
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
عند بناء نماذج تعلم الآلة، تحتاج إلى اختيار مختلف hyperparameters ، مثل معدل التسرب في طبقة أو معدل التعلم. تؤثر هذه القرارات على مقاييس النموذج ، مثل الدقة. لذلك ، تتمثل إحدى الخطوات المهمة في سير عمل التعلم الآلي في تحديد أفضل المعلمات التشعبية لمشكلتك ، والتي غالبًا ما تتضمن التجريب. تُعرف هذه العملية باسم "Hyperparameter Optimization" أو "Hyperparameter Tuning".
توفر لوحة معلومات HParams في TensorBoard العديد من الأدوات للمساعدة في هذه العملية لتحديد أفضل تجربة أو أكثر المجموعات الواعدة من المعلمات الفائقة.
سيركز هذا البرنامج التعليمي على الخطوات التالية:
- إعداد التجربة وملخص HParams
- يعمل Adapt على TensorFlow لتسجيل المعلمات والمقاييس التشعبية
- ابدأ بتشغيلها وقم بتسجيلها جميعًا ضمن دليل رئيسي واحد
- تصور النتائج في لوحة معلومات HParams من TensorBoard
ابدأ بتثبيت TF 2.0 وتحميل ملحق الكمبيوتر المحمول TensorBoard:
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
استيراد TensorFlow والمكوِّن الإضافي TensorBoard HParams:
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
تحميل FashionMNIST بيانات وتوسيع نطاق ذلك:
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. إعداد التجربة وملخص تجربة HParams
جرب ثلاثة معلمات تشعبية في النموذج:
- عدد الوحدات في الطبقة الأولى كثيفة
- معدل التسرب في طبقة التسرب
- محسن
ضع قائمة بالقيم التي تريد تجربتها ، وقم بتسجيل تكوين التجربة في TensorBoard. هذه الخطوة اختيارية: يمكنك توفير معلومات المجال لتمكين تصفية أكثر دقة للمعلمات التشعبية في واجهة المستخدم ، ويمكنك تحديد المقاييس التي يجب عرضها.
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
إذا اخترت تخطي هذه الخطوة، يمكنك استخدام حرفي سلسلة أينما كنت على خلاف ذلك استخدام HParam القيمة: على سبيل المثال، hparams['dropout'] بدلا من hparams[HP_DROPOUT] .
2. تكييف عمليات TensorFlow لتسجيل المعلمات الفوقية والمقاييس
سيكون النموذج بسيطًا للغاية: طبقتان كثيفتان مع طبقة متسربة بينهما. سيبدو رمز التدريب مألوفًا ، على الرغم من أن المعلمات الفائقة لم تعد مضمنة. بدلا من ذلك، يتم توفير hyperparameters في hparams قاموس والمستخدمة في وظيفة التدريب:
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
لكل عملية تشغيل ، قم بتسجيل ملخص hparams باستخدام المعلمات التشعبية والدقة النهائية:
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
عند تدريب نماذج Keras ، يمكنك استخدام عمليات الاسترجاعات بدلاً من كتابتها مباشرةً:
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. ابدأ عمليات التشغيل وقم بتسجيلها جميعًا ضمن دليل رئيسي واحد
يمكنك الآن تجربة تجارب متعددة ، وتدريب كل منها بمجموعة مختلفة من المعلمات الفائقة.
للتبسيط ، استخدم بحث الشبكة: جرب جميع تركيبات المعلمات المنفصلة والحدود الدنيا والعليا للمعامل الحقيقي القيمة. بالنسبة للسيناريوهات الأكثر تعقيدًا ، قد يكون من الأفضل اختيار كل قيمة معلمة تشعبية عشوائيًا (وهذا ما يسمى البحث العشوائي). هناك طرق أكثر تقدمًا يمكن استخدامها.
قم بإجراء بعض التجارب ، والتي ستستغرق بضع دقائق:
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. تصور النتائج في البرنامج الإضافي HParams الخاص بـ TensorBoard
يمكن الآن فتح لوحة أجهزة القياس HParams. ابدأ TensorBoard وانقر فوق "HParams" في الأعلى.
%tensorboard --logdir logs/hparam_tuning
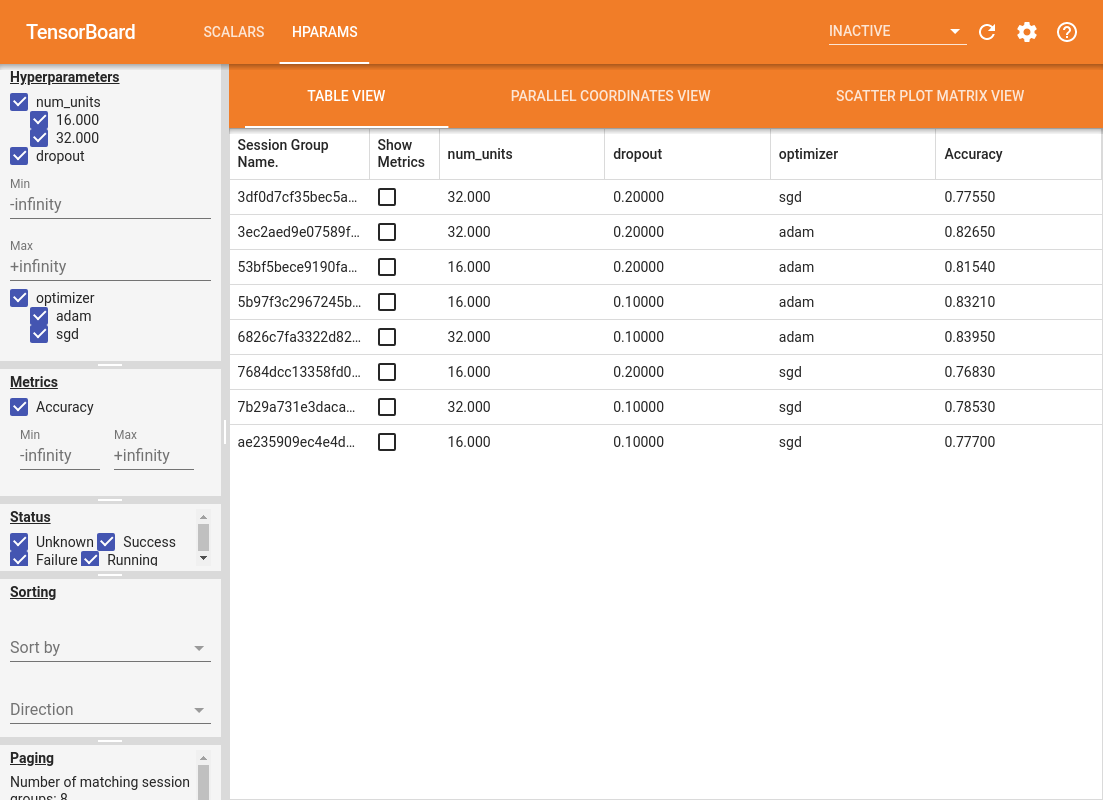
يوفر الجزء الأيمن من لوحة المعلومات إمكانيات تصفية نشطة عبر جميع طرق العرض في لوحة معلومات HParams:
- قم بتصفية المعلمات التشعبية / المقاييس التي تظهر في لوحة المعلومات
- قم بتصفية قيم المعلمات التشعبية / المقاييس التي تظهر في لوحة المعلومات
- التصفية على حالة التشغيل (قيد التشغيل ، النجاح ، ...)
- الفرز حسب المعامل التشعبي / القياس في عرض الجدول
- عدد مجموعات الجلسات المراد عرضها (مفيدة للأداء عند وجود العديد من التجارب)
تحتوي لوحة معلومات HParams على ثلاث طرق عرض مختلفة ، مع معلومات مفيدة متنوعة:
- وعرض الجدول يسرد أشواط، hyperparameters بهم، والمقاييس الخاصة بهم.
- والاحداثيات مشاهدة الموازي يظهر كل تشغيل كخط يمر محور لكل hyperparemeter ومتري. انقر واسحب الماوس على أي محور لتحديد المنطقة التي ستبرز فقط المسارات التي تمر عبرها. يمكن أن يكون هذا مفيدًا لتحديد مجموعات المعلمات التشعبية الأكثر أهمية. يمكن إعادة ترتيب المحاور نفسها عن طريق سحبها.
- في مؤامرة مبعثر مشاهدة عروض المؤامرات مقارنة كل hyperparameter / متري مع كل متري. هذا يمكن أن يساعد في تحديد الارتباطات. انقر واسحب لتحديد منطقة في قطعة أرض معينة وقم بتمييز تلك الجلسات عبر المؤامرات الأخرى.
يمكن النقر فوق صف جدول وخط إحداثيات متوازية وسوق مخطط مبعثر لرؤية مخطط للمقاييس كدالة لخطوات التدريب لتلك الجلسة (على الرغم من استخدام خطوة واحدة فقط في هذا البرنامج التعليمي لكل تشغيل).
لمزيد من استكشاف إمكانات لوحة معلومات HParams ، قم بتنزيل مجموعة من السجلات التي تم إنشاؤها مسبقًا مع المزيد من التجارب:
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
اعرض هذه السجلات في TensorBoard:
%tensorboard --logdir logs/hparam_demo
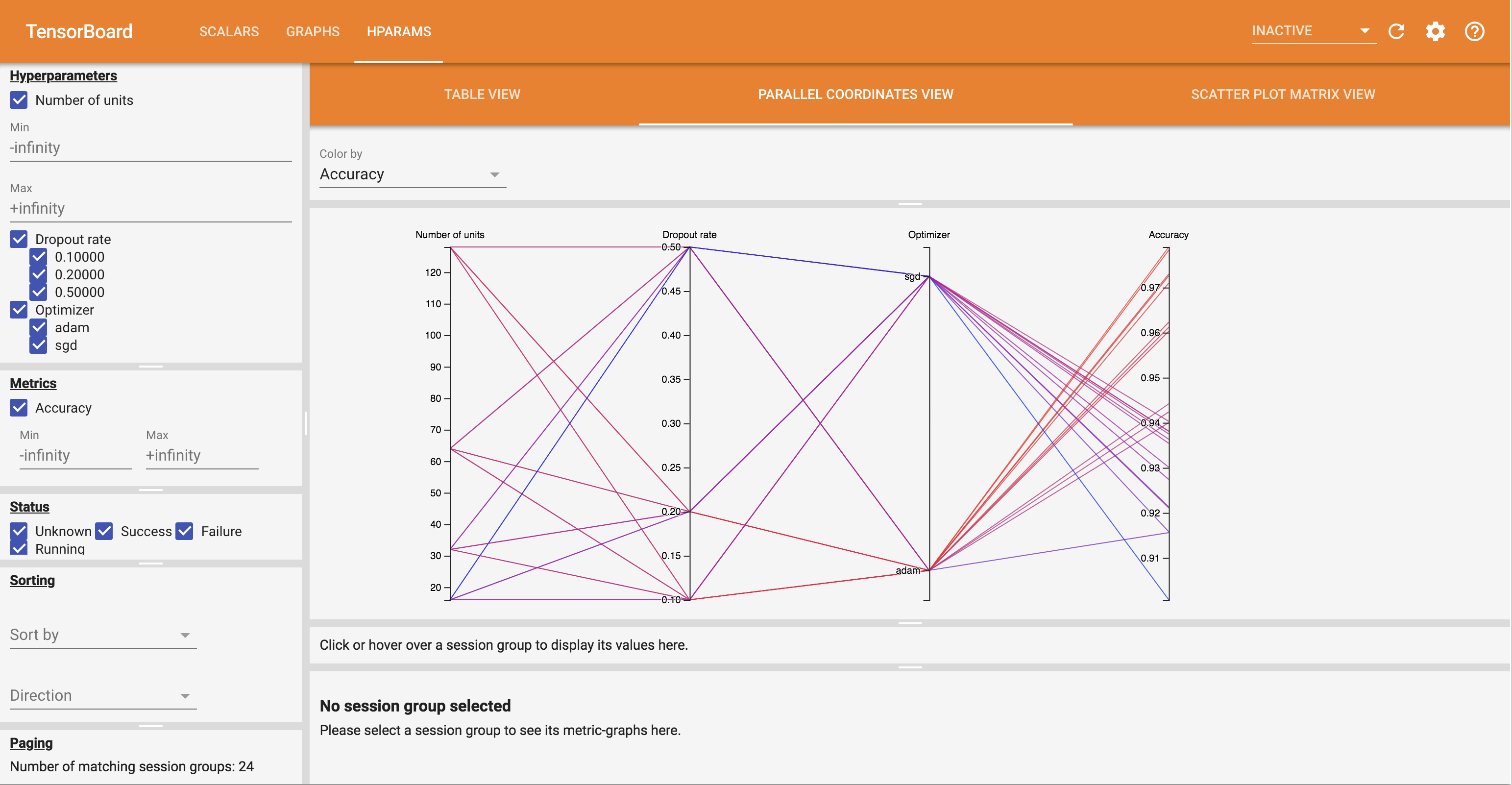
يمكنك تجربة طرق العرض المختلفة في لوحة معلومات HParams.
على سبيل المثال ، بالانتقال إلى عرض الإحداثيات المتوازية والنقر والسحب على محور الدقة ، يمكنك تحديد عمليات التشغيل بأعلى دقة. نظرًا لأن هذه العمليات تمر عبر "adam" في محور المحسن ، يمكنك استنتاج أن أداء "adam" أفضل من أداء "sgd" في هذه التجارب.