
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Nell'apprendimento automatico, per migliorare qualcosa è spesso necessario essere in grado di misurarlo. TensorBoard è uno strumento per fornire le misurazioni e le visualizzazioni necessarie durante il flusso di lavoro di apprendimento automatico. Consente di monitorare le metriche degli esperimenti come la perdita e l'accuratezza, la visualizzazione del grafico del modello, la proiezione di incorporamenti in uno spazio dimensionale inferiore e molto altro.
Questo avvio rapido mostrerà come iniziare rapidamente con TensorBoard. Le restanti guide in questo sito Web forniscono maggiori dettagli su funzionalità specifiche, molte delle quali non sono incluse qui.
# Load the TensorBoard notebook extension
%load_ext tensorboard
import tensorflow as tf
import datetime
# Clear any logs from previous runsrm -rf ./logs/
Utilizzando la MNIST set di dati come l'esempio, normalizzare i dati e scrivere una funzione che crea un semplice modello Keras per classificare le immagini in 10 classi.
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
def create_model():
return tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step
Utilizzo di TensorBoard con Keras Model.fit()
Quando la formazione con del Keras Model.fit () , aggiungendo il tf.keras.callbacks.TensorBoard callback assicura che i registri vengono creati e archiviati. Inoltre, abilitare istogramma calcolo ogni epoca con histogram_freq=1 (questa è disattivata di default)
Collocare i registri in una sottodirectory con timestamp per consentire una facile selezione di diverse sessioni di allenamento.
model = create_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])
Train on 60000 samples, validate on 10000 samples Epoch 1/5 60000/60000 [==============================] - 15s 246us/sample - loss: 0.2217 - accuracy: 0.9343 - val_loss: 0.1019 - val_accuracy: 0.9685 Epoch 2/5 60000/60000 [==============================] - 14s 229us/sample - loss: 0.0975 - accuracy: 0.9698 - val_loss: 0.0787 - val_accuracy: 0.9758 Epoch 3/5 60000/60000 [==============================] - 14s 231us/sample - loss: 0.0718 - accuracy: 0.9771 - val_loss: 0.0698 - val_accuracy: 0.9781 Epoch 4/5 60000/60000 [==============================] - 14s 227us/sample - loss: 0.0540 - accuracy: 0.9820 - val_loss: 0.0685 - val_accuracy: 0.9795 Epoch 5/5 60000/60000 [==============================] - 14s 228us/sample - loss: 0.0433 - accuracy: 0.9862 - val_loss: 0.0623 - val_accuracy: 0.9823 <tensorflow.python.keras.callbacks.History at 0x7fc8a5ee02e8>
Avvia TensorBoard tramite la riga di comando o all'interno di un'esperienza notebook. Le due interfacce sono generalmente le stesse. Nel notebook, utilizzare l' %tensorboard magia linea. Sulla riga di comando, esegui lo stesso comando senza "%".
%tensorboard --logdir logs/fit
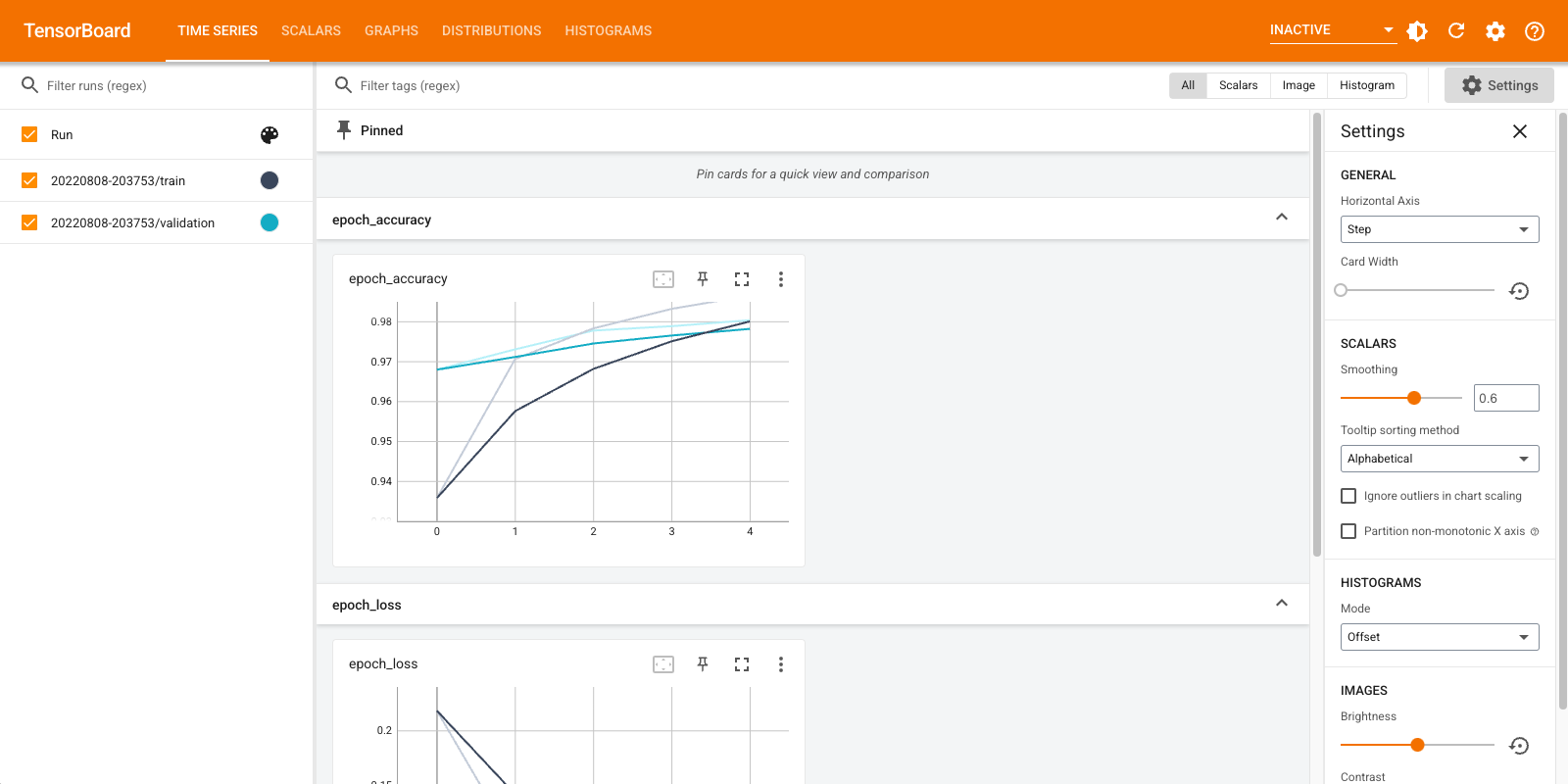
Una breve panoramica delle dashboard visualizzate (schede nella barra di navigazione in alto):
- Gli spettacoli cruscotto Scalari come la perdita e metriche cambiano con ogni epoca. Puoi usarlo anche per monitorare la velocità di allenamento, la velocità di apprendimento e altri valori scalari.
- Il cruscotto grafici aiuta a visualizzare il tuo modello. In questo caso, viene mostrato il grafico dei livelli Keras che può aiutarti a assicurarti che sia costruito correttamente.
- I cruscotti Distribuzioni e istogrammi mostrano la distribuzione di un tensore nel corso del tempo. Questo può essere utile per visualizzare pesi e distorsioni e verificare che stiano cambiando nel modo previsto.
Ulteriori plug-in TensorBoard vengono abilitati automaticamente quando si registrano altri tipi di dati. Ad esempio, il callback Keras TensorBoard consente di registrare anche immagini e incorporamenti. Puoi vedere quali altri plugin sono disponibili in TensorBoard facendo clic sul menu a discesa "inattivo" in alto a destra.
Utilizzo di TensorBoard con altri metodi
Quando la formazione con metodi quali tf.GradientTape() , l'uso tf.summary per registrare le informazioni richieste.
Utilizzare lo stesso insieme di dati come sopra, ma convertirlo in tf.data.Dataset per sfruttare il dosaggio funzionalità:
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.shuffle(60000).batch(64)
test_dataset = test_dataset.batch(64)
Il codice di formazione segue l' avanzata di avvio rapido tutorial, ma mostra come accedere alle metriche TensorBoard. Scegli la perdita e l'ottimizzatore:
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
Crea metriche con stato che possono essere utilizzate per accumulare valori durante l'allenamento e registrate in qualsiasi momento:
# Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')
Definire le funzioni di addestramento e test:
def train_step(model, optimizer, x_train, y_train):
with tf.GradientTape() as tape:
predictions = model(x_train, training=True)
loss = loss_object(y_train, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y_train, predictions)
def test_step(model, x_test, y_test):
predictions = model(x_test)
loss = loss_object(y_test, predictions)
test_loss(loss)
test_accuracy(y_test, predictions)
Configura i writer di riepilogo per scrivere i riepiloghi su disco in una directory dei registri diversa:
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)
Inizia la formazione. Utilizzare tf.summary.scalar() per accedere metriche (perdita e di precisione) durante l'allenamento / collaudo nell'ambito degli scrittori di sintesi di scrivere i sommari su disco. Hai il controllo su quali metriche registrare e con quale frequenza farlo. Altri tf.summary funzioni attivare la registrazione di altri tipi di dati.
model = create_model() # reset our model
EPOCHS = 5
for epoch in range(EPOCHS):
for (x_train, y_train) in train_dataset:
train_step(model, optimizer, x_train, y_train)
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
for (x_test, y_test) in test_dataset:
test_step(model, x_test, y_test)
with test_summary_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reset metrics every epoch
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states()
Epoch 1, Loss: 0.24321186542510986, Accuracy: 92.84333801269531, Test Loss: 0.13006582856178284, Test Accuracy: 95.9000015258789 Epoch 2, Loss: 0.10446818172931671, Accuracy: 96.84833526611328, Test Loss: 0.08867532759904861, Test Accuracy: 97.1199951171875 Epoch 3, Loss: 0.07096975296735764, Accuracy: 97.80166625976562, Test Loss: 0.07875105738639832, Test Accuracy: 97.48999786376953 Epoch 4, Loss: 0.05380449816584587, Accuracy: 98.34166717529297, Test Loss: 0.07712937891483307, Test Accuracy: 97.56999969482422 Epoch 5, Loss: 0.041443776339292526, Accuracy: 98.71833038330078, Test Loss: 0.07514958828687668, Test Accuracy: 97.5
Apri di nuovo TensorBoard, questa volta puntandolo alla nuova directory di registro. Avremmo anche potuto avviare TensorBoard per monitorare l'allenamento mentre procede.
%tensorboard --logdir logs/gradient_tape
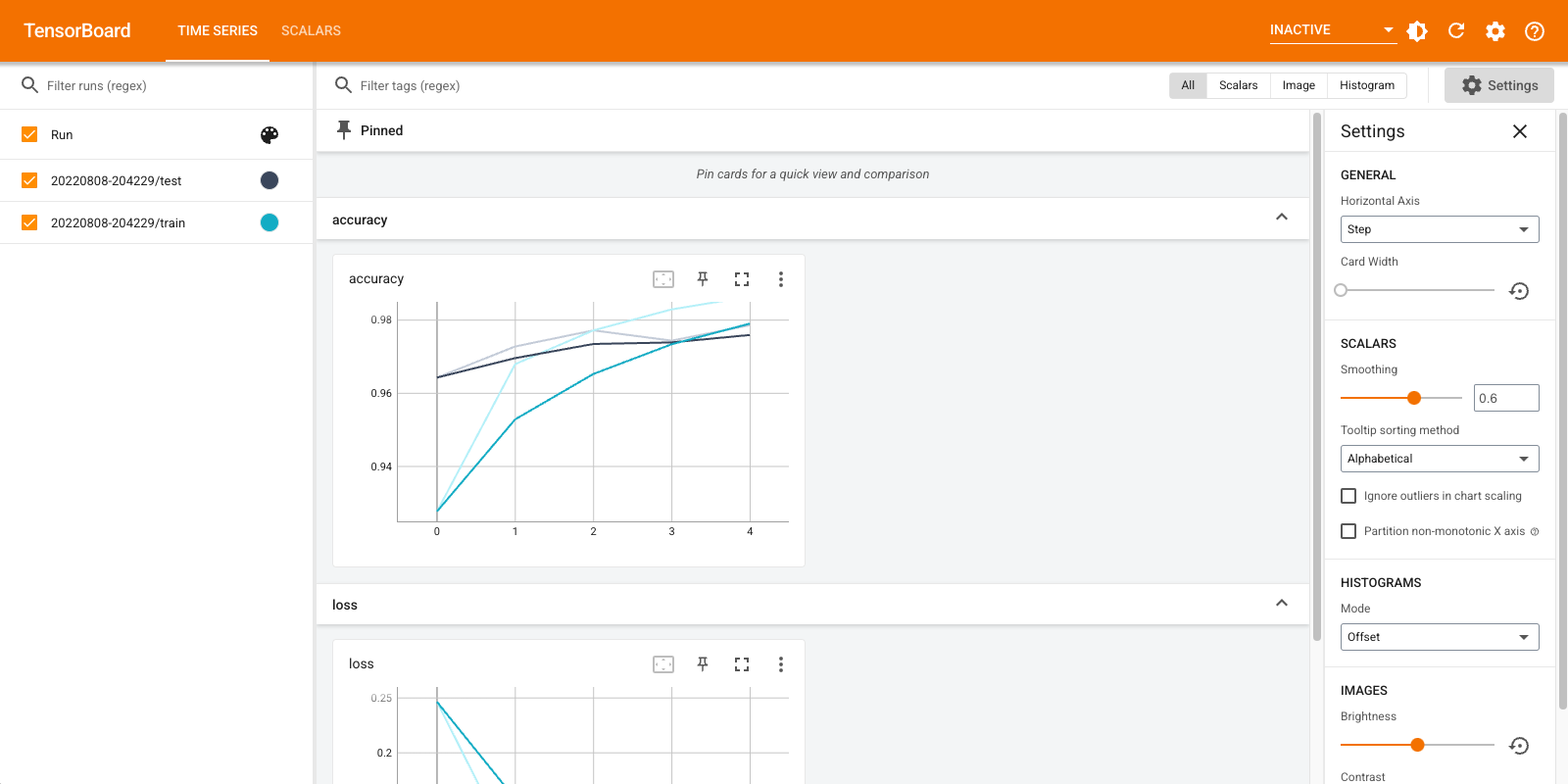
Questo è tutto! Ora avete visto come utilizzare TensorBoard sia attraverso il callback Keras e attraverso tf.summary per ulteriori scenari personalizzati.
TensorBoard.dev: ospita e condividi i risultati dell'esperimento ML
TensorBoard.dev è un servizio pubblico gratuito che consente di caricare i log di TensorBoard e ottenere un permalink che può essere condiviso con tutti in pubblicazioni accademiche, post di blog, social media, ecc Questo può consentire una migliore riproducibilità e la collaborazione.
Per utilizzare TensorBoard.dev, eseguire il comando seguente:
!tensorboard dev upload \
--logdir logs/fit \
--name "(optional) My latest experiment" \
--description "(optional) Simple comparison of several hyperparameters" \
--one_shot
Si noti che questa invocazione utilizza il prefisso esclamativo ( ! ) Per richiamare il guscio piuttosto che il prefisso per cento ( % ) per richiamare la magia CoLab. Quando si richiama questo comando dalla riga di comando non è necessario nessuno dei prefissi.
Visualizza un esempio qui .
Per ulteriori dettagli su come utilizzare TensorBoard.dev, vedere https://tensorboard.dev/#get-started