
ওভারভিউ
TensorBoard এর প্রধান বৈশিষ্ট্য হল এর ইন্টারেক্টিভ GUI। যদিও, ব্যবহারকারীদের মাঝে মাঝে প্রোগ্রামেটিক্যালি TensorBoard সংরক্ষিত ডেটা লগ, যেমন পোস্টে-হক বিশ্লেষণ পারফর্মিং এবং লগ ডেটা কাস্টম দৃশ্য তৈরি মতো উদ্দেশ্য পড়তে চাই।
2.3 সমর্থন এই ব্যবহারের ক্ষেত্রে TensorBoard সঙ্গে tensorboard.data.experimental.ExperimentFromDev() এটা তোলে TensorBoard এর প্রোগ্রামাটিক অ্যাক্সেসের অনুমতি দেয় স্কালে লগ । এই পৃষ্ঠাটি এই নতুন API এর মৌলিক ব্যবহার প্রদর্শন করে।
সেটআপ
অর্ডার কর্মসূচি এপিআই ব্যবহার করার জন্য, নিশ্চিত করুন যে আপনি ইনস্টল করতে pandas পাশাপাশি tensorboard ।
আমরা ব্যবহার করব matplotlib এবং seaborn এই সহায়িকার কাস্টম প্লট জন্য, কিন্তু আপনি বিশ্লেষণ এবং মনশ্চক্ষুতে আপনার পছন্দের টুল নির্বাচন করতে পারবেন DataFrame গুলি।
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
হিসেবে TensorBoard scalars লোড করা হচ্ছে pandas.DataFrame
একবার একটি TensorBoard logdir TensorBoard.dev এ আপলোড করা হয়েছে, এটা কি আমরা একটি পরীক্ষা হিসেবে পড়ুন হয়ে যায়। প্রতিটি পরীক্ষার একটি অনন্য আইডি আছে, যা পরীক্ষার TensorBoard.dev URL- এ পাওয়া যাবে। : নীচের আমাদের বিক্ষোভের জন্য, আমরা একটি TensorBoard.dev পরীক্ষা ব্যবহার করা হবে https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df একটি হল pandas.DataFrame পরীক্ষা সব স্কালে লগ রয়েছে সেটা।
এর কলাম DataFrame আছেন:
-
run: মূল logdir একটি সাব প্রতিটি রান অনুরূপ। এই পরীক্ষায়, প্রতিটি রান একটি প্রদত্ত অপটিমাইজার টাইপ (একটি প্রশিক্ষণ হাইপারপ্যারামিটার) সহ MNIST ডেটাসেটে একটি কনভোলিউশনাল নিউরাল নেটওয়ার্ক (CNN) এর সম্পূর্ণ প্রশিক্ষণ থেকে। এইDataFrameএকাধিক যেমন রান যা বিভিন্ন অপটিমাইজার ধরনের অধীনে পুনরাবৃত্তি প্রশিক্ষণ রান মিলা ধারণ করে। -
tag: এই বর্ণনা কিvalueযে একই সারিতে মানে, কি মেট্রিক মান সারিতে প্রতিনিধিত্ব করে। : এই পরীক্ষা, আমরা মাত্র দুটি অনন্য ট্যাগ আছেepoch_accuracyএবংepoch_lossসঠিকতা এবং ক্ষয় মেট্রিক্স যথাক্রমে জন্য। -
step: এই একটি সংখ্যা যে তার রান সংশ্লিষ্ট সারির অন্বয় প্রতিফলিত করে। এখানেstepআসলে কাল সংখ্যা বোঝায়। আপনি ছাড়াও টাইমস্ট্যাম্প প্রাপ্ত করতে চানstepমূল্যবোধ, আপনি শব্দ যুক্তি ব্যবহার করতে পারেনinclude_wall_time=Trueযখন কলিংget_scalars()। -
valueএই সুদ প্রকৃত সংখ্যাসূচক মান। উপরে বর্ণিত, প্রতিটিvalueএই বিশেষDataFrameপারেন একটি ক্ষতি বা কোনো সঠিকতা, উপর নির্ভর করেtagসারির।
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
একটি পিভোটেড (ওয়াইড-ফর্ম) ডেটাফ্রেম পাওয়া
আমাদের পরীক্ষা, দুই ট্যাগ ( epoch_loss এবং epoch_accuracy ) প্রতিটি রান ধাপের একই সেট উপস্থিত হয়। এই এটা সম্ভব একটি "ওয়াইড-ফর্ম" প্রাপ্ত করে তোলে DataFrame সরাসরি থেকে get_scalars() ব্যবহার করে pivot=True শব্দ যুক্তি। ওয়াইড-ফর্ম DataFrame তার সমস্ত ট্যাগ DataFrame, যা এই এক সহ কিছু ক্ষেত্রে এর সাথে কাজ করা আরও বেশি সুবিধাজনক হয় কলাম হিসেবে অন্তর্ভুক্ত হয়েছে।
যাইহোক, হুঁশিয়ার যে সব রানে সমস্ত ট্যাগ জুড়ে পদক্ষেপ মূল্যবোধের অভিন্ন সেট থাকার শর্ত পূরণ না হয় ব্যবহার করে pivot=True একটি ত্রুটি হয়ে যাবে।
dfw = experiment.get_scalars(pivot=True)
dfw
লক্ষ করুন যে, একটি একক "মান" কলামে পরিবর্তে, ওয়াইড-ফর্ম DataFrame স্পষ্টভাবে তার কলাম হিসাবে দুই ট্যাগ (মেট্রিক্স) রয়েছে: epoch_accuracy এবং epoch_loss ।
CSV হিসাবে DataFrame সংরক্ষণ করা হচ্ছে
pandas.DataFrame সঙ্গে ভাল ইনটেরোপিরাবিলিটি হয়েছে যে CSV । আপনি এটি একটি স্থানীয় CSV ফাইল হিসাবে সংরক্ষণ করতে পারেন এবং পরে আবার লোড করতে পারেন। উদাহরণ স্বরূপ:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
কাস্টম ভিজ্যুয়ালাইজেশন এবং পরিসংখ্যান বিশ্লেষণ সম্পাদন
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
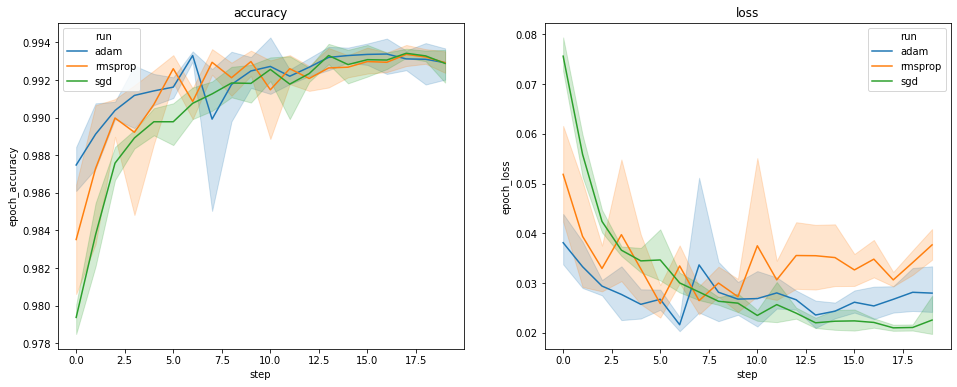
উপরের প্লটগুলি বৈধতা সঠিকতা এবং বৈধতা ক্ষতির সময়সূচী দেখায়। প্রতিটি বক্ররেখা একটি অপটিমাইজার টাইপের অধীনে 5 রান জুড়ে গড় দেখায়। একটি বিল্ট-ইন বৈশিষ্ট্য ধন্যবাদ seaborn.lineplot() , প্রতিটি বক্ররেখা এ অর্থও প্রায় প্রদর্শন ± 1 স্ট্যানডার্ড ডেভিয়েশন, যা আমাদের এই রেখাচিত্র তারতম্য এবং তিনটি অপটিমাইজার ধরনের মধ্যে পার্থক্য তাৎপর্য সুস্পষ্ট ইন্দ্রিয় দেয়। পরিবর্তনশীলতার এই দৃশ্যটি এখনও TensorBoard এর GUI তে সমর্থিত নয়।
আমরা এই অনুমানটি অধ্যয়ন করতে চাই যে ন্যূনতম বৈধতা ক্ষতি "অ্যাডাম", "আরএমএসপ্রপ" এবং "এসজিডি" অপ্টিমাইজারের মধ্যে উল্লেখযোগ্যভাবে পৃথক। সুতরাং আমরা প্রতিটি অপটিমাইজারের অধীনে ন্যূনতম বৈধতা ক্ষতির জন্য একটি ডেটাফ্রেম বের করি।
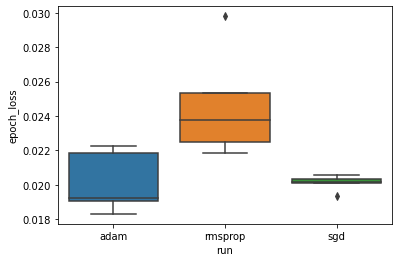
তারপরে আমরা ন্যূনতম বৈধতা ক্ষতির পার্থক্যটি কল্পনা করতে একটি বক্সপ্লট তৈরি করি।
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
অতএব, 0.05 এর তাত্পর্য স্তরে, আমাদের বিশ্লেষণ আমাদের অনুমানকে নিশ্চিত করে যে আমাদের পরীক্ষায় অন্তর্ভুক্ত অন্য দুটি অপ্টিমাইজারের তুলনায় আরএমএসপ্রপ অপ্টিমাইজারে ন্যূনতম বৈধতা ক্ষতি উল্লেখযোগ্যভাবে বেশি (অর্থাৎ, খারাপ)।
সংক্ষেপে বলা যায়, এই টিউটোরিয়াল যেমন স্কালে ডেটা অ্যাক্সেস করতে কিভাবে একটি উদাহরণ প্রদান করে panda.DataFrame TensorBoard.dev এর থেকে। এটা তোলে নমনীয় ও শক্তিশালী বিশ্লেষণ এবং কল্পনা আপনার সাথে কি করতে পারেন ধরনের প্রমান DataFrame গুলি।