
Durante un programma TensorFlow possono talvolta verificarsi eventi catastrofici che coinvolgono i NaN , paralizzando i processi di addestramento del modello. Le cause profonde di tali eventi sono spesso oscure, soprattutto per modelli di dimensioni e complessità non banali. Per semplificare il debug di questo tipo di bug del modello, TensorBoard 2.3+ (insieme a TensorFlow 2.3+) fornisce un dashboard specializzato chiamato Debugger V2. Qui dimostriamo come utilizzare questo strumento risolvendo un bug reale che coinvolge i NaN in una rete neurale scritta in TensorFlow.
Le tecniche illustrate in questo tutorial sono applicabili ad altri tipi di attività di debug come l'ispezione delle forme dei tensori di runtime in programmi complessi. Questo tutorial si concentra sui NaN a causa della loro frequenza relativamente elevata di occorrenza.
Osservando l'insetto
Il codice sorgente del programma TF2 di cui eseguiremo il debug è disponibile su GitHub . Il programma di esempio è anche incluso nel pacchetto tensorflow pip (versione 2.3+) e può essere richiamato da:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
Questo programma TF2 crea una percezione multistrato (MLP) e la addestra a riconoscere le immagini MNIST . Questo esempio utilizza intenzionalmente l'API di basso livello di TF2 per definire costrutti di livello personalizzati, funzione di perdita e ciclo di addestramento, poiché la probabilità di bug NaN è maggiore quando utilizziamo questa API più flessibile ma più soggetta a errori rispetto a quando utilizziamo la più semplice API di alto livello facili da usare ma leggermente meno flessibili come tf.keras .
Il programma stampa una precisione del test dopo ogni fase di addestramento. Possiamo vedere nella console che la precisione del test si blocca ad un livello quasi casuale (~0.1) dopo il primo passaggio. Questo non è certamente il modo in cui ci si aspetta che l'addestramento del modello si comporti: ci aspettiamo che la precisione si avvicini gradualmente a 1,0 (100%) man mano che il passo aumenta.
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
Un'ipotesi plausibile è che questo problema sia causato da un'instabilità numerica, come NaN o infinito. Tuttavia, come possiamo confermare che sia realmente così e come troviamo l'operazione TensorFlow (op) responsabile della generazione dell'instabilità numerica? Per rispondere a queste domande, strumentiamo il programma difettoso con Debugger V2.
Strumentazione del codice TensorFlow con Debugger V2
tf.debugging.experimental.enable_dump_debug_info() è il punto di ingresso API di Debugger V2. Strumenta un programma TF2 con una singola riga di codice. Ad esempio, aggiungendo la seguente riga all'inizio del programma, le informazioni di debug verranno scritte nella directory di registro (logdir) in /tmp/tfdbg2_logdir. Le informazioni di debug coprono vari aspetti del runtime di TensorFlow. In TF2, include la cronologia completa dell'esecuzione entusiasta, della costruzione del grafico eseguita da @tf.function , dell'esecuzione dei grafici, dei valori tensoriali generati dagli eventi di esecuzione, nonché della posizione del codice (tracce dello stack Python) di tali eventi . La ricchezza delle informazioni di debug consente agli utenti di restringere il campo ai bug oscuri.
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
L'argomento tensor_debug_mode controlla quali informazioni Debugger V2 estrae da ogni tensore desideroso o in-graph. "FULL_HEALTH" è una modalità che cattura le seguenti informazioni su ciascun tensore di tipo mobile (ad esempio, il float32 comunemente visto e il meno comune bfloat16 dtype):
- DType
- Rango
- Numero totale di elementi
- Una suddivisione degli elementi di tipo mobile nelle seguenti categorie: finito negativo (
-), zero (0), finito positivo (+), infinito negativo (-∞), infinito positivo (+∞) eNaN.
La modalità "FULL_HEALTH" è adatta per il debug di bug che coinvolgono NaN e infinito. Vedi sotto per altri tensor_debug_mode supportati.
L'argomento circular_buffer_size controlla quanti eventi tensoriali vengono salvati nella logdir. Il valore predefinito è 1000, il che fa sì che solo gli ultimi 1000 tensori prima della fine del programma TF2 strumentato vengano salvati su disco. Questo comportamento predefinito riduce il sovraccarico del debugger sacrificando la completezza dei dati di debug. Se si preferisce la completezza, come in questo caso, possiamo disabilitare il buffer circolare impostando l'argomento su un valore negativo (ad esempio, -1 qui).
L'esempio debug_mnist_v2 richiama enable_dump_debug_info() passandogli i flag della riga di comando. Per eseguire nuovamente il nostro problematico programma TF2 con questa strumentazione di debug abilitata, esegui:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
Avvio della GUI del Debugger V2 in TensorBoard
L'esecuzione del programma con la strumentazione del debugger crea una directory di registro in /tmp/tfdbg2_logdir. Possiamo avviare TensorBoard e puntarlo alla logdir con:
tensorboard --logdir /tmp/tfdbg2_logdir
Nel browser Web, accedere alla pagina di TensorBoard all'indirizzo http://localhost:6006. Il plugin “Debugger V2” sarà inattivo per impostazione predefinita, quindi selezionalo dal menu “Plugin inattivi” in alto a destra. Una volta selezionato, dovrebbe assomigliare al seguente:
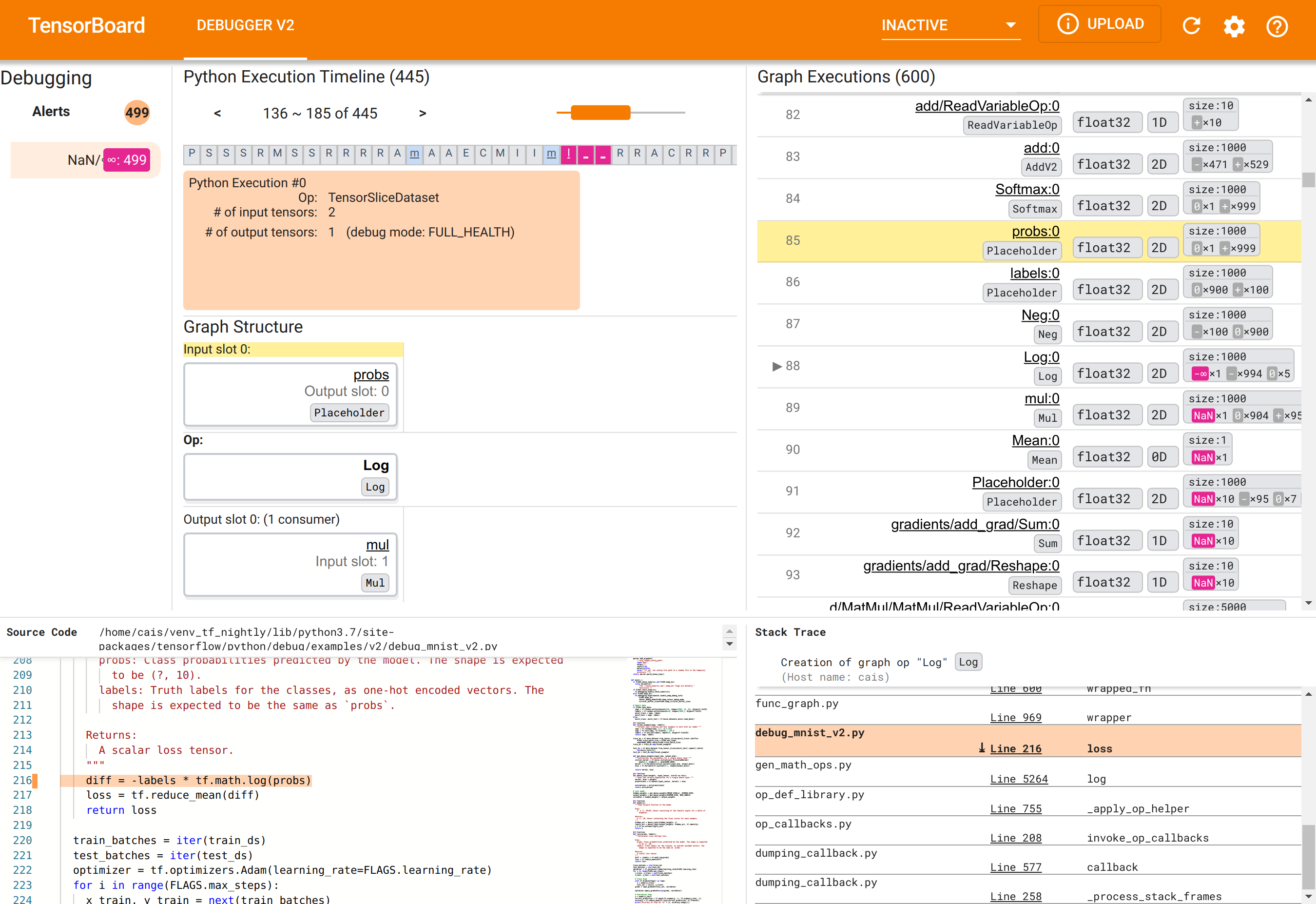
Utilizzo della GUI di Debugger V2 per trovare la causa principale dei NaN
La GUI di Debugger V2 in TensorBoard è organizzata in sei sezioni:
- Avvisi : questa sezione in alto a sinistra contiene un elenco di eventi di "avviso" rilevati dal debugger nei dati di debug del programma TensorFlow strumentato. Ogni avviso indica una determinata anomalia che merita attenzione. Nel nostro caso, questa sezione evidenzia 499 eventi NaN/∞ con un colore rosa-rosso saliente. Ciò conferma il nostro sospetto che il modello non riesca ad apprendere a causa della presenza di NaN e/o infiniti nei suoi valori tensoriali interni. Approfondiremo questi avvisi a breve.
- Timeline di esecuzione Python : questa è la metà superiore della sezione centrale in alto. Presenta la storia completa dell'esecuzione entusiasta di operazioni e grafici. Ogni casella della timeline è contrassegnata dalla lettera iniziale del nome dell'operazione o del grafico (ad esempio, "T" per l'operazione "TensorSliceDataset", "m" per il "modello"
tf.function). Possiamo navigare in questa sequenza temporale utilizzando i pulsanti di navigazione e la barra di scorrimento sopra la sequenza temporale. - Esecuzione del grafico : situata nell'angolo in alto a destra della GUI, questa sezione sarà centrale per la nostra attività di debug. Contiene una cronologia di tutti i tensori di tipo d mobile calcolati all'interno dei grafici (cioè compilati da
@tf-functions). - La struttura del grafico (metà inferiore della sezione centrale in alto), il codice sorgente (sezione in basso a sinistra) e l'analisi dello stack (sezione in basso a destra) sono inizialmente vuoti. Il loro contenuto verrà popolato quando interagiamo con la GUI. Queste tre sezioni svolgeranno anche un ruolo importante nella nostra attività di debug.
Dopo esserci orientati all'organizzazione dell'interfaccia utente, procediamo con i seguenti passaggi per andare a fondo del motivo per cui sono comparsi i NaN. Innanzitutto, fai clic sull'avviso NaN/∞ nella sezione Avvisi. Questo fa scorrere automaticamente l'elenco dei 600 tensori del grafico nella sezione Esecuzione del grafico e si concentra sul #88, che è un tensore denominato Log:0 generato da un Log (logaritmo naturale) op. Un colore rosa-rosso saliente evidenzia un elemento -∞ tra i 1000 elementi del tensore 2D float32. Questo è il primo tensore nella storia di esecuzione del programma TF2 che conteneva NaN o infinito: i tensori calcolati prima non contengono NaN o ∞; molti (in effetti, la maggior parte) tensori calcolati successivamente contengono NaN. Possiamo confermarlo scorrendo su e giù l'elenco di esecuzione del grafico. Questa osservazione fornisce un forte indizio sul fatto che Log op sia la fonte dell'instabilità numerica in questo programma TF2.
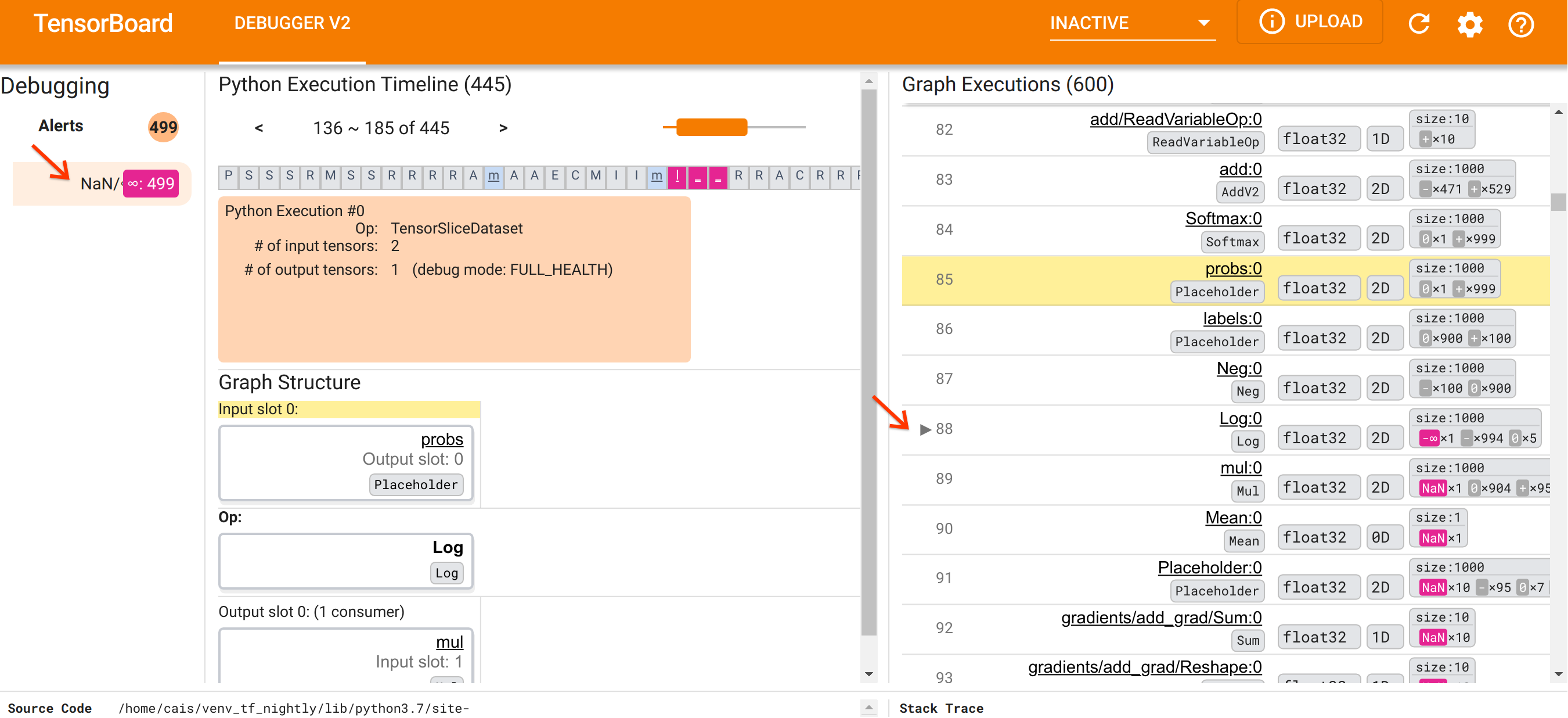
Perché questa operazione Log sputa un -∞? Per rispondere a questa domanda è necessario esaminare il contributo dell'op. Facendo clic sul nome del tensore ( Log:0 ) viene visualizzata una visualizzazione semplice ma informativa delle vicinanze dell'operazione Log nel suo grafico TensorFlow nella sezione Struttura del grafico. Notare la direzione del flusso di informazioni dall'alto verso il basso. L'operazione stessa è mostrata in grassetto al centro. Immediatamente sopra di esso, possiamo vedere un segnaposto op che fornisce l'unico input all'operazione Log . Dov'è il tensore generato da questo segnaposto probs nell'elenco di esecuzione del grafico? Utilizzando il colore di sfondo giallo come aiuto visivo, possiamo vedere che il tensore probs:0 è tre righe sopra il tensore Log:0 , cioè nella riga 85.
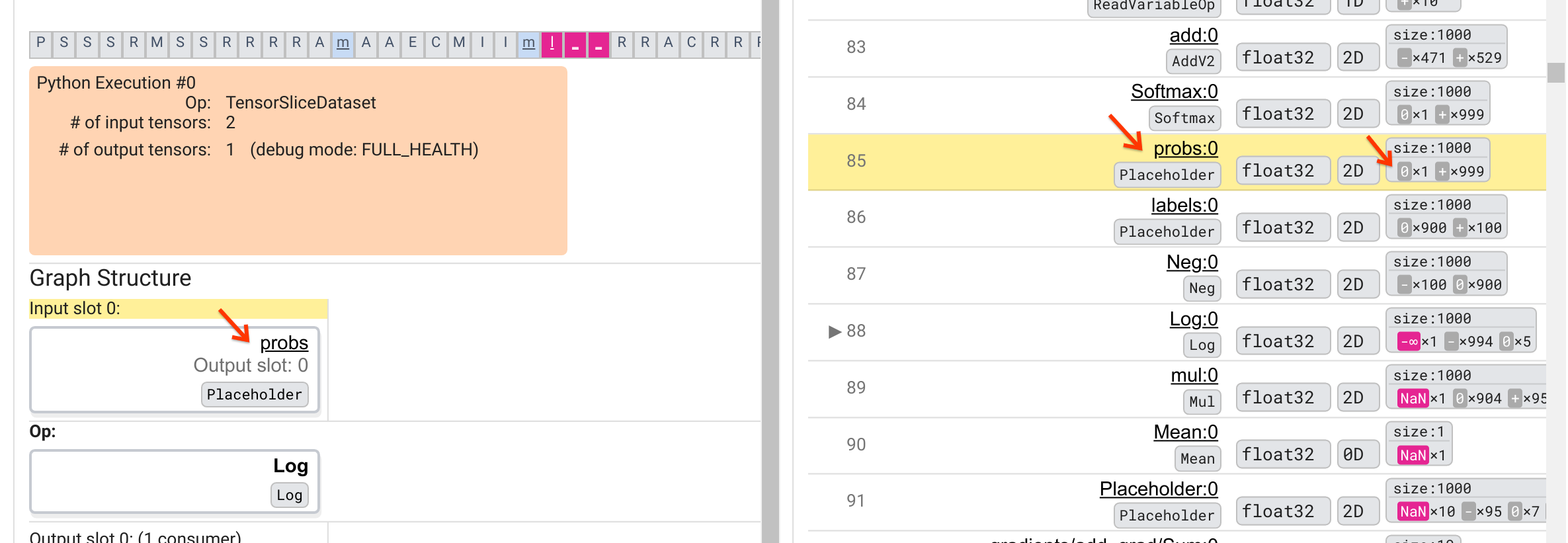
Uno sguardo più attento alla scomposizione numerica del tensore probs:0 nella riga 85 rivela perché il suo consumatore Log:0 produce un -∞: Tra i 1000 elementi di probs:0 , un elemento ha un valore di 0. Il -∞ è un risultato del calcolo del logaritmo naturale di 0! Se riusciamo in qualche modo a garantire che l'operazione Log venga esposta solo a input positivi, saremo in grado di impedire che si verifichi NaN/∞. Ciò può essere ottenuto applicando il ritaglio (ad esempio, utilizzando tf.clip_by_value() ) sul tensore probs Placeholder.
Ci stiamo avvicinando alla risoluzione del bug, ma non abbiamo ancora finito. Per applicare la correzione, dobbiamo sapere dove hanno avuto origine l'operazione Log e il relativo input segnaposto nel codice sorgente Python. Debugger V2 fornisce un supporto di prima classe per tracciare le operazioni del grafico e gli eventi di esecuzione alla loro origine. Quando abbiamo fatto clic sul tensore Log:0 in Esecuzioni grafico, la sezione Traccia dello stack è stata popolata con la traccia dello stack originale della creazione dell'operazione Log . L'analisi dello stack è piuttosto grande perché include molti frame del codice interno di TensorFlow (ad esempio, gen_math_ops.py e dumping_callback.py), che possiamo tranquillamente ignorare per la maggior parte delle attività di debug. Il frame di interesse è la riga 216 di debug_mnist_v2.py (cioè il file Python di cui stiamo effettivamente cercando di eseguire il debug). Facendo clic su "Riga 216" viene visualizzata la riga di codice corrispondente nella sezione Codice sorgente.
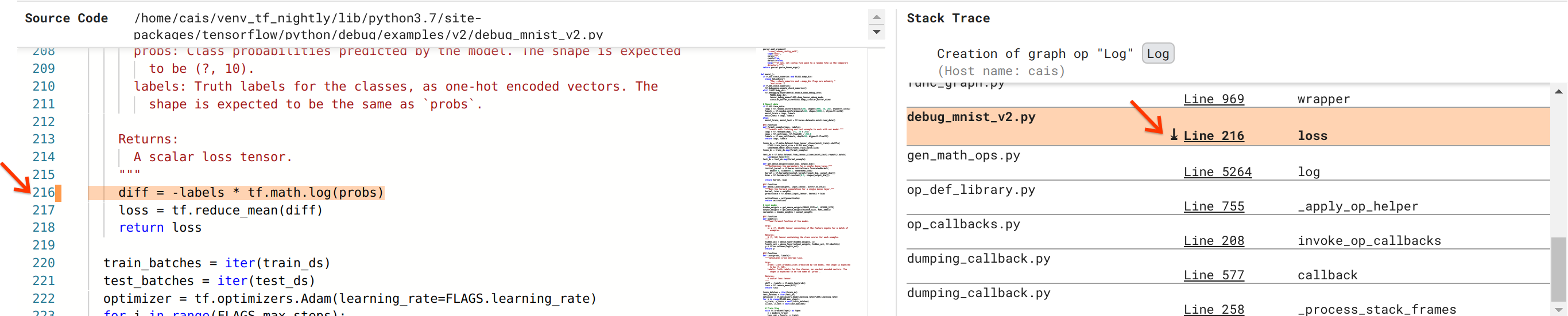
Questo ci porta finalmente al codice sorgente che ha creato il problematico Log op dal suo input probs . Questa è la nostra funzione personalizzata di perdita di entropia incrociata categorica decorata con @tf.function e quindi convertita in un grafico TensorFlow. Il segnaposto op probs corrisponde al primo argomento di input della funzione di perdita. L'operazione Log viene creata con la chiamata API tf.math.log().
La correzione del ritaglio del valore a questo bug sarà simile a:
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
Risolverà l'instabilità numerica in questo programma TF2 e farà sì che l'MLP si alleni con successo. Un altro possibile approccio per correggere l'instabilità numerica è utilizzare tf.keras.losses.CategoricalCrossentropy .
Questo conclude il nostro viaggio dall'osservazione di un bug del modello TF2 all'elaborazione di una modifica del codice che risolve il bug, aiutato dallo strumento Debugger V2, che fornisce piena visibilità nella cronologia di esecuzione del grafico e dell'esecuzione del programma TF2 strumentato, inclusi i riepiloghi numerici dei valori tensoriali e associazione tra ops, tensori e il loro codice sorgente originale.
Compatibilità hardware del Debugger V2
Debugger V2 supporta l'hardware di training tradizionale, tra cui CPU e GPU. È supportato anche il training multi-GPU con tf.distributed.MirroredStrategy . Il supporto per TPU è ancora in fase iniziale e richiede una chiamata
tf.config.set_soft_device_placement(True)
prima di chiamare enable_dump_debug_info() . Potrebbe avere anche altre limitazioni sui TPU. Se riscontri problemi utilizzando Debugger V2, segnala i bug nella nostra pagina dei problemi di GitHub .
Compatibilità API del Debugger V2
Debugger V2 è implementato a un livello relativamente basso dello stack software di TensorFlow e quindi è compatibile con tf.keras , tf.data e altre API basate sui livelli inferiori di TensorFlow. Debugger V2 è anche retrocompatibile con TF1, sebbene la sequenza temporale di esecuzione Eager sarà vuota per le directory di registro di debug generate dai programmi TF1.
Suggerimenti per l'utilizzo dell'API
Una domanda frequente su questa API di debug è dove nel codice TensorFlow si dovrebbe inserire la chiamata a enable_dump_debug_info() . In genere, l'API dovrebbe essere richiamata il più presto possibile nel programma TF2, preferibilmente dopo le righe di importazione di Python e prima che inizi la costruzione e l'esecuzione del grafico. Ciò garantirà una copertura completa di tutte le operazioni e i grafici che alimentano il tuo modello e il suo addestramento.
I tensor_debug_mode attualmente supportati sono: NO_TENSOR , CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH e SHAPE . Variano nella quantità di informazioni estratte da ciascun tensore e nel sovraccarico delle prestazioni del programma sottoposto a debug. Fare riferimento alla sezione args della documentazione di enable_dump_debug_info() .
Sovraccarico delle prestazioni
L'API di debug introduce un sovraccarico delle prestazioni nel programma TensorFlow strumentato. Il sovraccarico varia in base a tensor_debug_mode , al tipo di hardware e alla natura del programma TensorFlow strumentato. Come punto di riferimento, su una GPU, la modalità NO_TENSOR aggiunge un sovraccarico del 15% durante l'addestramento di un modello Transformer con dimensione batch 64. La percentuale di sovraccarico per altre modalità tensor_debug_mode è più alta: circa il 50% per CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH e SHAPE modalità. Sulle CPU, il sovraccarico è leggermente inferiore. Sulle TPU, il sovraccarico è attualmente più elevato.
Relazione con altre API di debug TensorFlow
Tieni presente che TensorFlow offre altri strumenti e API per il debug. Puoi sfogliare tali API nello spazio dei nomi tf.debugging.* nella pagina dei documenti API. Tra queste API quella utilizzata più frequentemente è tf.print() . Quando si dovrebbe usare Debugger V2 e quando invece dovrebbe essere usato tf.print() ? tf.print() è conveniente nel caso in cui
- sappiamo esattamente quali tensori stampare,
- sappiamo dove esattamente nel codice sorgente inserire quelle istruzioni
tf.print(), - il numero di tali tensori non è troppo grande.
Per altri casi (ad esempio, l'esame di molti valori tensoriali, l'esame dei valori tensoriali generati dal codice interno di TensorFlow e la ricerca dell'origine dell'instabilità numerica come mostrato sopra), Debugger V2 fornisce un modo più rapido di debug. Inoltre, Debugger V2 fornisce un approccio unificato all'ispezione dei tensori desiderosi e grafici. Fornisce inoltre informazioni sulla struttura del grafico e sulle posizioni del codice, che vanno oltre le capacità di tf.print() .
Un'altra API che può essere utilizzata per eseguire il debug di problemi che coinvolgono ∞ e NaN è tf.debugging.enable_check_numerics() . A differenza di enable_dump_debug_info() , enable_check_numerics() non salva le informazioni di debug sul disco. Invece, si limita a monitorare ∞ e NaN durante il runtime di TensorFlow e segnala errori con la posizione del codice di origine non appena qualsiasi operazione genera valori numerici così errati. Ha un sovraccarico prestazionale inferiore rispetto a enable_dump_debug_info() , ma non fornisce una traccia completa della cronologia di esecuzione del programma e non viene fornito con un'interfaccia utente grafica come Debugger V2.