
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
মেশিন লার্নিং-এ, কোনো কিছুর উন্নতি করার জন্য আপনাকে প্রায়ই তা পরিমাপ করতে সক্ষম হতে হবে। TensorBoard হল মেশিন লার্নিং ওয়ার্কফ্লো চলাকালীন প্রয়োজনীয় পরিমাপ এবং ভিজ্যুয়ালাইজেশন প্রদান করার একটি টুল। এটি ক্ষতি এবং নির্ভুলতা, মডেল গ্রাফটি ভিজ্যুয়ালাইজ করা, নিম্ন মাত্রিক স্থানে এম্বেডিং প্রজেক্ট করা এবং আরও অনেক কিছুর মতো ট্র্যাকিং পরীক্ষামূলক মেট্রিক্স সক্ষম করে।
এই কুইকস্টার্ট দেখাবে কিভাবে দ্রুত TensorBoard দিয়ে শুরু করা যায়। এই ওয়েবসাইটের অবশিষ্ট গাইডগুলি নির্দিষ্ট ক্ষমতা সম্পর্কে আরও বিশদ প্রদান করে, যার অনেকগুলি এখানে অন্তর্ভুক্ত করা হয়নি।
# Load the TensorBoard notebook extension
%load_ext tensorboard
import tensorflow as tf
import datetime
# Clear any logs from previous runsrm -rf ./logs/
ব্যবহার MNIST উদাহরণ হিসাবে ডেটা সেটটি, ডাটা স্বাভাবিক এবং একটি ফাংশন যা 10 ক্লাস মধ্যে চিত্র classifying জন্য একটি সহজ Keras মডেল তৈরি করে লিখুন।
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
def create_model():
return tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step
Keras Model.fit() এর সাথে TensorBoard ব্যবহার করা
যখন Keras এর সঙ্গে প্রশিক্ষণ Model.fit () যোগ tf.keras.callbacks.TensorBoard কলব্যাক নিশ্চিত করে যে লগগুলি তৈরি করেছেন এবং সংরক্ষণ করা হয়। উপরন্তু, সক্ষম হিস্টোগ্রাম গণনার যে যুগান্তকারী সঙ্গে histogram_freq=1 (এই ডিফল্টরূপে বন্ধ হয়)
একটি টাইমস্ট্যাম্পড সাবডিরেক্টরিতে লগগুলি রাখুন যাতে বিভিন্ন প্রশিক্ষণ রানের সহজ নির্বাচন করা যায়।
model = create_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])
Train on 60000 samples, validate on 10000 samples Epoch 1/5 60000/60000 [==============================] - 15s 246us/sample - loss: 0.2217 - accuracy: 0.9343 - val_loss: 0.1019 - val_accuracy: 0.9685 Epoch 2/5 60000/60000 [==============================] - 14s 229us/sample - loss: 0.0975 - accuracy: 0.9698 - val_loss: 0.0787 - val_accuracy: 0.9758 Epoch 3/5 60000/60000 [==============================] - 14s 231us/sample - loss: 0.0718 - accuracy: 0.9771 - val_loss: 0.0698 - val_accuracy: 0.9781 Epoch 4/5 60000/60000 [==============================] - 14s 227us/sample - loss: 0.0540 - accuracy: 0.9820 - val_loss: 0.0685 - val_accuracy: 0.9795 Epoch 5/5 60000/60000 [==============================] - 14s 228us/sample - loss: 0.0433 - accuracy: 0.9862 - val_loss: 0.0623 - val_accuracy: 0.9823 <tensorflow.python.keras.callbacks.History at 0x7fc8a5ee02e8>
কমান্ড লাইনের মাধ্যমে বা একটি নোটবুকের অভিজ্ঞতার মধ্যে টেনসরবোর্ড শুরু করুন। দুটি ইন্টারফেস সাধারণত একই। নোটবুক ইন, ব্যবহার %tensorboard লাইন জাদু। কমান্ড লাইনে, "%" ছাড়া একই কমান্ড চালান।
%tensorboard --logdir logs/fit
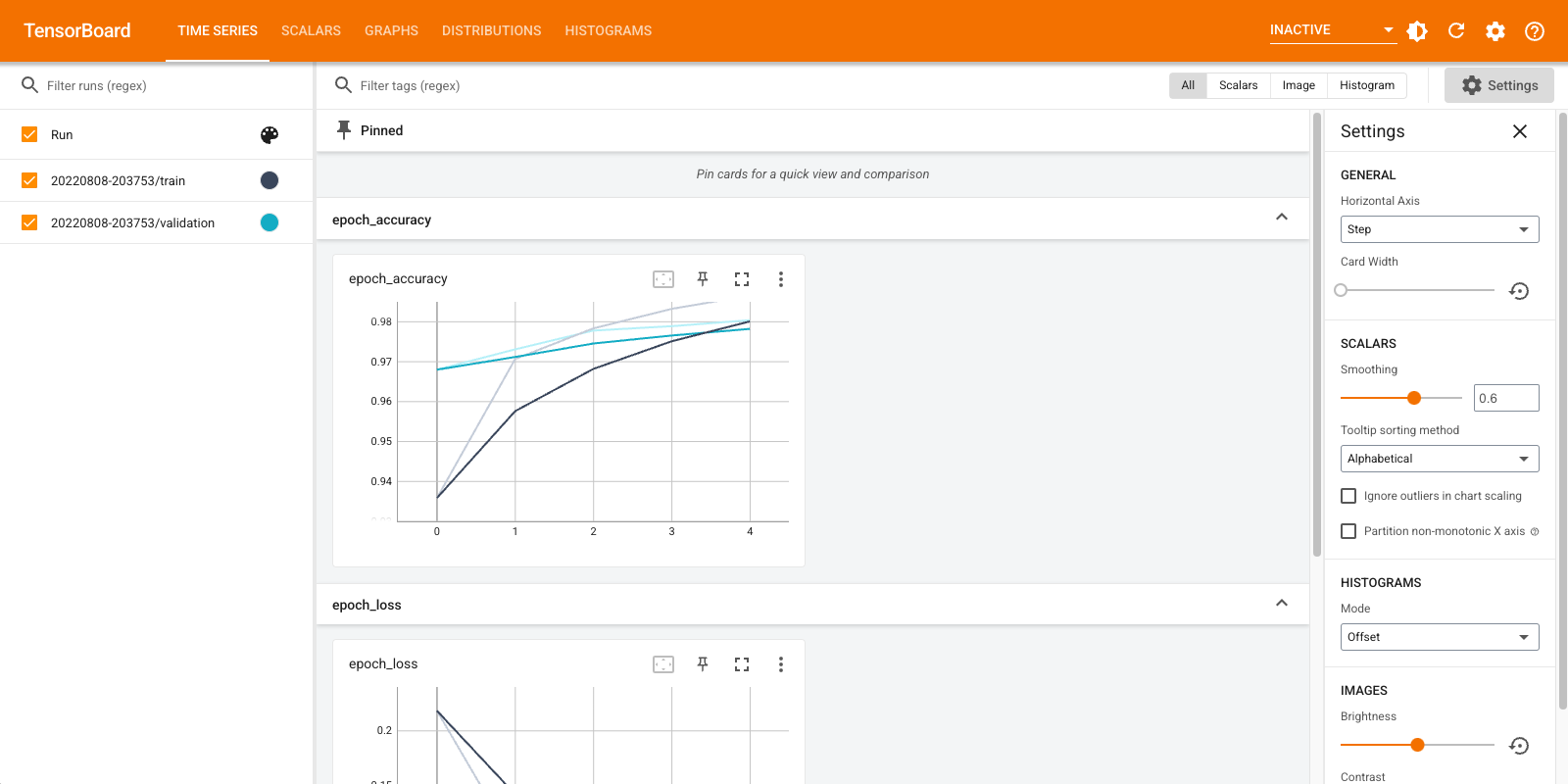
দেখানো ড্যাশবোর্ডগুলির একটি সংক্ষিপ্ত ওভারভিউ (শীর্ষ নেভিগেশন বারে ট্যাব):
- Scalars ড্যাশবোর্ড দেখায় কিভাবে কমে যাওয়া এবং বৈশিষ্ট্যের মান যে যুগান্তকারী পরিবর্তন। আপনি প্রশিক্ষণের গতি, শেখার হার এবং অন্যান্য স্কেলার মান ট্র্যাক করতে এটি ব্যবহার করতে পারেন।
- গ্রাফ ড্যাশবোর্ড আপনাকে আপনার মডেল ঠাহর করতে সাহায্য করে। এই ক্ষেত্রে, স্তরগুলির কেরাস গ্রাফ দেখানো হয়েছে যা আপনাকে এটি সঠিকভাবে নির্মিত হয়েছে তা নিশ্চিত করতে সাহায্য করতে পারে।
- ডিস্ট্রিবিউশন ও Histograms ড্যাশবোর্ডের সময়ের একটি টেন্সর বিতরণের প্রদর্শন করুন। ওজন এবং পক্ষপাতগুলি কল্পনা করতে এবং তারা প্রত্যাশিত উপায়ে পরিবর্তিত হচ্ছে তা যাচাই করতে এটি কার্যকর হতে পারে।
অতিরিক্ত টেনসরবোর্ড প্লাগইনগুলি স্বয়ংক্রিয়ভাবে সক্ষম হয় যখন আপনি অন্যান্য ধরণের ডেটা লগ করেন৷ উদাহরণস্বরূপ, কেরাস টেনসরবোর্ড কলব্যাক আপনাকে ছবি এবং এম্বেডিংগুলিও লগ করতে দেয়৷ উপরের ডানদিকে "নিষ্ক্রিয়" ড্রপডাউনে ক্লিক করে আপনি টেনসরবোর্ডে অন্যান্য কী প্লাগইন উপলব্ধ রয়েছে তা দেখতে পারেন।
অন্যান্য পদ্ধতির সাথে TensorBoard ব্যবহার করা
যখন যেমন পদ্ধতি প্রশিক্ষণ tf.GradientTape() , ব্যবহার tf.summary প্রয়োজনীয় তথ্য লগইন করুন।
উপরোক্ত হিসাবে একই ডেটা সেটটি ব্যবহার করুন, কিন্তু বলা যায় এর রূপান্তরের tf.data.Dataset ক্ষমতা Batching সুবিধা গ্রহণ করতে:
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.shuffle(60000).batch(64)
test_dataset = test_dataset.batch(64)
প্রশিক্ষণ কোড অনুসরণ করে অগ্রসর দ্রুতশুরু টিউটোরিয়াল, কিন্তু দেখায় কিভাবে TensorBoard করার বৈশিষ্ট্যের মান লগইন করুন। ক্ষতি এবং অপ্টিমাইজার চয়ন করুন:
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
স্টেটফুল মেট্রিক্স তৈরি করুন যা প্রশিক্ষণের সময় মান সংগ্রহ করতে ব্যবহার করা যেতে পারে এবং যেকোনো সময়ে লগ ইন করুন:
# Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')
প্রশিক্ষণ এবং পরীক্ষার ফাংশন সংজ্ঞায়িত করুন:
def train_step(model, optimizer, x_train, y_train):
with tf.GradientTape() as tape:
predictions = model(x_train, training=True)
loss = loss_object(y_train, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y_train, predictions)
def test_step(model, x_test, y_test):
predictions = model(x_test)
loss = loss_object(y_test, predictions)
test_loss(loss)
test_accuracy(y_test, predictions)
একটি ভিন্ন লগ ডিরেক্টরিতে ডিস্কে সারাংশ লিখতে সারাংশ লেখক সেট আপ করুন:
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)
প্রশিক্ষণ শুরু করুন। ব্যবহার করুন tf.summary.scalar() / প্রশিক্ষণের সময় মেট্রিক্স (কমে যাওয়া এবং সঠিকতা) লগ ইন করার সারসংক্ষেপ লেখকদের সুযোগ মধ্যে পরীক্ষা ডিস্কে সারাংশ লিখতে। কোন মেট্রিক্স লগ করতে হবে এবং কত ঘন ঘন করতে হবে তার উপর আপনার নিয়ন্ত্রণ আছে। অন্যান্য tf.summary ফাংশন তথ্য অন্যান্য ধরনের লগিং সক্ষম করুন।
model = create_model() # reset our model
EPOCHS = 5
for epoch in range(EPOCHS):
for (x_train, y_train) in train_dataset:
train_step(model, optimizer, x_train, y_train)
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
for (x_test, y_test) in test_dataset:
test_step(model, x_test, y_test)
with test_summary_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reset metrics every epoch
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states()
Epoch 1, Loss: 0.24321186542510986, Accuracy: 92.84333801269531, Test Loss: 0.13006582856178284, Test Accuracy: 95.9000015258789 Epoch 2, Loss: 0.10446818172931671, Accuracy: 96.84833526611328, Test Loss: 0.08867532759904861, Test Accuracy: 97.1199951171875 Epoch 3, Loss: 0.07096975296735764, Accuracy: 97.80166625976562, Test Loss: 0.07875105738639832, Test Accuracy: 97.48999786376953 Epoch 4, Loss: 0.05380449816584587, Accuracy: 98.34166717529297, Test Loss: 0.07712937891483307, Test Accuracy: 97.56999969482422 Epoch 5, Loss: 0.041443776339292526, Accuracy: 98.71833038330078, Test Loss: 0.07514958828687668, Test Accuracy: 97.5
TensorBoard আবার খুলুন, এবার এটিকে নতুন লগ ডিরেক্টরিতে নির্দেশ করুন। প্রশিক্ষণের অগ্রগতির সময় আমরা টেনসরবোর্ড চালু করতে পারতাম।
%tensorboard --logdir logs/gradient_tape
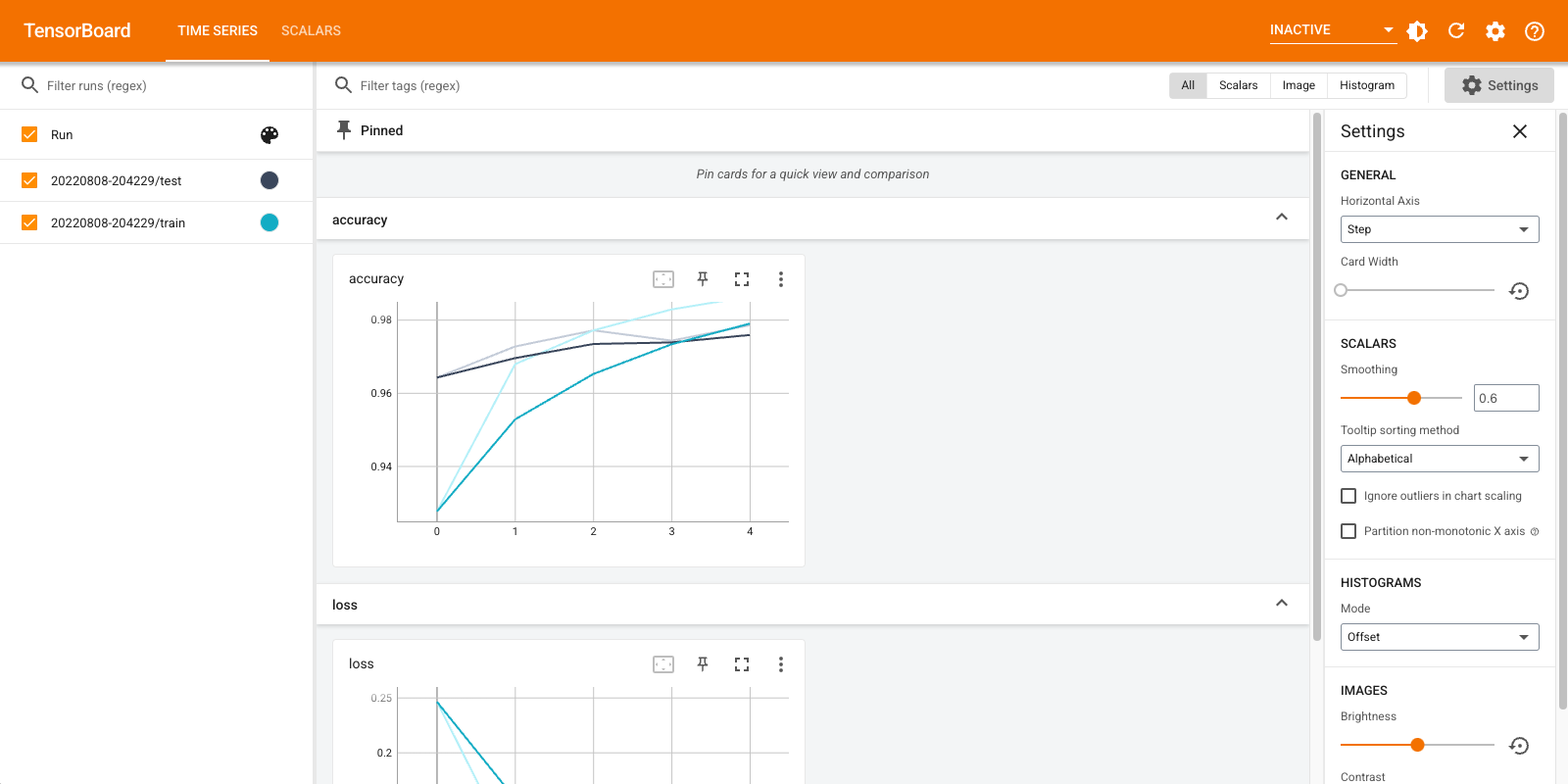
এটাই! আপনি এখন দেখেছি উভয় Keras কলব্যাক মাধ্যমে এবং এর মাধ্যমে TensorBoard কীভাবে ব্যবহার করবেন তা tf.summary আরো কাস্টম পরিস্থিতিতে জন্য।
TensorBoard.dev: আপনার ML পরীক্ষার ফলাফল হোস্ট করুন এবং শেয়ার করুন
TensorBoard.dev একটি বিনামূল্যে পাবলিক সার্ভিস যা আপনি আপনার TensorBoard লগ আপলোড এবং একটি পার্মালিঙ্ক যে একাডেমিক কাগজপত্র এ সবার, ব্লগ পোস্ট, সামাজিক মিডিয়া, ইত্যাদি এই ভাল reproducibility এবং সহযোগিতা সক্রিয় করতে পারেন সঙ্গে ভাগ করা যেতে পারে পেতে সক্ষম করে।
TensorBoard.dev ব্যবহার করতে, নিম্নলিখিত কমান্ডটি চালান:
!tensorboard dev upload \
--logdir logs/fit \
--name "(optional) My latest experiment" \
--description "(optional) Simple comparison of several hyperparameters" \
--one_shot
নোট যে এই আবাহন বিস্ময়বোধক উপসর্গ ব্যবহার ( ! ) শেল বদলে শতাংশ উপসর্গ (ডাকা % ) colab যাদু ডাকা। কমান্ড লাইন থেকে এই কমান্ডটি ব্যবহার করার সময় উভয় উপসর্গের প্রয়োজন নেই।
একটি উদাহরণ দেখুন এখানে ।
কিভাবে TensorBoard.dev ব্যবহার করবেন তার বিস্তারিত জানার জন্য দেখুন https://tensorboard.dev/#get-started