| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
ملخص
باستخدام TensorBoard تضمين العارض، يمكنك تمثل بيانيا التضمينات الأبعاد عالية. يمكن أن يكون هذا مفيدًا في تصور طبقات التضمين وفحصها وفهمها.

في هذا البرنامج التعليمي ، ستتعلم كيفية تصور هذا النوع من الطبقات المدربة.
يثبت
في هذا البرنامج التعليمي ، سنستخدم TensorBoard لتصور طبقة التضمين التي تم إنشاؤها لتصنيف بيانات مراجعة الفيلم.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
بيانات IMDB
سنستخدم مجموعة بيانات من 25000 مراجعة فيلم من IMDB ، ولكل منها ملصق رأي (إيجابي / سلبي). تتم معالجة كل مراجعة وتشفيرها كسلسلة من مؤشرات الكلمات (أعداد صحيحة). للتبسيط ، تتم فهرسة الكلمات حسب التردد الكلي في مجموعة البيانات ، على سبيل المثال ، يشفر العدد الصحيح "3" الكلمة الثالثة الأكثر شيوعًا التي تظهر في جميع المراجعات. يتيح ذلك عمليات التصفية السريعة مثل: "ضع في اعتبارك فقط أكثر 10000 كلمة شيوعًا ، ولكن احذف الكلمات العشرين الأكثر شيوعًا".
كمصطلح ، "0" لا يمثل أي كلمة محددة ، ولكنه يستخدم بدلاً من ذلك لتشفير أي كلمة غير معروفة. لاحقًا في البرنامج التعليمي ، سنزيل صف "0" في التصور.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
طبقة تضمين Keras
A طبقة Keras تضمين يمكن استخدامها لتدريب التضمين لكل كلمة في المفردات الخاصة بك. سيتم ربط كل كلمة (أو كلمة فرعية في هذه الحالة) مع متجه 16 بعدًا (أو تضمين) سيتم تدريبه بواسطة النموذج.
انظر هذا البرنامج التعليمي لمعرفة المزيد عن التضمينات كلمة.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
حفظ البيانات للوحة TensorBoard
يقرأ TensorBoard الموترات والبيانات الوصفية من سجلات مشروعات Tensorflow الخاصة بك. يتم تحديد المسار إلى دليل سجل مع log_dir أدناه. لهذا البرنامج التعليمي، ونحن سوف تستخدم /logs/imdb-example/ .
من أجل تحميل البيانات إلى Tensorboard ، نحتاج إلى حفظ نقطة تفتيش تدريب في هذا الدليل ، جنبًا إلى جنب مع البيانات الوصفية التي تسمح بتصور طبقة معينة من الاهتمام في النموذج.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
التحليلات
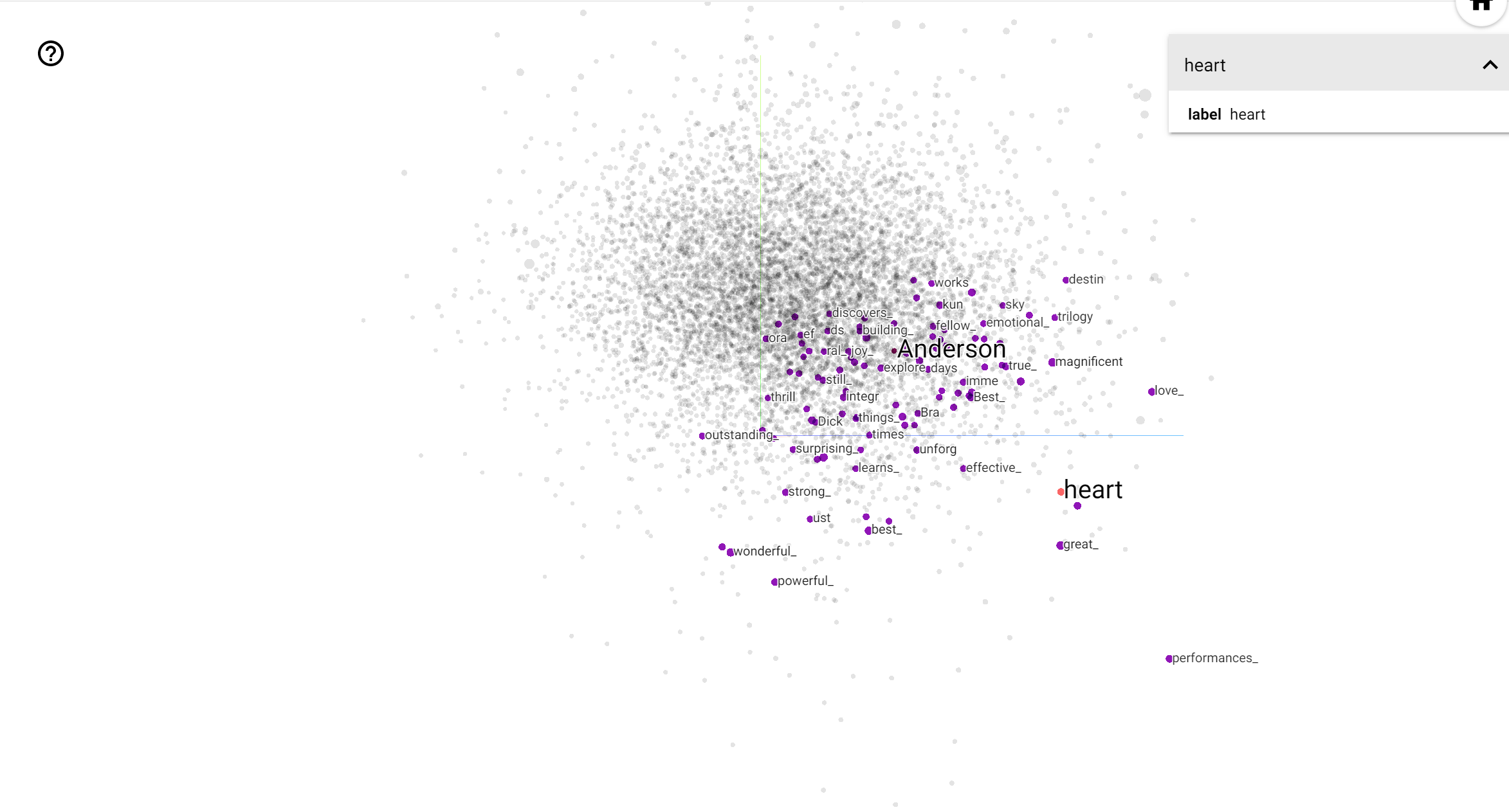
يُعد جهاز عرض TensorBoard أداة رائعة لتفسير التضمين وتصوره. تتيح لوحة المعلومات للمستخدمين البحث عن مصطلحات معينة ، وتميز الكلمات المجاورة لبعضها البعض في مساحة التضمين (منخفضة الأبعاد). من هذا المثال يمكننا أن نرى أن ويس أندرسون وألفريد هيتشكوك على حد سواء حيث محايدة إلى حد ما، ولكنها تتم الإشارة إليها في سياقات مختلفة.
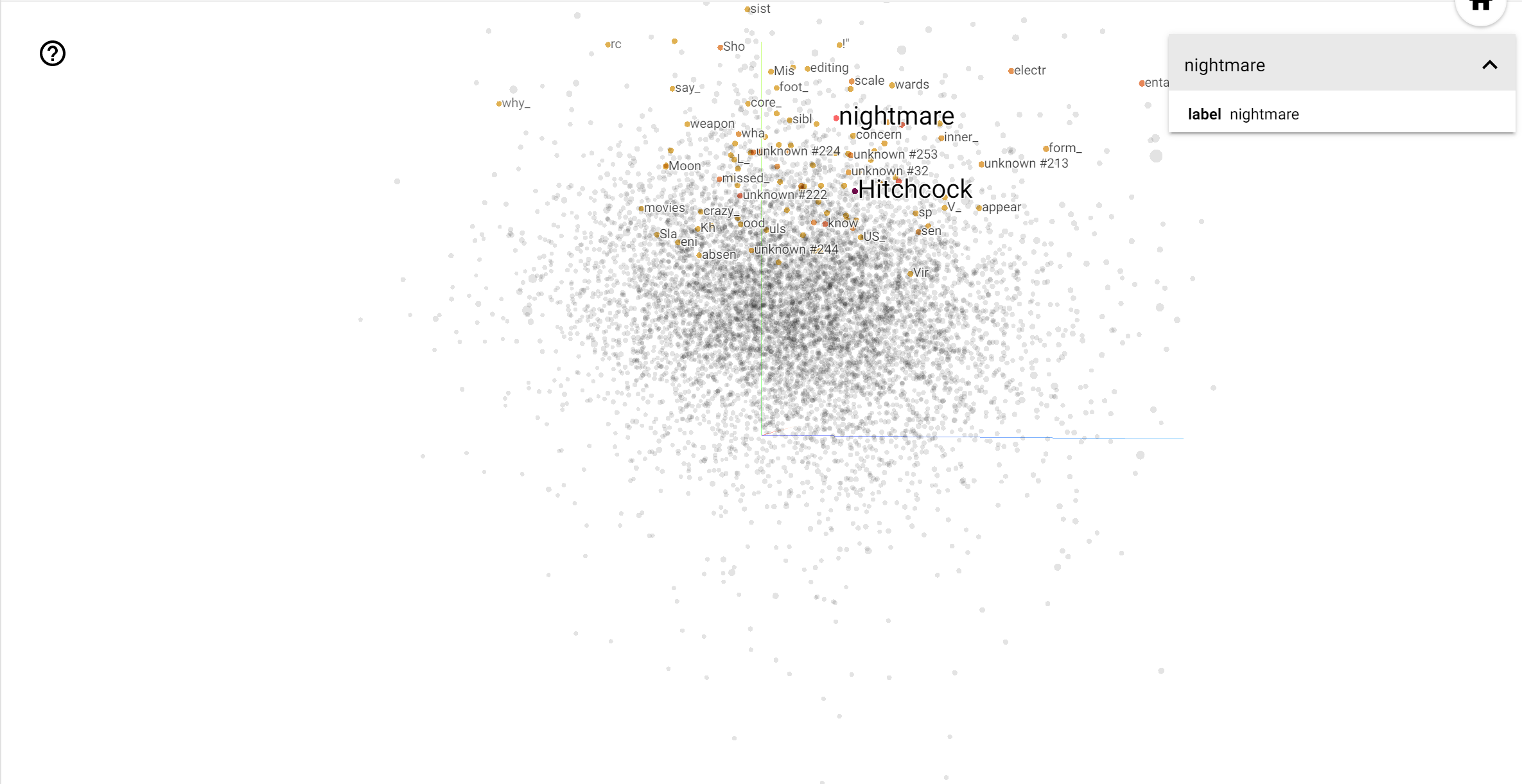
في هذا الفضاء، هيتشكوك هو أقرب إلى كلمات مثل nightmare ، والتي من المرجح يرجع ذلك إلى حقيقة أنه المعروفة باسم "سيد المعلق"، في حين اندرسون هو أقرب إلى كلمة heart ، وهو ما يتسق مع نظيره وأسلوب مفصل بلا هوادة الحميم .