
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
בשנת featurization הדרכה שילבנו מספר תכונות לתוך המודלים שלנו, אבל הדגמים כוללים שכבת הטמעה רק. אנו יכולים להוסיף שכבות צפופות יותר לדגמים שלנו כדי להגביר את כוח ההבעה שלהם.
באופן כללי, מודלים עמוקים יותר מסוגלים ללמוד דפוסים מורכבים יותר ממודלים רדודים יותר. לדוגמה, שלנו מודל המשתמשים משלבת זהויות משתמשים וחותמות זמן להעדפות המשתמש מודל בכל נקודת זמן. דגם רדוד (נניח, שכבת הטמעה אחת) עשוי ללמוד רק את הקשרים הפשוטים ביותר בין התכונות הללו לסרטים: סרט נתון הוא הפופולרי ביותר בזמן יציאתו לאקרנים, ומשתמש נתון מעדיף בדרך כלל סרטי אימה על קומדיות. כדי ללכוד מערכות יחסים מורכבות יותר, כגון העדפות משתמש המתפתחות עם הזמן, ייתכן שנצטרך מודל עמוק יותר עם מספר רב של שכבות צפופות מוערמות.
כמובן שלמודלים מורכבים יש גם חסרונות. הראשון הוא עלות חישובית, שכן דגמים גדולים יותר דורשים גם יותר זיכרון וגם יותר חישוב כדי להתאים ולשרת. השני הוא הדרישה ליותר נתונים: באופן כללי, נדרשים יותר נתוני הכשרה כדי לנצל מודלים עמוקים יותר. עם יותר פרמטרים, מודלים עמוקים עשויים להתאים יותר מדי או אפילו פשוט לשנן את דוגמאות האימון במקום ללמוד פונקציה שיכולה להכליל. לבסוף, הכשרה של מודלים עמוקים יותר עשויה להיות קשה יותר, ויש לנקוט זהירות רבה יותר בבחירת הגדרות כמו רגולציה וקצב למידה.
מציאת אדריכלות טובה עבור מערכות המלצת עולם אמיתי הנה אמנות מורכבת, הדורשת אינטואיציה טובה וזהירת כוונון hyperparameter . לדוגמה, גורמים כמו העומק והרוחב של המודל, פונקציית ההפעלה, קצב הלמידה והאופטימיזציה יכולים לשנות באופן קיצוני את ביצועי המודל. בחירות הדוגמנות מסובכות עוד יותר בשל העובדה שמעדי הערכה לא מקוונים טובים עשויים שלא להתאים לביצועים מקוונים טובים, ושהבחירה של מה לבצע אופטימיזציה היא לרוב קריטית יותר מאשר בחירת הדגם עצמו.
אף על פי כן, המאמץ המושקע בבנייה ובכוונן עדין של דגמים גדולים יותר משתלם לעתים קרובות. במדריך זה, נמחיש כיצד לבנות מודלים של אחזור עמוק באמצעות TensorFlow Recommenders. אנו נעשה זאת על ידי בניית מודלים מורכבים יותר ויותר כדי לראות כיצד זה משפיע על ביצועי המודל.
מוקדמות
אנו מייבאים תחילה את החבילות הדרושות.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
במדריך זה נשתמש מודלים מן ההדרכה featurization ליצור שיבוצים. לפיכך נשתמש רק בתכונות מזהה המשתמש, חותמת הזמן וכותרת הסרט.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
אנחנו גם עושים קצת משק בית כדי להכין אוצר מילים עלילתי.
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
הגדרת דגם
מודל שאילתה
אנחנו מתחילים עם מודל המשתמשים המוגדרים הדרכה featurization כמו השכבה הראשונה של המודל שלנו, שתפקידו המרת דוגמאות קלט גלם לתוך שיבוצים תכונה.
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
הגדרת מודלים עמוקים יותר תחייב אותנו לערום שכבות מצב על גבי הקלט הראשון הזה. ערימה צרה יותר ויותר של שכבות, מופרדות על ידי פונקציית הפעלה, היא דפוס נפוץ:
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
מכיוון שכוח הביטוי של מודלים ליניאריים עמוקים אינו גדול מזה של מודלים ליניאריים רדודים, אנו משתמשים בהפעלת ReLU עבור כל השכבה הנסתרת האחרונה מלבד השכבה הנסתרת האחרונה. השכבה הנסתרת הסופית אינה משתמשת בפונקציית הפעלה כלשהי: שימוש בפונקציית הפעלה יגביל את שטח הפלט של ההטבעות הסופיות ועלול להשפיע לרעה על ביצועי המודל. לדוגמה, אם נעשה שימוש ב-ReLUs בשכבת ההקרנה, כל הרכיבים בהטמעת הפלט יהיו לא שליליים.
אנחנו הולכים לנסות משהו דומה כאן. כדי להקל על הניסוי בעומקים שונים, הבה נגדיר מודל שעומקו (ורוחבו) מוגדר על ידי קבוצה של פרמטרים של בנאי.
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
layer_sizes פרמטר נותן לנו את העומק והרוחב של המודל. אנחנו יכולים לגוון אותו כדי להתנסות בדגמים רדודים יותר או עמוקים יותר.
מודל מועמד
אנחנו יכולים לאמץ את אותה גישה למודל הסרט. שוב, אנחנו מתחילים עם MovieModel מן featurization הדרכה:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
ולהרחיב אותו בשכבות נסתרות:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
דגם משולב
עם שניהם QueryModel ו CandidateModel מוגדר, אנחנו יכולים להרכיב מודל משולב וליישם היגיון האובדן ומדדים שלנו. כדי להפוך את הדברים לפשוטים, נאכף שמבנה המודל יהיה זהה בכל המודלים של השאילתה והמועמדים.
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
הכשרת הדגם
הכן את הנתונים
תחילה חילקנו את הנתונים לסט הדרכה ולסט בדיקות.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
דגם רדוד
אנחנו מוכנים לנסות את הדגם הראשון, הרדוד, שלנו!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
זה נותן לנו דיוק מוביל 100 של סביב 0.27. אנו יכולים להשתמש בזה כנקודת התייחסות להערכת מודלים עמוקים יותר.
דגם עמוק יותר
מה לגבי דגם עמוק יותר עם שתי שכבות?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
הדיוק כאן הוא 0.29, לא מעט טוב יותר מהדגם הרדוד.
אנו יכולים לשרטט את עקומות דיוק האימות כדי להמחיש זאת:
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
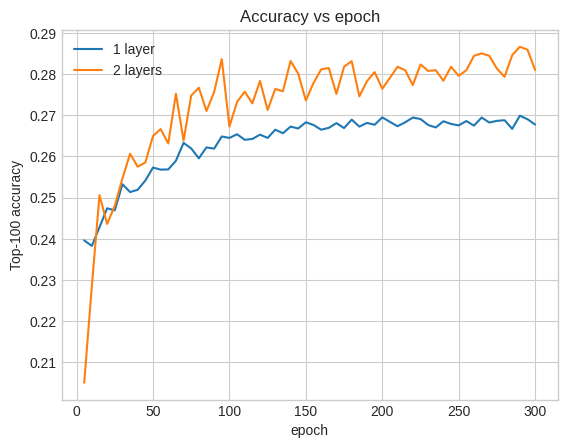
אפילו בשלב מוקדם של האימון, למודל הגדול יותר יש הובלה ברורה ויציבה על המודל הרדוד, מה שמרמז שהוספת עומק עוזרת למודל ללכוד קשרים ניואנסים יותר בנתונים.
עם זאת, גם דגמים עמוקים יותר אינם בהכרח טובים יותר. הדגם הבא מרחיב את העומק לשלוש שכבות:
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
למעשה, אנחנו לא רואים שיפור ביחס לדגם הרדוד:
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
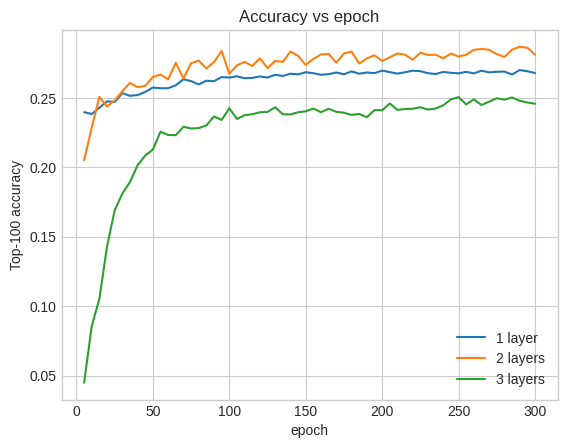
זוהי המחשה טובה לעובדה שדגמים עמוקים וגדולים יותר, למרות שהם מסוגלים לביצועים מעולים, דורשים לרוב כוונון זהיר מאוד. לדוגמה, לאורך המדריך הזה השתמשנו בשיעור למידה יחיד וקבוע. בחירות אלטרנטיביות עשויות לתת תוצאות שונות מאוד ושווה לחקור אותן.
עם כוונון מתאים ונתונים מספקים, המאמץ המושקע בבניית מודלים גדולים ועמוקים יותר שווה את זה במקרים רבים: מודלים גדולים יותר יכולים להוביל לשיפורים מהותיים בדיוק הניבוי.
הצעדים הבאים
במדריך זה הרחבנו את מודל האחזור שלנו עם שכבות צפופות ופונקציות הפעלה. כדי לראות כיצד ליצור מודל שיכול לבצע לא רק משימות תחזורנה אלא גם משימות דירוג, תסתכל על הדרכת ריבוי משימות .