות כדי להמחיש את היתרון שרשת צולבת יכולה להביא לממליצים. מכיוון שהנתונים שיצרנו זה עתה מכילים רק אינטראקציות תכונה מסדר שני, זה יהיה מספיק כדי להמחיש באמצעות רשת צולבת חד-שכבתית. אם נרצה ליצור מודל של אינטראקציות תכונות מסדר גבוה יותר, נוכל לערום מספר רב של שכבות צולבות ולהשתמש ברשת צולבת רב-שכבתית. שני הדגמים שנבנה הם:
- Cross Network עם שכבה צולבת אחת בלבד;
- רשת עמוקה עם שכבות ReLU רחבות ועמוקות יותר.
ראשית אנו בונים מחלקת מודל מאוחדת שההפסד שלה הוא השגיאה הממוצעת בריבוע.
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
לאחר מכן, אנו מציינים את הרשת הצולבת (עם שכבה צולבת אחת בגודל 3) ואת ה-DNN מבוסס ReLU (עם גדלי שכבות [512, 256, 128]):
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
אימון דוגמניות
עכשיו כשיש לנו את הנתונים והמודלים מוכנים, אנחנו הולכים לאמן את המודלים. ראשית, אנו מערבבים ומקבצים את הנתונים כדי להתכונן לאימון מודלים.
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
לאחר מכן, אנו מגדירים את מספר העידנים וכן את קצב הלמידה.
epochs = 100
learning_rate = 0.4
בסדר, הכל מוכן עכשיו ובואו נלקט ונאמן את הדגמים. אתה יכול להגדיר verbose=True אם אתה רוצה לראות איך התקדמות המודל.
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
הערכת מודל
אנו מאמתים את ביצועי המודל על מערך הנתונים של ההערכה ומדווחים על שגיאת ה-Root Mean Squared Error (RMSE, ככל שיותר נמוך יותר טוב).
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
אנו רואים כי בהירויות הצלב השיגו הרשת להנמיך RMSE מאשר DNN מבוסס ReLU, עם פרמטרים פחות בהירויות. זה הציע את היעילות של רשת צולבת בלימוד הצלבי תכונות.
הבנת מודל
אנחנו כבר יודעים אילו הצלבות תכונה חשובות בנתונים שלנו, יהיה כיף לבדוק האם המודל שלנו אכן למד את הצלב התכונה החשוב. ניתן לעשות זאת על ידי הדמיה של מטריצת המשקל הנלמדת ב- DCN. המשקל \(W_{ij}\) מייצג את החשיבות הנודעת אינטראקציה בין התכונה \(x_i\) ו \(x_j\).
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
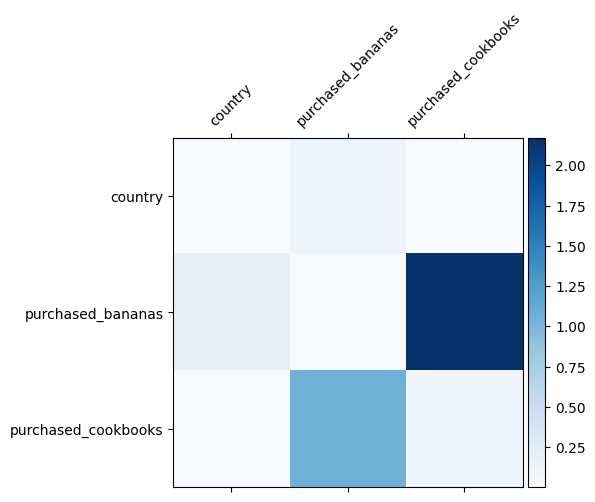
צבעים כהים יותר מייצגים אינטראקציות נלמדות חזקות יותר - במקרה זה, ברור שהדגם למד שרכישת בבאנות וספרי בישול יחד היא חשובה.
אם אתם מעוניינים לנסות נתונים סינתטי מסובכים יותר, אתה מוזמן לבדוק את הנייר הזה .
Movielens 1M לדוגמה
כעת אנו בוחנים את האפקטיביות של DCN על בסיס הנתונים מהעולם האמיתי: Movielens 1M [ 3 ]. Movielens 1M הוא מערך נתונים פופולרי למחקר המלצות. הוא חוזה את דירוג הסרטים של משתמשים בהינתן תכונות הקשורות למשתמש ותכונות הקשורות לסרטים. אנו משתמשים במערך נתונים זה כדי להדגים כמה דרכים נפוצות לשימוש ב-DCN.
עיבוד נתונים
הליך עיבוד נתונים כדלקמן הליך דומה כמו ההדרכה בדירוג הבסיסית .
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
לאחר מכן, אנו מחלקים את הנתונים באופן אקראי ל-80% לאימון ו-20% לבדיקות.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
לאחר מכן, אנו יוצרים אוצר מילים עבור כל תכונה.
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
בניית דגם
ארכיטקטורת המודל שנבנה מתחילה בשכבת הטמעה, המוזנת לרשת צולבת ואחריה רשת עמוקה. ממד ההטמעה מוגדר ל-32 עבור כל התכונות. אתה יכול גם להשתמש בגדלים שונים של הטבעה עבור תכונות שונות.
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
אימון דוגמניות
אנו מערבבים, מקבצים ומצמידים את נתוני ההדרכה והבדיקות.
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
הבה נגדיר פונקציה שמריצה מודל מספר פעמים ומחזירה את ממוצע ה-RMSE וסטיית התקן של המודל מתוך ריצות מרובות.
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
קבענו כמה פרמטרים יתר עבור הדגמים. שים לב שההיפר-פרמטרים האלה מוגדרים באופן גלובלי עבור כל הדגמים למטרת הדגמה. אם אתה רוצה להשיג את הביצועים הטובים ביותר עבור כל דגם, או לבצע השוואה הוגנת בין דגמים, אז אנו מציעים לך לכוונן עדין את הפרמטרים ההיפר. זכור כי ארכיטקטורת המודל ותכניות האופטימיזציה שלובות זו בזו.
epochs = 8
learning_rate = 0.01
DCN (מוערם). תחילה אנו מאמנים מודל DCN עם מבנה מוערם, כלומר, התשומות מוזנות לרשת צולבת ואחריה רשת עמוקה.
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
DCN בדרגה נמוכה. כדי להפחית את עלות האימון וההגשה, אנו ממנפים טכניקות בדרג נמוך כדי להעריך את מטריצות המשקל של DCN. ההדרגה מועברת דרך הטיעון projection_dim ; קטן יותר projection_dim תוצאות בעלות נמוכה יותר. הערה כי projection_dim צריך להיות קטן יותר (גודל קלט) / 2 כדי להפחית את העלות. בפועל, ראינו ששימוש ב-DCN בדרגה נמוכה עם דירוג (גודל קלט)/4 שמר באופן עקבי את הדיוק של DCN בדירוג מלא.
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
DNN. אנו מאמנים מודל DNN בגודל זהה בתור רפרנס.
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
אנו מעריכים את המודל על נתוני הבדיקה ומדווחים על הממוצע ועל סטיית התקן מתוך 5 ריצות.
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
אנו רואים ש-DCN השיג ביצועים טובים יותר מאשר DNN בגודל זהה עם שכבות ReLU. יתרה מכך, ה-DCN בדרגה נמוכה הצליח להפחית פרמטרים תוך שמירה על הדיוק.
עוד על DCN. מלבד מה יש הודגם לעיל, ישנם יותר יצירתי עדיין כמעט בדרכים מועילות לנצל DCN [ 1 ].
DCN עם מבנה מקביל. התשומות מוזנות במקביל לרשת צולבת ולרשת עמוקה.
שרשור שכבות צולבות. הכניסות מוזנות במקביל למספר רב של שכבות צולבות כדי ללכוד הצלבות תכונות משלימות.
הבנת מודל
מטריצת משקל \(W\) ב DCN מגלה מה מאפיין חוצה את המודל למד להיות חשוב. נזכיר כי בדוגמה צעצוע הקודמת, את החשיבות של אינטראקציות בין \(i\)ה- יצא ו \(j\)ה- יצא תכונות הוא נתפס על ידי (\(i, j\)) אלמנט ה- יצא של \(W\).
מה זה שונה קצת כאן היא כי שיבוצים תכונה הם בגודל 32 במקום בגודל 1. מכאן החשיבות יאופיין על ידי \((i, j)\)בלוק ה- יצא\(W_{i,j}\) וזה של המימד 32 על ידי 32. הבאה, אנחנו לדמיין את נורמת Frobenius [ 4 ] \(||W_{i,j}||_F\) של כול בלוק, ואת נורמה גדולה ממליצה חשיבות גבוהה יותר (בהנחה שיבוצי התכונות הן של קשקשים דומים).
מלבד נורמה בלוק, נוכל גם לדמיין את המטריצה כולה, או את הערך הממוצע/חציוני/מקסימום של כל בלוק.
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
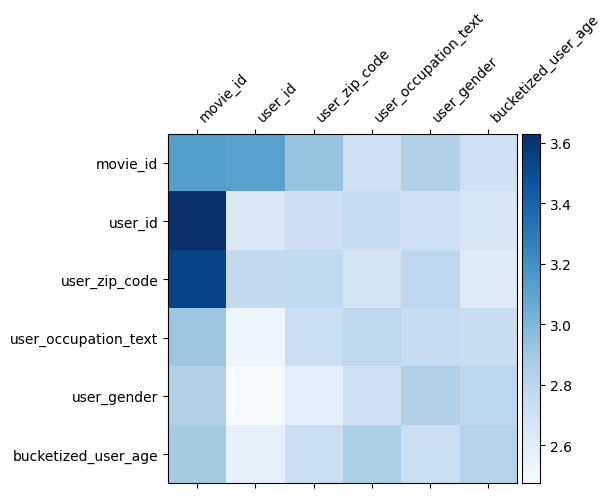
זה הכל בשביל הקולאב הזה! אנו מקווים שנהנית ללמוד כמה יסודות של DCN ודרכים נפוצות להשתמש בו. אם אתה מעוניין ללמוד יותר, אתה יכול לבדוק את שני מסמכים רלוונטיים: DCN-v1-נייר , DCN-v2-נייר .
הפניות
DCN V2: שיפור Deep & Cross רשת שיעורים מעשיים ללמידה מידה אינטרנט למערכות דרגה .
Ruoxi Wang, Rakesh Shivanna, Derek Zhiyuan Cheng, Sagar Jain, Dong Lin, Lichan Hong, Ed Chi. (2020)
Deep & Cross רשת עבור תחזיות מודעות לחיצה .
Ruoxi Wang, Bin Fu, Gang Fu, Mingliang Wang. (AdKDD 2017)